
- 1推荐一款YYDS的低代码开源项目:1小时创建企业专属ERP_电商erp零代码搭建
- 2Python资源汇总
- 3基于ssm+vue+Mysql的企业公寓后勤管理系统
- 4Ubuntu下PostgreSQL的安装与使用_ubuntu安装postgresql
- 5win11安装docker-desktop_win11安装docker desktop
- 6Linux 基础命令知识1_lunix 命令count
- 7java web 找回密码_java web实现 忘记密码(找回密码)功能及代码
- 8数据结构与算法——二叉树、堆、优先队列_结点的直接前驱
- 9python判断质数_python i%j==0
- 10黑屏定屏那些事 - 系统机制,分析套路和实战(系统篇)_android黑屏问题分析
使用基于智能搜索和大模型打造企业下一代知识库-LangChain 集成及其在电商的应用...
赞
踩

感谢大家阅读《基于智能搜索和大模型打造企业下一代知识库》系列博客,全系列分为 5 篇,将为大家系统性地介绍新技术例如大语言模型如何赋能传统知识库场景,助力行业客户降本增效。更新目录如下:
第三篇《Langchain 集成及其在电商的应用》(本篇)
第四篇《制造/金融/教育等行业实战场景》(即将上线)
第五篇《与 Amazon Kendra 集成》(即将上线)
背景
在本系列的《基于智能搜索和大模型打造企业下一代知识库》博客中,前面 2 篇已介绍了《典型实用场景及核心组件介绍》和《手把手快速部署指南》,本篇主要介绍 LangChain 和开源大语言模型集成,结合亚马逊云科技的云基础服务,构建基于企业知识库的智能搜索问答方案。
LangChain 介绍
LangChain 是一个利用大语言模型的能力开发各种下游应用的开源框架,它的核心理念是为各种大语言模型应用实现通用的接口,简化大语言模型应用的开发难度,主要的模块示意图为:
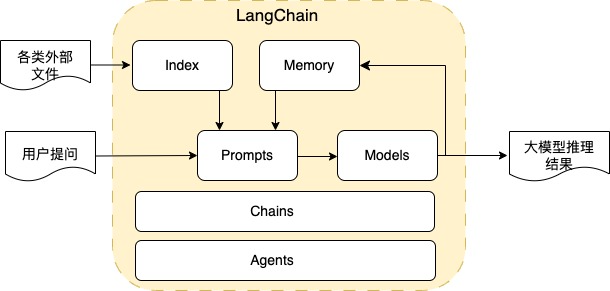
