- 151单片机入门_江协科技_1~10_OB记录的笔记
- 2建信金科是外包吗_offer比较:北京数据所vs上海建信金科 - 找工作啦(Job)版 - 北大未名BBS...
- 3一文弄懂Flink CDC
- 4如何用人工智能预测股票(完整答案)_[nltk_data] downloading package vader_lexicon to
- 5[Mac OS X] 内核、驱动开发资料汇总_mac os 硬件驱动开发
- 6Mac使用Microsoft Remote Desktop远程控制Win10电脑_remote desktop for mac 端口号
- 7内网穿透FRP详细教程_frpc
- 8哈尔滨工业大学2022计算机系统大作业_哈工大oj题库
- 9禁用AMQP配置中的明文身份验证机制--漏洞解决方法_在 amqp 配置中禁用明文验证机制。
- 10Python:关机小程序_python关机程序
第四章 Ambari二次开发之自定义Flink服务源码剖析_ambari 开发
赞
踩
1、Ambari架构剖析
1.1、Ambari概述
(1)Ambari目标
①核心目标:解决Hadoop生态系统部署问题
②实现方式:默认配置写入stack中,在开启时将stack总各个版本的config文件读入,在使用blueprint创建集群部署hadoop时,直接生成command-json文件。
(2)Ambari主要概念
①资源:ambari将集群及集群中的服务、组件、机器都视为资源,资源的状态都会记录在db中。
②Stack:发行版本含义,如HDP有多个版本。
③host:运行ambari-sgent的一台物理机,同时也是搭建集群内部的一台机器。
④角色:物理机集群部署时指定的角色。,如master、slave等,也可以指定每种角色需要的host个数。例如namenode为单一host组件,可以部署在master机器上,datanode可以部署在多台host上那么可以指定部署datanode的角色为slave
⑤Blueprint:调用一次restAPI即可进行集群创建、服务安装、组件部署、服务开始等集群操作,简化了单步创建的调用次数。
(3)Ambari整体流程
①restAPI---->ambari-server单步创建
- 核心:通过调用ambari提供的restAPI进行集群的单步创建
Ⅰ、Add cluster:新建集群
Ⅱ、Update cluster:更新集群配置
Ⅲ、Add service for cluster:向集群添加服务
Ⅳ、Add component for service:为每个服务添加对应组件
Ⅴ、Add host for cluster:添加host资源
Ⅵ、Add component on host:设置每个host上运行的组件
Ⅶ、Install/Start/Stop service:安装/开启/关闭 集群的对应服务
②ambari-server->ambari-agent
Ⅰ、ambari-server端负责接收rest请求,再向agent端发送命令,发送命令的格式是json,内部包涵部署脚本执行命令(安装/开始/停止服务)所需要的配置信息,这里所指的配置信息一般是手动部署集群需要配置的xml文件,例如hadoop-site.xml文件,在blueprint或单步创建里会有详细说明。
