
- 1[C++]STL-set/multiset容器_std::multiset自动排序
- 2hadoop大数据开发基础_大数据,Hadoop生态详解
- 3Java:MybatisPlus--配置及其注解_mybatisplus的configuration配置
- 4Flink作业的逻辑与物理拓扑详解
- 5液冷数据中心走红,什么是液冷?_风液比
- 6Android Studio实现内容丰富的安卓手机购物商城APP_android studio购物app
- 7【Linux】信号
- 8redis持久化_redis持久化文件存在哪里
- 9MySQL中执行SQL的BufferPool缓存机制
- 10MyBatisPlus 多数据源配置_mybatisplus多数据源配置
Flink反压原理深入浅出及解决思路
赞
踩
1. 前言
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行快速计算。既然是对流式数据进行处理,那么就要面临数据在流动计算时,上下游数据通信以及数据处理速度不一致所带来的问题。
本文先从「生产者-消费者模式」的角度介绍了Flink中的数据传输,从而引出了「反压」的概念。接着介绍了Flink在V1.5前「基于TCP的反压机制」以及V1.5后「基于Credit的反压机制」分别如何实现网络流控。最后针对一个反压案例进行分析,介绍了如何进行反压定位和资源调优,并展示了调优结果。
希望在阅读完本文后,读者可以深入理解Flink节点反压的概念以及背后的原理,在遇到反压场景时,能够快速定位瓶颈点,并拥有一套基本的调优思路。
2. 从Flink数据传输看「反压」
2.1 生产者-消费者模式
Flink作业在运行状态时,数据会在各个TaskManager(TM)之间流动交换,上游TM到下游TM的数据传输,可以简单看作是生产者&消费者模式。
下面将会介绍 Producer 和 Consumer 在吞吐率不同时,导致的普遍性问题。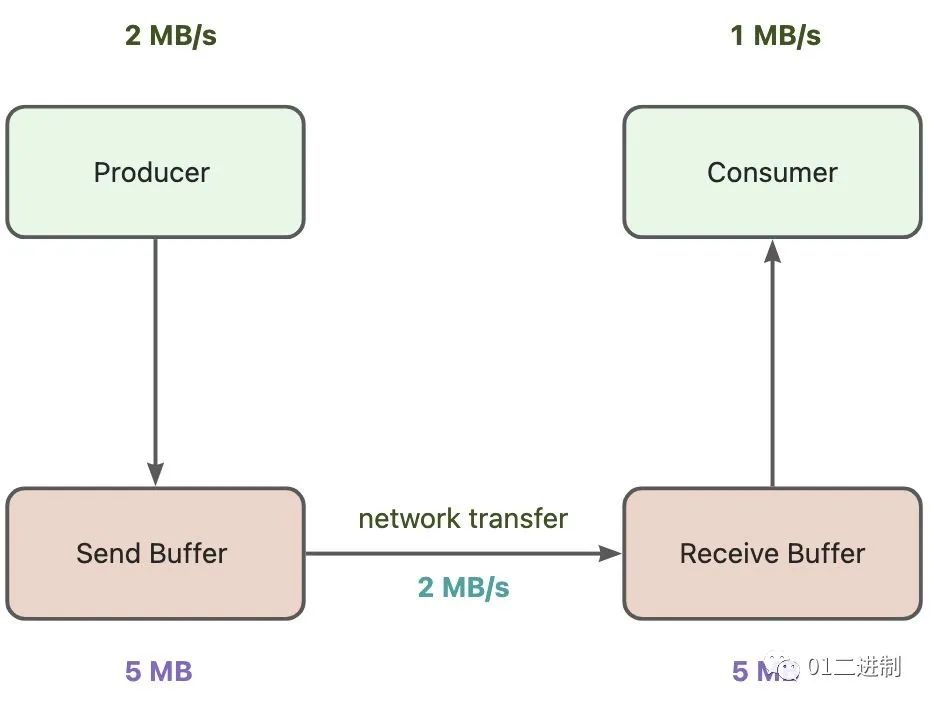
假设 Producer的吞吐率为 2 MB/s,Consumer是 1 MB/s ,此时上游产生数据的速度 大于 下游处理数据的速度,且假设两端都存在Buffer,用来暂时存放数据,再假设底层网络传输速度为 2 MB/s。
若Buffer有界,经过5s后,Consumer 端的 Receive Buffer 会被打满,后面新到达的数据就只能被丢弃掉;但在实际场景中,通常生产者在发送数据前会检查 buffer 的可用状态,若 buffer 处于不可用状态,则不会发送新的数据。
面对上述问题,需要有一种动态反馈的机制,根据数据实时传输的情况,动态调整数据的发送速率和接收速率,从而更好的进行网络传输。
动态反馈可以分为以下两种:
正向反馈:当Producer的发送速率 小于 Consumer的接受速率时,需要通知 Producer可以提高发送速率
负向反馈:当Producer的发送速率 大于 Consumer的接受速率时,需要通知 Producer可以降低发送速率
2.2 何为「反压」
通过上小节的介绍,我们了解到,当上游生产数据和下游消费数据速率不一致时,会导致一些问题,这时候需要一种「动态反馈」机制,下面引入「反压」的概念
「反压」是流式系统中关于数据处理能力的动态反馈机制,并且是从下游到上游的反馈,一般发生在实时数据处理的过程中,上游节点的生产速度大于下游节点的消费速度的情况下。
