
- 1分割、合并、转换、重组:强大的自部署 PDF 处理工具 | 开源日报 No.143
- 2合伙人制度的创新与实践:全平台利润分配的探索
- 3visual studio无法打开源文件报错解决方案
- 4npm ERR! node-sass@4.14.1 postinstall: `node scripts/build.js`
- 5鸿蒙原生应用元服务开发-Web管理位置权限
- 6在LobeChat中私有化部署Llama3_lobe-chat出现response.ollamaserviceunavailable
- 7github npm包发布管理教程_github的npm包管理地址
- 8Oracle数据库连接之TNS-12541_无监听器
- 9ubuntu 安装docker + seagull实现图形化管理
- 10【BASH 常用脚本系列3 -- shell实现查找目录并进入目录】
PyTorch三种主流模型构建方式:nn.Sequential、nn.Module子类、nn.Module容器开发实践,以真实烟雾识别场景数据为例_self.model = nn.sequential
赞
踩
Keras和PyTorch是两个常用的深度学习框架,它们都提供了用于构建和训练神经网络的高级API。
Keras:
Keras是一个高级神经网络API,可以在多个底层深度学习框架上运行,如TensorFlow和CNTK。以下是Keras的特点和优点:
优点:
简单易用:Keras具有简洁的API设计,易于上手和使用,适合快速原型设计和实验。
灵活性:Keras提供了高级API和模块化的架构,可以灵活地构建各种类型的神经网络模型。
复用性:Keras模型可以轻松保存和加载,可以方便地共享、部署和迁移模型。
社区支持:Keras拥有庞大的社区支持和活跃的开发者社区,提供了大量的文档、教程和示例代码。
缺点:
功能限制:相比于底层框架如TensorFlow和PyTorch,Keras在某些高级功能和自定义性方面可能有所限制。
可扩展性:虽然Keras提供了易于使用的API,但在需要大量定制化和扩展性的复杂模型上可能会有限制。
灵活程度:Keras主要设计用于简单的流程,当需要处理复杂的非标准任务时,使用Keras的灵活性较差。
适用场景:
初学者:对于新手来说,Keras是一个理想的选择,因为它简单易用,有丰富的文档和示例来帮助快速入门。
快速原型设计:Keras可以快速搭建和迭代模型,适用于快速原型设计和快速实验验证。
常规计算机视觉和自然语言处理任务:Keras提供了大量用于计算机视觉和自然语言处理的预训练模型和工具,适用于常规任务的开发与应用。
PyTorch:
PyTorch是一个动态图深度学习框架,强调易于使用和低延迟的调试功能。以下是PyTorch的特点和优点:
优点:
动态图:PyTorch使用动态图,使得模型构建和调试更加灵活和直观,可以实时查看和调试模型。
自由控制:相比于静态图框架,PyTorch能够更自由地控制模型的复杂逻辑和探索新的网络架构。
算法开发:PyTorch提供了丰富的数学运算库和自动求导功能,适用于算法研究和定制化模型开发。
社区支持:PyTorch拥有活跃的社区和大量的开源项目,提供了丰富的资源和支持。
缺点:
部署复杂性:相比于Keras等高级API框架,PyTorch需要开发者更多地处理模型的部署和生产环境的问题。
静态优化:相对于静态图框架,如TensorFlow,PyTorch无法进行静态图优化,可能在性能方面略逊一筹。
入门门槛:相比于Keras,PyTorch对初学者来说可能有一些陡峭的学习曲线。
适用场景:
研究和定制化模型:PyTorch适合进行研究和实验,以及需要灵活性和自由度较高的定制化模型开发。
高级计算机视觉和自然语言处理任务:PyTorch在计算机视觉和自然语言处理领域有广泛的应用,并且各类预训练模型和资源丰富。
在前面的两篇文章中整体系统总结记录了Keras和PyTroch这两大主流框架各自开发构建模型的三大主流方式,并对应给出来的基础的实例实现,感兴趣的话可以自行移步阅读即可:
《总结记录Keras开发构建神经网络模型的三种主流方式:序列模型、函数模型、子类模型》
本文的主要目的就是想要基于真实业务数据场景来实地开发实践这三种不同类型的模型构建方式,并对结果进行对比分析。
首先来看下数据集:

首先来看序列模型构建实现:
- def initModel():
- """
- nn.Sequential按层顺序构建模型
- """
- model = nn.Sequential()
- model.add_module("conv1", nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3))
- model.add_module("pool1", nn.MaxPool2d(kernel_size=2, stride=2))
- model.add_module("conv2", nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5))
- model.add_module("dropout", nn.Dropout2d(p=0.1))
- model.add_module("pool2", nn.AdaptiveMaxPool2d((1, 1)))
- model.add_module("flattens", nn.Flatten())
- model.add_module("linear1", nn.Linear(64, 32))
- model.add_module("relu1", nn.ReLU())
- model.add_module("linear2", nn.Linear(32, 1))
- return model
接下来是继承nn.Module基类构建自定义模型,如下所示:
- class initModel(nn.Module):
- """
- 继承nn.Module基类构建自定义模型
- """
-
- def __init__(self):
- super(initModel, self).__init__()
- self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)
- self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
