
热门标签
热门文章
- 1Redis缓存详解(黑马-未完结)_redis缓存介绍
- 2人脸识别示例解析(三)——微笑识别解析_面部识别 如何微笑
- 3渗透测试快速稳定远控软件,高级渗透测试第八季-demo即是远控
- 4基于java相亲交友系统的设计与实现论文_基于java的社交网站设计与实现
- 5文献学习-20-基于学习的视觉应变融合,用于手眼连续体机器人姿态估计与控制
- 6代码随想录-二分查找题目分析
- 7基于React Hooks的简单全局状态共享实现方案
- 8把数据从mysql导入到hdfs中_mysql to hdfs full
- 9淘宝人生2的AIGC技术应用——虚拟人写真算法技术方案
- 10MKS SERVO28C 闭环步进电机 使用说明_闭环步进电机怎么使用
当前位置: article > 正文
python连接neo4j数据库
作者:你好赵伟 | 2024-04-30 01:47:27
赞
踩
python连接neo4j
引言:
本文主要介绍的是利用python工具pycharm连接neo4j数据并创建数据节点和节点关系,不会涉及到neo4j的基础环境搭建,如果有小伙伴不会neo4j基础环境搭建可以:
https://www.baidu.com/
连接neo4j需要用到的库
py2neo
这个库就是专门用来连接驱动neo4j的库
这里我用的python版本和py2neo的版本是:

目前python版本和neo4j数据库契合的版本有那么些:
Python 2.7 / 3.3 / 3.4 / 3.5
Neo4j 2.0 / 2.1 / 2.2 / 2.3 / 3.0
连接数据库操作
from py2neo import *
graph = Graph('http://127.0.0.1(这里的IP根据每个人的地址来写):7474', username="这里是你的用户名好吧", password="你的数据库密码")
- 1
- 2
上边是比较小白的写法,你也可以这样写:
graph = Graph("http://127.0.0.1:7474",auth=("账号","密码"))
- 1
这样写:
g = Graph('http://账号:密码@127.0.0.1:7474')
- 1
连接上数据库之后我们用一些数据来对它进行一些节点的创建。
我这里用的是基于CSV文件来对neo4j数据库进行关系创建,这是我的csv文件的一些内容:

数据来源于wake瑜伽网,没错是爬下来的,爬虫代码就不贴出来了。
下边是是实现过程:
1,首先是读取文件:
frame = pd.read_csv(r"C:/data/",encoding='gbk')
- 1
2,然后遍历获取文件的头:
for i in frame.index:
'''获取数据'''
yoga_name = frame["招式"].values[i]
yoga_ms = frame["描述"].values[i]
yoga_yc = frame["益处"].values[i]
yoga_zysx = frame["注意事项"].values[i]
yoga_cjwt = frame["常见问题"].values[i]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3,把遍历得出来的头保存为str类型的数据以免出现参数错误:
yoga_name = str(yoga_name)
yoga_ms = str(yoga_ms)
yoga_yc = str(yoga_yc)
yoga_zysx = str(yoga_zysx)
yoga_cjwt = str(yoga_cjwt)
- 1
- 2
- 3
- 4
- 5
4,数据读取了,格式转换了,开始进入节点创建:
yoga_node = Node('招式', name=yoga_name)
graph.merge(yoga_node) ## merge方法是将重复数据去除掉,只留第一个
ms_node = Node('描述', name=yoga_ms)
yc_node = Node('益处', name=yoga_yc)
zysx_node = Node('注意事项', name=yoga_zysx)
cjwt_node = Node('常见问题', name=yoga_cjwt)
- 1
- 2
- 3
- 4
- 5
- 6
5,节点创建完了,开始创建节点与节点之间的关系:
# 瑜伽类
yoga_2 = Relationship(yoga_node, '描述', ms_node)
yoga_3 = Relationship(yoga_node, '益处', yc_node)
yoga_4 = Relationship(yoga_node, '注意事项', zysx_node)
yoga_5 = Relationship(yoga_node, '常见问题', cjwt_node)
- 1
- 2
- 3
- 4
- 5
6,所有东西都准备好了之后,我们开始创建操作:
try: graph.create(yoga_2) except: continue try: graph.create(yoga_3) except: continue try: graph.create(yoga_4) except: continue try: graph.create(yoga_5) except: continue