下面将会介绍在Flink中,TaskManager之间如何传输数据,看看 Flink 中数据传输的生产者-消费者模式的具体形式。
2.3 TaskManager之间的数据传输
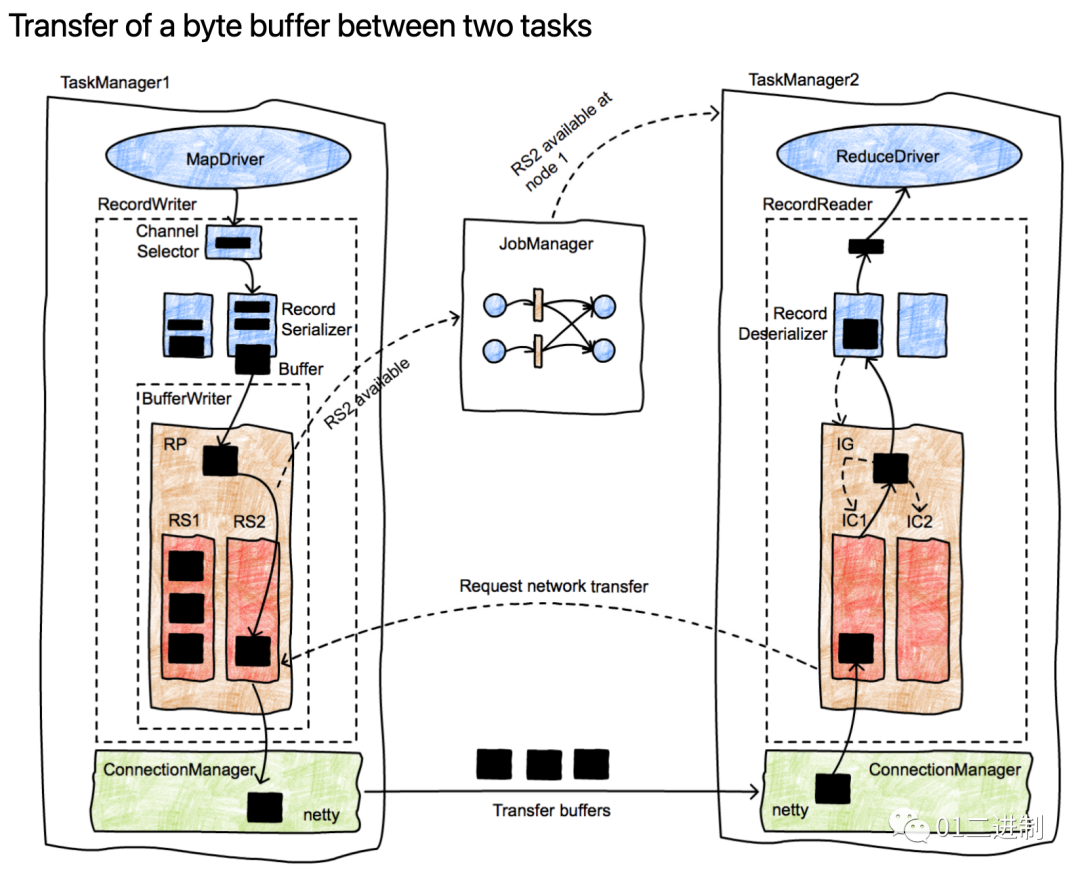
下图来源于Apache Flink (http://flink.apache.org) 图中相关概念: ResultPartition(RP) ResultSubPartition(RS) InputChannel(IC) InputGate(IG)
- /**
- * The {@link ChannelSelector} determines to which logical channels a record should be written to.
- *
- * @param <T> the type of record which is sent through the attached output gate
- */
- public interface ChannelSelector<T extends IOReadableWritable> {
-
- /**
- * Initializes the channel selector with the number of output channels.
- *
- * @param numberOfChannels the total number of output channels which are attached to respective
- * output gate.
- */
- void setup(int numberOfChannels);
-
- /**
- * Returns the logical channel index, to which the given record should be written. It is illegal
- * to call this method for broadcast channel selectors and this method can remain not
- * implemented in that case (for example by throwing {@link UnsupportedOperationException}).
- *
- * 选择模式
- *
- * @param record the record to determine the output channels for.
- * @return an integer number which indicates the index of the output channel through which the
- * record shall be forwarded.
- */
- int selectChannel(T record);
-
- /**
- * Returns whether the channel selector always selects all the output channels.
- * 广播模式
- *
- * @return true if the selector is for broadcast mode.
