
- 1Python常用模块12-python的xlsxwriter模块(操作excel)_xlsxwriter python
- 2论文aigc检测率为多少合格?论文ai免费润色_本科论文查重和aigc率多少
- 3如何在eclipse中安装angularjs插件_eclipse安装angularjs插件
- 4如何将一个本地Android工程导入到自己的GitHub库里并将git与项目绑定,AS、IDEA一样适用_如何把别人的代码移动到自己的github
- 5sql中如何添加数据_sql表里插数据
- 6GPT怎样教我用Python进行数据可视化_python chartgpt
- 7java程序jar包xjar加密及破解解密_jar包加密
- 8【计算机毕业设计】061医疗病历交互系统_填写诊断交互
- 9黑客 如何攻破一个网站?长文图解全流程
- 10LAMP兄弟连PHP高薪就业班2012召集令_新浪朴庆斌
Java的23种设计模式_java设计模式
赞
踩
设计模式就是对优良设计的总结,固化下来的写法,是业界公认的优雅设计。
一、创建型设计模式
1.单例模式 singleton
单例模式常见的不同写法有八种之多,真正完美无缺的只有一种枚举单例。其他单例都存在些许问题,但一般不会有人去用枚举来写单例,因为很怪,本来只是要搞个单例结果整了个枚举,我也不是太偏向这么写,一般使用:双重检查锁、静态内部类、静态属性三种写法都是可以接受的。我们经常使用的Spring框架的单例模式是从静态属性的单例模式变化而来,被称为注册表单例模式,后面也会说下。
1.1.静态属性单例模式
加载方式:饿汉
优势:无线程安全问题
唯一缺点:饿汉加载,存在加载不使用的可能,不使用则浪费内存(感觉其实不是事)
public class Single1 {
private static final Single1 singleton = new Single1();
// 核心点是私有化构造器,让外部无法进行新对象创建
private Single1() {
}
public static Single1 getInstance() {
return singleton;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.2 静态属性变种
这个和上个唯一区别是将实例化放在了静态代码块,其实和第一种基本差不多
加载方式:饿汉
优势:无线程安全问题
唯一缺点:饿汉加载,存在加载不使用的可能,不使用则浪费内存(感觉其实不是事)
public class Single2 { public static final Single2 singleTwo; static { singleTwo = new Single2(); } private Single2() { } public static Single2 getInstance() { return singleTwo; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.3 基础的懒汉模式
这是最基础的懒汉模式,所以他有不可接受的缺点
加载方式:懒汉
优点:懒加载,不存在内存泄露的问题
缺点:存在线程安全问题,并发时,单例无法保证
public class Single3 { private static Single3 instance ; private Single3() { } public static Single3 getInstance() { if (instance == null) { // 放大线程安全问题 try { Thread.sleep(2000); } catch (InterruptedException e) { throw new RuntimeException(e); } instance = new Single3(); } return instance; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
1.4 线程安全的懒加载单例
这是对上一个的改进,但是依然存在问题,虽然实现了懒加载,也增加了安全锁,但是锁的粒度太大
优点:安全、懒加载
缺点:高并发时效率不高
public class Single4 {
private static Single4 instance;
private Single4(){}
public static synchronized Single4 getInstance(){
if(instance==null){
return instance =new Single4();
}
return instance;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.5 线程安全的懒加载 单例-改进
这是对上一个的改进,改进方向是缩小锁的粒度,下面代码猛一看感觉没问题,其实再一看就会发现有安全漏洞,当并发高时,肯定存在多个线程都进入到实例为空的逻辑内部,然后排队等待锁,这时候就会重复创建对象了
加载模式:懒加载
优点:降低了锁粒度
缺点:高并发无法保证单例
public class Single5 {
private static Single5 instance;
private Single5(){}
public static Single5 getInstance(){
if(instance == null){
synchronized(Single5.class){
instance = new Single5();
}
}
return instance;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.6 双重检查锁
这被认为是一个没有缺点的单例模式,实际上他只是保证了在使用构造器创建对象时完全实现了单例,且保证了锁的粒度足够小的同时保证了线程安全性。但是我们知道创建对象java里还可以使用Cloneable的clone方法,还可以使用反射,还可以使用反序列化这些操作。这些操作其实一样式可以绕可这个单例的。
优点:懒加载、线程安全,尽最大努力降低了锁的粒度
缺点:相比于静态内部类效率稍微差点,但是生产可用
public class Single6 { private static volatile Single6 single6; private Single6(){} public static Single6 getInstance(){ // 这里加if可已在高并发时省去大部分排队加锁的操作,是有必要的 if(single6==null){ // 这里可能存在多个线程都进入的场景,所以下面的同步代码块可能存在执行多次的场景 synchronized (Single6.class){ // 因为这段代码可能存在多次执行,但是同一时间只有一个会执行,所以再进行一次非空判断就解决了问题 if(single6==null){ single6=new Single6(); return single6; } } } return single6; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1.7 静态内部类
这种单例不会有线程安全问题,线程安全由JVM保证,且是懒加载,算是一种好的设计了
加载:懒加载
优点:线程安全、懒加载、并发由JVM保证单例
缺点:基本无(抛开了反射、反序列化、克隆等创建对象的方式不谈)
public class Single7 {
private Single7(){}
private static class Singleton{
private static Single7 single7 = new Single7();
}
public static Single7 getInstance(){
return Singleton.single7;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1.8 枚举单例
这是java自身就支持的特性,java里的枚举类就是单例的,所以使用枚举来实现单例简单也简洁,不过把正常类写成枚举总感觉怪怪的。此外枚举单例还解决了上面这些单例解决不了的问题
解决反序列化破坏单例:枚举类天生支持序列化,在序列化的时候,只会序列化枚举的name,而不会序列化枚举的属性,反序列化时也是根据name找到实例返回,并不会创建新对象,所以序列化破坏不了这个单例。
解决反射场景破坏单例:反射还是利用原类的构造方法进行创建,而枚举类的实际上集成了Enum这个类,他没有空参构造,且有参构造不支持枚举类的创建,所以不存在反射的问题
解决克隆破坏单例:枚举类无法被克隆,所以不会被创建,他的clone方法是final的无法重写,所以克隆也破坏不了单例
public enum Single8 {
INSTANCE("zhangsan");
private String name;
private Single8(String name) {
this.name = name;
}
public static Single8 getInstance() {
return INSTANCE;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.9 注册表单例
这是Spring采用的单例模式,其实和静态属性差不多,只是将对象存储到了Map中,利用了Map的键不能重复的原则 实现了值的唯一,从而保证了单例。
优点:线程安全、懒加载、设计新颖(利用Map的键不重复保证了值的唯一)
缺点:高并发下存在多个线程同时创建多个对象的可能,但是不会存在多个实例
下面是笔者自己仿写的
public class Single9 { private static ConcurrentHashMap<String,Object> hashMap = new ConcurrentHashMap<>(); public static Object getInstance(String key) throws Exception{ if(hashMap.get(key) == null){ hashMap.put(key,Class.forName(key).newInstance()); } return hashMap.get(key); } // 测试 public static void main(String[] args) throws Exception{ for (int i = 0; i < 50; i++) { new Thread(()->{ try { System.out.println(getInstance("com.example.design.pattern.Single.Single9")); } catch (Exception e) { e.printStackTrace(); } }).start(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.工厂方法模式 factory
优点:集中创建对象,当创建对象的过程需要变更时只需要微调部分代码即可,因为真实场景中是有一些对象的创建是需要依赖很多的其他信息的,比如数据库连接的创建等。
下面是一个简单工厂,Spring中的工厂类似于这个
public class SimpleFactory {
public static ConcurrentHashMap<String, Object> map = new ConcurrentHashMap<>();
public static Object getInstance(String className) throws Exception{
if(map.containsKey(className)){
return map.get(className);
}
map.put(className,Class.forName(className).newInstance());
return map.get(className);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我感觉上面写法挺好,就是类似一个单例,其实常见的写法是直接return一个实例,而不是类似于Spring这种使用单例(这里并未保证单例)。而常见的return一个实例的写法就回存在一个问题,类型变换需要增加代码,这明显违反了设计模式的开闭原则,所以为了遵守开闭原则而有了下边的工厂方法模式,他不支持修改,只是对工厂类的扩展。但是新增对象后还是需要新增对应的工厂。
下工厂方法模式的代码:
// 猫类 public class Cat { private } // 狗类 public class Dog { } // 工厂顶层接口 public interface Factory<T> { public T getInstance(); } // 猫工厂 public class CatFactory implements Factory<Cat>{ @Override public Cat getInstance() { return new Cat(); } } // 狗工厂 public class DogFactory implements Factory<Dog>{ @Override public Dog getInstance() { return new Dog(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.抽象工厂模式 factory
