
- 1c语言多字符和宽字符,2.1.5 多字节字符和宽字符
- 2RabbitMQ中动态创建队列和监听_rabbitmq动态创建队列
- 3前端开发者必备的代码开源平台,记得收藏转发!_前端开元代码库
- 42023年,总要干点不一样的事情_专访朱少民
- 5Oracle中表的连接及其调整
- 6Qt 三维柱状图 Q3DBar 和 三维条形图中的数据序列 QBar3DSeries_q3dbars 重
- 7Android studio 护眼模式配置、字体大小设置、内存大小设置等各类疑难杂症_android studio设置内存大小
- 8十五分钟带你学会 Electron_electron 教程 百度网盘
- 9《大数据分析技术》教学上机实验报告_大数据 上机操作
- 10【北邮国院大四上】Business Technology Strategy 企业技术战略
Elasticsearch:什么是自然语言处理(NLP)?_elasticsearch 自然语言
赞
踩
自然语言处理定义
自然语言处理 (natural language processing - NLP) 是人工智能 (AI) 的一种形式,专注于计算机和人们使用人类语言进行交互的方式。 NLP 技术帮助计算机使用我们的自然交流模式(语音和书面文本)来分析、理解和响应我们。
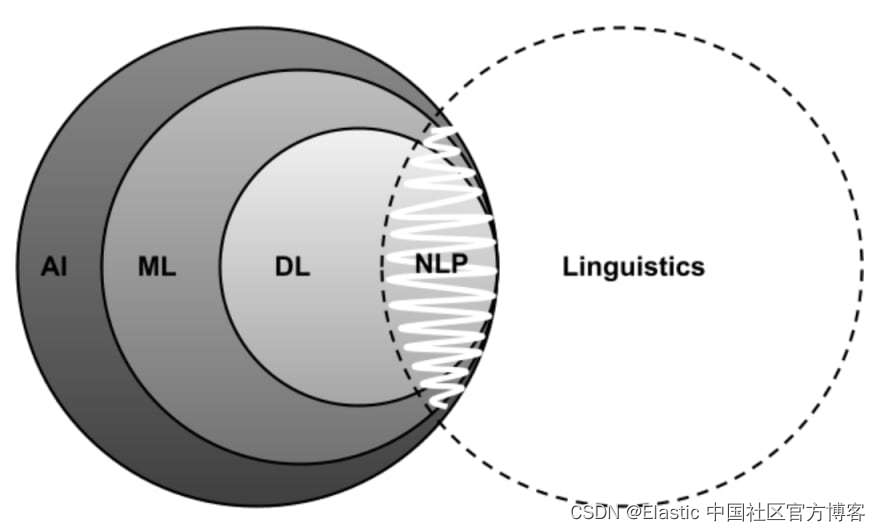
自然语言处理是计算语言学的一个子专业。 计算语言学是一个跨学科领域,结合了计算机科学、语言学和人工智能来研究人类语言的计算方面。
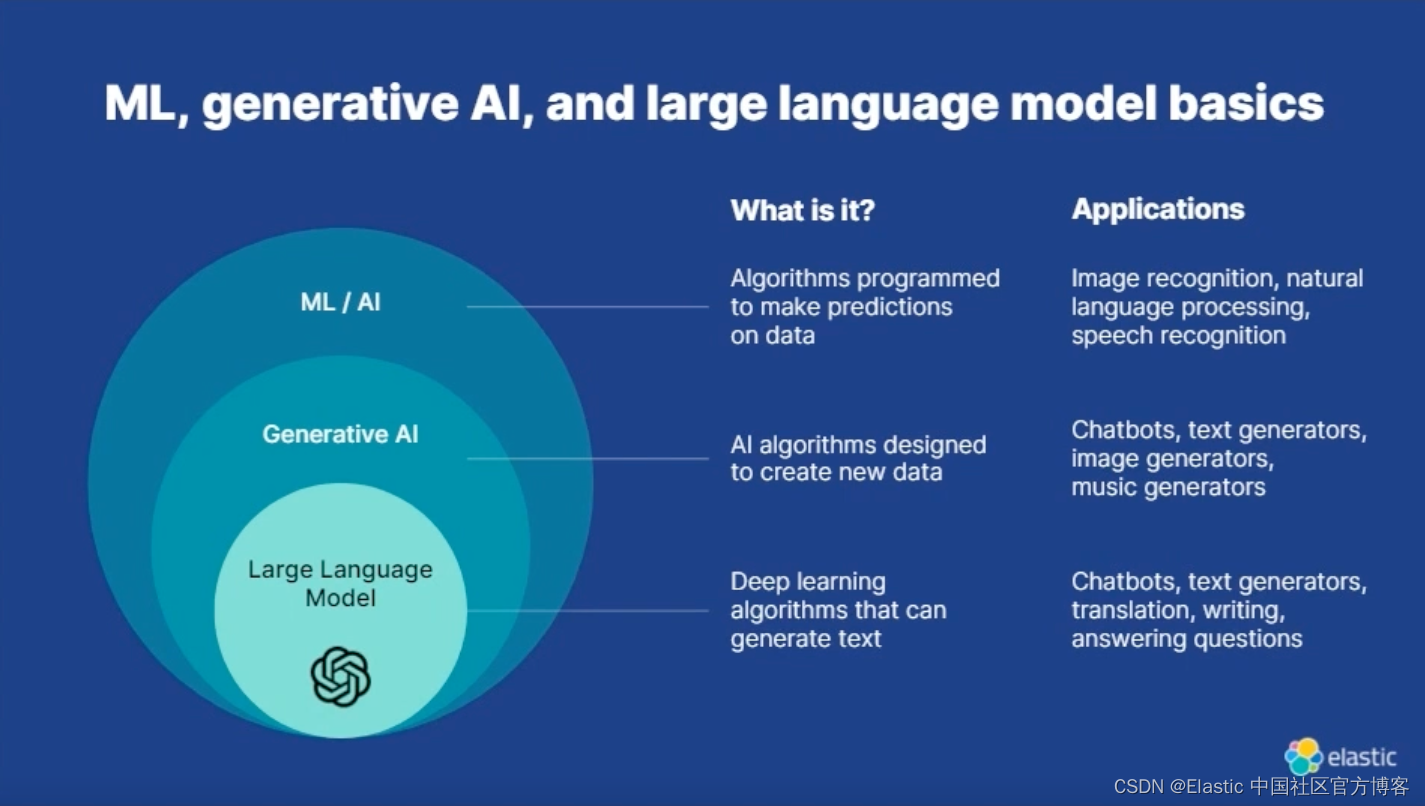
自然语言处理 (NLP) 的历史
自然语言处理的历史可以追溯到 20 世纪 50 年代,当时计算机科学家首次开始探索教会机器理解和产生人类语言的方法。 1950 年,数学家艾伦·图灵提出了他著名的图灵测试,将人类语音与机器生成的语音进行对比,看看哪个听起来更逼真。 这也是研究人员开始探索使用计算机翻译语言的可能性的时候。
在其研究的第一个十年中,NLP 依赖于基于规则的处理。 到 20 世纪 60 年代,科学家们开发出了利用语义分析、词性标记和句法分析来分析人类语言的新方法。 他们还开发了第一个语料库,这是大型机器可读文档,带有用于训练 NLP 算法的语言信息注释。
20 世纪 70 年代,科学家开始使用统计 NLP,它使用统计模型分析和生成自然语言文本,作为基于规则的方法的替代方案。
20 世纪 80 年代,人们开始关注开发更高效的算法来训练模型并提高其准确性。 这导致了 NLP 领域机器学习算法的兴起。 机器学习是使用大量数据来识别模式的过程,这些模式通常用于进行预测。
深度学习、神经网络和 Transformer 模型从根本上改变了 NLP 研究。 深度神经网络的出现结合 Transformer 模型和 “注意力机制 (attention mechanism)” 的发明,创造了 BERT 和 ChatGPT 等技术。 例如,注意力机制不仅仅是寻找与你的查询相似的关键字。 它根据每个连接术语的相关性来衡量其权重。 这是目前使用的一些最令人兴奋的 NLP 技术背后的技术。