- */
- boolean isBroadcast();
- }

序列化输出的二进制流数据会被存放在buffer块中,之后 BufferWriter 会将这些buffer块写入到指定的ResultPartition(RP)中。RP中又包含多个子分区(ResultSubpartitions,如RS1,RS2),每个子分区只会存放特定消费者需要的数据。由图可见,一个 buffer 已经被 BufferWriter 放入了 RS2 中,这时 RS2 这个子分区已经变成了可被消费状态,接下来会通知 JobManager。
- public abstract class ResultPartition implements ResultPartitionWriter {
-
- protected final ResultPartitionID partitionId;
-
- /** 该分区的类型,定义要使用的具体子分区实现 */
- protected final ResultPartitionType partitionType;
-
- protected final ResultPartitionManager partitionManager;
-
- /** Subpartition 的个数 */
- protected final int numSubpartitions;
-
- // - Runtime state --------------------------------------------------------
-
- /** ResultPartition 中的缓冲区 */
- protected BufferPool bufferPool;
-
- }
JobManager 会寻找 RS2 的消费者,通知TaskManager2,该数据块可以消费了。接着InputChannel会接收到该消息(图中是 IC1,用于接收上一步中存放到 RS2 中的 buffer,且 InputChannel 和 ResultSubpartition 是1-1对应的,一个 InputChannel 接收一个 ResultSubpartition 的输出),并通知 RS2 初始化网络连接,可以开始传输数据了。然后 RS2 通过 TaskManager1 的网络栈基于 Netty 进行数据传输,该网络连接是在各个TaskManager 之间长期存在的。