上一个工厂的缺点就是有多少对象就得有多少个工厂,其实很麻烦,所以抽象工厂模式对上一个工厂模式是一个改进,对可以进行抽象的类进行一个抽象,从而进行减少工厂类的实现,当有一个华为品牌时,可以创建一个华为工厂用于生产多种产品,当有小米时可以为其再建一个工程,其实相对于工厂方法,就是将不同的创建归拢到了一起。但是这种写法当类型中多一个具体类时,还是要破坏开闭原则对其进行修改。
// 电视类 public class TV { } // 手机类 public class Phone { } // 电脑类 public class Computer { } // 顶层工厂 public interface Factory { public TV getInstanceTV(); public Phone getInstancePhone(); public Computer getInstanceComputer(); } // 华为工厂 public class HuaWeiFactory implements Factory{ @Override public TV getInstanceTV() { return new TV(); } @Override public Phone getInstancePhone() { return new Phone(); } @Override public Computer getInstanceComputer() { return new Computer(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.建造者模式 builder
建造者模式也是比较常用的模式了,常用的框架Lombok的注解@Builder就是将我们的实体类自动增加建造者。所以建造者就按字面意思理解即可,就是用来建造对象的模式。代码如下,核心是对外隐藏场景,只能有build方法来进行对象构建。
优点:更加关注创建对象的过程,当参数过多时使用普通构造器创建很容易搞混参数,建造者不会。核心是利用静态内部类来对创建对象进行封装。
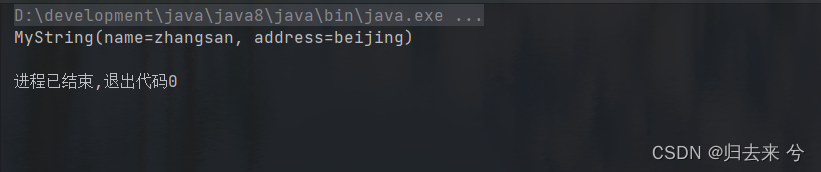
@Data public class MyString { private String name; private String address; private MyString(String name, String address) { this.address = address; this.name = name; } public static MyStringBuilder builder() { return new MyStringBuilder(); } public static class MyStringBuilder { private String name; private String address; public MyStringBuilder name(String name) { this.name = name; return this; } public MyStringBuilder address(String address) { this.address = address; return this; } public MyString build() { return new MyString(name, address); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
下面是测试代码:
public class TestBuilder {
public static void main(String[] args) {
MyString build = MyString
.builder()
.name("zhangsan")
.address("beijing")
.build();
System.out.println(build);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.原型模式 prototype
说原型模式之前先说下深浅拷贝。
- 浅拷贝:只拷贝栈中的信息为浅拷贝,基础数据类型存在栈中,所以肯定浅拷贝,引用类型的引用也是存储在占中java在进行对象赋值时只是复制了一个引用所以也是浅拷贝,所以java默认情况是浅拷贝的。
- 深拷贝:深拷贝就是将原对象的所有属性都从新复制一份形成一个新的对象,注意对象的属性也不能和原对象共用,这样才能算是原型模式
java里实现原型模式可以借助clone方法,但是也可以自己写将对象中的每个属性进行从新创建然后赋值给新对象
@Data public class DogPrototype implements Cloneable{ private Dog dog; @Override public DogPrototype clone() { try { DogPrototype clone = (DogPrototype) super.clone(); return clone; } catch (CloneNotSupportedException e) { throw new AssertionError(); } } public static void main(String[] args) { DogPrototype dogPrototype = new DogPrototype(); dogPrototype.setDog(new Dog()); DogPrototype dogPrototypeClone = dogPrototype.clone(); System.out.println(dogPrototype == dogPrototypeClone); System.out.println(dogPrototype.getDog() == dogPrototypeClone.getDog()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

从上面的输出结果可以看到,显然上面不是一个正确的原型模式,因为对象内部的属性和之前还是相同的,所以我们是需要对属性进行从新创建的,这样才能保证原型模式的正确。实现一个对象的完全复制,如下:
@Data public class DogPrototype implements Cloneable{ private Dog dog; @Override public DogPrototype clone() { try { DogPrototype clone = (DogPrototype) super.clone(); Optional.ofNullable(clone.getDog()).ifPresent(dog->{ // dog若是有属性也是需要进行操作的,其实最好是原型模式依赖的来也需要实现原型模式,那么就不需要考虑属性的属性的问题了 // 只需保证自身属性从新创建即可 clone.setDog(dog.clone()); }); return clone; } catch (CloneNotSupportedException e) { throw new AssertionError(); } } public static void main(String[] args) { DogPrototype dogPrototype = new DogPrototype(); dogPrototype.setDog(new Dog()); DogPrototype dogPrototypeClone = dogPrototype.clone(); System.out.println(dogPrototype == dogPrototypeClone); System.out.println(dogPrototype.getDog() == dogPrototypeClone.getDog()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

上面的代码需要注意,实现原型模式的对象的属性也需要时原型模式的,不然我们就需要在clone方法内部去实现(属性的属性)的原型问题了,这种设计就很沙雕了。
二、结构型设计模式
结构型的设计模式,基本都是利用现有的类或者对象组合到一起,形成更强大的结构。这一组模式里对于“合成复用原则”体现的比较明显。
1.适配器模式 adapter
适配器模式的核心是适配,将原本无法适配的场景,通过类、对象、接口等方式变得支持适配,可以使用。这就是适配器模式的核心场景。比如电脑的适配器,手机充电的适配器等。
1.1 类适配器模式
通过继承需要适配的类,然后对类中的方法进行适配,从而达到可用的目的
/** * @author pcc * 这是标准的手机生产者,但是无法满足 * 客户的需求,需要增加一些功能, */ public class SupplierPhone { public void call() { System.out.println("生产标准手机"); } } /** * 这是假设场景里真正需要的手机生产者,需要使用他来进行生产 */ public interface NeedPhone { public void myCall(); } /** * @author pcc * SupplierPhone生产的是标准手机,业务场景无法直接使用 * 所以我们需要对其进行适配,在生产我们自己手机时对其进行二次加工 * 所以这里需要继承SupplierPhone来获得他的手机生产方式 * 然后对手机进行二次加工 * * 这里最好不要让SupplierPhone 和 NeedPhone 的生产方法同名,同名的话 * 会把SupplierPhone的方法认为是NeedPhone的实现了 */ public class PhoneAdapter extends SupplierPhone implements NeedPhone{ @Override public void myCall() { System.out.println("更换手机原件"); super.call(); System.out.println("为手机增加商标"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
通过上面我们就可以使得自己的生产方法里拥有对标准手机生产改造的场景了,从而满足自己的特殊需要场景。下面是验证
public static void main(String[] args) {
PhoneAdapter phoneAdapter = new PhoneAdapter();
phoneAdapter.myCall();
}
- 1
- 2
- 3
- 4
- 5

1.2 对象适配器模式(接口适配器)
(类适配器模式+桥接模式=对象适配器模式)
类适配器,核心是通过继承需要适配的对象来实现适配,对象适配器则是通过将需要适配的对象进行引入,从而实现适配。那为什么要有这个设计呢,其实核心有两点原因:
- 1.java的类是单继承,类适配器会占用继承坑位,导致无法去继承其他类,影响扩展
- 2.类适配器无法解决需要适配接口的场景,假设上面场景中SupplierPhone是个接口,则无法使用上面的写法,所以有了对象适配
还有人把对象适配器又划分为对象适配和接口适配的(按照适配的是类和接口来区分),其实他俩没啥区别,所以一般认为都是对象适配器。
// 需要适配的对象从类变成了接口,当然这里是类也依然是可以的 @FunctionalInterface interface SupplierPhoneInterface{ void myCall(); } /** * 这是假设场景里真正需要的手机生产者,需要使用他来进行生产 * 这个还是自己的生产手机的地方,这个没动 */ public interface NeedPhone { public void myCall(); } /** * 适配器 * @author pcc * 对象适配和类适配的区别是,对象适配是引入一个待适配的对象 * 而类适配则是通过继承来实现,类适配无法处理接口需要适配的场景,且占用继承坑位不利于扩展 * 这里使用的NeedPhone还是上面代码的NeedPhone * 新增SupplierPhoneInterface 这是待适配的接口 */ public class ObjectPhoneAdapter implements NeedPhone { SupplierPhoneInterface supplierPhoneInterface; public ObjectPhoneAdapter(SupplierPhoneInterface supplierPhoneInterface){ this.supplierPhoneInterface = supplierPhoneInterface; } @Override public void myCall() { System.out.println("更换原手机组件"); supplierPhoneInterface.myCall(); System.out.println("为手机贴标"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
