
- 1Spring Boot 中三种跨域场景总结,这篇必看!不看后悔系列_跨域问题场景
- 2ubuntu18.04系统下androidstudio启动模拟器发生错误: /dev/kvm device:permission denied_ubuntu android studio (permission denied)
- 3Git The requested URL returned error: 403,Token authentication requirements for Git operations
- 4内部排序—归并排序_归并排序内部用的什么排序
- 5graphics.h头文件_C语言图形(graphics.h头文件功能和示例)
- 6SwiftUI如何在动画完成时得到通知_swiftui withanimation结束
- 7yolov5 deepsort 行人/车辆(检测 +计数+跟踪+测距+测速)_yolov5测车辆速度
- 8Android布局属性大全
- 9miui删除内置不卡米教程_小米MIUI免root一键删除系统内置软件!!
- 10小白宝塔建站教程(1):CentOS7安装宝塔面板详细步骤_centos7 宝塔安装
【机器学习】科学库使用第5篇:Matplotlib,学习目标【附代码文档】
赞
踩

机器学习(科学计算库)完整教程(附代码资料)主要内容讲述:机器学习(常用科学计算库的使用)基础定位、目标,机器学习概述定位,目标,学习目标,学习目标,1 人工智能应用场景,2 人工智能小案例。机器学习概述,1.5 机器学习算法分类学习目标,学习目标,1 监督学习,2 无监督学习,3 半监督学习,4 强化学习。机器学习概述,1.7 Azure机器学习模型搭建实验学习目标,学习目标,Azure平台简介,学习目标,1 深度学习 —— 神经网络简介,2 深度学习各层负责内容。Matplotlib,3.2 基础绘图功能 — 以折线图为例学习目标,学习目标,1 完善原始折线图 — 给图形添加辅助功能,2 在一个坐标系中绘制多个图像,3 多个坐标系显示— plt.subplots(面向对象的画图方法),4 折线图的应用场景。Matplotlib,3.3 常见图形绘制学习目标,学习目标,1 常见图形种类及意义,2 散点图绘制,3 柱状图绘制,4 小结。Numpy,4.2 N维数组-ndarray学习目标,学习目标,1 ndarray的属性,2 ndarray的形状,3 ndarray的类型,4 总结。Numpy,4.4 ndarray运算学习目标,学习目标,问题,1 逻辑运算,2 通用判断函数,3 np.where(三元运算符)。Pandas,5.1Pandas介绍学习目标,学习目标,1 Pandas介绍,2 为什么使用Pandas,3 小结,学习目标。Pandas,5.3 基本数据操作学习目标,学习目标,1 索引操作,2 赋值操作,3 排序,4 总结。Pandas,5.6 文件读取与存储学习目标,学习目标,1 CSV,2 HDF5,3 JSON,4 小结。Pandas,5.8 高级处理-数据离散化学习目标,学习目标,1 为什么要离散化,2 什么是数据的离散化,3 股票的涨跌幅离散化,4 小结。Pandas,5.12 案例学习目标,学习目标,1 需求,2 实现,1.独立同分布(i.i.d.),2.简单解释 — 独立、同分布、独立同分布。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
全套教程部分目录:


部分文件图片:
Matplotlib
学习目标
- 应用Matplotlib的基本功能实现图形显示
- 应用Matplotlib实现多图显示
- 应用Matplotlib实现不同画图种类
3.3 常见图形绘制
学习目标
-
目标
-
掌握常见统计图及其意义
Matplotlib能够绘制折线图、散点图、柱状图、直方图、饼图。
我们需要知道不同的统计图的意义,以此来决定选择哪种统计图来呈现我们的数据。
1 常见图形种类及意义
- 折线图:以折线的上升或下降来表示统计数量的增减变化的统计图
特点:能够显示数据的变化趋势,反映事物的变化情况。(变化)
api:plt.plot(x, y)

- 散点图:用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
api:plt.scatter(x, y)