- /**
- * An input channel consumes a single {@link ResultSubpartitionView}.
- *
- * <p>For each channel, the consumption life cycle is as follows:
- *
- * <ol>
- * <li>{@link #requestSubpartition()}
- * <li>{@link #getNextBuffer()}
- * <li>{@link #releaseAllResources()}
- * </ol>
- */
- public abstract class InputChannel {
- /** 输入通道的信息,以便在任务中全局识别它. */
- protected final InputChannelInfo channelInfo;
-
- /** 此通道消费接收的RP编号. */
- protected final ResultPartitionID partitionId;
-
- /** 此通道使用的子分区的索引. */
- protected final int consumedSubpartitionIndex;
-
- protected final SingleInputGate inputGate;
- }
基于 Netty 的网络传输,buffer块被传递到 TaskManager2 网络栈,之后由 ConnectionManager 来控制将 buffer数据传递到指定的 InputChannel 中,并进入InputGate,最终进入反序列化器 (RecordDeserializer)将buffer中的数据还原成制定类型的对象,最后传递给接收数据的task。
其实这是典型的生产者-消费者模式,上游生产数据到 ResultPartition(由ResultSubpartition构成) 中,下游通过 InputGate (由InputChannel构成)消费数据。不同的 task 可能在同一个 TaskManager 中运行,此时这些task可以看做是同一个 TaskManager进程中的不同线程,可以在本地进行数据交换;不同的 task 也可能在不同的 TaskManger 中运行,此时就要通过TaskManager 间的网络通信进行数据交换。