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
完整代码
数据集下载地址:
链接:https://pan.baidu.com/s/1utGHNHy7k-JqzBEqI6wWRA
提取码:fuck
以上就是python连接neo4j数据的一些小操作了,以下是完整代码:
from py2neo import * import pandas as pd graph = Graph('http://127.0.0.1(这里的IP根据每个人的地址来写):7474', username="这里是你的用户名好吧", password="你的数据库密码") def yogadata(): count = 0 frame = pd.read_csv(r"C:/data/", encoding='gbk') for i in frame.index: '''获取数据''' yoga_name = frame["招式"].values[i] yoga_ms = frame["描述"].values[i] yoga_yc = frame["益处"].values[i] yoga_zysx = frame["注意事项"].values[i] yoga_cjwt = frame["常见问题"].values[i] yoga_name = str(yoga_name) yoga_ms = str(yoga_ms) yoga_yc = str(yoga_yc) yoga_zysx = str(yoga_zysx) yoga_cjwt = str(yoga_cjwt) yoga_node = Node('招式', name=yoga_name) graph.merge(yoga_node) ## merge方法是将重复数据去除掉,只留第一个 ms_node = Node('描述', name=yoga_ms) yc_node = Node('益处', name=yoga_yc) zysx_node = Node('注意事项', name=yoga_zysx) cjwt_node = Node('常见问题', name=yoga_cjwt) # 瑜伽类 yoga_2 = Relationship(yoga_node, '描述', ms_node) yoga_3 = Relationship(yoga_node, '益处', yc_node) yoga_4 = Relationship(yoga_node, '注意事项', zysx_node) yoga_5 = Relationship(yoga_node, '常见问题', cjwt_node) try: graph.create(yoga_2) except: continue try: graph.create(yoga_3) except: continue try: graph.create(yoga_4) except: continue try: graph.create(yoga_5) except: continue count += 1 print(count) yogadata()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
结果展示:
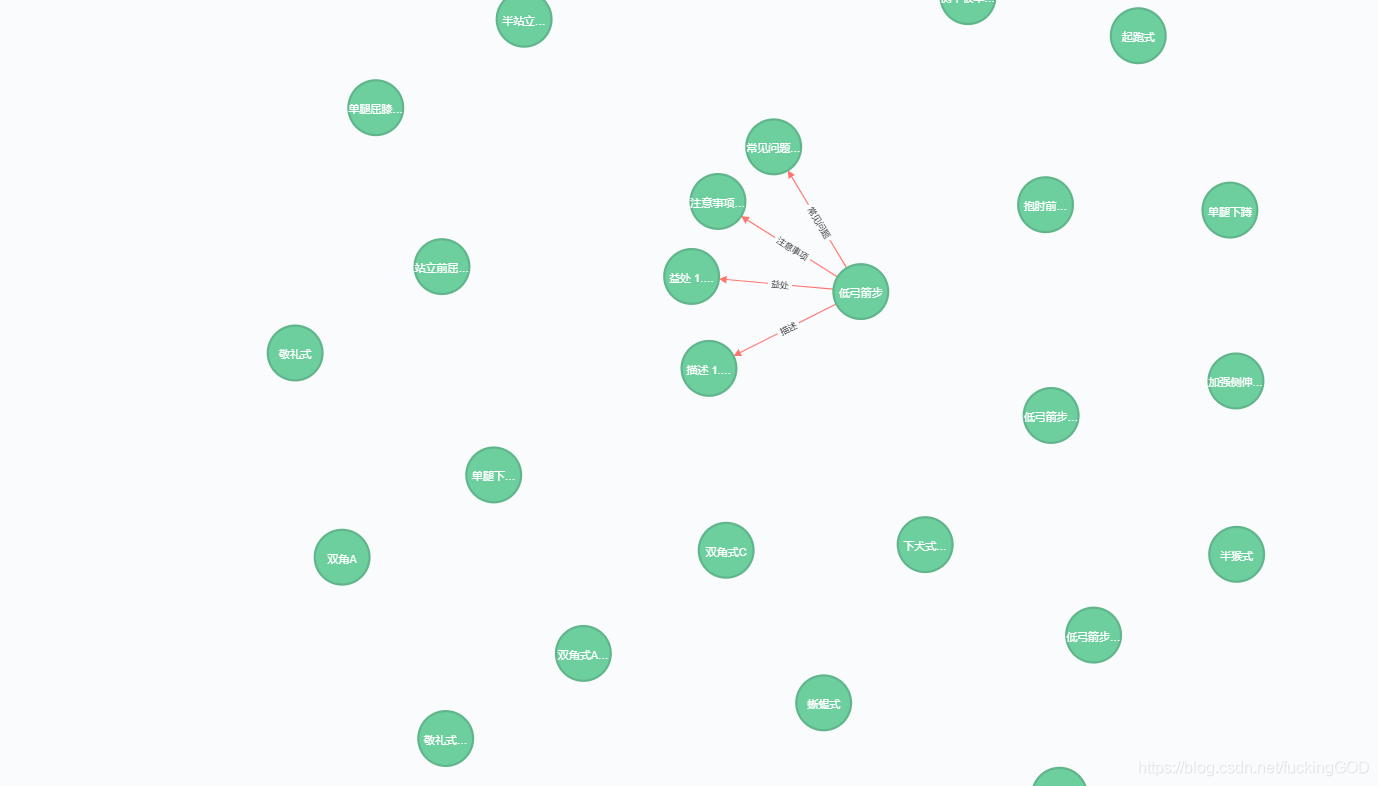
可以看到灰常完美!
如果对你有帮助,不妨一键三连,么么哒么么叽!

最后呢,我在本篇文章的基础上迭代了python 对 neo4j数据库进行连接和增删改查的一些方法,有兴趣的可以看看基础CQL语句连接neo4j数据库
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/510878
推荐阅读

相关标签