Ⅱ、ambari-agent执行脚本:ambari-agent所执行的脚本存储在ambari-server 机器上的/var/lib/ambari-server/resources/stacks/HDP/2.0.6/下各个service路径下的package路径下的scripts内,脚本的编写语言为python,脚本继承了名为Script的父类,该父类提供了一些函数,例如Script.get_config(),该函数将agent接收来自server端的command-json文件的内容转化为字典格式方便脚本实现部署时对配置的使用。具体anent接收到的command-json保存在了运行agent机器下的/var/lib/ambari-agent/data路径下。
1.2、基本架构图
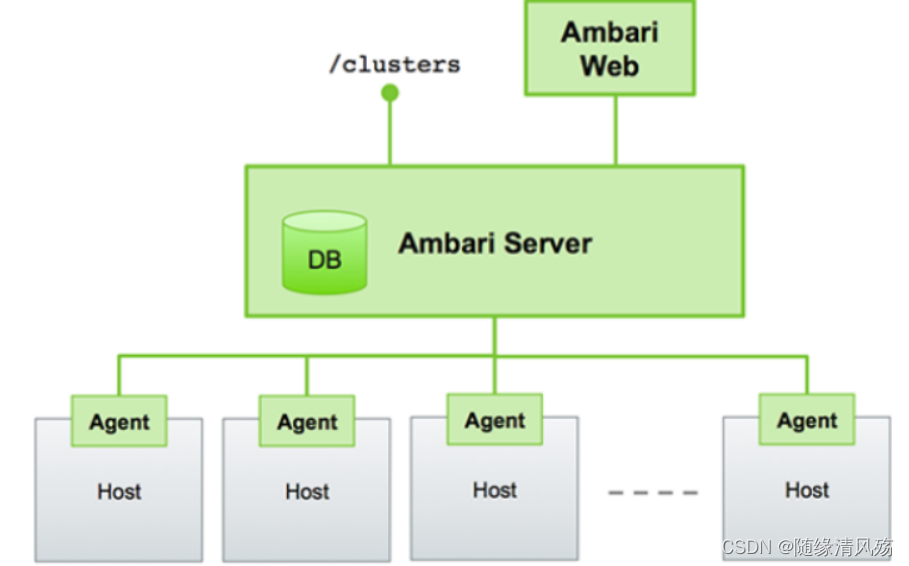
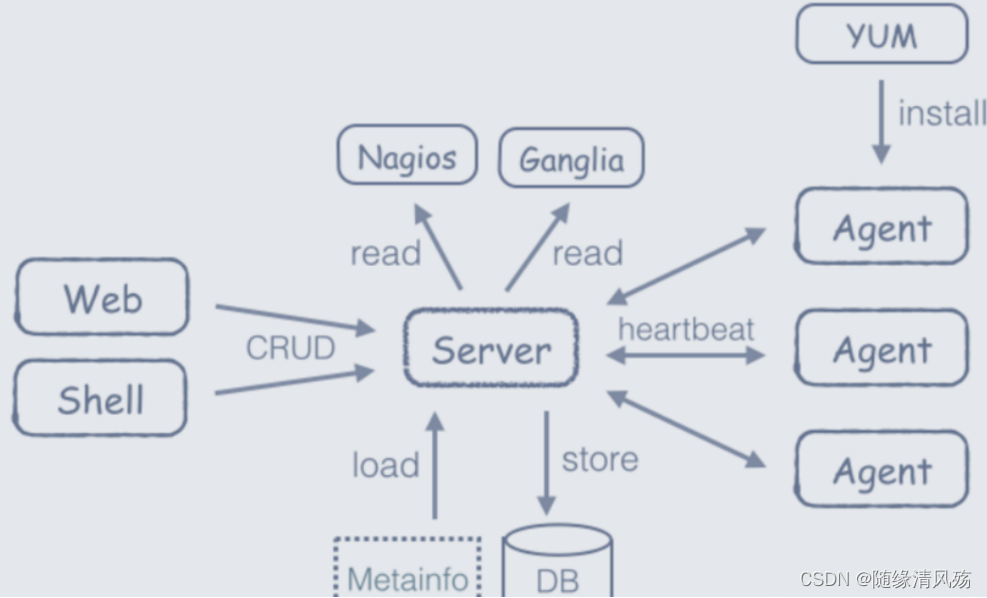
Ambari框架采用的是Server/Client模式,主要由两部分组成:ambari-agent和ambari-server。
- ambari-server:依赖于python
- ambari-agent:依赖于ruby、puppet、fecter等工具,包括监控工具nagios、ganglia用于监控集群状况。
1.3、系统架构图
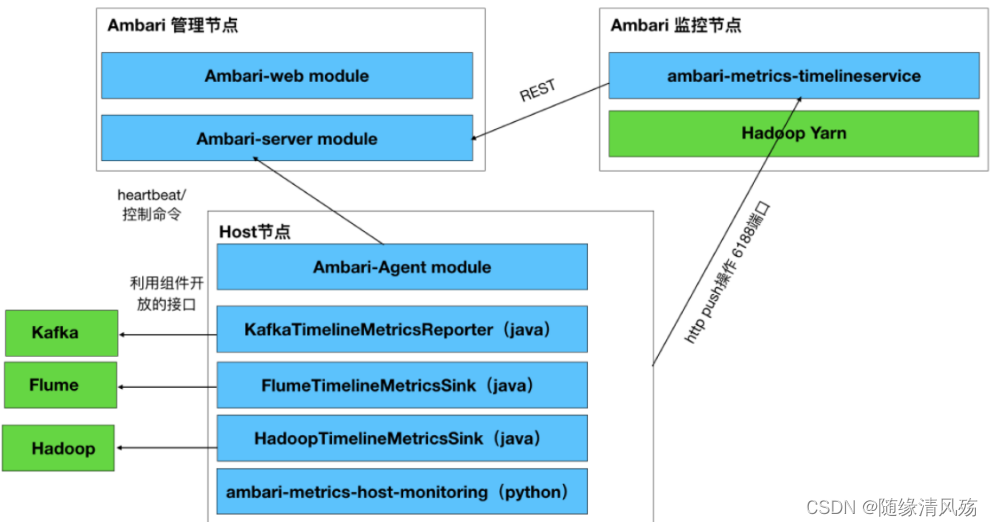
(1)整体架构说明
- 核心:Ambari Web通过调用Ambari REST API实现对Hadoop生态系统各个组件的操作,即Ambari REST API是唯一暴露给"外部"系统进行操作Ambari的方式。
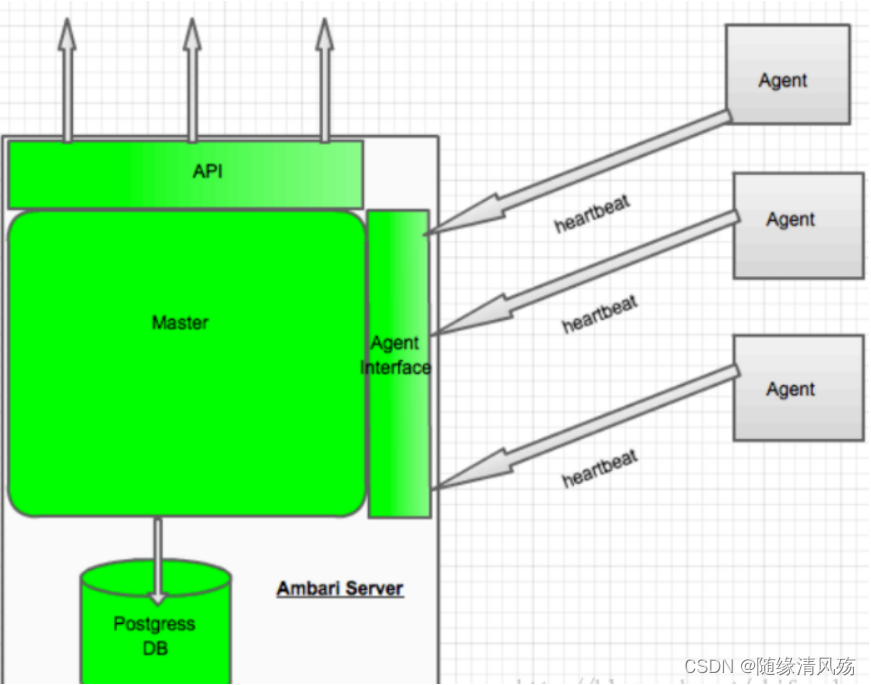
在ambari-server开放的REST API主要分为两大类API,其中一类为 ambari-web提供监控管理服务,另一类用于与ambari-agent交互,接受ambari-agent向ambari-server发送心跳请求。
①Matser模块:接收API和 AgentInterface的请求,完成ambari-server的集中式管理监控逻辑。
②Agent节点:只负责在所在节点的状态采集和维护工作。
(2)详细组成
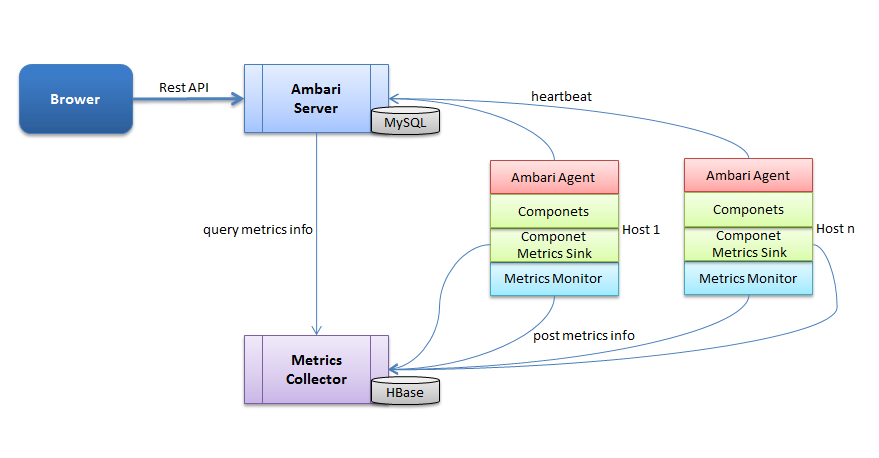
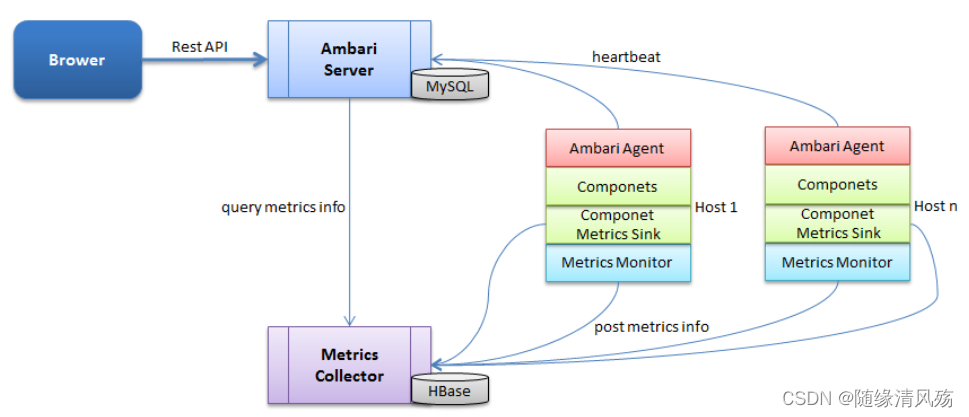
- 主要组成 - 四个部分
①Brower:指的是前端,前端通过 HTTP 发送 Rest 指令和 Ambari Server 进行交互。
②Ambari Server:是一个 web 服务器,开放两个端口,分别用来和前端、Agent 进行交互。从图中也可以看出,Ambari Server 的数据存储在 MySQL 中。
③Metrics Collector:是一个 web 服务器,提供两个功能,一方面将 Metrics Monitor 和 Metrics Sink 汇报上来的监控信息存储到 HBase 中,另一方面提供监控信息查询接口,供 Ambari Server 进行查询。