3. Flink网络流控
前面介绍了 Flink 基于生产者-消费者模式的数据传输方式,且我们了解到,流式系统在处理数据时,如果上下游处理速度不一致,会出现数据堵塞等问题。这时候需要一种动态反馈的机制,根据数据实时传输的情况,动态调整数据的发送速率和接受速率,从而更好的进行网络传输,即「网络流控」。
本章将会介绍 Flink 在V1.5前后进行网络流控的两种方式:
基于 TCP 的反压机制
基于 Credit 的反压机制
3.1 基于TCP的反压机制
我们先来看看Flink在V1.5前是如何做动态反馈,进而实现网络流控的。 基于TCP的反压机制底层依赖于「TCP的滑动窗口算法」,本章不会赘述,而会重点描述反压现象的传递过程。
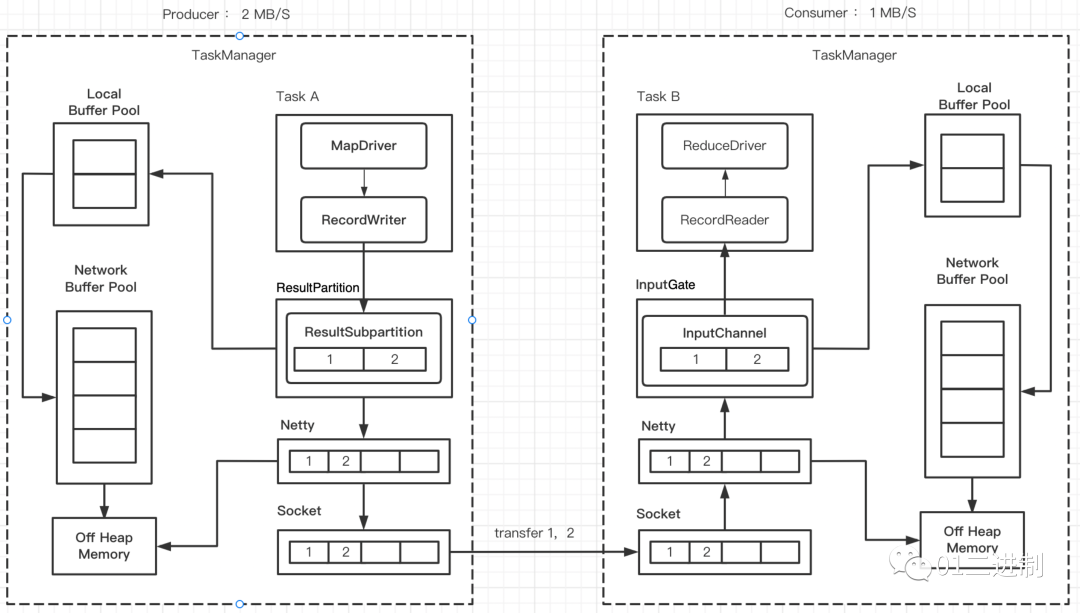
由上图可见,每个TaskManager中都会有个被内部所有task共享的 Network Buffer Pool,它从堆外内存申请内存资源,之后可以为每个 ResultSubpartition 创建 Local Buffer Pool。
假设生产者的速率是 2 MB/S,消费者的速率是 1 MB/S。下面会描述,由于速度不匹配,各层buffer被打满,从而引起反压的过程。
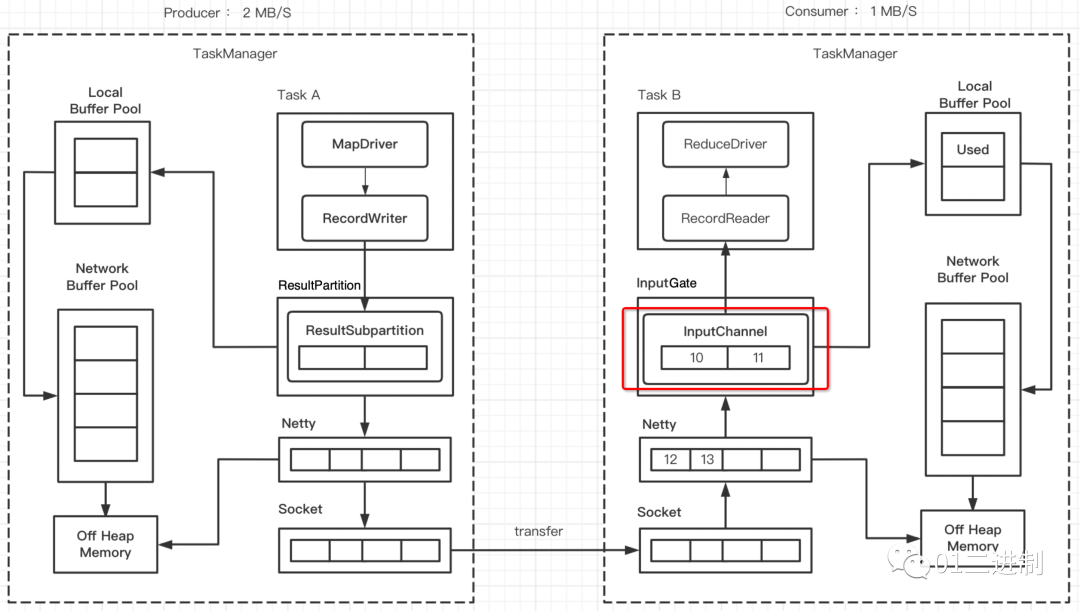
3.1.1 InputChannel Buffer 打满
一段时间后,会达到下图的状态,此时 InputChannel 暂时被打满,需要向 Local Buffer Pool 申请新的 buffer,此时 Local Buffer Pool 里的一个 buffer 被标记为 Used。
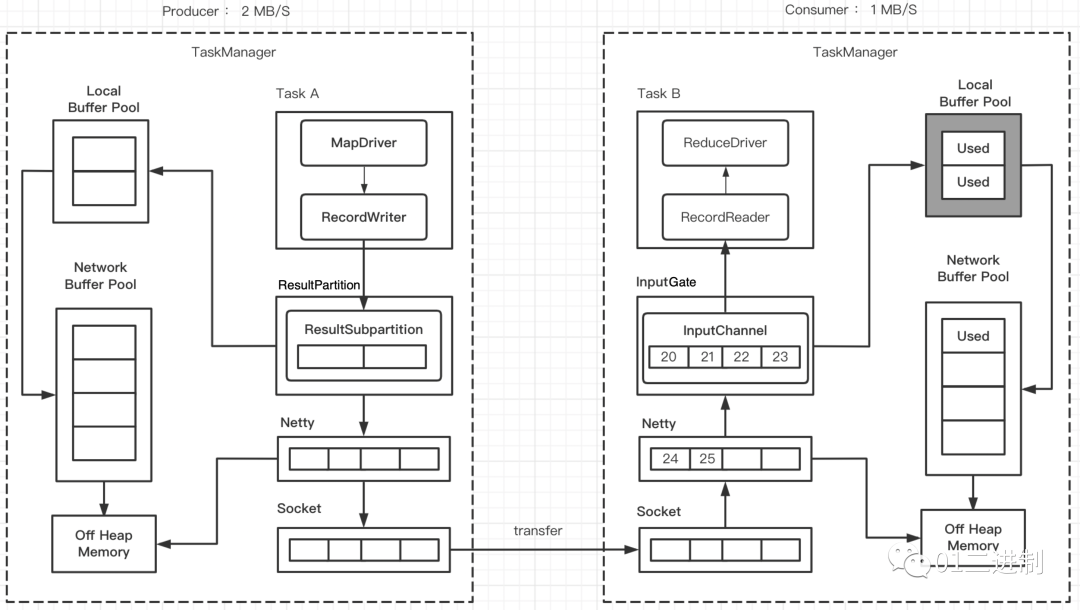
3.1.2 Consumer Local Buffer Pool 打满
