- 1Bugku CTF 每日一题 where is flag_bugku where is flag
- 2fastadmin html完整版,前端 - FastAdmin框架文档 - FastAdmin开发文档
- 3解决github push/pull报错443_github 443
- 4重走长征路-PaddleClas训练ImageNet 1K数据集实践-后台任务版_imagenet1k要多久
- 5【大模型的前世今生】从自然语言处理说起_大模型 自然语言处理
- 6面试:前端安全之XSS及CSRF_反射型xss漏洞前端过滤
- 7【C++ 语言】C++字符串 ( string 类 | 创建方法 | 控制台输出 | 字符串操作 | 栈内存字符串对象 | string* )_c++ 创建字符串的方法
- 8Oracle中的CASE WHEN语句使用详解与实例
- 9【网站项目】农产品自主供销小程序
- 10SPSS常用的10种统计分析_spss数据分析
transformer在cv领域_transformer在cv上的应用
赞
踩
transformer - vision transformer()第一次将transformer运用在计算机视觉领域
纯transformer模型的缺点:
参数多,要求算力高
缺少空间归纳偏置
迁移到其他任务比较繁琐
模型训练困难
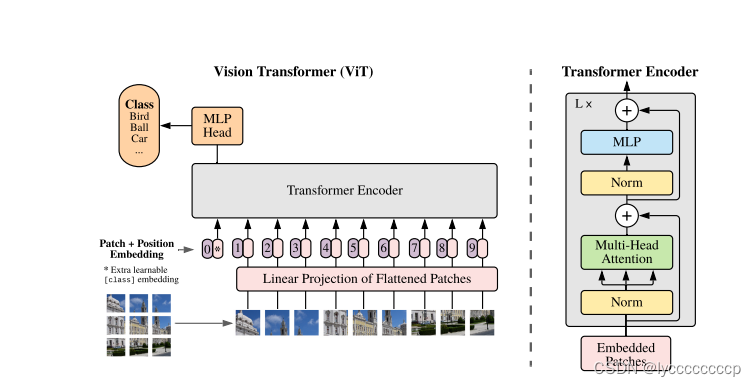