Index:提供了各类文档导入、文本拆分、文本向量化存储和检索的接口,导入的文档类型除常见的 word、excel、PDF、txt 外,还包括 API 和数据库接口,向量化存储包括各类向量数据库,其中也包含 Amazon 的 OpenSearch 搜索引擎。通过 Index 模块,非常容易处理各类型的外部数据,来提供给大模型进行推理。
Prompts:将用户输入和其他外部数据转化为适合大语言模型的提示词,包括提示词管理、提示词优化和提示词序列化等功能。通过调整提示词,可以让大语言模型执行各类任务,如文本生成文本(包括聊天、问答、摘要、报告等)、文本生成 SQL、文本生成代码等,另外还可以通过提示词让模型进行 few shot learning,目前对各任务的提示词最优实践在如火如荼的研究中,通过提示词不断探索大语言模型的能力边界,LangChain 提供了一个易用的提示词管理工具。
Models:提供了对各类大语言模型的管理和集成,除闭源的大语言模型 API 接口外,还提供对多个开源模型仓库中开源大语言模型的集成接口,以及在云上部署的大语言模型接口,如部署在 Amazon SageMaker Endpoint 的大语言模型接口。
Memory:用来保存与模型交互时的上下文状态,是实现多轮对话的关键组件。
Chains:LangChain 的核心组件,能对上面的各组件组合在一起以完成特定的任务,如一个 chain 可以包含 prompt 模版、大语言模型及输出处理组件,来完成用户聊天功能。对各种不同的任务,LangChain 提供不同的 chain,如问答任务提供了 Question Answering Chain,文本摘要任务提供了 Summarization Chain,文本生成 SQL 任务提供了 SQL Chain,数学计算任务提供了 LLM Math Chain 等,同时可以自定义 Chain,Chain 组件提供了不同的模型推理模式,包括 stuff、map_reduce、refine、map-rerank 等,可以根据具体的任务需求,选择合适的 Chain 以及模型推理模式来完成任务。