自然语言处理是如何工作的?
自然语言处理以几种不同的方式工作。 基于人工智能的 NLP 涉及使用机器学习算法和技术来处理、理解和生成人类语言。 基于规则的 NLP 涉及创建一组可用于分析和生成语言数据的规则或模式。 统计 NLP 涉及使用从大型数据集导出的统计模型来分析和预测语言。 混合 NLP 结合了这三种方法。
基于人工智能的 NLP 方法如今最为流行。 与任何其他数据驱动的学习方法一样,开发 NLP 模型需要对文本数据进行预处理并仔细选择学习算法。
步骤一:数据预处理
这是清理和准备文本的过程,以便 NLP 算法可以对其进行分析。 一些常见的数据预处理技术包括文本挖掘(它获取大量文本并将其分解为数据)或标记化(将文本分割成单独的单元)。 这些单位可以是标点符号、单词或短语。 停用词删除是一种工具,可以消除对分析没有多大帮助的常见单词和言论文章。 词干提取和词形还原将单词分解为基本的词根形式,从而更容易识别其含义。 词性标记可识别句子中的名词、动词、形容词和其他词性。 句法分析分析句子的结构以及不同单词之间的关系。
步骤二:算法开发
这就是将NLP算法应用于预处理后的数据的过程。 它从文本中提取有用的信息。 以下是一些最常见的自然语言处理任务:
- 情感分析 (sentiment analysis) 确定一段文本的情感基调或情绪。 情感分析将单词、短语和表达标记为积极、消极或中性。
- 命名实体识别 (named entity recognition) 可识别命名实体并对其进行分类,例如人员、位置、日期和组织。
- 主题建模 (topic modeling) 将相似的单词和短语分组在一起,以识别文档或文本集合中的主要主题或主题。
- 机器翻译 (machine translation) 使用机器学习自动将文本从一种语言翻译成另一种语言。 语言建模预测特定上下文中单词序列的可能性。
- 语言建模 (language modeling) 用于自动完成、自动更正应用程序和语音转文本系统。
NLP 的两个值得注意的分支是自然语言理解(natural language understanding - NLU)和自然语言生成(natural language generation - NLG)。 NLU 致力于使计算机能够使用与人类使用的类似工具来理解人类语言。 它的目标是使计算机能够理解人类语言的细微差别,包括上下文、意图、情感和歧义。 NLG 专注于从数据库或一组规则创建类人语言。 NLG 的目标是生成人类易于理解的文本。
自然语言处理的好处
自然语言处理的一些好处包括:
- 沟通的提升:NLP 允许与搜索应用程序进行更自然的沟通。 NLP可以适应不同的风格和情绪,创造更便捷的客户体验。
- 效率:NLP 可以自动执行许多通常需要人们完成的任务。 一些示例包括文本摘要、社交媒体和电子邮件监控、垃圾邮件检测和语言翻译。
- 内容管理:NLP 可以根据个人用户的偏好识别最相关的信息。 了解上下文和关键词可以提高客户满意度。 使数据更易于搜索可以提高搜索工具的效率。
自然语言处理面临哪些挑战?