④Host:实际安装大数据服务的主机,可以有多台。从图中可以看出,每台主机都安装有一个 Ambari Agent 服务和 Metrics Monitor 服务,有些组件如果需要更详细和特有的监控信息,可以集成相对应的 Metrics Sink(比如HDFS的 Metrics Sink 可以监控空间的使用情况)。
1.4、Ambari-Server架构图
(1)工作流程
Ambari Server 和 Ambari Agent 之间是通过短连接进行通信,所以 Server 无法把需要执行的命令,直接推送给相应的 Agent,所以需要 ActionQueue 来存储命令,然后通过 Heartbeat 把命令下发给 Agent 执行。
①Ambarii-Server对外提供ambari web,rest api,ambari shell三大方式操作机群;
②ambari将集群的配置、各个服务的配置等信息存在ambari server端的DB中(比如可以是postgresql);
③ambari server与ambari agent的交流走RPC,即agent向server报告心跳,server将command通过respons发回给agent,agent本地执行命令,比如:agent端执行相应的python脚本;
④ambari有自己的一套监控、告警、镜像服务,以可插拔的形式供上层服务调用;
(2)内部架构
Ambari-server的Heartbeat Handler模块用于接收各个agent的心跳请求(心跳请求里面主要包含两类信息:节点状态信息和返回的操作结果),把节点状态信息传递给FSM状态机去维护着该节点的状态,并且把返回的操作结果信息返回给Action Manager去做进一步的处理。
(1)Live Cluster State:集群现有状态,各个节点汇报上来的状态信息会更改该状态;
(2)Desired State:用户希望该节点所处状态,是用户在页面进行了一系列的操作,需要更改某些服务的状态,这些状态还没有在节点上产生作用;
(3)Action State:操作状态,是状态改变时的请求状态,也可以看作是一种中间状态,这种状态可以辅助LiveCluster State向Desired State状态转变。
1.5、Ambari-Agent架构图
(1)工作流程
①HeartBeatHandler:收集组件当前状态(通过ResultMap)、Command 执行结果(通过ResultMap)、Alert 检查结果(通过 AlertCollect)等,封装到 HTTP Request 当中,发送给 Ambari Server;Ambari Server 响应请求,通过 HTTP Response 带回来需要执行的 Command、需要终止的 Command、发生修改的 Config、发生修改的 Alert 定义等**,并把 Comand 和 修改的 Config 封装为 Agent Command 对象,存储到 CommandQueue 中**;把修改的 Alert 定义,更新到 Alert definitions 文件中(如果 Alert definitions 文件发生了变化,需要通知 AlertSchedulerHandler 重新加载一遍
②ActionExecutor:定期从 CommandQueue 中加载需要执行的 Command,找到 Command 对应的 Python 脚本,执行脚本,并把结果存储到 ResultMap 中。