vit首次将transformer运用在计算机视觉领域,应为transformer输入的是1d序列,而图片是2d的,那么如何将transformer运用在cv领域呢,以前有人提出将图片按像素展平,但是如果按像素展平,例如224*224的图片,展平再做自注意力,那么计算复杂度是很高的,所以作者就想了一个办法,将图片分割成16*16的patch进行输入,如上图,其实在代码中就是运用卷积来实现的,分割好之后进入patch embadding层 patch就变成了一个个token,在之后cancat拼接一个分类的token(在代码中通过直接给出一个1*768的可训练参数实现),这里也可以在最后像卷积一样进行全局平均池化,后面也做过对比实验。但是作者想要证明纯transformer也可以运用在cv中,所以就参考了bert模型,加入了cls。但是这里又出现了一个问题,nlp领域中的句子是没有前后相关性的,但图片不同,每个patch之间存在关系,所以作者加入了位置编码,在原文中,作者做了对比实验,分别对比了一维位置编码,二维位置编码,相对位置编码,如下图。
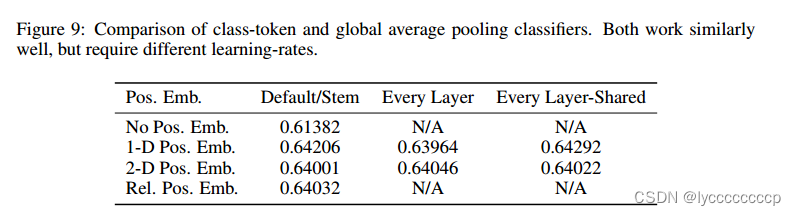
可以看到,位置编码的效果是差不多的,所以在原文中,作者采用了相对较好的1D位置编码。
其实在代码中实现就是给定一个可训练的196*768的参数,在与已存在的token进行相加。
然后进如transformer encoder,结构图上图所示这里不再赘述,直接截霹导的图,L代表重复多少次。
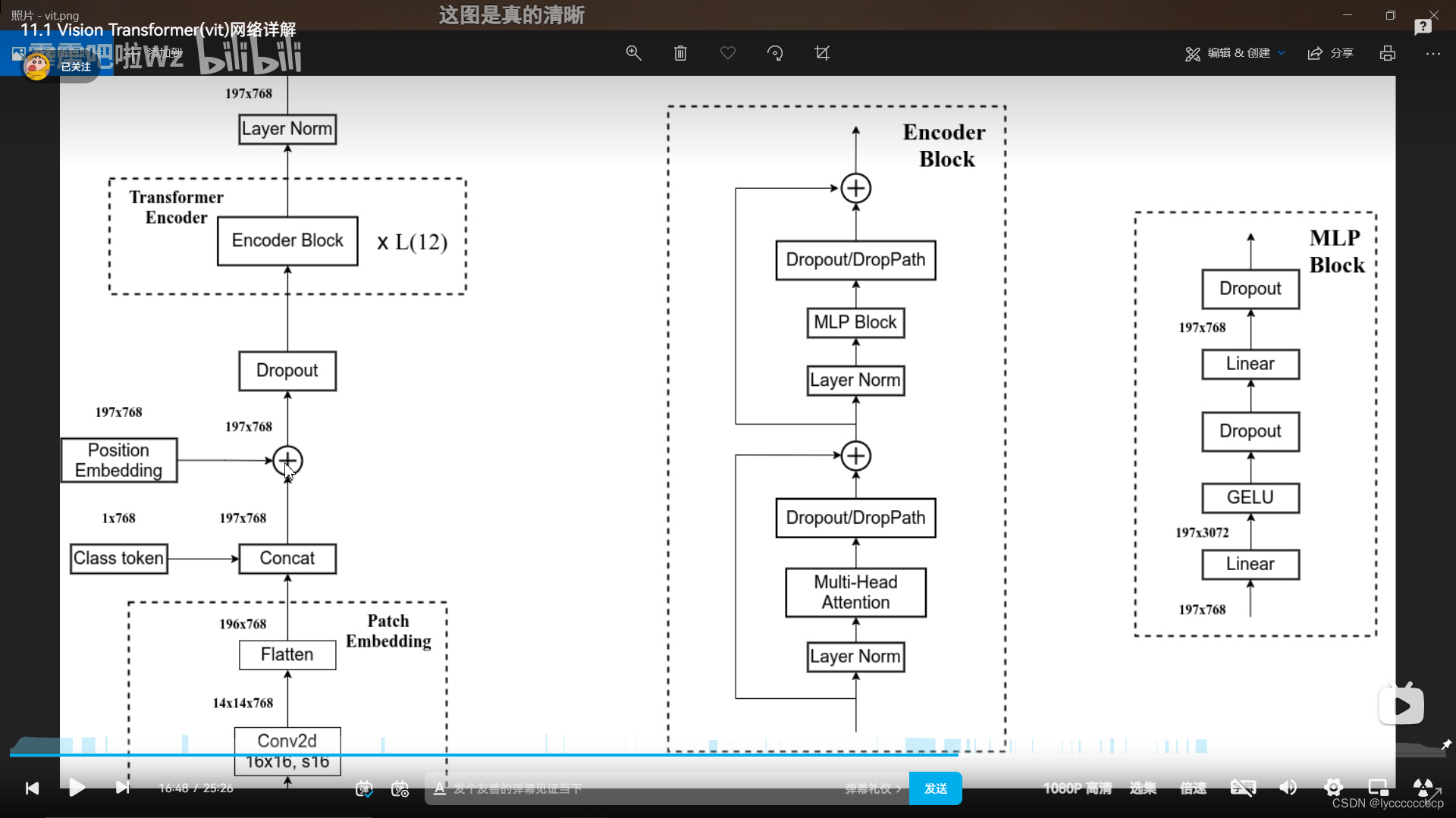
通过transformer block 后提取出cls,在代码中用切片形式提取。最后进入MLP 线性层分类。
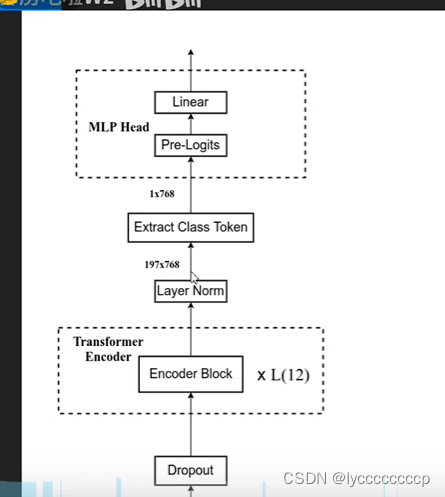
这就是整个vision transformer的架构。