上面就是对象适配器模式了,核心就是将需要适配的对象通过构造方法传入,而不是通过继承实现,因为是通过传入,所以既可以支持对象也可以支持接口实现类。下面是测试
/**
* @author pcc
*/
public class TestObjectAdapter {
public static void main(String[] args) {
// 对象适配器,传入接口实现类
ObjectPhoneAdapter objectPhoneAdapter = new ObjectPhoneAdapter(()->{
System.out.println("我生产标准手机");
});
objectPhoneAdapter.myCall();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

其实完全可以把我们写的Service层的实现类,看成对象适配模式:ServiceImpl中需要维护一个Mapper接口,然后我们是对Mapper接口进行一些处理,增加一些逻辑,最后返回一个新的结果给到客户端。其实是可以看成适配器模式的代码,但是这里作用不是为了适配,而是为了增强,看作用更像是装饰模式,但是代码结构和对象适配器模式更像。
2.桥接模式 bridge
桥接模式的核心是解耦抽象和实现,抽象部分不集成在使用端进行变化,而是将变化进行独立。从而达到了提高代码的灵活性和可扩展性。
假设我们需要一杯coffee,我们可以选择杯子的大小,是否加冰。此外还有我们无需选择的比如使用咖啡豆进行制作coffee。那这里的杯子的大小,可能是大杯、中杯、小杯。是否加冰也是有多重选择:多冰、少冰、不加冰。在这个场景里杯子的大小就是一个抽象,大小的不同就是抽象的不同实现。是否加冰也是如如此。对于这种场景最原始的做法是抽象一个抽象类出来CupSize、IfIce。我们如果想要一个大杯咖啡,那就是继承抽象类,然后定义杯子大小和是否加冰。到这里就会发现:好像不能多继承,所以这种方式有很大的短板,不仅不能多继承,而且还提升了代码的耦合度,将抽象与实现耦合在了一起。怎么解决就需要引入桥接模式了:桥接模式关注的核心点是解耦抽象和是实现
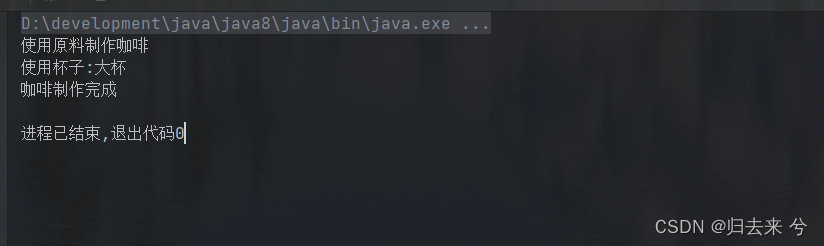
/** * @author pcc * 这是桥接模式类 * 通过使用抽象的尺寸大小的对象,而不是继承抽象类,从而实现分类抽象和实现的目的。 * */ public class SupplierCoffee { CupSize cupSize; public SupplierCoffee(CupSize cupSize){ this.cupSize = cupSize; } public void doSupplierCoffee(){ System.out.println("使用原料制作咖啡"); System.out.print("使用杯子:"); cupSize.size(); System.out.println("咖啡制作完成"); } } /** * @author pcc * 因为杯子有多种尺寸,所以对杯子的共性进行抽象,定义一个抽象类 * 不同的尺寸对应不同的子类,子类中定义自己的特有属性,这里假设只有尺寸不同 */ public abstract class CupSize { public abstract void size(); } class BigCupSize extends CupSize{ @Override public void size() { System.out.println("大杯"); } } class MiddleCupSize extends CupSize{ @Override public void size() { System.out.println("中杯"); } } class LittleCupSize extends CupSize{ @Override public void size() { System.out.println("小杯"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
== 上面就是桥接模式的代码了,他的核心是分离抽象和实现,对抽象和实现进行解耦。从而达到提高代码的可用性和扩展性。猛一看可能感觉桥接模式和对象适配器有些类似,其实是不同的,只不过他们都是结构型适配都是遵循组合复用原则,所以猛一看有些相似。对象适配关注的是对现有接口方法或者类方法的改造,而桥接模式关注的是抽象和实现的分离,非要对比的话,感觉对象适配器模式应该在桥接模式的上面,比如如果桥接模式提供的子类不能满足我们的需要,我们是可以对桥接的对象进行适配的。所以说他们的关注点不同。一个关注在对象的不同实现,一个关注的是对象的方法合不合用。==
下面是测试:
/**
* @author pcc
*/
public class TestBridge {
public static void main(String[] args) {
SupplierCoffee supplierCoffee = new SupplierCoffee(new BigCupSize());
supplierCoffee.doSupplierCoffee();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.组合模式:Composite /ˈkɒmpəzɪt/
组合模式应用场景主要是在树形结构的数据中如:组织、文件系统、UI元素等。组合模式主要解决使用端对不同的节点需要不同的方法来处理的弊端问题。比如下面的例子,处理国家、省份等都提供一套方法就很麻烦,我们完全可以将不同的组织抽象成一个抽象类,客户端处理时,面向抽象类来处理,而不关心真正的实现(这里只能是处理各个组织都拥有的共性属性)。从而实现降低客户端与各个对象的耦合,提升代码的可读性。
树形结构的数据中的不同数据一般都具有一些共性,我们是可以将他们的共性进行抽取,然后形成一个抽象类。以行政区划为例来说下,中国的行政区划包含中国、中国下面有34个省级行政区划,34个省级下面还有不同的市级等。那么行政区划就是我们抽象出来的抽象类他需要包含不同组织的相同共性。而针对不同的组织我们是需要有不同的实现类的,比如国家、省、市等不同抽象类。他们又拥有各自不同的特有属性。
组合模式关注的核心点是:抽离对象共性,从而降低客户端与对象的耦合度,实现客户端可以调用一个方法对所有对象的都可以操作。组合模式的弊端:结构比较简单时实用组合模式反而增加复杂度,所以设计模式不应该强行使用。
import lombok.Data; import lombok.experimental.Accessors; import java.util.List; /** * @author pcc * 这是将行政区划抽象出来的一个抽象的组织类 * 假设只抽离除了名称、编码、子节点三个属性 */ @Data public abstract class Organization { private String name; private String code; private List<Organization> children; } /** * 国家类 */ @Accessors(chain = true) class Country extends Organization { public void supplierRMB(){ System.out.println("我是国家,我可以印钱"); } } /** * 省类 */ @Accessors(chain = true) class Province extends Organization { public void manageCity(){ System.out.println("我是省,我可以管理市"); } } /** * 市类 */ @Accessors(chain = true) class City extends Organization{ public void cry(){ System.out.println("我是底层人民,只能哭泣"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
组合模式代码就是上面了,抽象了组织的共同属性,这样客户端在进行操作共同属性时,就无需关心到底是哪个节点了,只需要面对抽象类即可实现操作了。简化了客户端的操作,解耦了客户端与不同对象的耦合。
需要注意的是组合模式一般得用递归去遍历所有元素,这其实对性能上是有一定损耗的。
下面是测试代码:
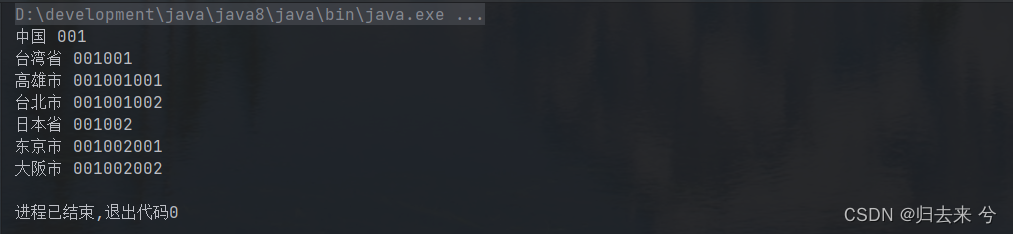
import java.util.ArrayList; import java.util.List; import java.util.Optional; /** * @author pcc */ public class TestComposite { public static void main(String[] args) { Organization organization = new Country(); organization.setName("中国"); organization.setCode("001"); Organization province1 = new Province(); Organization province2 = new Province(); province1.setName("台湾省"); province1.setCode("001001"); province2.setName("日本省"); province2.setCode("001002"); Organization city1 = new City(); Organization city2 = new City(); Organization city3 = new City(); Organization city4 = new City(); city1.setName("高雄市"); city1.setCode("001001001"); city2.setName("台北市"); city2.setCode("001001002"); city3.setName("东京市"); city3.setCode("001002001"); city4.setName("大阪市"); city4.setCode("001002002"); // 组合属性结构 List<Organization> listProvince = new ArrayList<>(); listProvince.add(province1); listProvince.add(province2); // 台湾省 List<Organization> listCity = new ArrayList<>(); listCity.add(city1); listCity.add(city2); // 日本省 List<Organization> listCity2 = new ArrayList<>(); listCity2.add(city3); listCity2.add(city4); organization.setChildren(listProvince); province1.setChildren(listCity); province2.setChildren(listCity2); // 假设我们的业务场景是获取每个组织的名称和编码 outPut(organization); } // 递归遍历 public static void outPut(Organization organization){ Optional.ofNullable(organization).ifPresent(org -> { System.out.println(org.getName() + " " + org.getCode()); // 存在子节点 Optional.ofNullable(org.getChildren()).ifPresent(children -> { children.forEach(TestComposite::outPut); }); }); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
下面是运行截图
4.装饰模式 Decorator /ˈdekəreɪtə®/
装饰模式的核心是在于不改变原接口的情况下实现对原接口方法的增强。猛一看会感觉他和对象适配模式有些像,其实区别还是挺明显的。
- 类适配模式,是有自己的接口然后将自己的方法区适配标准方法
- 装饰模式,用的还是原接口,是对原接口的一个增强
不过他们在思想上是一致的,下面的代理模式中的静态代理,才是和装饰模式在代码上傻傻分不清,可以说一模一样了。