Agents:LangChain 的高级功能,能根据用户的输入来决定调用那些工具,同时能组合一系列的 Chain 来完成复杂的任务,如提问:我的账号余额能买多少两黄金?Agents 通过 SQL chain 查询账号余额,通过调用网页查询接口的 LLM 查找实时黄金价格,通过调用 LLM Math 计算能买到的黄金数量完成最终的任务,这一系列的逻辑操作均可以在 Agents 中配置。
除 LangChain 外,目前另一个比较常用的开源大语言模型应用开发框架是 LIamaIndex。LIamaIndex 有丰富的数据导入接口,特别是对结构化数据的支持更友好,另外 LIamaIndex 的 Index 对多种模式的问答逻辑进行了封装,易于使用但缺少灵活性。LIamaIndex 支持与 LangChain 集成,2 个框架可以互相调用。
基于智能搜索的
大语言模型增强解决方案指南
结合 LangChain 的各类功能接口和亚马逊云科技的基础服务,我们构建了亚马逊云科技基于智能搜索的大语言模型增强解决方案指南,架构图如下:
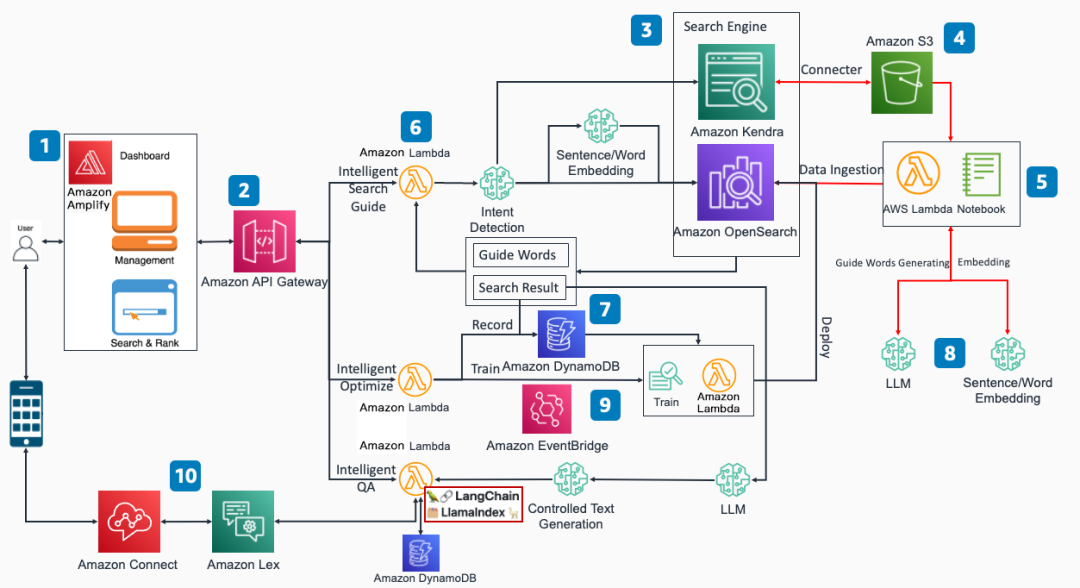
相比本系列博客第一篇《典型实用场景及核心组件介绍》的架构图,本篇的主要差异如下:
Intelligent QA 功能中,在实现功能逻辑的 Lambda 代码集成了 LangChain 和 LIamaIndex 框架,利用开源框架提升了方案灵活性和可扩展性,后续可以利用 LangChain 的能力快速增加新功能。
增加了 DynamoDB 组件,用于保存用户的多轮对话记录,实现多轮对话功能。
方案的工作流程示意图如下:
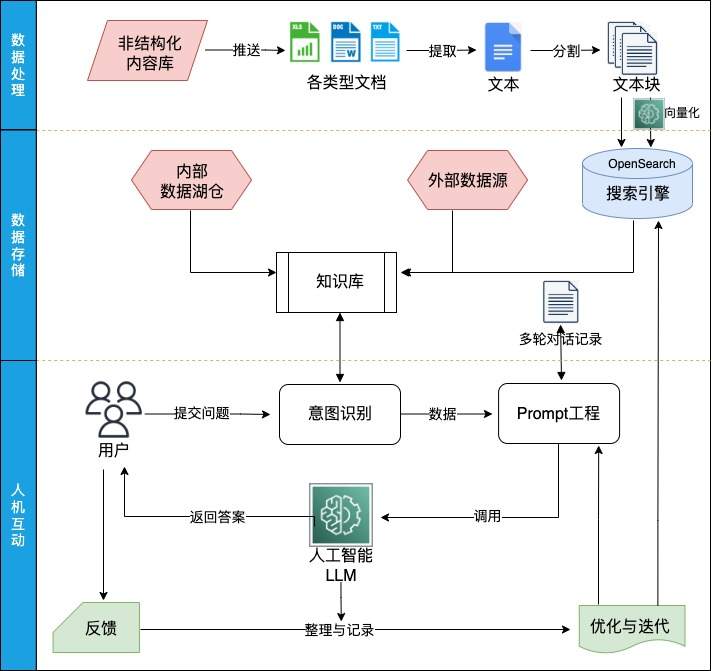
方案的工作流程及与 LangChain 的集成说明如下:
1. 数据处理和数据存储模块,集成 LangChain 的 Index 接口,支持多种外部数据导入,汇总各类数据,形成企业的知识库:
对非结构数据,主要支持 word、excel、PDF 和 txt 等常见文档,通过对非结构数据进行文本提取和文本拆分,得到多条文本块,通过调用部署在 SageMaker Endpoint 的向量模型,得到文本块相应的向量,最后将文本块和向量存储到 OpenSearch 搜索引擎中。
对结构化数据,通过集成 LlamaIndex 的 SQL Index,读取数据库取得相应的数据,目前主要通过规则生成 SQL 语言查询数据库,通过开源大语言模型生成 SQL 语言还在调测中。
如果需要查询网络获取实时信息,可以通过 Index 接口读取 URL 网址的信息,也可以通过搜索引擎接口查询网络实时信息。
2. 意图识别模块,集成 LangChain 的 RouterChain 接口,通过对用户输入问题进行语义判断,自动选择合适的数据来源来回答用户提出的问题。
3. Prompt 工程模块,集成 LangChain 的 Prompt 接口,对各类不同任务、不同场景、不同语种的 Prompt 进行管理和调优。同时集成 LangChain 的 Memory 接口,将用户的问题和答案存储在 DynamoDB,形成用户问答的 History 信息,作为多轮对话任务的大语言模型推理依据。
4. 大语言模型模块,集成 LangChain 的 Model 接口,调用部署在 SageMaker Endpoint 的开源大语言模型,对各类型的任务进行推理。
5. 反馈及优化迭代模块,通过记录有问题的答案,分析方案存在问题,及时在知识库和 Prompt 工程上调优。
相比其它基于 LangChain 的知识库私有化部署方案,本方案使用了亚马逊云科技的云原生服务,包括 SageMaker、OpenSearch 和 Lambda 等,这些云原生服务可以通过 auto scaling 机制,根据线上实际流量情况,快速扩展或收缩资源,以最优的性价比来确保线上业务平稳运行。
可通过方案的调测页面,方便地进行智能问答功能调试:
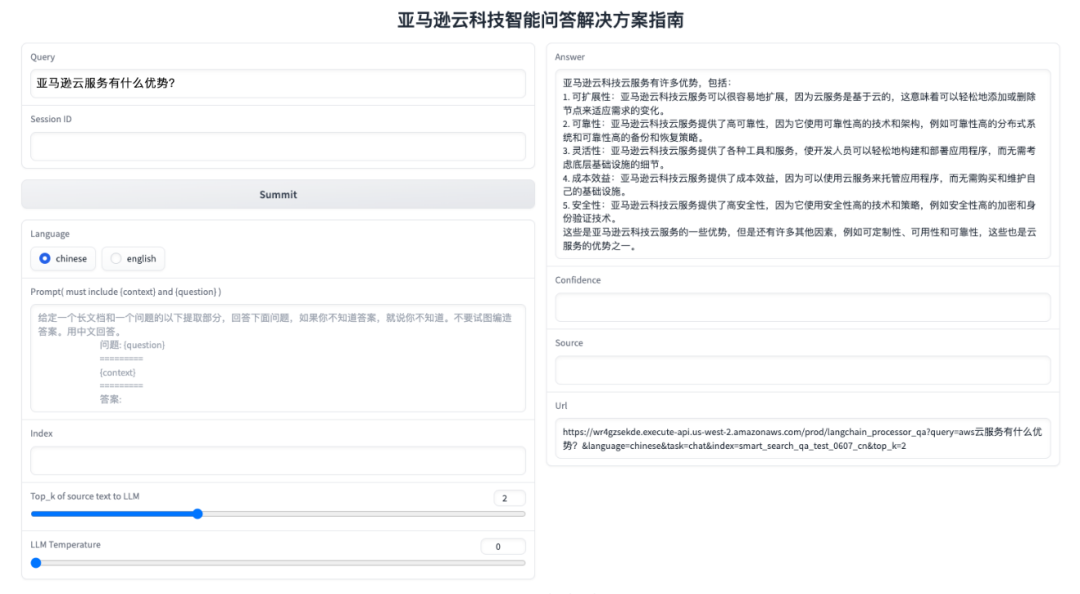
输入:
query:用户提问文本
Session ID:用户请求的 session id,对话信息会以 session id 为 key 保存在 DynamoDB 中
Language:语言选择,目前支持中文和英文,不同语言对应的文本分拆方法、文本向量模型和开源大语言模型均不相同
Prompt:提示词调试,可以在默认提示词的基础上,测试不同的提示词文本对结果的影响
Index:OpenSearch 存储数据的 Index
Top_k:放到大模型推理的相关文本的数量,如果文档资料比较规范,文档与 query 容易匹配,可以减少 Top_k 以增加答案的确定性
LLM Temperature:大语言模型的 temperature 参数,temperature 参数控制大语言模型的随机程度,temperature 越小答案的确定性越高
输出:
Answer:大语言模型对问题的推理输出
Confidence:答案的置性度
Source:与 Query 相关且放到大模型推理的文本
基于智能搜索的大语言模型增强解决方案指南在电商场景的应用
智能客服
随着电商行业的发展,消费者对网上购物的服务质量要求越来越高,客服已成为电商服务不可或缺的一环。为了节约成本,商家倾向于使用智能客服自动回答简单问题,智能客服解决不了的问题再由人工回复。然而各大电商平台的智能客服系统,往往通过关键词给出预设的答案,无法完成理解顾客提出的问题,答案与客户的需求存在差距,用户体验并不友好。而大语言模型的语义理解和归纳推理能力,非常适合智能客服场景。目前方案在智能客服场景的应用包括:
1. 基于企业知识库的智能问答。使用企业知识库数据,结合大语言模型的推理能力,实现精准问答。
下例在导入电商退换货示例文档后,顾客提出退货问题的回答:
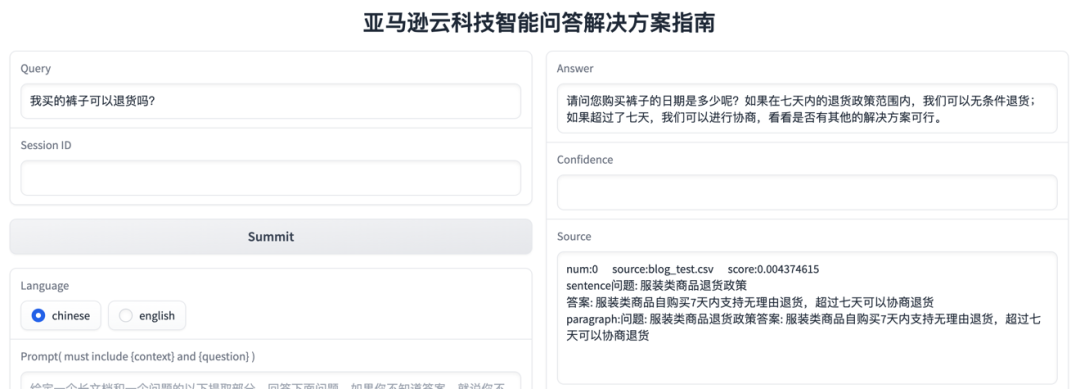