- 柱状图:排列在工作表的列或行中的数据可以绘制到柱状图中。
特点:绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
api:plt.bar(x, width, align='center', **kwargs)
Parameters:
x : 需要传递的数据
width : 柱状图的宽度
align : 每个柱状图的位置对齐方式
{‘center’, ‘edge’}, optional, default: ‘center’
**kwargs :
color:选择柱状图的颜色
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
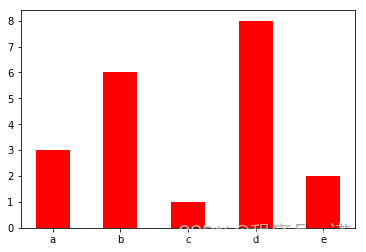
- 直方图:由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据范围,纵轴表示分布情况。
特点:绘制连续性的数据展示一组或者多组数据的分布状况(统计)
api:matplotlib.pyplot.hist(x, bins=None)
Parameters:
x : 需要传递的数据
bins : 组距
- 1
- 2
- 3

- 饼图:用于表示不同分类的占比情况,通过弧度大小来对比各种分类。
特点:分类数据的占比情况(占比)
api:plt.pie(x, labels=,autopct=,colors)
Parameters:
x:数量,自动算百分比
labels:每部分名称
autopct:占比显示指定%1.2f%%
colors:每部分颜色
- 1
- 2
- 3
- 4
- 5

2 散点图绘制
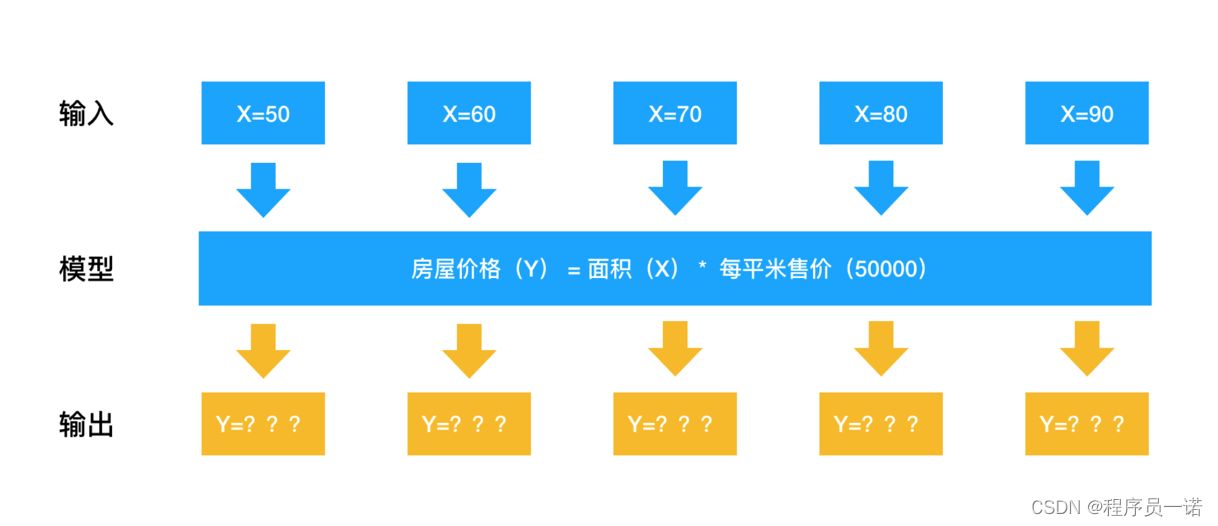
需求:探究房屋面积和房屋价格的关系
房屋面积数据:
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9 , 53.06, 224.72, 29.51,
21.61, 483.21, 245.25, 399.25, 343.35]
- 1
- 2
- 3
房屋价格数据:
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9 , 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1 ,
30.74, 400.02, 205.35, 330.64, 283.45]
- 1
- 2
- 3