③AlertSchedulerHandler:从 Alert definitions 文件中加载所有 Alert 定义,根据 Alert 定义,找到对应的 Python 脚本,周期性执行,并把结果存储到 AlertCollect 中。
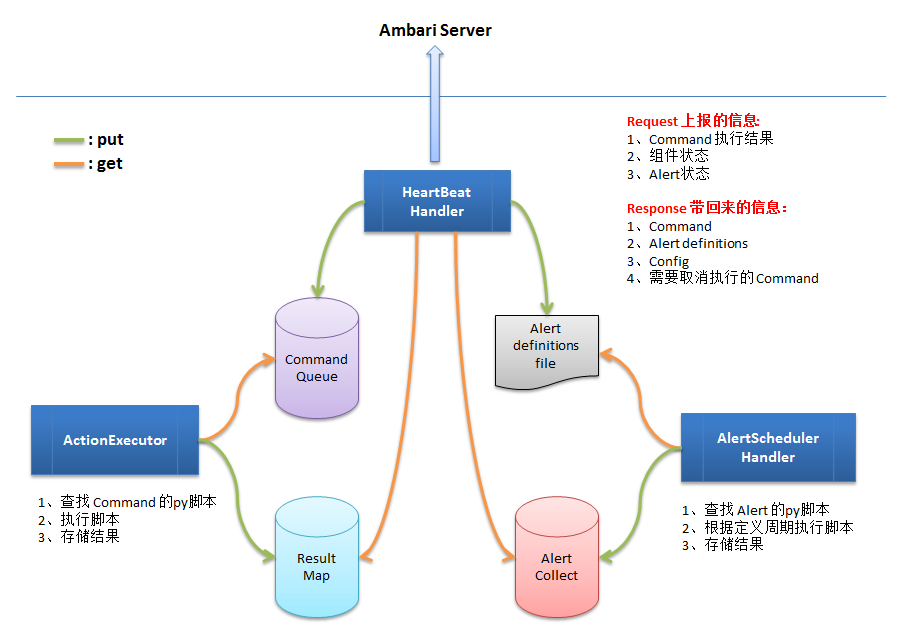
- 4个数据容器:
- CommandQueue:存储需要执行的 Command。
- ResultMap:存储 Command 的执行结果。
- Alert definitions file:是一个文件,保存所有的 Alert 定义。
- AlertCollect:存储 Alert 的检查结果。
(2)内部架构
Ambari-agent是一个无状态的,其功能分两部分:
①采集所在节点的信息并且汇总发送心跳发送汇报给ambari-server。
②处理ambari-server的执行请求。
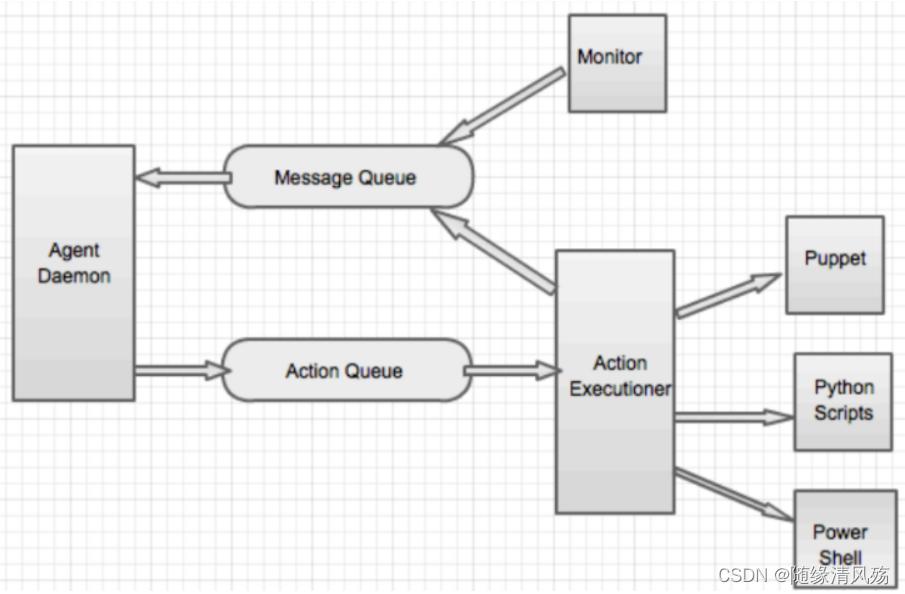
- 两个消息队列
- 消息队列Message Queu:包括节点状态信息(包括注册信息)和执行结果信息,并且汇总后通过心跳发送给ambari-server。
- 操作队列ActionQueue:用于接收ambari-server发送过来的状态操作,然后交给执行器调用puppet或Python脚本等模块执行任务。
2、Ambari源码剖析
2.1、设计思想-资源抽象
(1)第一层抽象:资源
在Ambari中一切皆是资源,包括服务、组件、机器都是资源,其中一个Service由多个ServiceComponent构成,一个ServiceCompoent又是由多个ServiceComponentHost构成,比如:
①Service:HDFS、Yarn、Hbase
②ServiceCompoent:HDFS.NameNode、YARN.ResourceManager
③ServiceComponentHost: HDFS.NameNode.HostA,、YARN.ResourceManager.HostB
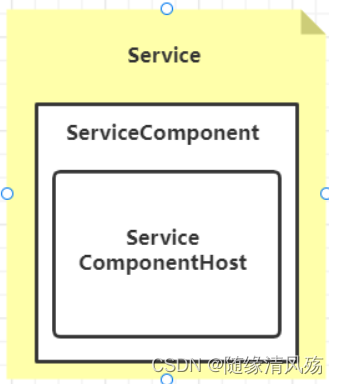
上面的Service、ServiceComponent、ServiceComponentHost都是资源的一种类型,在Ambari中,有多达74种类型(Ambari2.0.0版本)的不一样资源(Resource),每一种类型都有相应的XXXResourceProvider提供相应的操做接口,好比ClusterResourceProvider,又经过XXXService来暴露相应资源的REST API,好比ClusterService。
(2)资源相关概念
- Resource Service:资源服务,用来接收前端的 Rest 请求。关于 Resource 的几个基本概念:

①Resource:Ambari Server 定义了各种各样的 Resource,比如 Config、User、Cluster、
Component、Alert 等都是一种 Resource。
②Resource Type:每种 Resource 都对应一个 ResourceType,标记所属的资源类型。
③Resource Service:每种 Resource 都对应一个 Resource Service,比如ConfigService、UserService等,Service 中定义了相对应 Resource 的 Rest API。