/** * 这是建造房子的接口 * 假设这个接口有一个建造方法的方法,createRoom * 他有一个实现类BuildRoomImpl,这个类负责真正去建造一个房子 * 这里对实现类BuildRoomImpl进行装饰,增加一些功能 */ public interface BuildRoom { void createRoom(); } class BuildRoomImpl implements BuildRoom{ @Override public void createRoom() { System.out.println("建造了一个房子"); } } /** * @author pcc * 这里是一个简单写法,若是建造房子有多个子类且要求 有不同的装饰 * 则我们需要创建多个装饰类,这里只是写了单个的子类场景,不过若是装饰都相同,也可以面向BuildRoom * 进行装饰,这种只需要一个装饰类即可 */ public class BuildRoomDecorator implements BuildRoom{ private BuildRoom buildRoom; public BuildRoomDecorator(BuildRoom buildRoom) { this.buildRoom = buildRoom; } @Override public void createRoom() { buildRoom.createRoom(); System.out.println("为房子增加装饰:粉刷墙面"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
上面就是装饰模式的代码了,其实在效果上他和对象适配器很像。因为都是结构型的设计模式,他们都有一个核心,那就是组合复用,基本都是围绕这一个核心点的。所以看起来很像。
5.代理模式 proxy
代理模式一般是说静态代理,此外java还提供了动态代理,动态代理当然是根据静态代理来实现的,只不过不需要我们自己写代理类了,jdk会帮助我们自动进行生成,此外cglib也有一套动态代理,不过他的原理就和jdk的不同了,而且他还支持对类的代理,不像jdk只能代理接口的。
代理模式的核心是对于代理类的访问控制,实现对原类型方法的访问控制。但是在实现和操作上和装饰模式基本没区别,而且Spring使用代理模式做AOP,明显不是对类的访问控制,而是对于原始方法的一个装饰,更像是装饰者模式,所以他们很容易混,但笔者感觉无需分的这么清晰,本来设计模式就是为了让代码更优雅,解耦提高复用性的,无论装设模式还是代理模式,他们都能达到我们想要的目的,就是个名称而已。所以不要被名称欺骗了,重要的是会用。
5.1 静态代理
普通的代理模式被称为静态代理,他是相对于动态代理来说的,代码和装饰模式没有区别。
假设存在这种场景:有一个药品生产的接口,定义了药品生产和检查。云南白药想要生产自己的药品,就需要实现这套标准。现在我想要代理云南白药的药品,对药品需要二级包装。
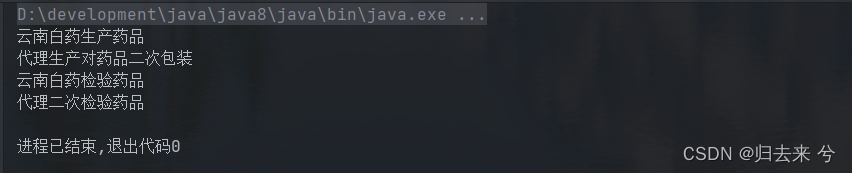
/** * @author pcc * 静态代理和装饰模式代码上基本相同 * 假设有一个药品接口:drug /drʌɡ/,他有两个抽象方法 * 1. 生产药品 * 2. 检验药品 * 他有一个实现类云南白药 YunNanBaiYaoSupplierDrug * 现在我想要做云南白药药厂生产的药的代理 * */ public interface SupplierDrug { public void produceDrug(); public void checkDrug(); } // 云南药厂 class YunNanBaiYaoSupplierDrug implements SupplierDrug { @Override public void produceDrug() { System.out.println("云南白药生产药品"); } @Override public void checkDrug() { System.out.println("云南白药检验药品"); } } // 代理云南药厂 class ProxyYunNanBaiYaoSupplierDrug implements SupplierDrug { private SupplierDrug supplierDrug; public ProxyYunNanBaiYaoSupplierDrug(SupplierDrug supplierDrug) { this.supplierDrug = supplierDrug; } @Override public void produceDrug() { supplierDrug.produceDrug(); System.out.println("代理生产对药品二次包装"); } @Override public void checkDrug() { supplierDrug.checkDrug(); System.out.println("代理二次检验药品"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
这就是静态代理模式了,可以说和装饰模式基本一样了,下面是测试:
/**
* @author pcc
*/
public class TestProxy {
public static void main(String[] args) {
SupplierDrug supplierDrug = new ProxyYunNanBaiYaoSupplierDrug(new YunNanBaiYaoSupplierDrug());
supplierDrug.produceDrug();
supplierDrug.checkDrug();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注意静态代理是支持代理抽象类和普通类的,即使不是接口我们也是可以做代理的。只需要去继承即可,只不过java单继承,使用继承方法影响扩展,所以一般都是设计成接口。
5.2 JDK动态代理
之所以有动态代理,是因为静态代理每次需要写代理类,其实我们可能只想要代理其中一个方法,但是不得不必须去写一个代理类,因为是接口还得实现接口的所有方法,这其实不够友好。所以才有了动态代理。
import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; import java.lang.reflect.Proxy; /** * @author pcc */ public class TestDynamicProxy implements InvocationHandler { private Object target; public TestDynamicProxy(Object target) { this.target = target; } @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { //只代理生产药品的方法 if("produceDrug".equals(method.getName())){ System.out.println(proxy.getClass().getName() + " invoke method " + method.getName() + " begin..."); System.out.println("动态代理前置操作"); Object result = method.invoke(target, args); System.out.println("动态代理后置操作"); System.out.println("返回参数:"+result); return result; } return method.invoke(target, args); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
上面是动态代理的代码,其实很简单就是实现InvocationHandler接口重写invoke方法就行了。一般使用动态代理都是对一类方法进行代理,对于单个方法进行代理的也有不过会少一些。那如何使用呢,只有这些怎么来操作动态代理呢,下面是使用的代码,使用时我们需要为Proxy.newInstance传入三个参数,①类加载器,②接口列表,③InvocationHandler的实现类。JDK通过类加载器来加载传入接口列表自动生成的实现类,这个实现类中就是将nvocationHandler的Invoke方法进行编织到目标方法上,从而实现动态代理。
public static void main(String[] args) {
SupplierDrug yunNanBaiYaoSupplierDrug = new YunNanBaiYaoSupplierDrug();
SupplierDrug supplierDrug= (SupplierDrug)Proxy.newProxyInstance(
// 传入类加载器
yunNanBaiYaoSupplierDrug.getClass().getClassLoader(),
// 传入类接口列表
yunNanBaiYaoSupplierDrug.getClass().getInterfaces(),
// 传入handler实现类
new TestDynamicProxy(yunNanBaiYaoSupplierDrug)
);
supplierDrug.produceDrug();
supplierDrug.checkDrug();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
真正使用时是可以对上面操作进行封装,不然看着挺难看,他们三个参数其实只穿一个被代理的对象和InvocationHandler的实现类即可。
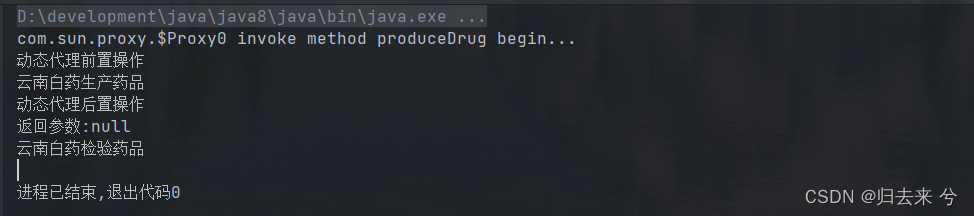
那为什么jdk动态代理不能代理类呢而只能代理接口?一句话java是单继承,因为jdk动态代理生成的最终代理类继承了Proxy这个代理类,这个代理类有一个属性h,指向的就是我么自己编写的InvocationHandler类,最终的代理类通过继承Proxy获得了invoke方法,然后最终的代理类还实现了我们传入的接口,这样就可以重写接口方法然后调用invoke了。这样就实现了cglib的动态代理,也因此直支持类的动态代理了。
5.3 CGLIB动态代理
JDK的动态代理具有鲜明的特点是只能代理接口,那若是一个类没有实现接口或者实现的是抽象类,则使用JDK动态代理就会报错,他会告诉你类型转换的错误。所以Spring中只使用JDK动态代理是无法解决问题的,所以Spring还是用了CGLIB的动态代理。CGLIB底层使用的是一个叫ASM的框架,这个框架支持对字节码的编辑,可以直接更改编译后的信息,这样实现代理自然也是可以的。因为本来java也是支持普通类的代理的。
import org.springframework.cglib.proxy.Enhancer; import org.springframework.cglib.proxy.MethodInterceptor; import org.springframework.cglib.proxy.MethodProxy; import java.lang.reflect.Method; /** * @author pcc */ public class TestCGLIBDynamicProxy implements MethodInterceptor { // 注意final类型的参数,要么在静态代码块初始化,要么在构造函数初始化,要么就是直接初始化,其他不支持了 Object object; public TestCGLIBDynamicProxy(Object object) { this.object = object; } @Override public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable { if("checkDrug".equals(method.getName())){ System.out.println("增强前"); Object invoke = method.invoke(object, objects); System.out.println("增强后"); return invoke; } return method.invoke(object, objects); } // 下面是测试代码 public static void main(String[] args) { // 增强器 Enhancer enhancer = new Enhancer(); // 设置代理类的父类,这里可以是被代理类,也可以是他的父类或者接口,这里 enhancer.setSuperclass(YunNanBaiYaoSupplierDrug.class); // 设置MethodInterceptor的实现类,MethodInterceptor的intercept方法会在调用代理类的方法时调用 enhancer.setCallback(new TestCGLIBDynamicProxy(new YunNanBaiYaoSupplierDrug())); // 创建代理类 SupplierDrug supplierDrug = (SupplierDrug) enhancer.create(); // 调用代理类的方法 supplierDrug.produceDrug(); supplierDrug.checkDrug(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
