- 1verilog高级语法-原语-ibuf-obuf-LUT_ibuf obuf
- 2论文|Jointly Pre-Training Transformers on Unpaired Images and Text_towards a unified foundation model: jointly pre-tr
- 3深度学习使用Accelerate库
- 4谷歌登录失败:google play Couldn‘t sign in.There was a problem communicating with google serves.
- 5Docker + Hadoop 搭建完全分布式_docker容器中完全分佈式hadoop搭建
- 6Github Pro申请
- 7基于udp做服务发现_udp3702端口
- 8【C++风云录】解锁智慧之门:物联网安全工具和库助力打造安全可靠的智能家居
- 9Linux系统中卸载Anaconda_linux卸载anaconda
- 10ARINC818(FC-AV)协议,ADVB
Kafka持久化
赞
踩
Kafka很大程度上依赖文件系统来存储和缓存消息。有一普遍的认识:磁盘很慢。这让人们怀疑使用磁盘作为持久化的性能。实际上,磁盘是快还是慢完全取决于我们是如何使用它。
就目前来说,一个 six 7200rpm SATA RAID-5磁盘线性(顺序)写入的性能能达到600MB/sec,而任意位置写(寻址再写)的性能只有100k/sec。这些线性读写是所有使用模式中最可预测的,并且由操作系统进行了大量优化。现在的操作系统提供了预读取和后写入的技术。实际上你会发现,顺序的磁盘读写比任意的内存读写更快。
基于jvm内存有以下缺点:
对象的内存开销非常高,通常会让存储数据的大小加倍(或更多)
随着堆内数据的增加,GC的速度越来越慢,而且可能导致错误
基于操作系统的文件系统来设计有以下好处:
可以通过os的pagecache来有效利用主内存空间,由于数据紧凑,可以cache大量数据,并且没有gc的压力
即使服务重启,缓存中的数据也是热的(不需要预热)。而基于进程的缓存,需要程序进行预热,而且会消耗很长的时间。(10G大概需要10分钟)
大大简化了代码。因为在缓存和文件系统之间保持一致性的所有逻辑都在OS中。以上建议和设计使得代码实现起来十分简单,不需要尽力想办法去维护内存中的数据,数据会立即写入磁盘。
这种以页面缓存(pagecache)为中心的设计风格在一篇关于Varnish设计的文章中有详细描述。
总的来说,Kafka不会保持尽可能多的内容在内存空间,而是尽可能把内容直接写入到磁盘。所有的数据都及时的以持久化日志的方式写入到文件系统,而不必要把内存中的内容刷新到磁盘中。
Kafka的持久化
1.数据持久化:
发现线性的访问磁盘(即:按顺序的访问磁盘),很多时候比随机的内存访问快得多,而且有利于持久化;
传统的使用内存做为磁盘的缓存
Kafka直接将数据写入到日志文件中,以追加的形式写入
2.日志数据持久化特性:
写操作:通过将数据追加到文件中实现
读操作:读的时候从文件中读就好了
3.优势:
读操作不会阻塞写操作和其他操作(因为读和写都是追加的形式,都是顺序的,不会乱,所以不会发生阻塞),数据大小不对性能产生影响;
没有容量限制(相对于内存来说)的硬盘空间建立消息系统;
线性访问磁盘,速度快,可以保存任意一段时间!
4.持久化的具体实现:

5.索引
为数据文件建索引:因为是线性存储的所以可以做稀疏索引
稀疏存储,每隔一定字节的数据建立一条索引(这样的目的是为了减少索引文件的大小)。
下图为一个partition的索引示意图:
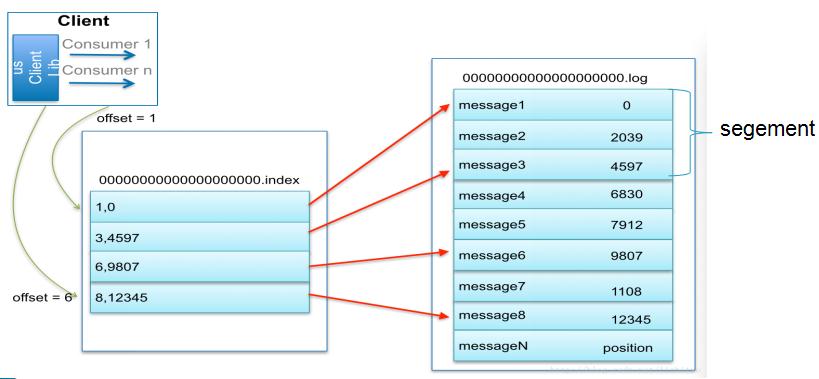
注:
1.现在对6.和8建立了索引,如果要查找7,则会先查找到8然后,再找到8后的一个索引6,然后两个索引之间做二分法,找到7的位置
2.每一个log文件中又分为多个segment
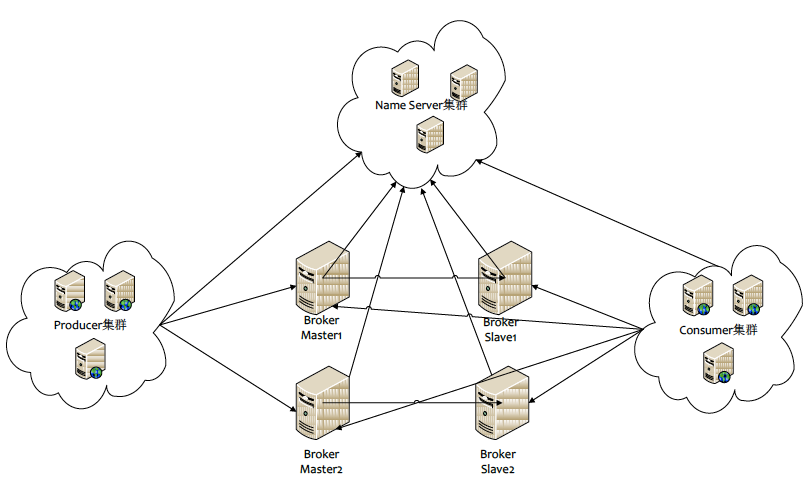
二.Kafka的分布式实现
注:

1.当生产者将消息发送到Kafka后,就会去立刻通知ZooKeeper,会往zookeeper的节点中去挂,
zookeeper中会watch到相关的动作,当watch到相关的数据变化后,会通知消费者去消费消息。
2.消费者是主动去Pull(拉)kafka中的消息,这样可以降低Broker的压力,因为Broker中的消息是无状态的,Broker也不知道哪个消息是可以消费的
3.当消费者消费了一条消息后,也必须要去通知ZooKeeper。zookeeper会记录下消费的数据,这样但系统出现问题后就可以还原,可以知道哪些消息已经被消费了
部署图:
Name Server集群即ZooKeeper集群