swintransformer
 swintransformer与ViT的不同
swintransformer与ViT的不同
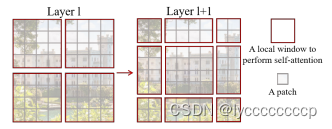
1 swintransformer的特征层具有层次性,就像我们之前学习的cnn一样。VIT下采样倍率不变。
2 swintransformer用一个一个窗口的形式将feature map分割,窗口与窗口之间没有重叠,而vit没有。这一个个window就之后要讲的windows mutihad selfattention。引入这个结构后可以在每个windows内部进行self attention的计算。window与window不进行信息传递。好处在与大大降低运算量。尤其在浅层网络。下采样倍率比较低的时候,相对于整个特征图进行mutihad selfattention,会减少计算量。
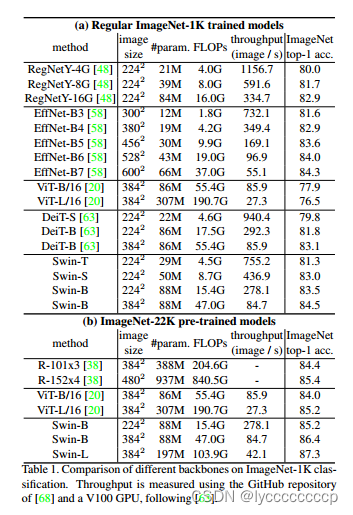
在image1k上进行训练的话。vitb16在imagenet top 1达到的准确率是77.9 ,使用vit只有在非常大的数据集预训练才能得到很好的效果,如果直接在image1K上训练效果不是很好。
在更大的数据集上进行与训练Vit为,swin更好些
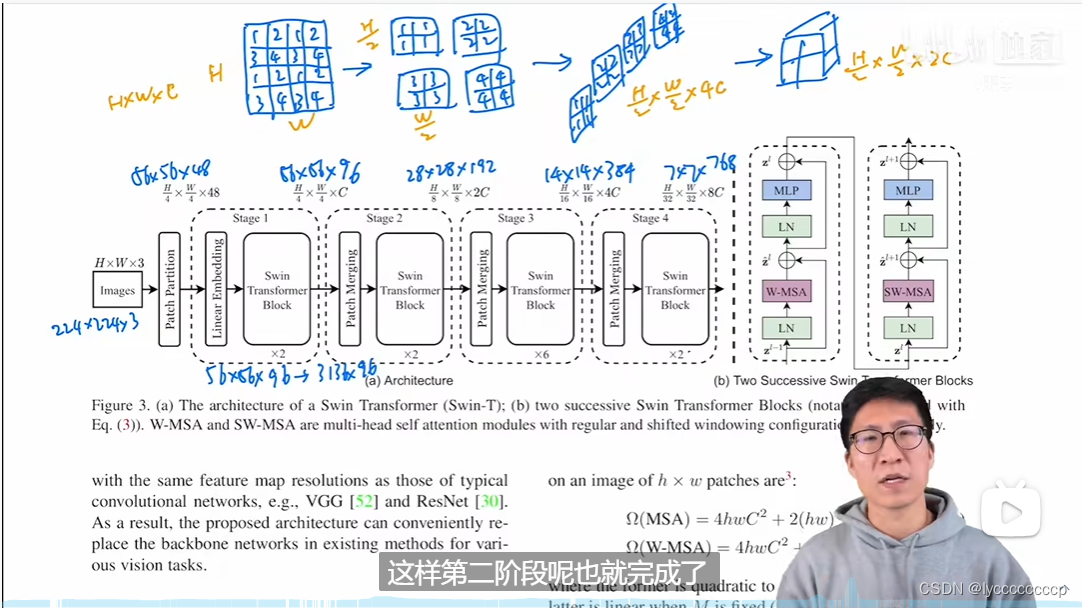
整体网络架构
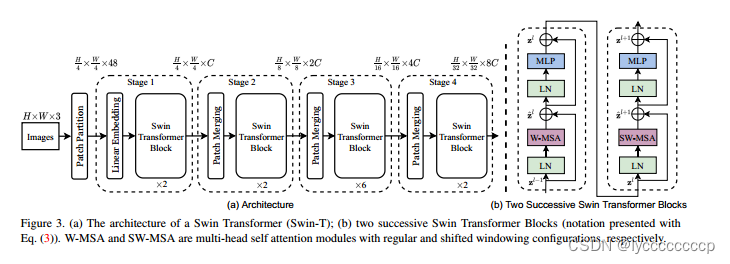