下面是运行截图:
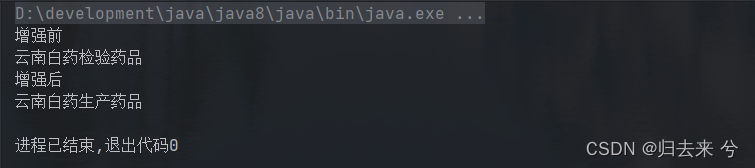
总结代理模式,其实还是cglib的代理其实更优秀一些。上面笔者用的其实是Spring提供的一套cglib的实现,api和cglib的一模一样,所以用起来没有任何感觉,如果想用原生cglib的可以引入cglib的包,将其中 的类换成cglib的即可。类名方法名等都和cglib一模一样。
6.外观模式 facade /fəˈsɑːd/
外观模式是一个简单的结构型模式,他的核心时:统筹一复杂的流程,然后对外暴露出的接口只是一个,自己内部将复杂流程进行处理操作。从而实现对外的简洁化。这种模式其实引用场景很多。举一个例子你需要请假:我们需要先填写审批单、然后在进行提交、提交后再进行审核、审核完成后还需要将请假单给到考勤。这个过程其实是很繁琐臃肿的,那么我们就可以使用外观模式,简化我们的操作,对外暴露的接口就是一个提起请假的接口就行了,剩下的自动化流程处理。
外观模式,有的也叫门面模式,很明显是为了简化流程的。
/** * @author pcc */ public class TestFacade { public void funOne(){ System.out.println("填写请假信息"); } public void funTwo(){ System.out.println("找留到审批请假"); } public void funThree(){ System.out.println("将请假信息交给考勤人员"); } public void funFour(){ funOne(); funTwo(); funThree(); } public static void main(String[] args) { new TestFacade().funFour(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
7.享元模式 Flyweight /ˈflaɪweɪt/
享元模式也是一种比较简单的结构型模式,他的核心思想是共享可以共享的部分,尽量减少内存的压力。比如Java里的String对象就是一种享元模式的设计,如果我们新建两个相同的String对象,那么字符串在常量池中只会存在一份,他并没有进行重复存储相同的对象,而是去共用一份。包括基本数据类型也是如此,他们在栈中也都是共用的。享元模式就是这个思路:比如一个工程中需要很多地方使用一个对象,这个对象只需要一个,那我们只需要为这个工厂创建一个对象即可,然后大家一起用。这里其实就是单例了。但是他们是从不从角度对代码的优化,只是最后走到了一起。(享元模式和原型模式在理念上正好相反,他们适合相反的场景)
// 这里就以单例来举例吧 /** * @author pcc */ public class TestFlyweight { static class TestFlyweightInner{ private static final TestFlyweight testFlyweight = new TestFlyweight(); } private TestFlyweight(){ } public static TestFlyweight getInstance(){ return TestFlyweightInner.testFlyweight; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
到这里结构型的设计模式就都完了,结构型设计模式最突出的原则就是“组合复用原则”。看完可能会感觉有些模式很相似,其实有些类似的设计模式是下面三个,其他模式都是各有特点
- 适配模式:类适配、对象适配,对象适配和下面有些像,不过适配模式的核心是关注方法的适配,而不是增强和装饰
- 装饰模式:继承接口对原方法进行装饰,功能扩展,类同样支持,只是扩展性不好
- 代理模式:代码和上面不同,主要是使用不同,主要用于做一些和主体功能无关的动作,比如日志,异常等
以下模式特点比较鲜明 - 组合模式:处理树形结构的数据,核心思想是抽离共性,简化客户端的操作,解耦
- 桥接模式:比较简单,核心是将抽象与实现进行分离解耦,使用不关心实现,只关心抽象的类,由调用放再指定具体实现类
- 外观模式:比较简单,对繁琐的步骤进行封装,对外暴漏统一接口,简化操作
- 享元模式:比较简单,相同部分实现共享,从而降低内存压力
三、行为型设计模式
行为型设计模式关注的是系统中对象之间的交互,研究系统在运行时对象之间的通信与协作。
1.解释器模式
解释器模式顾名思义就是用来做解释使用的。他并没有什么标准的格式,一般用来做解析时使用,比如JVM解析栈针中的指令,这就可以看成解释器模式,只不过语言不是java了。同样我们自己也可以写一种我们自定义的语言,然后写一个解释器来运行这个语言。事实上解释器模式基本是用不到的。这里有一个大佬写的挺好,可以参考:
解释器模式
2.模版方法模式 template method
模板方法模式,在日常代码中是随处可见的,这点在java的源码中体现的尤为明显。模版方法模式的核心是:使用顶层类或者接口来定义一些方法,对于逻辑确定的方法进行实现,对于不确定的则交给子类进行实现,子类只负责其中一部分功能的实现就可以使用一个完整的功能。比如java中的函数式接口对于模版方法模式使用的就比较频繁,常见的Consumer、Function、Predicate等,都有使用这种设计风格。以Predicate进行举例(只使用两个方法来进行说明)。
@FunctionalInterface public interface Predicate<T> { /** * 这是函数式接口唯一的抽象方法 * 也就是模版方法模式中,不确定的方法内容,需要子类进行实现的 */ boolean test(T t); /** * 这是一个默认方法,有自己的实现,他是对test方法的一个处理 * 判断两个test返回都为真时他则为真,他是一个确定的实现,不定的是test,需要子类进行实现。 */ default Predicate<T> and(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) && other.test(t); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这就是模版方法模式,模版方法模式的核心是提供模版方法让子类实现,但同时又定了了模版方法的使用规则,子类 只需要关系模版方法的实现,而不用关心使用方法的创建和修改,此外模版方法 模式还有一个比较亮眼的优点:当我们需要对变更的方法进行修改时,若是使用的模版方法模式,则只需要对其实现类进行修改,而不是去修改一坨需要看很久的代码了,这很利于代码的扩展,利于后期维护。
假设有这种场景:一个业务流程结束以后,我们需要做一些操作,但是这个操作呢可能存在很多场景,也有可能会发生变更,他是不确定的,所以我们可以使用模版方法模式,代码如下:
/** * @author pcc * 这是完成流程的接口,完成流程时我们将数据的状态进行更新记录日志等这是一个固定操作 * 此外可能还有需要通知三方系统等,但不确定有哪些三方系统 * 这里使用的是函数式接口来实现场景,无论是函数式接口还是普通类、抽象类都是可以的 */ @FunctionalInterface public interface CompleteProcess { /** * 这是一个抽象方法:供子类实现 */ void notifyThirdSystem(); /** * 完成的流程是确定的,我们唯一不确定的是通知的系统 */ default void complete(){ System.out.println("更新数据状态"); notifyThirdSystem(); System.out.println("记录日志"); } } /** * 这是子类 */ class DealProcess implements CompleteProcess{ /** * * 子类只负责这个方法,其他方法由父类实现 * 此外若是这个实现变动,也无需改动父类 */ @Override public void notifyThirdSystem() { System.out.println("通知三方系统:A"); System.out.println("通知三方系统:B"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
上面就是模版方法模式的代码了,下面是测试代码:
/**
* @author pcc
*/
public class TestTemplateMethod {
public static void main(String[] args) {
DealProcess process = new DealProcess();
process.complete();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
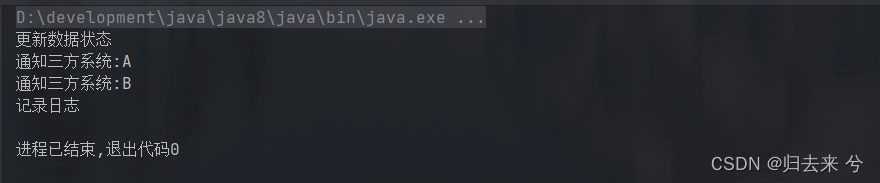
3.责任链模式 chain of responsibility
责任链模式比较重要,在实际应用场景中比较多,而且使用责任链是可以解决很多问题的。先说下责任链模式的核心:他的典型特点是一个请求需要被多个结点处理,且每个结点的需要依赖上个结点处理完成后才能开始。此时我们就可以使用责任链模式了
- 责任链模式解耦请求的发送者和处理者(对于多个处理者,请求者只需要把请求发送给第一个处理者即可)
- 责任链支持动态的添加、移除处理者,灵活性高,方便扩展
假设有如下的场景:一个新增场景的业务流程,请求者是只需要发起请求,后面后多个审核节点,每个审核节点都需要依赖前一个审核完成的动作才能开始。那这就是一个典型的可以使用责任链的场景。下面是代码演示:
/** * 这是定义的顶层的处理器抽象类,所有的处理器,都是需要是吸纳处理方法 * 然后通过next方法获取到下一个结点,来设置链式调用 */ public abstract class DealProcess { DealProcess next; abstract void process(); // 这里返回this其实也可以,只不过到时候调用方式就得改变,且不好看,使用next更直观易于理解,代码更优雅 DealProcess next(DealProcess next){ this.next = next; return next; } } /** * @author pcc */ public class DealProcessOne extends DealProcess{ @Override public void process() { if(next != null){ System.out.println("执行处理1"); next.process(); }else{ System.out.println("执行最终节点"); } } } /** * @author pcc */ public class DealProcessTwo extends DealProcess{ @Override public void process() { if(next != null){ System.out.println("执行处理2"); next.process(); }else{ System.out.println("执行最终节点"); } } } /** * @author pcc */ public class DealProcessThree extends DealProcess{ @Override public void process() { if(null!=next){ System.out.println("执行处理3"); next.process(); }else { System.out.println("执行最终处理"); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
上面就是责任链的代码了,其实也很简单,最上层的处理器抽象类使用接口也可以,不过接口不支持声明变量,变量的操作就需要增加到子处理器中,这样增加了代码复杂度,所以使用抽象类作为顶层的处理器更合适。这样每个处理器都只需要关注处理操作即可。而无需关系其他动作,解耦了无关操作。下面是测试方法:
/**
* @author pcc
*/
public class TestDealProcess {
public static void main(String[] args) {
DealProcess dealProcess = new DealProcessOne();
dealProcess.next(new DealProcessTwo()).next(new DealProcessThree());
