
- 1机器人方向控制中应用的磁阻角度传感芯片
- 2fatal: unable to access ‘https://github.com/.../...git/‘: Failed to connect to github.com port 443
- 3沟通训练营笔记_沟通训练营 回应
- 4《tkinter实用教程二》tkinter的子模块ttk_tkinter ttk
- 5python易忘 自用小甲鱼笔记_鱼c速查宝典
- 6【IoT】TLV 报文格式详细解析_tlv格式
- 7【New Release】PostgreSQL小版本(16.2, 15.6, 14.11, 13.14,12.18) 发布了_pg14.8版本是什么时候发布的
- 8【GitHub项目推荐--1个用于批量给图片增加水印的Python库】【转载】_github 简单水印
- 9招银网络面经,2024金三银四春招来袭,java中级工程师面试
- 102024最新ros学习教程与机械臂抓取相关算法论文项目大全
使用语言学特征进行文本情感分类《Linguistically Regularized LSTM for Sentiment Classification》_语言学特征 文本
赞
踩
摘要
本文主要是做句子情感分类任务的研究,前人做的工作大多都依赖于短语级别的标注,这样费时费力,而一旦仅使用句子级别的标注的话模型效果就会大幅下降。本文提出了一种简单的句子级情感分类模型,把语言学规则(情感词典,否定词和程度副词)融入到现有的句子级LSTM情感分类模型中。
模型
语言学知识对情感分析任务至关重要,
主要包括:
情感词典(sentiment lexicons)
否定词(negation words (not, never, neither, etc.))
程度副词(intensity words (very, extremely, etc.))
- 情感词典(sentiment lexicon)
情感词典(英文)应用比较广泛的有Hu and Liu 2004年提出的情感词典和MPQA词典,详细介绍可分别参考以下两篇文章:
[Hu and Liu 2004] Mining and Summarizing Customer Reviews
[Wilson, Wiebe, and Hoffmann 2005] Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis
- 否定词(negation words)
否定词在情感分析中也是一个关键元素,它会改变文本表达的情感倾向。有很多相关研究:
1. [Polanyi and Zaenen 2006] Contextual Valence Shifters
2. [Taboada et al. 2011] Lexicon-Based Methods for Sentiment Analysis
3. [Zhu et al. 2014] An Empirical Study on the Effect of Negation Words on Sentiment
4. [Kiritchenko and Mohammad 2016] Sentiment Composition of Words with Opposing Polarities
文章1:对否定词的处理是将含有否定词的文本的情感倾向反转;
文章2:由于不同的否定表达以不同的方式不同程度影响着句子的情感倾向,文中提出否定词按照某个常量值的程度改变着文本的情感倾向;
文章3:将否定词作为特征结合到神经网络模型中;
文章4:将否定词和其他语言学知识与SVM结合在一起,分析文本情感倾向。
- 程度副词 (intensity words)
程度副词影响文本的情感强度,在细粒度情感中非常关键,相关研究可参考:
1. [Taboada et al. 2011] Lexicon-Based Methods for Sentiment Analysis
2. [Wei, Wu, and Lin 2011] A regression approach to affective rating of chinese words from anew
3. [Malandrakis et al. 2013] Distributional semantic models for affective text analysis
4. [Wang, Zhang, and Lan 2016] Ecnu at semeval-2016 task 7: An enhanced supervised learning method for lexicon sentiment intensity ranking
文章1:直接让程度副词通过一个固定值来改变情感强度;
文章2:利用线性回归模型来预测词语的情感强度值;
文章3:通过核函数结合语义信息预测情感强度得分;