首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,进行通道数调整。由48变成C,C具体变成多少呢,swt不同类型有所不同。即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。
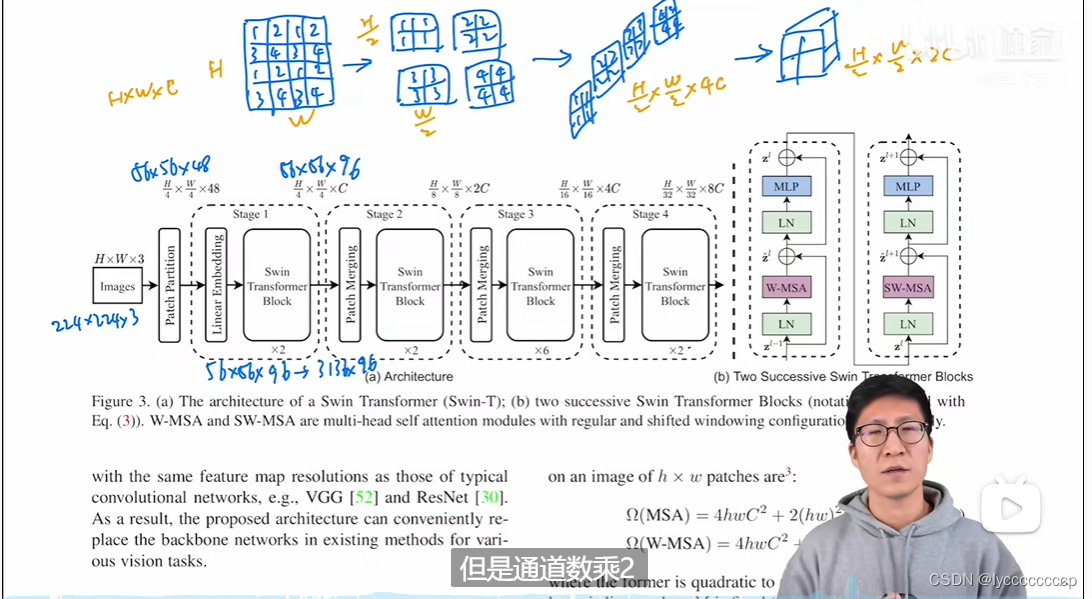
这里也直接引用沐神团队的大佬所讲的网络结构来介绍,假设输入的图片是224*224*3的rgb图像,首先经过patch partition,将图片分为4*4的patch ,这是图像维度为,56*56*4*4*3,既56*56*48,再经过一个线性层,维度变为56*56*96,展平后变为3136*96。与vit相比,是不是3136比196大的多呢,为了减少计算量,作者提出了窗口自注意力机制。这个后面再说。若不加其他操作,transformer是不会改变维度的,所以出来仍然是56*56*96,为了体现层结构,作者提出了patch merging的操作,如上图,将原图片中的相隔的patch 拿出来再合并成一个patch,(在源码中通过切片操作)这样就可以增大patch的大小,显示此时通道数变为4倍,为了与卷积相符合,在通过一个layernorm层,再通过线性层降维,通道数变为原来的2倍。这样就完成了前面所说的层结构。所以swint这篇论文更向与卷积那边,所以并没有使用 cls,而是得到最后的特征图,用全局平均池化。
W-MSA模块
对普通的MSA,会对每一个像素求一个QKV,在进行一些列操作
对W-MSA 先分成一个个窗口,然后对每一个window的内部做MSA,但window和wiindow之间没有MSA
目的:减少计算量
缺点:窗口之间无法进行信息交互,导致感受野变小
具体省多少呢?