④Resource Provider:每种 Resource 都对应一个 ResourceProvider,比如ConfigResourceProvider、UserResourceProvider等,对 Resource 的具体操作,都封装在 Provider 中。
(3)第二层抽象:对资源的操作
- 核心:以上三种资源对应三种操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f36gf6Sl-1666534684691)(C:\Users\lihw\Desktop\数据架构师\AMBARI二次开发环境搭建.assets\image-20220815105714660.png)]
①Operation: Service层面的操做(Install/Start/Stop/Config),一个Operation能够做用于一个或多个Service;
②Stage: ServicesComponent层面的操做,根据不一样ServicesComponent操做间的依赖关系,一个Operation的全部Task可能被划分红多个Stage,一个Stage内的多个Task相互没有依赖,能够并行执行;
③Task: ServiceComponentHost层面的操做,为了完成一个Operation,须要为不一样的机器分配一系列的Task去执行;
- 注意事项:关于操作执行顺序
- Ⅰ、不一样的Stage只能顺序执行。后面的Stage只有在前面Stage执行成功后才会下发给Agent。若是前面Stage失败,后面的Stage将取消;
- Ⅱ、同一个Stage内的多个Task能够并行执行,能够同时下发给Agent,若是某个Task失败,其余的已下发且正执行的Task将被取消;
- Ⅲ、分配给同一个机器的不一样Task只会顺序执行;
2.2、源码基础概念
(1)基本概念
①Resource:Ambari把能够被管理的资源的抽象为一个Resource实例,资源能够包括服务、组件、主机节点等,一个resource实例中包括了一系列该资源的属性;
②Property:服务组件的指标名称;
③ResourceProvider和PropertyProvider分别相应Resource和Property的提供方,获取指标须要先获取Resource,然后获取Property相应的metric;
④Query:Query是Resource的内部对象,代表了对该资源的操作;
⑤Request:一个Request代表了对Resource的操作请求,包括http信息及要操作的Resource的实例,Request依照http的请求方式分为四种:GET、PUT、DELETE、POST;
⑥Predicate:一个Predicate代表了一系列表达式,如and、or等;
(2)基本组件
①Ambari-server:提供 REST 接口给Agent 和 Web 访问。
②Ambari-agent:在集群的每一台机器上都会部署 Ambari-agent 程序。 Agent 主要负责接收来着 Server 端的命令, 这些命令可以是安装、启动、停止 Hadoop 集群上的某一服务。同时, agent 端需要向 Ambari-server 端上报命令执行的结果,是执行成功还是失败。