代码:
# 0.准备数据 x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64, 163.56, 120.06, 207.83, 342.75, 147.9 , 53.06, 224.72, 29.51, 21.61, 483.21, 245.25, 399.25, 343.35] y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9 , 239.34, 140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1 , 30.74, 400.02, 205.35, 330.64, 283.45] # 1.创建画布 plt.figure(figsize=(20, 8), dpi=100) # 2.绘制散点图 plt.scatter(x, y) # 3.显示图像 plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3 柱状图绘制
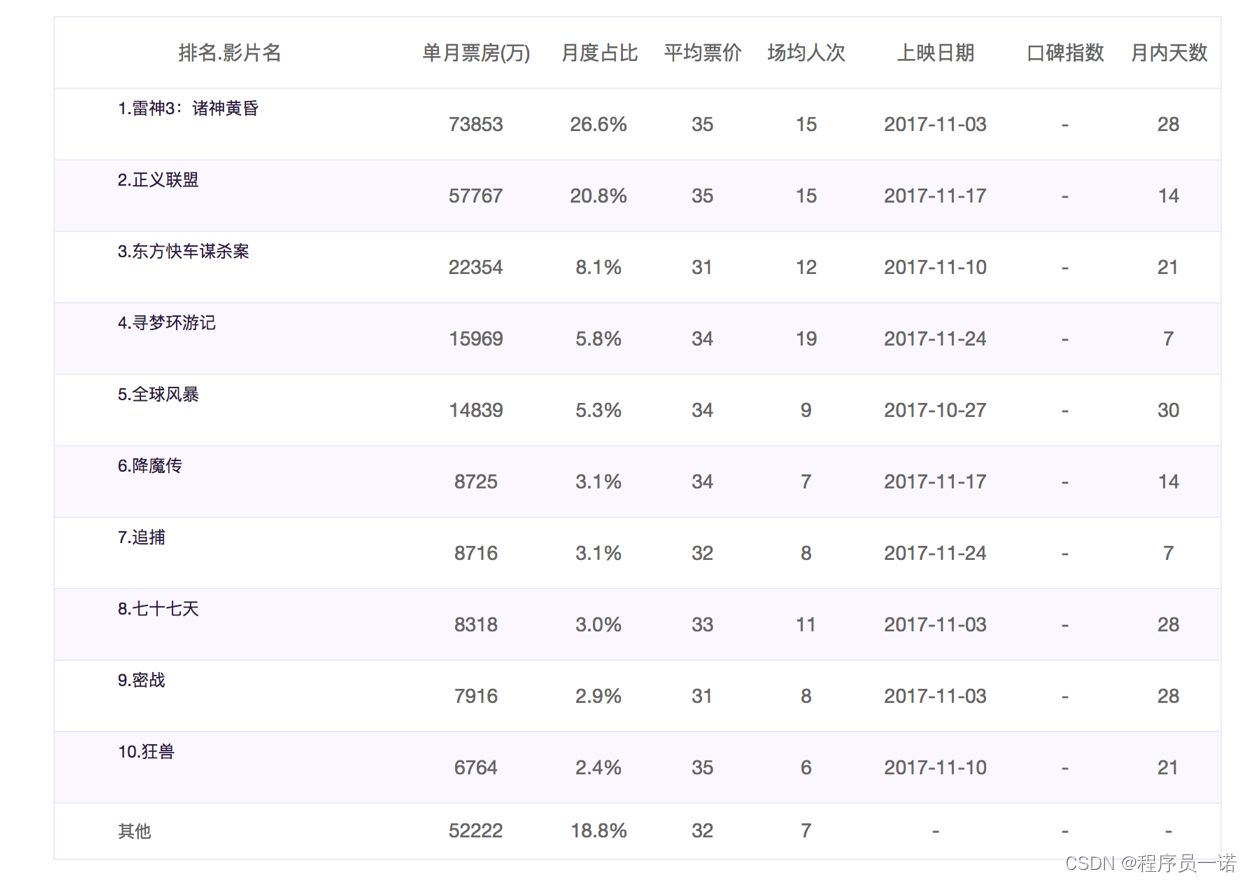
需求-对比每部电影的票房收入