NLP仍然面临着许多挑战。 人类的言语是不规则的,并且常常含糊不清,根据上下文具有多种含义。 然而,程序员必须从一开始就向应用程序传授这些复杂的知识。
同音异义词和语法可能会混淆数据集。 即使是最好的情感分析也不能总能识别讽刺和反讽。 人类需要数年时间才能了解这些细微差别,即使如此,也很难读懂短信或电子邮件的语气。
文本以多种语言发布,而 NLP 模型则针对特定语言进行训练。 在输入 NLP 之前,你必须应用语言识别来按语言对数据进行排序。
不具体和过于笼统的数据会限制 NLP 准确理解和传达文本含义的能力。 对于特定领域,需要比大多数 NLP 系统更多的数据才能做出实质性主张。 特别是对于依赖最新、高度具体信息的行业。 新的研究,例如 ELSER(Elastic Learned Sparse EncodeR),正在努力解决这个问题,以产生更相关的结果。
处理人们的个人数据也会引起一些隐私问题。 在医疗保健等行业,NLP 可以从患者档案中提取信息来填写表格并识别健康问题。 这些类型的隐私问题、数据安全问题和潜在的偏见使得 NLP 难以在敏感领域实施。
自然语言处理的商业应用有哪些?
NLP 具有广泛的商业应用:
- 聊天机器人和虚拟助理:用户可以与你的系统进行对话。 这些是常见的客户服务工具。 他们还可以指导用户完成复杂的工作流程或帮助他们浏览网站或解决方案。
- 语义搜索:通常在电子商务中用于生成产品推荐。 它通过分析搜索引擎并使用基于知识的搜索来解码关键字的上下文。 它解释用户意图以提供更相关的建议。
- NER:识别文本中的信息以填写表格或使其更易于搜索。 教育机构可以用它来分析学生的写作并自动评分。 此外,文本转语音和语音转文本功能使残障人士更容易获取信息并更轻松地进行沟通。
- 文本摘要:各行业的研究人员可以快速将大型文档总结为简洁、易理解的文本。 金融业利用这一点来分析新闻和社交媒体,以帮助预测市场趋势。 政府和法律行业用它从文件中提取关键信息。
NLP的未来是什么?
ChatGPT 和生成式人工智能带来了变革的希望。 随着 ChatGPT 等技术进入市场,NLP 的新应用可能即将出现。 我们可能会看到与语音识别、计算机视觉和机器人技术等其他技术的集成,这将产生更先进和复杂的系统。
NLP 也将变得更加个性化,使机器能够更好地理解个人用户并调整他们的响应和建议。 能够理解和生成多种语言的 NLP 系统是国际业务的主要增长领域。 最重要的是,NLP 系统在生成听起来自然的语言方面不断变得更好:它们听起来越来越人性化。
开始使用 Elastic 进行 NLP
Elastic Stack 8.0 的发布引入了将 PyTorch 模型上传到 Elasticsearch 的功能,以在 Elastic Stack 中提供现代 NLP,包括命名实体识别和情感分析等功能。
Elastic Stack 目前支持符合标准 BERT 模型接口并使用 WordPiece 标记化算法的 Transformer 模型。
- BERT
- BART
- DPR bi-encoders
- DistilBERT
- ELECTRA
- MobileBERT
- RoBERTa
- RetriBERT
- MPNet
- 具有上述转换器架构的 SentenceTransformers 双编码器
Elastic 可让你利用 NLP 提取信息、对文本进行分类并为你的业务提供更好的搜索相关性。 开始使用 Elastic 进行 NLP。

