
热门标签
热门文章
- 1NodeJS常见报错_the node.js path can contain
- 2gitcode 上传文件报错文件太大has exceeded the upper limited size
- 3玄子Share-计算机网络参考模型
- 4牛客:C++工程师面试宝典:第二章:基础知识:2.1:基础语言(一)_牛客c++面试宝典
- 5GitHub开源项目权限管理-使用账号和个人令牌访问_gitlub如何开启允许令牌登陆
- 6【安全】web中的常见编码&;浅析浏览器解析机制_web网站码源(1)_浏览器编码
- 7Unity微信小游戏登录授权获取用户信息_unity createuserinfobutton
- 8使用cmd命令行打开MySQL数据库_cmd打开mysql
- 9RabbitMQ配置属性表_rabbitmq表
- 10oracle zfs storage zs3-4,「服务器、工作站」全新原包Oracle ZFS Storage ZS4-4 Appliance-深圳市惟思华-马可波罗网...
当前位置: article > 正文
基于FPGA的VGG16卷积神经网络加速器--WL_在fpga上实现卷积神经网络
作者:你好赵伟 | 2024-04-23 11:56:27
赞
踩
在fpga上实现卷积神经网络
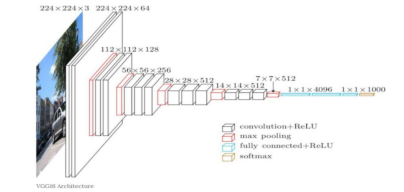
VGG16是一个典型的卷积神经网络,由13层卷积层,5层池化层和3层全连接层组成。且卷积层的计算时间在整个计算过程中占比极大,通过FPGA的并行运算可以有效的加快卷积层的计算速度。
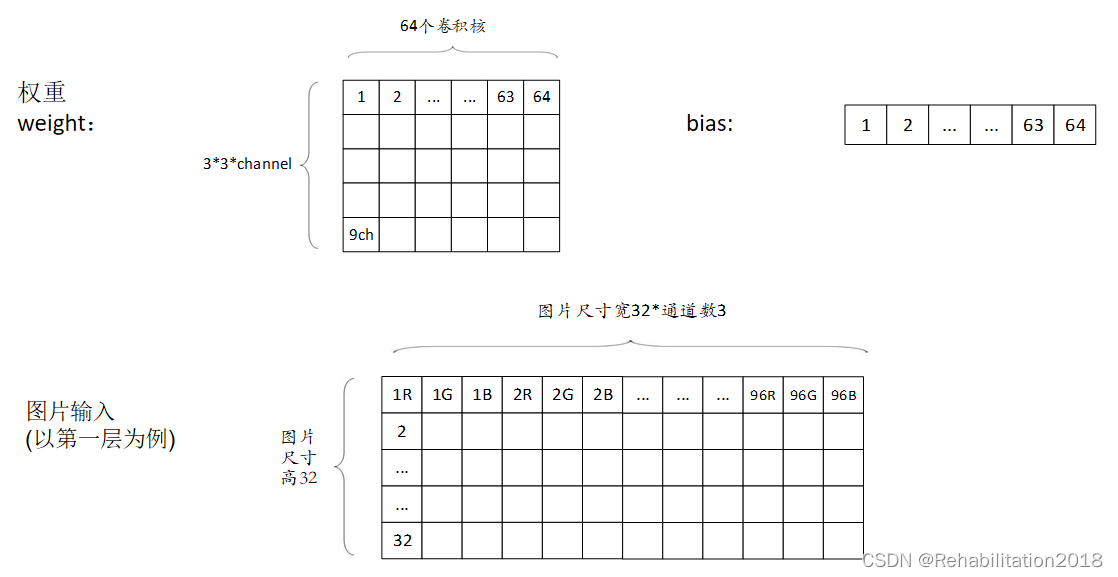
一个卷积层可以有若干个卷积核,以第一层为例,该层对应的卷积核为64个3×3×3的卷积核,3×3是卷积核的尺寸,相当于将1个卷积核也按照RGB 分成3份(卷积核的通道数=输入图片的通道数),对其进行卷积也就是乘加运算。
以尺寸为7×7的3通道图片与2个3×3的3通道卷积核为例
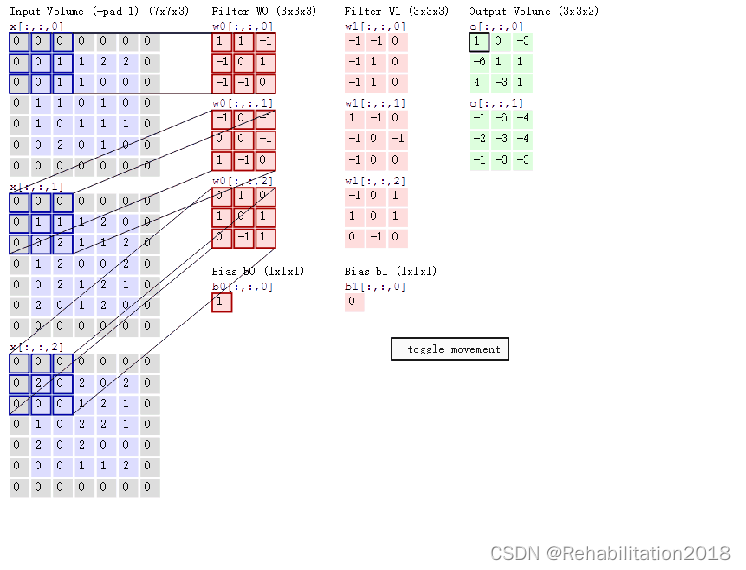
采用SoPC(ARM+FPGA),通过C语言将数据放置在片外SDRAM中,并向硬件中的卷积状态机传输地址,通道数,卷积核数等参数和一个卷积使能信号。通过FPGA来进行卷积运算。
第一层的数据在SDRAM中的排列顺序如下:
硬件架构如下图,卷积状态机conv_state控制全部的计算过程,当PE单元完成1次计算并输出后,状态机控制DMA加载数据继续计算,直至全部完成。

卷积层第一二层的计算
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/473780
推荐阅读
相关标签