电影数据如下图所示:
- 准备数据
['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴', '降魔传','追捕','七十七天','密战','狂兽','其它']
[73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222]
- 1
- 2
- 绘制柱状图
代码:
# 0.准备数据 # 电影名字 movie_name = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','降魔传','追捕','七十七天','密战','狂兽','其它'] # 横坐标 x = range(len(movie_name)) # 票房数据 y = [73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222] # 1.创建画布 plt.figure(figsize=(20, 8), dpi=100) # 2.绘制柱状图 plt.bar(x, y, width=0.5, color=['b','r','g','y','c','m','y','k','c','g','b']) # 2.1b修改x轴的刻度显示 plt.xticks(x, movie_name) # 2.2 添加网格显示 plt.grid(linestyle="--", alpha=0.5) # 2.3 添加标题 plt.title("电影票房收入对比") # 3.显示图像 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
参考链接:
[
4 小结
-
折线图【知道】
-
能够显示数据的变化趋势,反映事物的变化情况。(变化)
-
plt.plot()
-
散点图【知道】
-
判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
-
plt.scatter()
-
柱状图【知道】
-
绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
-
plt.bar(x, width, align="center")
-
直方图【知道】
-
绘制连续性的数据展示一组或者多组数据的分布状况(统计)
-
plt.hist(x, bins)
-
饼图【知道】
-
用于表示不同分类的占比情况,通过弧度大小来对比各种分类
- plt.pie(x, labels, autopct, colors)
Numpy
学习目标
- 了解Numpy运算速度上的优势
- 知道数组的属性,形状、类型
- 应用Numpy实现数组的基本操作
- 应用随机数组的创建实现正态分布应用
- 应用Numpy实现数组的逻辑运算
- 应用Numpy实现数组的统计运算
- 应用Numpy实现数组之间的运算
4.1 Numpy优势
学习目标
-
目标
-
了解Numpy运算速度上的优势
- 知道Numpy的数组内存块风格
- 知道Numpy的并行化运算
1 Numpy介绍

Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
2 ndarray介绍
NumPy provides an N-dimensional array type, the ndarray,
which describes a collection of “items” of the same type.
- 1
- 2
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
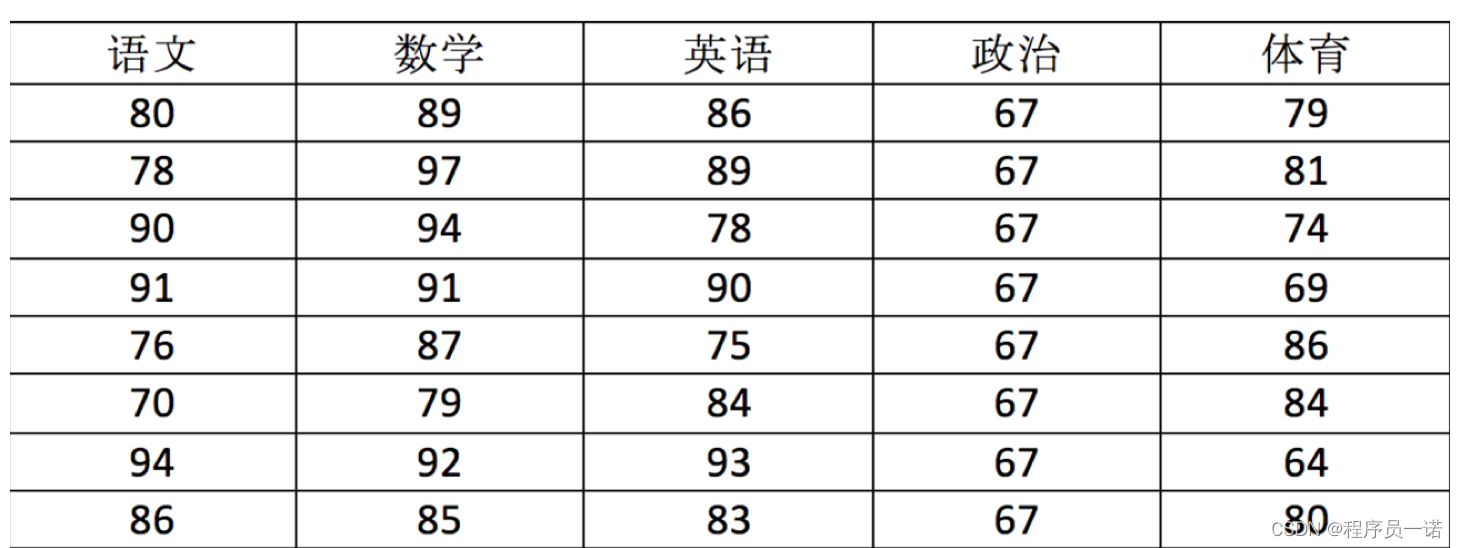
用ndarray进行存储:
import numpy as np # 创建ndarray score = np.array( [[80, 89, 86, 67, 79], [78, 97, 89, 67, 81], [90, 94, 78, 67, 74], [91, 91, 90, 67, 69], [76, 87, 75, 67, 86], [70, 79, 84, 67, 84], [94, 92, 93, 67, 64], [86, 85, 83, 67, 80]]) score
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
返回结果:
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
提问:
使用Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组,那么为什么还需要使用Numpy的ndarray呢?
3 ndarray与Python原生list运算效率对比
在这里我们通过一段代码运行来体会到ndarray的好处
import random import time import numpy as np a = [] for i in range(100000000): a.append(random.random()) # 通过%time魔法方法, 查看当前行的代码运行一次所花费的时间 %time sum1=sum(a) b=np.array(a) %time sum2=np.sum(b)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
其中第一个时间显示的是使用原生Python计算时间,第二个内容是使用numpy计算时间:
CPU times: user 852 ms, sys: 262 ms, total: 1.11 s
Wall time: 1.13 s
CPU times: user 133 ms, sys: 653 µs, total: 133 ms
Wall time: 134 ms
- 1
- 2
- 3
- 4
从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。
Numpy专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,Numpy的优势就越明显。
思考:
ndarray为什么可以这么快?
4 ndarray的优势
4.1 内存块风格
ndarray到底跟原生python列表有什么不同呢,请看一张图:
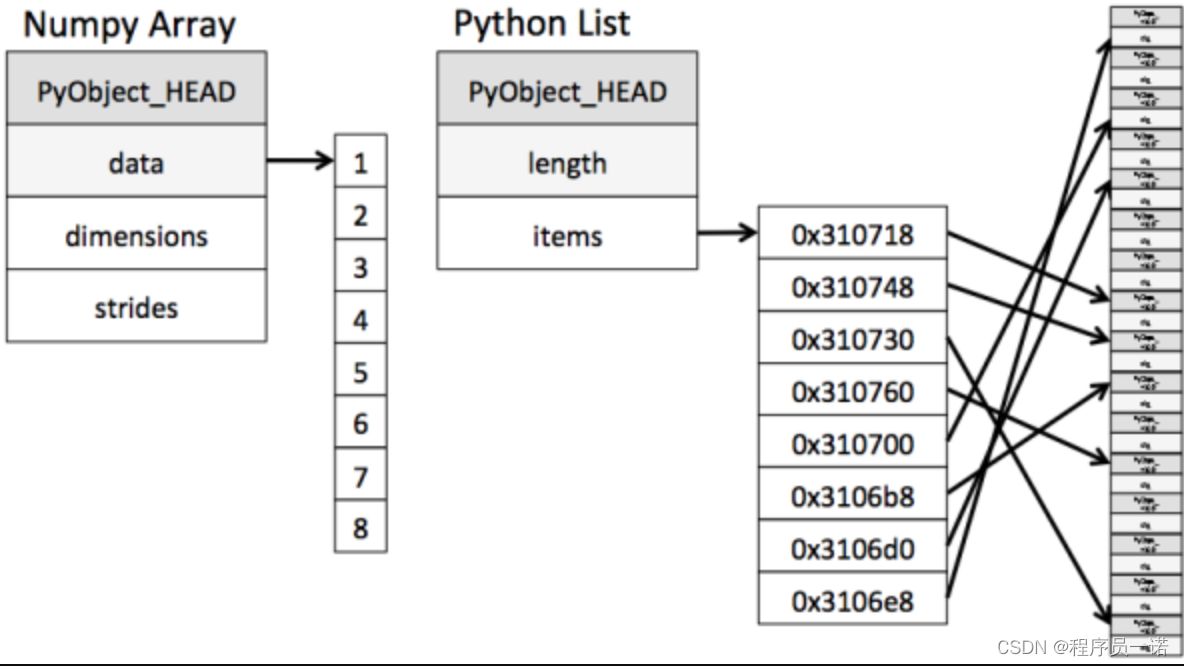
从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
4.2 ndarray支持并行化运算(向量化运算)
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
4.3 效率远高于纯Python代码
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,所以,其效率远高于纯Python代码。
5 小结
-
numpy介绍【了解】
-
一个开源的Python科学计算库
- 计算起来要比python简洁高效
-
Numpy使用ndarray对象来处理多维数组
-
ndarray介绍【了解】
-
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
-
生成numpy对象:np.array()
-
ndarray的优势【掌握】
-
内存块风格
- list -- 分离式存储,存储内容多样化
- ndarray -- 一体式存储,存储类型必须一样
-
ndarray支持并行化运算(向量化运算)
- ndarray底层是用C语言写的,效率更高,释放了GIL