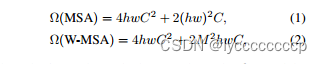
M代表每个窗口的大小
SW-MSA
目的:实现不同windows之间的信息交互
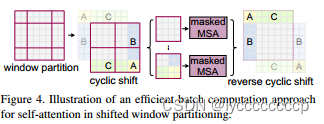
向右向下移动两个像素 然和移动,把不相邻的元素做掩码。算完后再拼回去
Relative position bia

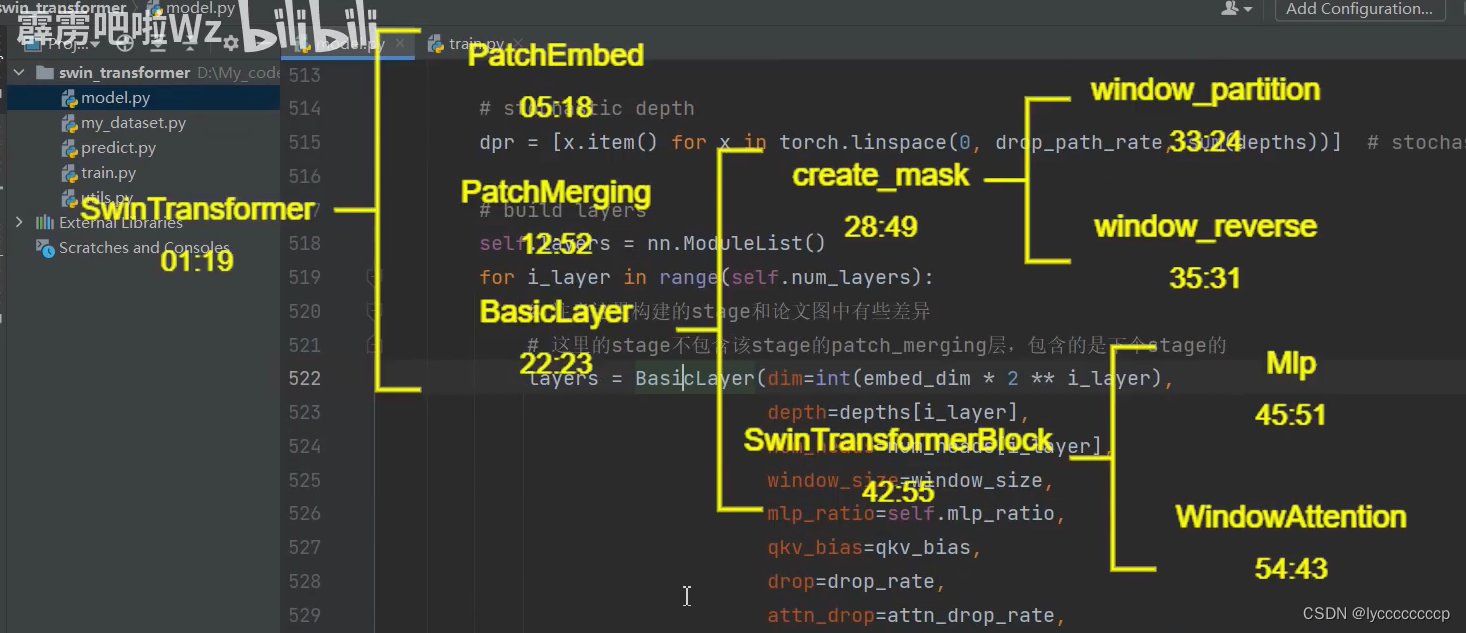
代码部分可以直接看
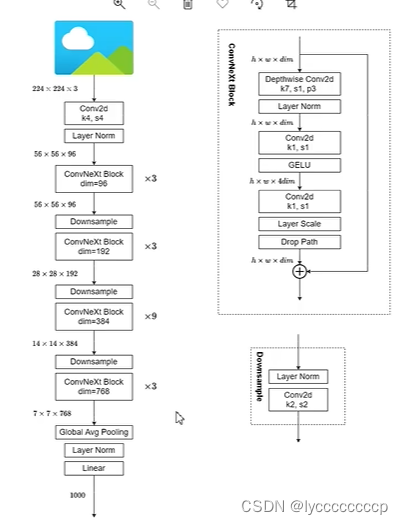
ConvNeXt
ConvNeXt网络详解_convnext在哪提出-CSDN博客