dealProcess.process();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

这就是责任链了,应用起来很简单,而且可以很方便的替换各个节点。
在java中比较典型的责任链就是Filter的调用链了,当我们自己实现一个Filter时,需要实现他的doFilter方法,如下
class TestFilter implements Filter{
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
chain.doFilter(request, response);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
当执行完毕后我们都需要去执行一个chain.doFilter(request, response)这个命令,他的作用其实就是开始执行下一个Filter的。在FilterChain的实现ApplicationFilterChain中他的调用动作是这样的:doFilter---->internalDoFilter---->filter.doFilter。通过这种形式完成了对下一个Filter的调用。这里可能会存在的疑问点:这个filter时哪里来的?我们使用FIlter无论是原始的配置servlet还是使用WebFilter注解,都会再项目启动时将所有的Filter进行加载,然后给到FilterChain的实现类,形成一个Filter的数组,FilterChain就是通过维护这个数组来进行Filter链调用的。当然这种模式与上面的例子略有区别,上面的例子我们是通过链表的形式来维护调用链的,而Filter是通过数组来进行维护调用链,其实都是可以的。
4.命令模式 command
命令模式的核心是:减少调用者和接收者的耦合,方便扩展。
假设有这种场景:一个遥控器需要给电视发送开机和关机的命令。假如不使用命令模式,我们可能会这么做,点击开机按钮,我们调用电视的开机接口实现开机。那假如遥控对象换成空调,我们又需要重新定义一个空调的遥控器。而且我们每次直接面向命令的接收者编程代码也不优雅。这种场景下我们就可以使用命令模式了。命令模式的核心就是解耦请求和实现。下面是代码:
/** * @author pcc * 命令都是需要接收者执行的,这里的TV就是接收者 */ public class TV { public void powerOn() { System.out.println("TV power on"); } public void powerOff() { System.out.println("TV power off"); } } /** * @author pcc * 命令模式的核心就是命令的抽象类,所有命令都需要实现这个抽象类 * 每个命令是一个具体的命令类,每个命令类都只实现一个命令,每个命令类都只完成一项功能 * 调用者通过调用命令对象的execute方法来执行命令 * 命令模式的核心是抽象命令类,每个具体的命令类都是抽象命令类的子类,每个具体的命令类都完成具体的功能。 * 命令模式把本来复杂的代码,抽离出来,形成一个个命令类,这样会更直观更容易理解。代码也更容易维护、扩展 */ public abstract class Command { public abstract void execute(); } class PowerOnCommand extends Command { TV tv; public PowerOnCommand(TV tv){ this.tv = tv; } @Override public void execute() { tv.powerOn(); } } class PowerOffCommand extends Command { TV tv; public PowerOffCommand(TV tv){ this.tv = tv; } @Override public void execute() { tv.powerOff(); } } /** * @author pcc * 这是遥控器类,负责统筹各种命令 */ public class RemoteController { private Command PowerOnCommand; private Command PowerOffCommand; public RemoteController (Command PowerOnCommand, Command PowerOffCommand) { this.PowerOnCommand = PowerOnCommand; this.PowerOffCommand = PowerOffCommand; } public void powerOn () { PowerOnCommand.execute(); } public void powerOff () { PowerOffCommand.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
上面就是命令模式的代码了,他最鲜明的特点就是解耦请求和执行者,通过加入命令这一中间商,从而解开两者的耦合,实现代码的可读性、扩展性等方面的提高。下面是测试代码:
/**
* @author pcc
* 当真正使用时代码的清晰度就会非常高了,而不会看着都是一坨,
* 同时解耦了命令的发送者和执行者,两者之间没有直接引用,而是通过命令对象进行command的调用
* 这样就避免了调用者与接收者之间的耦合。
* 命令模式的关键在于引入了命令对象,将调用者与接收者解耦。
*/
public class TestCommand {
public static void main(String[] args) {
TV tv = new TV();
RemoteController remoteController = new RemoteController(new PowerOnCommand(tv),new PowerOffCommand(tv));
remoteController.powerOn();
remoteController.powerOff();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

5.迭代器模式 iterator
迭代器模式,应该所有人都用过,因为java里的集合类都和迭代器有关,他们都直接或者间接实现了迭代器接口,Map是通过他的key实现的。迭代器模式主要是定义了迭代的规则,方便集合和数组的遍历。Java里提供了Iterator接口用以实现我们自己的迭代器,下面仿写一个ArrayList。用以实现我们自己的迭代器(日常开发中感觉不会自己写的,使用java提供的已经完全足够了)。但是自己写一个集合挺有意思,但是需要考虑的场景太多了,不如直接用。
import java.util.Iterator; /** * @author pcc * 这里继承的是Iterable接口,而不是Iterator接口,注意 */ public class MyArrayList<T> implements Iterable<T>{ private static Integer index = 0; T[] t ; // 内部容器数组需要初始化 public MyArrayList(T[] t){ this.t = t; } public MyArrayList add(T t){ this.t[index++]=t; return this; } @Override public Iterator<T> iterator() { return new MyIterator(); } // 需要一个Iterator的实现 private class MyIterator implements Iterator<T>{ int cursor = 0; @Override public boolean hasNext() { return cursor<t.length; } @Override public T next() { return t[cursor++]; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
上面是自己定义了一个迭代器MyArrayList需要实现Iterable,它内部有一个Iterator的接受方法,所以还需要提供一个Iterator对象。下面是测试代码:
/** * @author pcc */ public class TestMyArrayList { public static void main(String[] args) { MyArrayList<String> myArrayList = new MyArrayList<>(new String[10]); myArrayList.add("a"); myArrayList.add("b"); myArrayList.add("c"); myArrayList.add("d"); myArrayList.add("e"); myArrayList.add("f"); myArrayList.add("g"); myArrayList.add("h"); myArrayList.add("i"); myArrayList.add("j"); for (String s : myArrayList) { System.out.println(s); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
6.中介者模式 mediator /ˈmiːdieɪtə®/
中介者模式的核心是解决复杂的多对多关系,将其简化为简单的一对一。单个对象的事件的处理只需要单向的通过中介者来操作即可,实现与中介者的一对一,中介者与目标则是一对多的关系。
假设有这样的场景:很多人想买房,很多人也想卖房,但是他们之间存在信息差。此时就需要房产中介来做中介者了。
import java.util.HashMap; import java.util.Map; /** * @author pcc * 这是中介者模式的中介:房产中介 */ public class Mediator { // 中介者需要存储被注册的房客和房主的信息 Map<String,String> map = new HashMap<>(); // 注册房客和房主 public void register(String key,String value){ if(map.containsKey(key)){ return; } map.put(key,value); } // 获取房客和房主的信息 public String get(String key){ if(map.containsKey(key)){ return map.get(key); } return null; } } import lombok.AllArgsConstructor; import lombok.Data; /** * @author pcc */ @Data @AllArgsConstructor public class SellPerson { String name; String address; // 把房子交给中介 public void sellRoom(Mediator mediator) { mediator.register(this.name,this.address); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
其实很简单,就是简化多对多关系,将他们封装,这样就可以大大简化系统的复杂度,将杂乱的关系梳理清晰。代码很简单,思路也比较清晰。下面是测试代码:
/** * @author pcc */ public class TestMediator { public static void main(String[] args) { Mediator mediator = new Mediator(); SellPerson sellPerson = new SellPerson("金城碧桂园1","12栋1单元201"); SellPerson sellPerson2 = new SellPerson("金城碧桂园2","12栋1单元202"); SellPerson sellPerson3 = new SellPerson("金城碧桂园3","12栋1单元203"); sellPerson.sellRoom(mediator); sellPerson2.sellRoom(mediator); sellPerson3.sellRoom(mediator); // 下面假设是买方动作 if(null!=mediator.get("金城碧桂园1")){ System.out.println("周到目标:"+mediator.get("金城碧桂园1")); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

7.备忘录模式 memento /məˈmentəʊ/
备忘录模式的核心就是将对象作为临时状态进行存储,在需要的场景下支持对历史信息的恢复。常见的场景比如,使用在线的腾讯文档或者飞书文档等,都是支持对历史版本进行回溯的,这其实就是备忘录模式。但是备忘录模式好是好,他非常占用资源,当对象比较大时对磁盘空间消耗将会很大。所以使用时需要合理设计。