由上下游处理速率不一致,一段时间过后,InputChannel 将 Local Buffer Pool 的内存申请完了,此时 Local Buffer Pool 的所有 buffer 都被标记为 Used,但还可以向 Network Buffer Pool 继续申请 buffer。
3.1.3 Consumer Network Buffer Pool 打满
渐渐 Network Buffer Pool 也没有可用 buffer 了,全都变成了 Used,此时消费者无法再读取数据了,Netty也不会接收Socket的数据了。
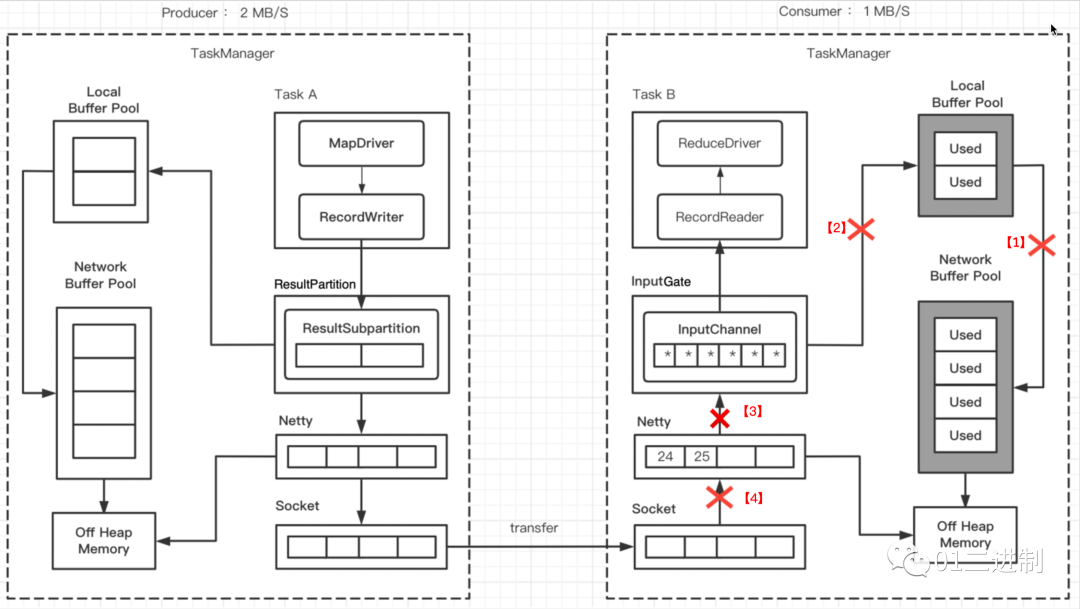
3.1.4 socket停止数据传输
当消费者的 socket 被用尽,此时会将 windows=0 发送给生产者的发送端(TCP滑动窗口),此时socket会停止发送数据。
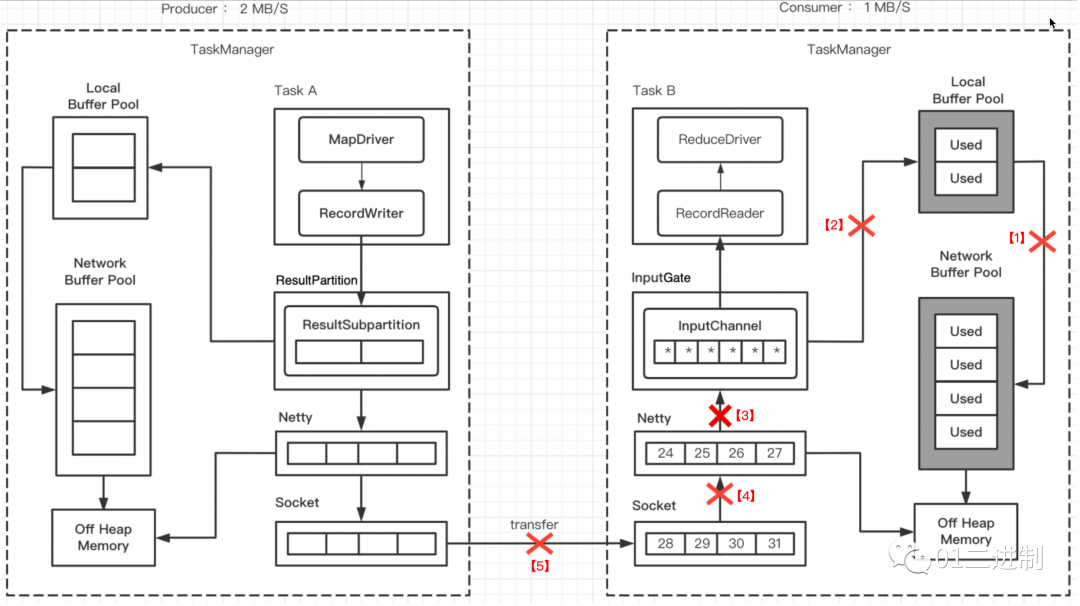
3.1.5 Netty不可写
不久socket buffer用尽,Netty检测到后会停止向socket发送数据,之后由于 RecordWriter 还在发送数据,这些数据会堆积在Netty Buffer中,到一定程度后,Netty会变为不可写状态,ResultSubpartition 发送数据前都会检测 Netty是否可写,此时 ResultSubpartition 会停止向 Netty 中写数据。
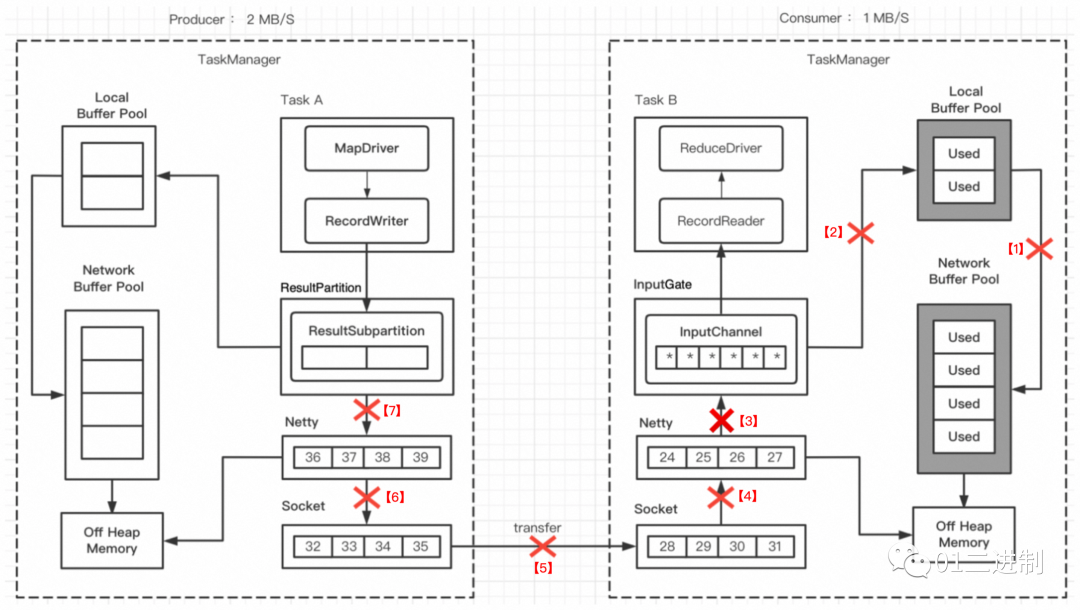
3.1.5 RecordWriter 停止写数据
ResultSubpartition 的空间很快被用尽,直到 Local Buffer Pool 和 Network Buffer Pool 的 buffer都被打满后,RecordWriter 就会停止写数据,至此,完成了跨TaskManager的反压。
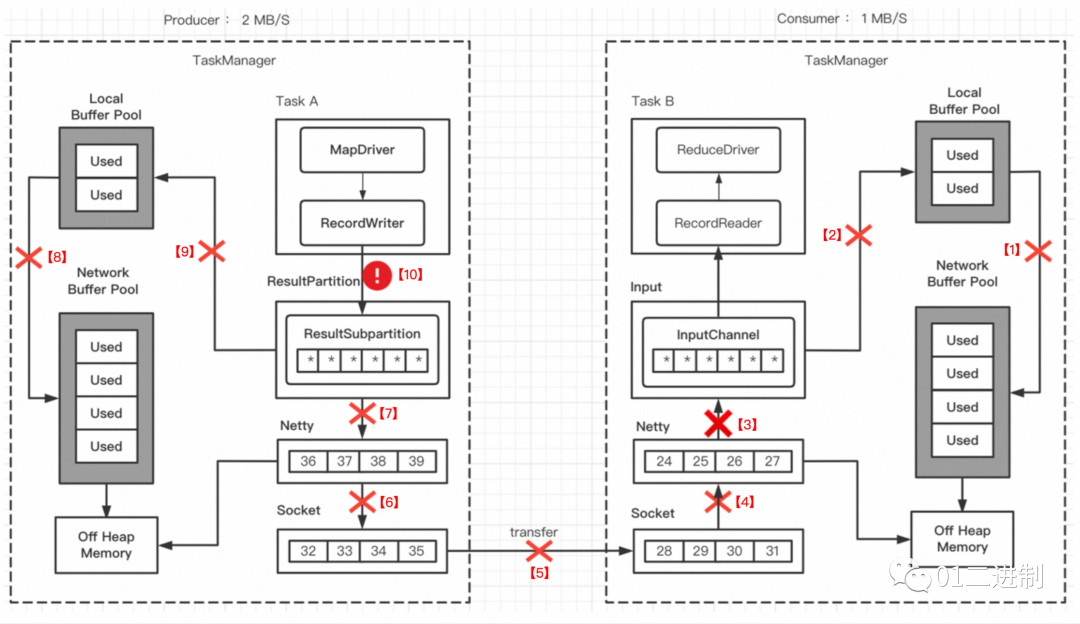
3.1.6 TCP反压机制的问题
当一个 Task 的缓冲池用尽之后,网络连接就处于阻塞状态,上游 Task 无法产出数据,下游 Task 无法接收数据,也就是我们所说的「反压」状态。
但是基于TCP的反压机制有以下问题:
一个 TaskManager 内通常会有多个Task,它们底层会复用同一个Socket,一旦某个Task反压导致Socket阻塞不可用,即便其它 Task 关联的缓冲池仍然存在空余,但也都无法向 TCP 连接中写入数据或者从中读取数据。
基于底层TCP流控的反压机制,从 ResultPartition 到 Netty 到 Socket整条链路较长,会导致反压行为不够灵敏,动态反馈过程比较迟钝。
3.2 基于Credit的反压机制
3.2.1 算法介绍
为了解决上述问题,Flink 1.5 重构了网络栈,引入了“基于信用值的流量控制算法”(Credit-based Flow Control),即在Flink层实现网络流控,缩短反压链路,且确保 TaskManager 之间的网络连接始终不会处于阻塞状态。
Credit-based Flow Control 的思路其实很简单,它在接收端和发送端之间建立一种类似“信用评级”的机制,发送端向接收端发送的数据永远不会超过接收端的信用值的大小。对于 Flink来说,信用值就是接收端TaskManager 可用的 Buffer 的数量,这样就可以保证发送端 TaskManager 不会向 TCP 连接中发送超出接收端缓冲区可用容量的数据。
基于Credit 实现流量控制 的具体机制为:
当发送端发送 buffer 的时候,它把当前堆积数据的 buffer 数量(backlog size)告知接收端;
接收端将根据发送端堆积的数量来申请 buffer;
接收端向发送端声明可用的 Credit(一个可用的 buffer 对应一个 credit);
当接收端分配了 N 点 Credit 给发送端,表明它有 N 个空闲的 buffer 可以接收数据;
当发送端获得了 N 点 Credit,表明它可以向网络中发送 N 个 buffer;
只有在 Credit > 0 的情况下发送端才发送 buffer;发送端每发送一个 buffer,Credit 也相应地减少;
3.2.2 反压过程
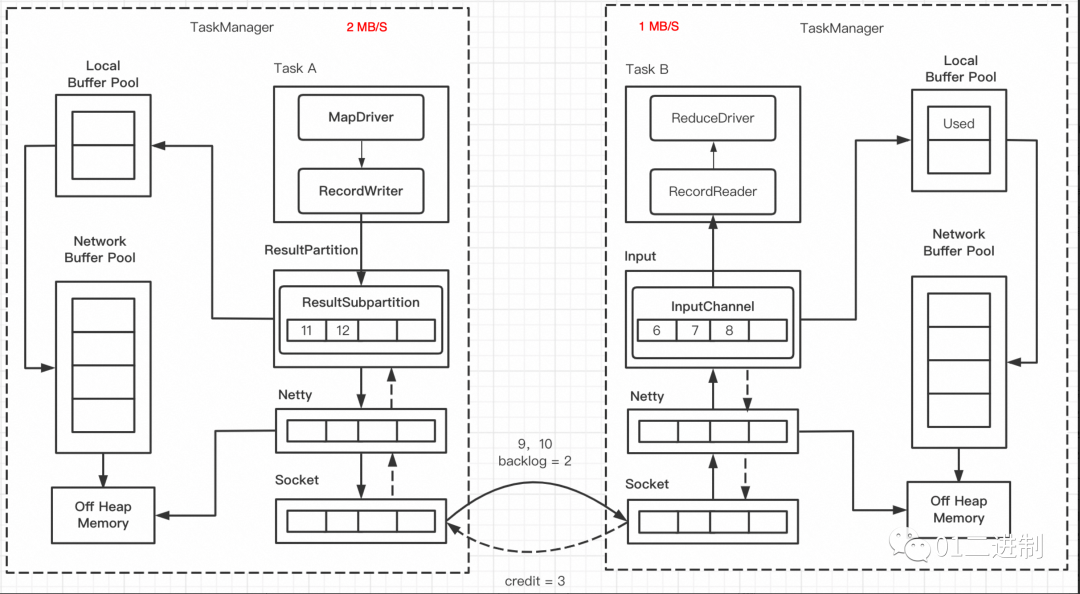
如图所示,当前 ResultPartition 已经堆积了两个 Buffer 的数据,所以在底层网络传输会将 要传输的数据以及backlog size = 2 发送至接收端;下游收到了之后,会计算获得credit信用值,此时接收端共剩下 6 个buffer, 接收速率是 1 个buffer,backlog size 为2个buffer, credit 为 3 个buffer(6-1-2 = 3)。