文章4:提出一种learning-to-rank模型预测情感强度得分。
本文提出的Linguistically Regularized LSTM 是把语言学规则(包括情感词典、否定词和程度副词)以约束的形式和LSTM结合起来。
本文通过语言学的角度来将文本中所有词汇分为四种:
- Non-Sentiment Regularizer (NSR),代表不带有语义的字,例如 movie, book, water。
NSR的基本想法是: 如果相邻的两个词都是non-opinion(不表达意见)的词,那么这两个词的情感分布应该是比较相近的。 将这种想法结合到模型中,有如下定义:
关于
KL 散度:
KL 散度是用来衡量两个函数或者分布之间的差异性的一个指标,其原始定义式如下:
两个分布的差异越大,D(p||q)=∑i=1np(x)⋅logp(x)q(x) KL 散度值越大; 两个分布的差异越小,KL 散度值越小; 当两个分布相同时,KL 散度值为0
这里所用的对称KL 散度定义如下:DKL=12∑l=1Cp(l)logq(l)+q(l)logp(l)
所以我们可以看到, 当相邻的两个词分布较近,KL 散度小于M 时,NSR 的值为0 ; 随着两个词的分布差异增大时,NSR 值变大。
- Sentiment Regularizer (SR),包含语义的字,例如 interesting, good, disaster,从sentiment lexicon 中得到
SR的基本想法是: 如果当前词是情感词典中的词,那么它的情感分布应该和前一个词以及后一个词有明显不同。 例如:
This movie is interesting. 在位置t=4 处的词“interesting” 是一个表达正向情感的词, 所以在t=4 处的情感分布应该比t=3 处要positive 得多。 这个叫做sentiment drift(情感漂流) 。
为了将这种想法结合到模型中, 作者提出一个极性漂流分布
SR定义如下:
通俗来讲就是如果当前词相对上一个词的情感变化明显,则当前词为SR
- Negation Regularizer (NR),带有预期转折的字,例如 not, nothing, never,手工提取
否定词通常会反转文本的情感倾向(从正向变为负向,或者是从负向变为正向), 但是具体情况是跟否定词本身和它所否定的对象有关的。 例如:“not good”和“not bad”中,“not”的角色并不一样,前者是将正向情感转为负向情感,后者是将负向情感转为中性情感。