③Ambari-web:
④Ambari-metrics-collector:接收集群中组件 metrics 的模块。
⑤Ambari-metrics-monitor :接收集群中组件 metrics 的模块。
2.3、源码项目模块
- 项目模块总体架构
- 整体项目模块如下
| 模块内容 | 模块描述 | 备注 |
|---|---|---|
| ambari-server | Ambari的Server程序,主要管理部署在每个节点上的管理监控程序 | |
| Ambari-agent | 部署在监控节点上运行的管理监控程序 | |
| ambari-common | Ambari-server 和Ambari-agent 共用的代码 | |
| ambari-web | Ambari页面UI的代码,作为用户与Ambari server交互的 | 汉化工作 |
| ambari-views | 用于扩展Ambari Web UI中的框架 | |
| ambari-metrics | 在Ambari所管理的集群中用来收集、聚合和服务Hadoop和系统度量 | |
| ambari-utility | 工具类 | |
| Contrib | 自定义第三方库 | |
| Docs | 文档 | 工程文档 |
2.4、服务端源码剖析
- 核心:服务端主要包含三部分,包括Ambari-web模块、Ambari-server模块、Ambari-metrics模块。
(1)Ambari-web模块
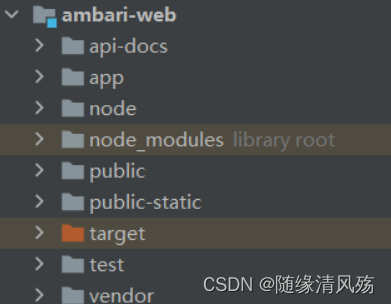
Ambari-Web模块采用前后端分离的思路与服务端进行rest交互,是基于ember.js的纯前端mvc代码,前端核心代码如下:
a.route确定路由跳转到特定的template;
b. 每个template有对应的controller;
c. 同时在models下定义ember中所谓的data;
e. controller里与服务端交互,获取JSON数据后经过mapper处理更新data;
f. 模板里UI效果的更新取决于这些data数据;
(2)Ambari-server模块
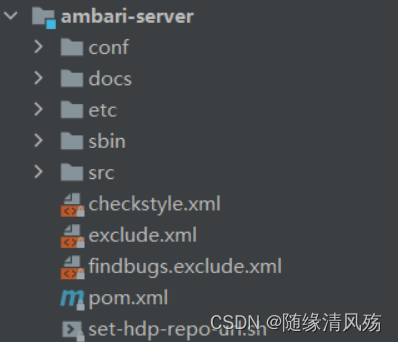
Ambari-server核心的服务端代码由java编写, 实际打包后为各个平台的安装包,如rpm或deb,由python脚本启动jar主程序;
(3)Ambari-metrics模块
Ambari-metrics模块是独立部署的,主类继承org.apache.hadoop.service.CompositeService; 主要接收metric推送,存储是基于hbase,提供各种聚合能力(如月、日、周、小时等)。
3、自定义服务文件剖析
3.1、Stacks & Service
(1)Stacks
Stack为一系列service的集合。可以在Ambari中定义多个不同版本的stacks。比如HDP3.1为一个stack,可以包含Hadoop, Spark等等多个特定版本的service。
- Stack目录如下
(2)Service
- 核心:单个集群服务,包括Zookeeper、HDFS、Yarn等