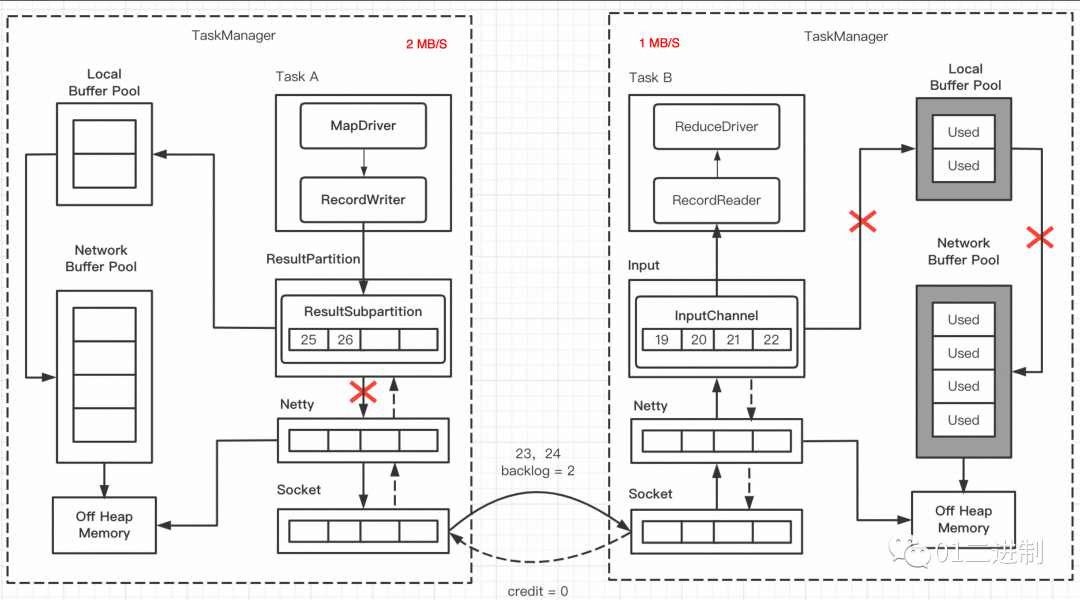
下图中,发送端发送的 backlog size = 2,但接收端的各级Buffer已经打满,所以下游向上游返回的 credit 为0,说明由于上下游处理速率不一致,导致了下游暂时无法处理数据;此时 ResultPartition 就不会向 Netty 传输数据,数据很快就会积压打满,从而达到反压的效果;
3.2.3 优化点
基于Credit算法的反压机制,解决了两个问题:
可以直接在 ResultPartition 层实现反压,而不用将压力流经过多层传递,层层反馈。提高了反压效率,降低了延迟;
不会把底层socket打满,从而阻碍网络数据传输,不会让单个 Task 的瓶颈成为整个TaskManager 的瓶颈;
4. 小结
本文首先介绍了Flink中跨TaskManager的数据传输,引出了「生产者-消费者模式」在吞吐率不同时,导致的普遍性问题,以及「动态反馈」机制的必要性,并明确了「反压」的概念,「反压」是流式系统中关于处理能力的动态反馈机制,并且是从下游到上游的反馈。
接着介绍了Flink的网络流控机制,Flink在V1.5前,「基于TCP的滑动窗口机制」实现反压,但是存在单个Task反压会导致整个TaskManager共享的Socket不可用,而且反压链路较长,动态反馈机制较为迟钝等缺点。Flink在V1.5后,采用「基于Credit算法的反压机制」,在ResultPartition层实现反压,提高了反压效率。
5. 参考资料
https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
https://www.ververica.com/blog/how-flink-handles-backpressure
https://docs.google.com/document/d/1chTOuOqe0sBsjldA_r-wXYeSIhU2zRGpUaTaik7QZ84/edit#heading=h.pjh6mv7m2hjn