由于每个转折词可能会转向不同的情感,既可以由positive转向negative,也可能由negative转向positive,故本文针对每一个否定词,提出一个转化矩阵
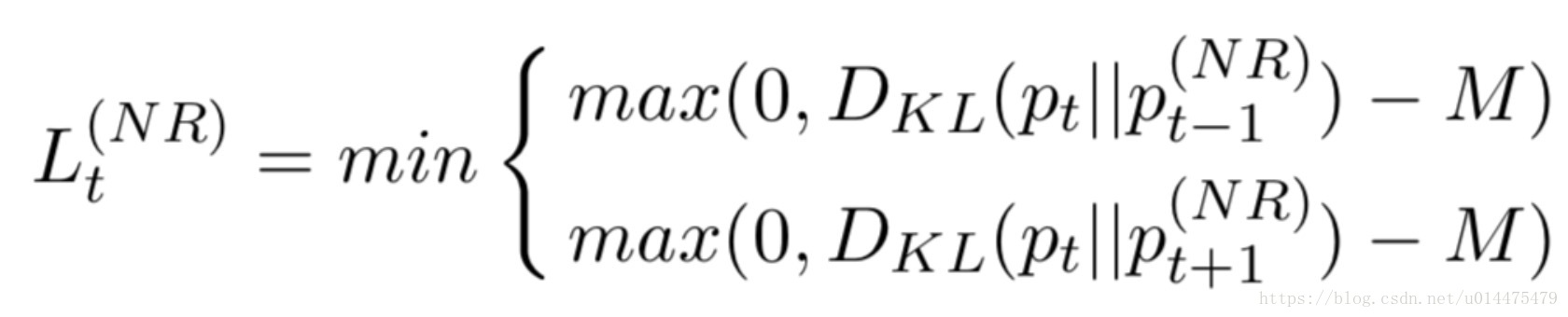
通俗来讲就是通过当前词的上一个词和下一个词来判断情感转换的方向。
- Intensity Regularizer (IR),程度副词,例如 very, terribly, too,手工提取
程度副词改变文本的情感强度(比如从positive变为very positive),这种表达对细粒度情感分析很重要。
程度副词对于情感倾向的改变和否定词很像,只是改变的程度不同,本文也是通过一个转化矩阵来定义IR的。
接下来我们来看本文提出的模型
Linguistic Regularizers to Bidirectional LSTM
Linguistically Regularized LSTM是把语言学规则(包括情感词典、否定词和程度副词)以约束的形式和LSTM结合起来。
模型结构如下图所示:
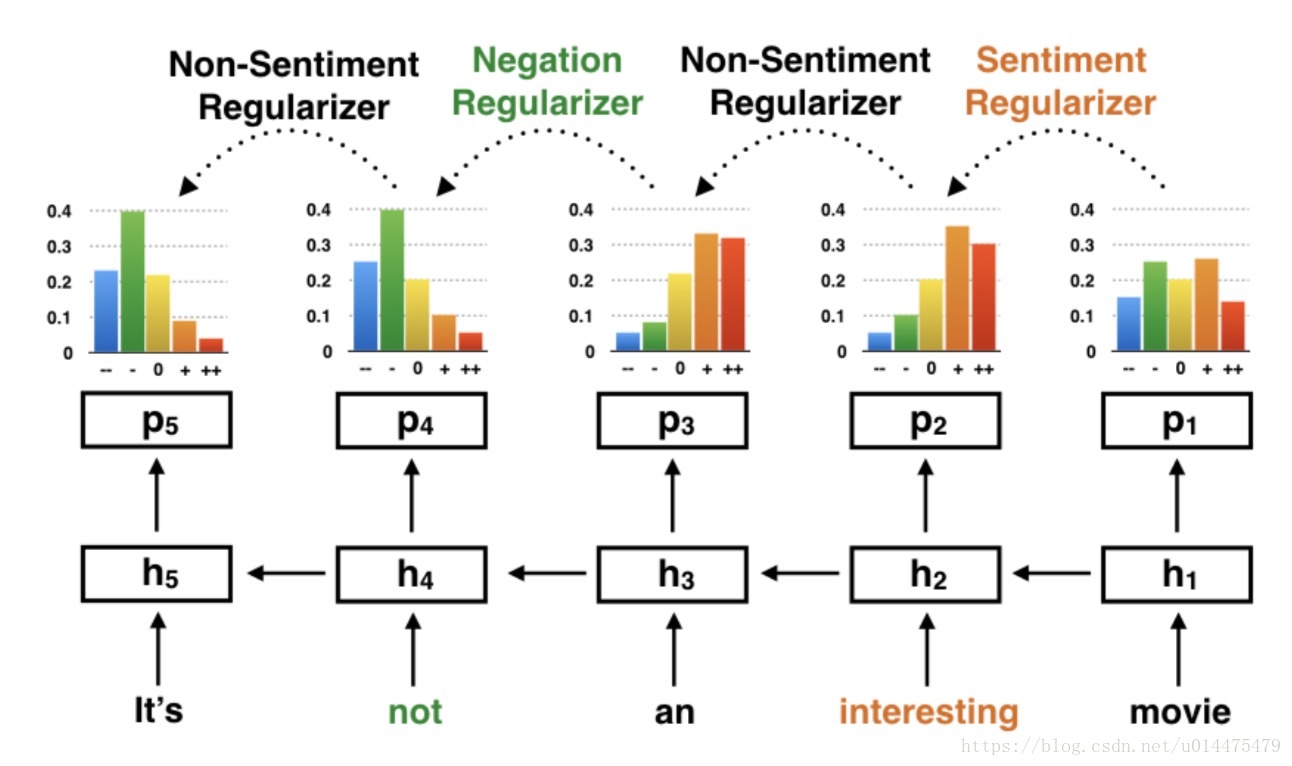
我们用单向LSTM从右往左合成 It’s not an interesting movie。 从时刻1到时刻2,输入了一个情感词interesting,仅凭直觉就可以断言,代表着interesting movie的情感分布p2,一定比movie的情感分布p1有一个偏移量,这个偏移量应该与情感词interesting保持一致。所以,在我们的模型中,我们使用一个Sentiment Regularizer去约束p1和p2的关系,当然这个regularizer是与interesting相关的,并且是可学习的。 从时刻2到时刻3,输入了一个非情感词an,凭着我们的先验知识,an interesting movie与interesting movie的情感分布应该是近似的,所以我们使用一个Non-Sentiment Regularizer去约束p2和p3的关系。 从时刻3到时刻4,输入了一个否定词not,我们知道加入not后情感应该会发生很大的变化,通常是一定程度的反转。所以我们为否定词not学习一个Negation Regularizer,并用它去约束p3和p4的关系。
损失函数为:
模型训练的目标是最小化损失函数,让样本的实际分布与预测分布尽可能接近的同时,让模型符合上述四种规则。
实验
数据
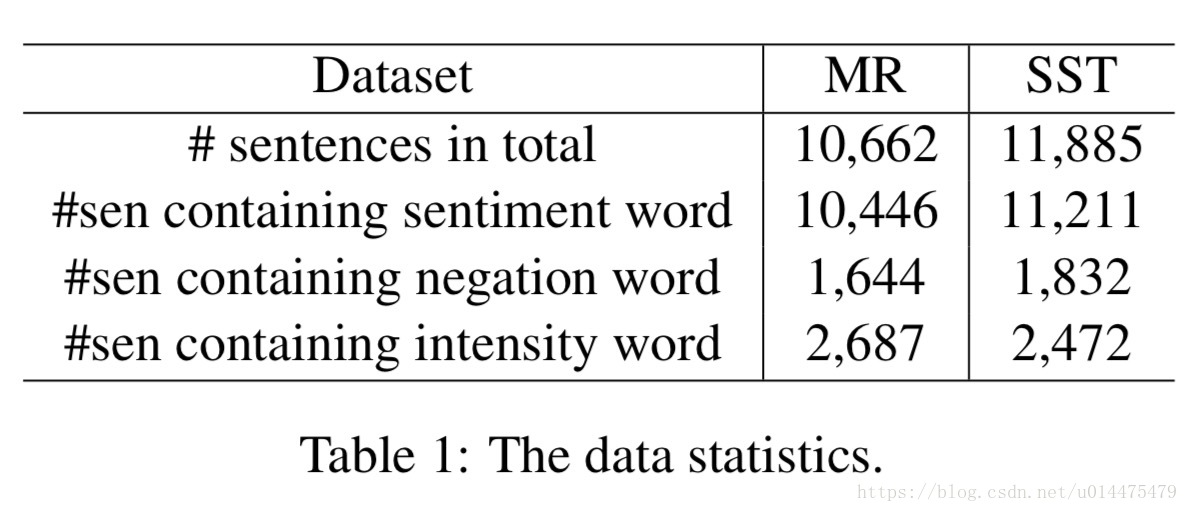
本文实验用了两个数据集来验证模型性能,
- Movie Review (MR)(with two classes { negative, positive})
- Stanford Sentiment Treebank (SST) (with five classes { very negative, negative, neutral, positive, very positive})
两个数据集的具体统计信息如下图所示
实验结果
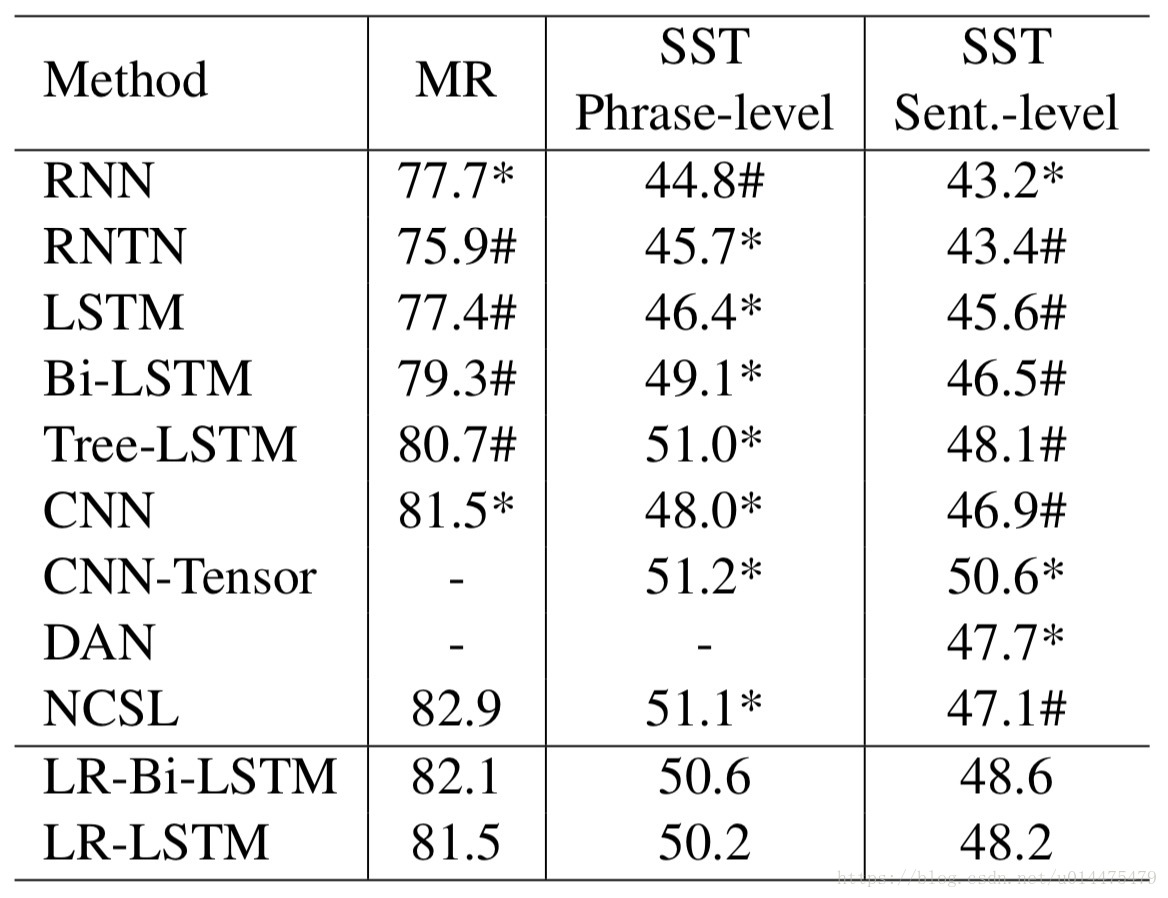
从实验结果可以看出:
- LR-LSTM和LR-BI-LSTM与对应的LSTM相比都有较大提升;
- LR-BI-LSTM在句子级标注数据上的结果与BI-LSTM在短语级标注数据上的结果基本持平,表明通过引入LR,可以减少标注成本,并得到差不多的结果;
- 本文的LR-LSTM和LR-BI-LSTM和Tree-LSTM的结果基本持平,但是本文的模型更简单,效率更高,同时省去了短语级 的标注工作。
不同规则的效果分析
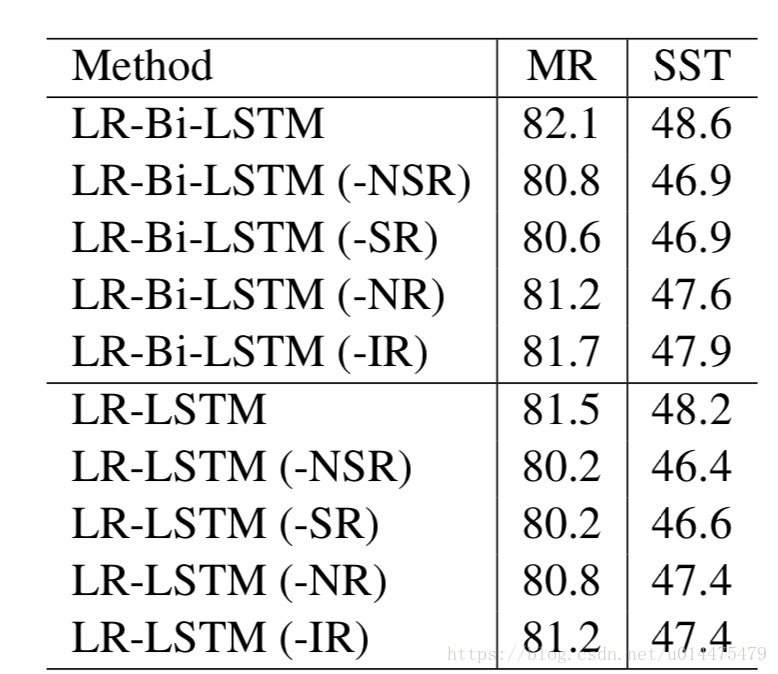
从实验结果可以看出,
NSR和SR对提升模型性能最重要,
NR和IR对模型性能提升重要性没有那么强,
可能是因为在测试数据中只有14%的句子中含有否定词,只有23%的句子含有程度副词。
为了进一步研究NR和IR的作用,作者又分别在仅包含否定词的子数据集(Neg.Sub)和仅包含程度副词的子数据集(Int.Sub)上做了对比实验,实验结果如下图
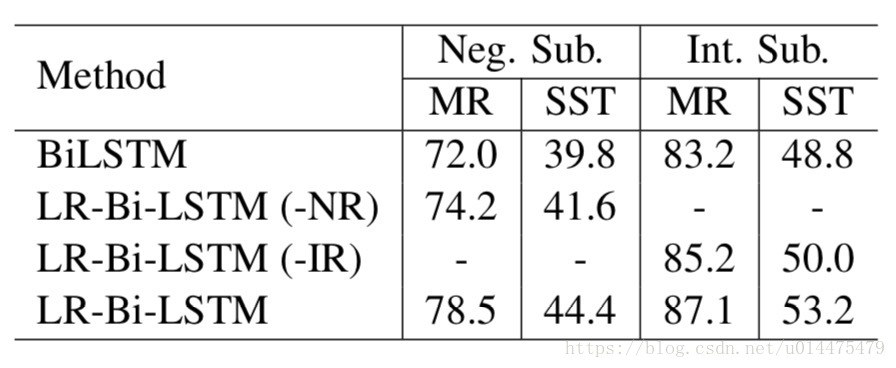
从实验结果可以看出,
- 在这些子数据集上,LR-Bi-LSTM的性能优于Bi-LSTM;
- 去掉NR或者IR的约束,在MR和SST两个数据集上模型性能都有明显下降。
结论
这篇文章通过损失函数将语言学规则引入现有的句子级情感分析的LSTM模型。在没有增大模型复杂度的情况下,有效的利用情感词典、否定词和程度副词的信息,在实验数据集上取得了较好效果。
随着深度学习的发展,人们慢慢忽略了宝贵的经典自然语言资源,如何有效将这部分知识有效地融入到深度学习模型中是一个非常有意义的工作。