假设我们在使用腾讯的在线文档功能,那我们来一个破产版的在线文档:
// 这是基础的文档类 @Data @AllArgsConstructor @NoArgsConstructor class Document{ /** * 文档内容 */ String content; } import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import java.time.LocalDate; import java.util.HashMap; import java.util.Map; /** * @author pcc */ public class DocumentMemento { /** * 文档暂存时的时间,用于恢复文档的历史状态 */ LocalDate dateTime; /** * 暂存文档的集合,真实场景都是数据库或者缓存 */ Map<LocalDate,Document> map = new HashMap<>(); /** * 暂存文档 * @param document 文档 */ public void docuMemento(Document document,LocalDate dateTime){ map.put(dateTime,new Document(document.getContent())); } /** * 获取对应时间的文档信息 * 恢复历史记录 */ public Document getDocuMemento(LocalDate dateTime){ return map.get(dateTime); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
上面就是代码了,其实很简单,就是将对象保存到一个容器里,这里使用Map,真实场景中大多是缓存或者数据库来存储。使用Map需要注意的是存储时得新建对象存储,不然对象属性更改了Map中也会更改,因为他们所有引用都是指向堆中唯一的对象。下面是测试代码:
import java.time.LocalDate; import java.util.Optional; /** * @author pcc */ public class TestMemento { public static void main(String[] args) { DocumentMemento documentMemento = new DocumentMemento(); Document document = new Document(); document.setContent("北国风光,万"); saveTmp(document,documentMemento,LocalDate.now()); // 暂存一次 document.setContent("北国风光,万里雪飘"); saveTmp(document,documentMemento,LocalDate.now().plusDays(1)); // 暂存一次 document.setContent("北国风光,万里雪飘,千里冰封"); saveTmp(document,documentMemento,LocalDate.now().plusDays(2)); // 暂存一次 System.out.println("当前文档为:"+document.getContent()); // 假设有一个页面,我们选择了恢复到时间点为第二条的数据 Document docuMemento = documentMemento.getDocuMemento(LocalDate.now().plusDays(1)); System.out.println("恢复文档为:"+docuMemento.getContent()); } static void saveTmp(Document document,DocumentMemento documentMemento,LocalDate localDate){ Optional.ofNullable(document).ifPresent(docume->{ documentMemento.docuMemento(docume, localDate); }); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

8.观察者模式 observer /əbˈzɜːvə®/
观察者模式又被称为发布订阅模式,他的核心是一对多的通知。我们可以做广播类型的观察者,也可以做topic类型的观察者。
java本身提供了观察者的的接口,我们可以直接使用(自己写也很简单,但肯定没有jdk提供的全面)。
- Observalbe: 被观察对象,是一个类,可以管理观察者
- Observer:观察者接口
这里使用一个父类封装被观察者添加观察者的动作,如下:
package com.cheng.ebbing.message.observer; import org.springframework.beans.factory.InitializingBean; import org.springframework.stereotype.Component; import javax.annotation.Resource; import java.util.Observable; import java.util.Observer; import java.util.function.Predicate; /** * @author pcc * @version 1.0.0 * * @description 观察者父类,这里使用Spring的InitializingBean接口,在bean初始化时,将当前对象添加到被观察者中 * 该观察者不做任何业务动作,只为了封装被观察者的addObserver方法 */ @Component public abstract class MyObserver implements Observer, InitializingBean { @Resource private Observable observable; @Override public void afterPropertiesSet() throws Exception { // 父级观察者不加入 if(Predicate.isEqual(this.getClass().getName()).negate().test(MyObserver.class.getName())){ observable.addObserver(this); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
下面是两个观察者,他们都是上面父级观察者的子类:
package com.cheng.ebbing.message.observer; import org.springframework.stereotype.Component; import java.util.Observable; /** * @author pcc * @version 1.0.0 * @description 观察者1 */ @Component public class ObserverOne extends MyObserver { @Override public void update(Observable o, Object arg) { System.out.println("ObserverOne收到消息:" + arg); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
package com.cheng.ebbing.message.observer; import org.springframework.stereotype.Component; import java.util.Observable; /** * @author pcc * @version 1.0.0 * @description 观察者2 */ @Component public class ObserverTwo extends MyObserver { @Override public void update(Observable o, Object arg) { System.out.println("ObserverTwo收到消息:" + arg); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
下面是被观察者的代码:
package com.cheng.ebbing.message.observer; import org.springframework.stereotype.Component; import java.util.Observable; /** * @author pcc * @version 1.0.0 * @description 被观察对象 */ @Component public class MyObservable extends Observable { public void postUpdate() { // 这里可以写业务代码 setChanged(); notifyObservers("更新消息了"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这就是观察者模式的全部代码了,下面是测试代码:
package com.cheng.ebbing.message.observer; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.annotation.Resource; /** * @author pcc * @version 1.0.0 * @description 测试类 */ @RestController public class TestObserverController { @Resource private MyObservable observable; @RequestMapping(value ="/testObserver") public void testObserver(){ observable.postUpdate(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
下面是执行截图:

9.状态模式 state
状态模式的核心是对于对象不同的状态应该对应着不同的业务动作,注意这里要区别备忘录模式,备忘录相当于存的是版本,而状态更强调的时不同的状态下对象应该做什么。状态模主要讲述对象状态变更时应该做何种处理的场景。状态模式有一个顶层的状态接口,还有多个状态实现类,不同的状态类代表不同的状态,同时有着不同的动作。
假设有这种场景:有个新增流程,它对应着发起、审批、完成三个状态,我们需要在不同的状态结点通知不同的审核人
/** * @author pcc * 状态抽象类,定义为借口其实更好 * 以及他的三个状态实现类 * * 优点:解耦状态还业务实现 * 缺点:若是状态过多,容易造成状态类过多(感觉不是缺点,若是每个状态都做自己的动作与业务代码耦合在一起,会导致后期维护越来越乱) */ public abstract class State { public abstract void handlerEvent(); } class StartState extends State{ public static final Integer STATE = 0; @Override public void handlerEvent() { System.out.println("start-process"); } } class DealState extends State{ public static final Integer STATE = 1; @Override public void handlerEvent() { System.out.println("deal-process"); } } class CompleteState extends State{ public static final Integer STATE = 2; @Override public void handlerEvent() { System.out.println("complete-process"); } } import lombok.Data; import lombok.EqualsAndHashCode; /** * @author pcc */ @Data @EqualsAndHashCode(callSuper = true) public class Process extends State{ String name; // 流程名 String desc; // 流程描述 State state; // 流程状态 @Override public void handlerEvent() { state.handlerEvent(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