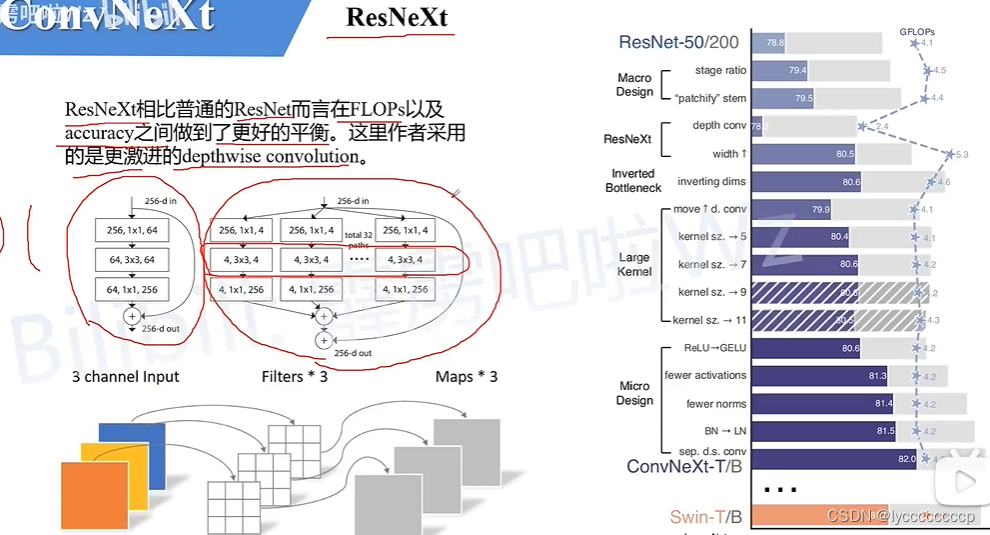
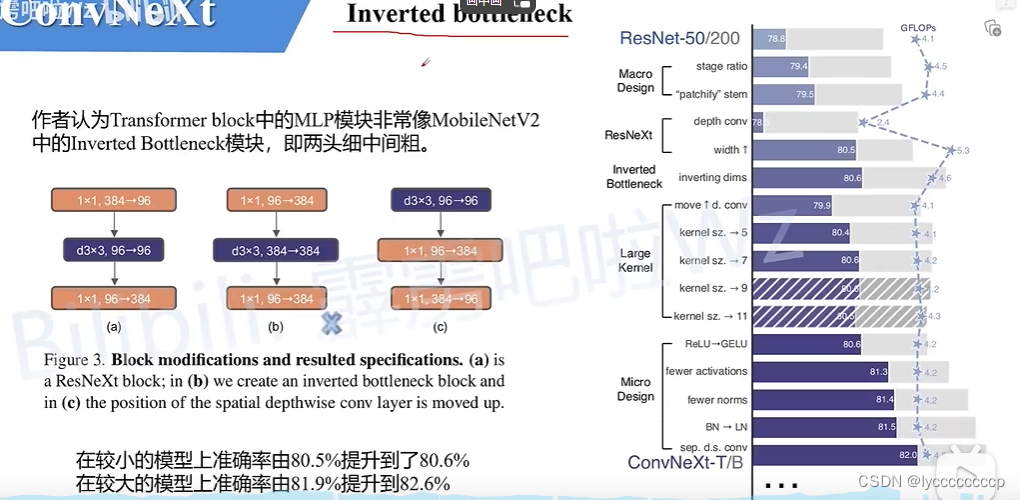
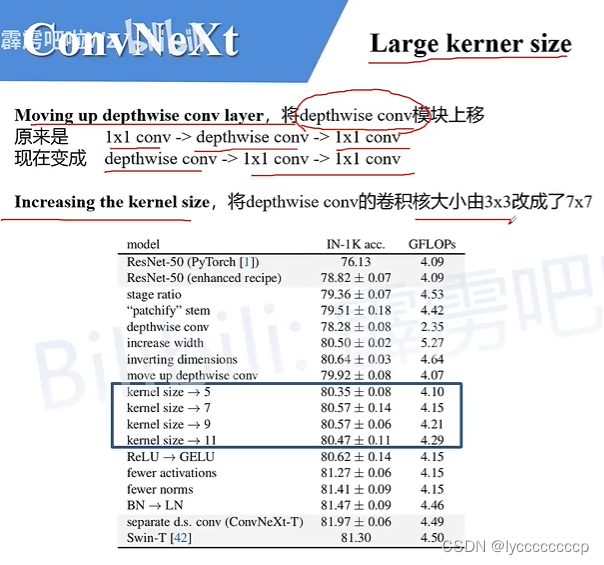
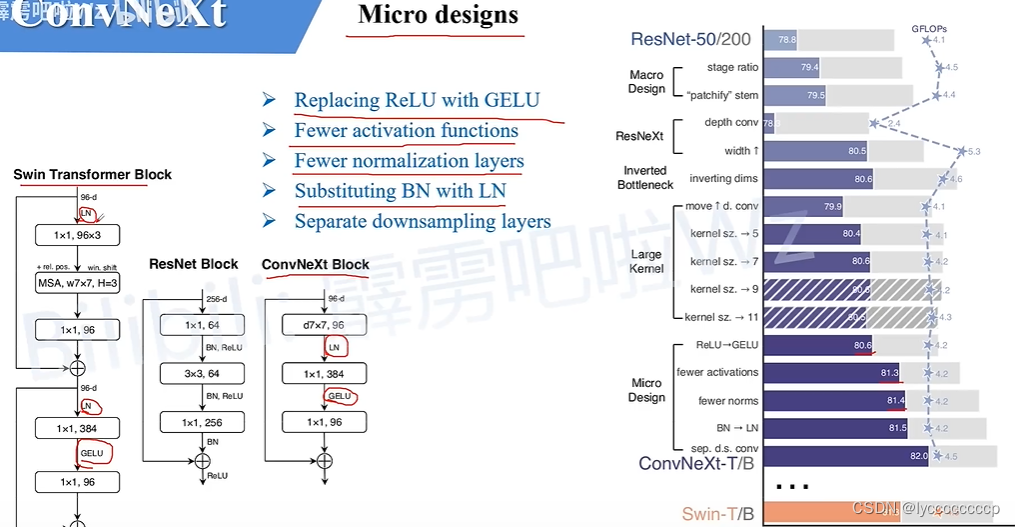
网络结构