单个Service下通过配置Service下存储的metainfo.xml来设置构成服务的component(组件)以及部署组件的部署脚本、运行组件的角色名称、部署脚本的文件名称、部署脚本的语言种类等信息。如果多个stacks需要使用相同的service配置,需要将配置放置于common-services中。common-services目录中存放的内容可供任意版本的stack直接使用或继承。

- Service组成部分说明
| 组成部分 | 组成说明 | 备注 |
|---|---|---|
| Service ID | 通常为大写,为Service名称 | |
| configuration | 存放了service对应的配置文件 | 即service的图形化配置页面的配置文件,配置该页面包含什么配置项 |
| package | 主要问控制service生命周期的python文件 | |
| alert.json | service的告警信息定义 | |
| kerberos.json | service和Kerberos结合使用的配置信息 | |
| metainfo.xml | 定义service的名称,版本号,简介和控制脚本名称等等信息 | service最为重要的配置文件。 |
| metrics.json | service的监控信息配置文件 | Widget 也就是 Ambari Web 中呈现 Metrics 的图控件,根据Metrics数值做简单的聚合运算 |
| widgets.json | service的监控图形界面展示配置 | 显示 AMS 收集的 Metrics 属性 |
3.2、metainfo.xml详解
①公共部分
<?xml version="1.0"?>
<metainfo>
<schemaVersion>2.0</schemaVersion>
<services>
<!-->自定义服务相关信息<-->
</services>
</metainfo>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
②service - 描述服务
<!-->Ⅰ、name: 服务名,必须唯一,建议大写<-->
<name>HDFS</name>
<!-->Ⅱ、displayName: 服务在 web UI 上的显示名<-->
<displayName>HDFS</displayName>
<!-->Ⅱ、serviceType: <-->
<serviceType>HDFS</serviceType>
<!-->Ⅲ、comment: 服务的描述信息<-->
<comment>Apache Hadoop Distributed File System</comment>
<!-->Ⅳ、version: 服务版本, 用 name 和 version 唯一标记一个服务<-->
<version>1.14.5</version>
<!-->Ⅴ、components: 服务中包含的组件<-->
<components>
<component>
<name>FLINK_MASTER</name>
<displayName>Flink</displayName>
<category>MASTER</category>
<cardinality>1</cardinality>
<commandScript>
<script>scripts/flink.py</script>
<scriptType>PYTHON</scriptType>