上面就是状态模式的代码了,其实也很简单,但是当我们对对象做状态相应的变更时,就可以实现解耦业务和状态的操作。下面是测试代码:
/** * @author pcc */ public class TestState { public static void main(String[] args) { Process process = new Process(); process.setState(new StartState()); // 在合适的场景进行状态变更的处理操作 process.handlerEvent(); process.setState(new DealState()); // 在合适的场景进行状态变更的处理操作 process.handlerEvent(); process.setState(new CompleteState()); // 在合适的场景进行状态变更的处理操作 process.handlerEvent(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

10.策略模式 strategy /ˈstrætədʒi/
策略模式的核心是将不同场景的运算逻辑封装在不同的策略里,从而实现针对不同场景的处理进行分开处理。解耦场景判断与场景实现的耦合,当有不同的场景时,我们需要增加场景类来提供不同的场景算法。
当if、else判断场景比较多时,我们就可以考虑使用策略模式,来对代码进行优化。策略模式可以解耦场景和算法,易扩展。策略模式需要以下类:
- 策略上下文:用于管理策略,执行时通过上下文选择策略
- 策略父类:定义策略的方法
- 若干策略子类:重写策略父类的方法,也是真正的算法实现的地方
这是策略父类代码
package com.cheng.ebbing.message.strategy; import org.springframework.stereotype.Component; /** * @author pcc * @version 1.0.0 * @description 策略父类,用以定义策略的方法和策略标识 */ @Component public class FatherStrategy { public static final String STRATEGY_NAME = "strategy0"; public String getStrategyType(){ return STRATEGY_NAME; } public void dealStrategy(){ System.out.println("父类策略-method1"); } public void dealStrategy2(){ System.out.println("父类策略-method2"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这是两个策略子类的代码:
package com.cheng.ebbing.message.strategy; import org.springframework.stereotype.Component; /** * @author pcc * @version 1.0.0 * @description 策略类1,重写策略方法和定义自己的策略类型 */ @Component public class StrategyOne extends FatherStrategy{ public static final String STRATEGY_NAME = "strategy1"; @Override public String getStrategyType() { return STRATEGY_NAME; } @Override public void dealStrategy() { System.out.println("策略1-method1"); } @Override public void dealStrategy2() { System.out.println("策略1-method2"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
package com.cheng.ebbing.message.strategy; import org.springframework.stereotype.Component; /** * @author pcc * @version 1.0.0 * @description 策略类2,重写策略方法和定义自己的策略类型 */ @Component public class StrategyTwo extends FatherStrategy{ public static final String STRATEGY_NAME = "strategy2"; @Override public String getStrategyType() { return STRATEGY_NAME; } @Override public void dealStrategy() { System.out.println("策略2-method1"); } @Override public void dealStrategy2() { System.out.println("策略2-method2"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
这是策略上下文代码:
package com.cheng.ebbing.message.strategy; import org.springframework.stereotype.Component; import javax.annotation.Resource; import java.util.List; import java.util.function.Predicate; /** * @author pcc * @version 1.0.0 * @description 策略上下文,客户端选择策略时使用 */ @Component public class StrategyContext { @Resource private List<FatherStrategy> strategies; public FatherStrategy getStrategy(String type){ for (FatherStrategy strategy : strategies) { if(Predicate.isEqual(strategy.getStrategyType()).test(type)) { return strategy; } } throw new RuntimeException("stratey异常:无可用策略"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
下面是测试代码:
package com.cheng.ebbing.message.strategy; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.annotation.Resource; /** * @author pcc * @version 1.0.0 * @description 测试策略 */ @RestController public class TestStrategyController { @Resource StrategyContext strategyContext; @RequestMapping(value ="/testStrategy") public void testStrategy(){ FatherStrategy strategy = strategyContext.getStrategy("strategy1"); strategy.dealStrategy(); strategy.dealStrategy2(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
下面是执行结果:

11.访问者模式 visitor
访问者模式的核心是在不改变原有对象的基础上,提供针对同一个对象的不同操作。可以这么理解一个学生考了59分,当学生知道59分的时候,学生是访问者,当老师、父母等看到59分时他们都可以是访问者,不同的访问者对于这个分数他们的处理应该是不同的。访问者模式通过抽象不同的访问者来实现解耦,而且易于扩展。
下面以学生分数为例来说明访问者模式:
import java.util.Optional; public interface ScoreVisitor { void visit(Student student); } // 学生访问者,不同的访问者对待同一个事情的反应是不同的 class StudentVisitor implements ScoreVisitor{ @Override public void visit(Student student) { Optional.ofNullable(student).ifPresent(s->{ if(s.getScore()!=null && s.getScore()>=60){ System.out.println("学生:及格了好开心,回家不用挨打了"); }else{ System.out.println("学生:没及格,回家挨打"); } }); } } // 老师访问者 class TeacherVisitor implements ScoreVisitor{ @Override public void visit(Student student) { Optional.ofNullable(student).ifPresent(s->{ if(s.getScore()!=null && s.getScore()>=60){ System.out.println("老师:及格了,希望能考个好大学,给我送个红包"); }else{ System.out.println("老师:废物一个,下次给他安排旮旯角"); } }); } } // 父母访问者 class ParentsVisitor implements ScoreVisitor{ @Override public void visit(Student student) { Optional.ofNullable(student).ifPresent(s->{ if(s.getScore()!=null && s.getScore()>=60){ System.out.println("父母:及格了,希望孩子有个好的未来"); }else{ System.out.println("父母:得想想怎么帮助他了"); } }); } } import lombok.Data; import lombok.EqualsAndHashCode; /** * @author pcc */ public class Person { String name; // 姓名 String identity; // 身份 } // 这是学生类,他拥有分数 @EqualsAndHashCode(callSuper = true) @Data class Student extends Person { Integer score; } @Data @EqualsAndHashCode(callSuper = true) class Teacher extends Person { String level; // 教师职级 } @Data @EqualsAndHashCode(callSuper = true) class Parent extends Person { String love; // 父母的爱 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
访问者模式代码也就是这些了,核心就是针对同一个场景或者对象,不同访问者具有完全不同的动作,下面是测试代码:
/** * @author pcc */ public class TestVisitor { public static void main(String[] args) { Student student = new Student(); student.setScore(59); // 假设考了59分 StudentVisitor studentVisitor = new StudentVisitor(); TeacherVisitor teacherVisitor = new TeacherVisitor(); ParentsVisitor parentsVisitor = new ParentsVisitor(); studentVisitor.visit(student); teacherVisitor.visit(student); parentsVisitor.visit(student); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17