- self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5)
- self.dropout = nn.Dropout2d(p=0.1)
- self.pool2 = nn.AdaptiveMaxPool2d((1, 1))
- self.flatten = nn.Flatten()
- self.linear1 = nn.Linear(64, 32)
- self.relu = nn.ReLU()
- self.linear2 = nn.Linear(32, 1)
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.pool1(x)
- x = self.conv2(x)
- x = self.dropout(x)
- x = self.pool2(x)
- x = self.flatten(x)
- x = self.linear1(x)
- x = self.relu(x)
- x = self.linear2(x)
- return x
最后是继承nn.Module基类并辅助应用模型容器进行封装构建方式,这里在前文中提到共有三种模型容器可用,分别是:
- nn.Sequential
- nn.ModuleList
- nn.ModuleDict
代码实现如下所示:
- class initModel(nn.Module):
- """
- 继承nn.Module基类并辅助应用模型容器进行封装
- nn.Sequential作为模型容器
- """
-
- def __init__(self):
- super(initModel, self).__init__()
- self.model = nn.Sequential()
- self.model.add_module(
- "conv1", nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)
- )
- self.model.add_module("pool1", nn.MaxPool2d(kernel_size=2, stride=2))
- self.model.add_module(
- "conv2", nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5)
- )
- self.model.add_module("dropout", nn.Dropout2d(p=0.1))
- self.model.add_module("pool2", nn.AdaptiveMaxPool2d((1, 1)))
- self.model.add_module("flatten", nn.Flatten())
- self.model.add_module("linear1", nn.Linear(64, 32))
- self.model.add_module("relu", nn.ReLU())
- self.model.add_module("linear2", nn.Linear(32, 1))
-
- def forward(self, x):
- y = self.model(x)
- return y
-
-
- class initModel(nn.Module):
- """
- 继承nn.Module基类并辅助应用模型容器进行封装
- nn.ModuleList作为模型容器
- """
-
- def __init__(self):
- super(initModel, self).__init__()
- self.layers = nn.ModuleList(
- [
- nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5),
- nn.Dropout2d(p=0.1),
- nn.AdaptiveMaxPool2d((1, 1)),
- nn.Flatten(),
- nn.Linear(64, 32),
- nn.ReLU(),
- nn.Linear(32, 1),
- ]
- )
-
- def forward(self, x):
- for layer in self.layers:
- x = layer(x)
- return x
-
-
- class initModel(nn.Module):
- """
- 继承nn.Module基类并辅助应用模型容器进行封装
- nn.ModuleDict作为模型容器
- """
-
- def __init__(self):
- super(initModel, self).__init__()
- self.layers_dict = nn.ModuleDict(
- {
- "conv1": nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3),
- "pool1": nn.MaxPool2d(kernel_size=2, stride=2),
- "conv2": nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5),
- "dropout": nn.Dropout2d(p=0.1),
- "pool2": nn.AdaptiveMaxPool2d((1, 1)),
- "flatten": nn.Flatten(),
- "linear1": nn.Linear(64, 32),
- "relu": nn.ReLU(),
- "linear2": nn.Linear(32, 1),
- }
- )
-
- def forward(self, x):
- layers = [
- "conv1",
- "pool1",
- "conv2",
- "dropout",
- "pool2",
- "flatten",
- "linear1",
- "relu",
- "linear2",
- ]
- for layer in layers:
- x = self.layers_dict[layer](x)
- return x
跟keras框架一样,默认都是设定100次epoch的迭代计算,这里直接来看结果图:
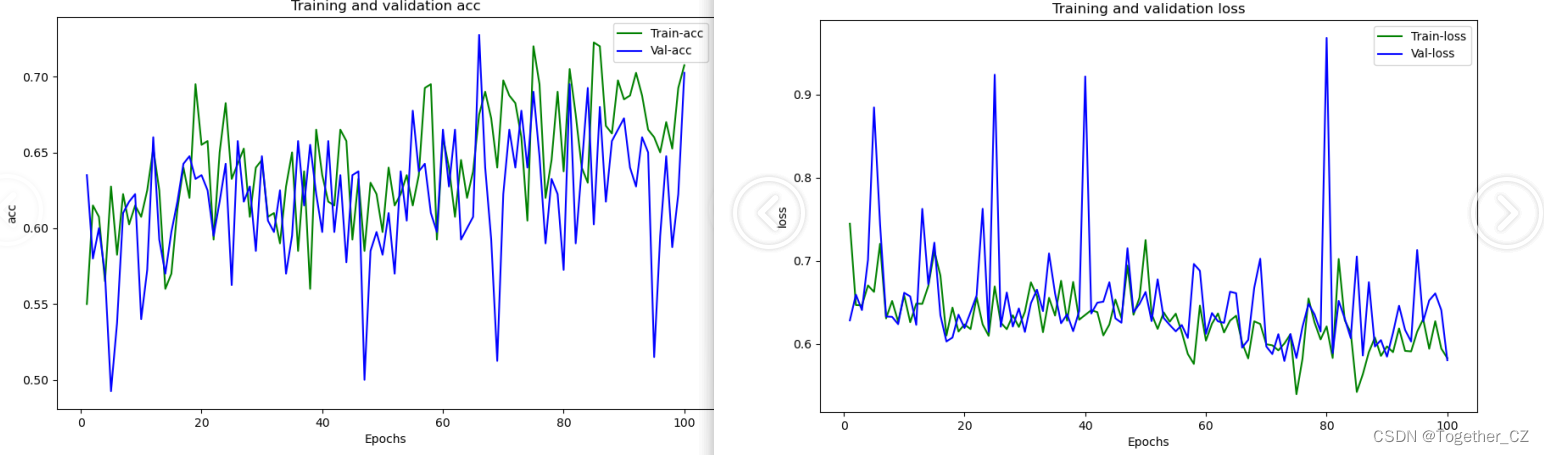
感兴趣都可以自行实践一下,很多内容或者是方法本质上都是触类旁通的。

