
热门标签
热门文章
- 1回溯算法(四)排列问题_回溯法排列问题
- 2Docker 学习笔记(七):介绍 Dockerfile 相关知识,使用 Dockerfile 构建自己的 centos 镜像
- 3springboot 文件上传Linux环境报错
- 4文心一言插件开发(第二篇_基于文心一言的模块功能进行二次开发 csdn
- 5Spring Data Elasticsearch 使用(Elasticsearch)_elasticsearch根据id查询数据
- 6git 上传超过100M文件报错后的处理方式_error: file: 108.91 mb, exceeds 100.00 mb
- 7如何将idea关联远程gitlab仓库_idea关联gitlab教程
- 82024年AI威胁场景报告:揭示现今最大的AI安全挑战_2024年人工智能安全报告
- 9java ssl 发邮件_java SSL 邮件发送
- 10Rust与Java交互-JNI模块编写-实践总结_java能和rust一起吗
当前位置: article > 正文
Navicat建数据库时字符集与排序规则说明
作者:你好赵伟 | 2024-04-27 22:00:28
赞
踩
Navicat建数据库时字符集与排序规则说明
一、字符集说明
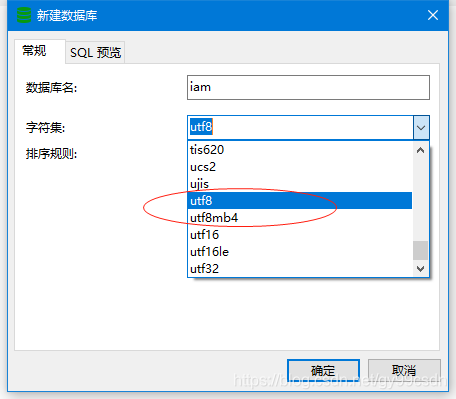
一般选择utf8。
下面介绍一下utf8与utf8mb4的区别:
utf8mb4兼容utf8,且比utf8能表示更多的字符。至于什么时候用,看你的做什么项目了,到 https://www.cnblogs.com/renlinsen/p/14206715.html看unicode编码区从1 ~ 126就属于传统utf8区,当然utf8mb4也兼容这个区,126行以下就是utf8mb4扩充区,什么时候你需要存储那些字符,你才用utf8mb4,否则只是浪费空间。
二、排序规则说明
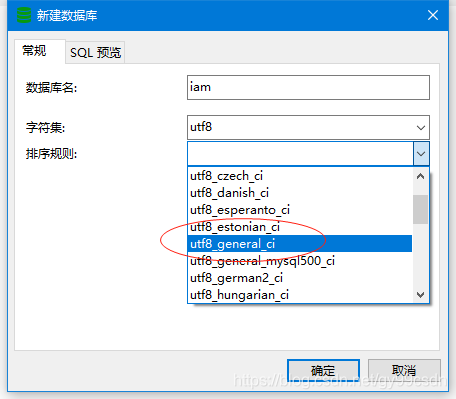
排序规则一般有3种: utf8_general_ci、utf8_general_cs、utf8_bin。
- ci全称为case insensitive,意思是大小写不敏感;
- cs区分大小写;
- bin是以二进制数据存储,且区分大小写。
例如:
SELECT * FROM table WHERE txt = ‘a’;
那么在utf8_bin中找不到 txt = ‘A’ 的那一行, 而 utf8_general_ci 则可以。
- utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
- utf8_general_ci校对速度快,但准确度稍差。 (准确度够用,一般建库选择这个。)
- utf8_unicode_ci准确度高,但校对速度稍慢。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/498896
推荐阅读
相关标签