<timeout>10000</timeout>
</commandScript>
</component>
</components>
<!-->Ⅵ、osSpecifics: 服务会根据操作系统的差异来选择不同的 rpm 包<-->
<osSpecifics>
<osSpecific>
<osFamily>redhat7,redhat6</osFamily>
<packages>
<package><name>git</name></package>
<package><name>java-1.7.0-openjdk-devel</name></package>
<package><name>apache-maven-3.2*</name></package>
</packages>
</osSpecific>
</osSpecifics>
<!-->Ⅶ、configuration-dependencie: 服务依赖的 xml 文件<-->
<configuration-dependencies>
<config-type>flink-ambari-config</config-type>
</configuration-dependencies>
<!-->Ⅷ、restartRequiredAfterChange: 服务更改后是否强制重启<-->
<restartRequiredAfterChange>false</restartRequiredAfterChange>
<!-->Ⅸ、requiredServices: 集群上强制依赖的其他服务<-->
<requiredServices>
<service>YARN</service>
</requiredServices>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 参数说明如下
| 属性 | 描述 |
|---|---|
| name | 服务名,必须唯一,建议大写 |
| displayName | 服务在 web UI 上的显示名 |
| comment | 服务的描述信息 |
| version | 服务版本,用 name 和 version 唯一标记一个服务 |
| components | 服务中包含的组件 |
| commandScript(可选) | 自定义命令 python 脚本入口,如果一个 Service 的 metainfo.xml 有该字段,那么在 Service 的 Action 列表中就会出现 自定义 命令。 |
| requiredServices:(可选) | 集群上强制依赖的其他服务。换句话说,安装当前服务之前,必须安装 requiredServices 内指定的服务。 |
| configuration-dependencies(可选) | 服务依赖的 xml 文件,当在前端页面上修改 xml 文件内容后并保存配置,服务会提示重启,服务下的所有组件都将被重启。 |
| quickLinksConfigurations(可选) | 自定义快速链接,通常在这里设置 服务 web UI 链接。 |
| osSpecifics(可选) | 服务会根据操作系统的差异来选择不同的 rpm 包 |
| themes(可选) | 指定主题配置,通常和 json 文件相关联。 |
- 文件结果展示