从上面例子可以看到,大语言模型理解顾客买的裤子属于服装类商品,有相应的 7 天无理由退货政策,但需要进一步获取购买日期才能确认是否能退货,最后生成了一个进一步获取顾客购买日期以及 7 天无理由退货政策解释的答案。
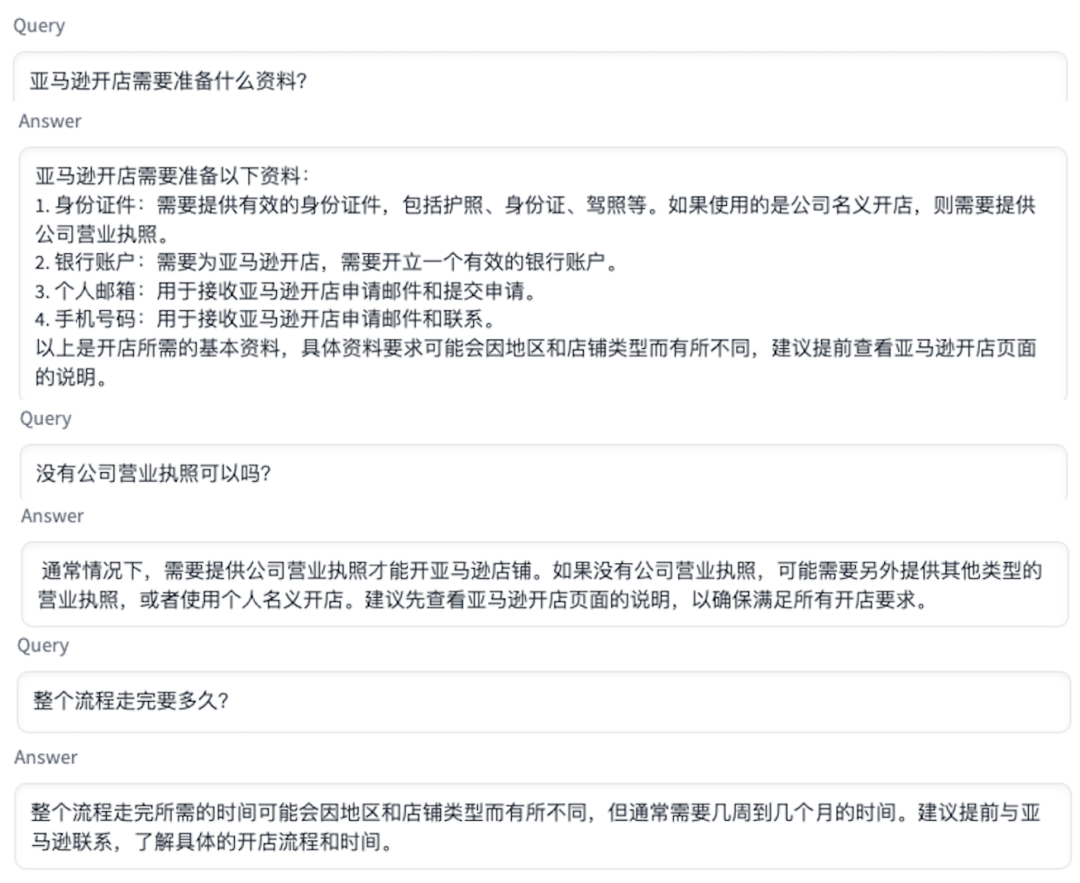
2. 多轮聊天。方案会把用户与大语言模型交互的信息保存起来,在下次对话时作为上下文信息嵌入 Prompt 提示词,让大语言模型知道上下文信息回答后续的问题。
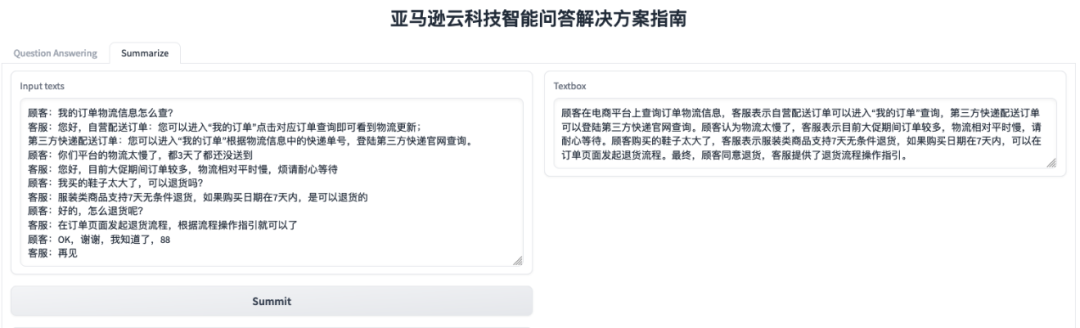
3. 文本摘要提取和文本报告生成。通过输入客服中的电话通话记录,快速生成通话摘要,准确提取用户在通话记录中提到的需求点,以便后续对通话记录进行分析和客户后续跟进营销。以下为客户咨询产品购买问题的案例:
智能推荐
当前电商行业逐步进入内容电商的时代,直播带货在电商的成交占例越来越高,直播带货的一个特点是主播与观众的互动非常频繁,观众通常针对直播场景进行提问。可以把智能问答系统当成导购员,辅助主播回答问题,比如在一个主播推销球鞋的直播间,观众可能问:“什么系列球鞋适合雨天踢球?”、“人比较胖穿哪个配色好看点?”、“哪双球鞋有情侣款?”,智能问答系统能结合产品的描述信息、产品的评价信息和用户的购买记录信息,对用户的提问直接输出产品推荐或产品使用建议,提升主播与观众互动的效率。
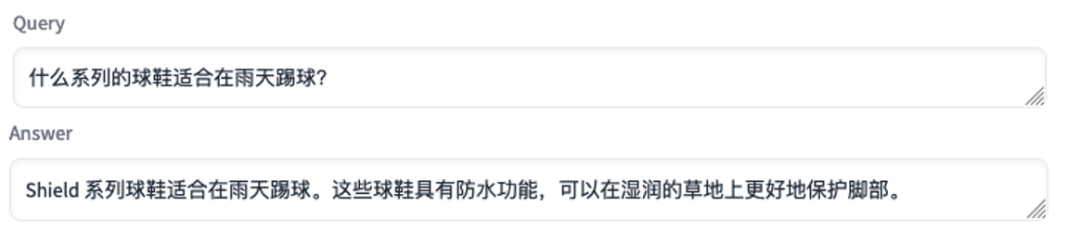
智能问答系统生成答案使用的产品示例数据:

上面例子中,在提供了不同系列的球鞋合适的使用场景信息后,智能问答系统能根据顾客提出的问题,将合适的产品推荐给用户。
常遇问题及解决方法
目前基于企业知识库的智能问答功能是需求和落地最多的功能,方案在不同的场景落地时,往往需要针对具体的场景需求进行调优,在落地中普遍遇到的问题以及解决方法有:
1. 如何在知识库中准确找到与问题相关的文本?
我们主要使用企业规则文档和之前的客服问答数据作为知识库,文档使用 docs 格式存储,使用句子和段落拆分数据,但存在的主要问题是:多个句子或段落组成一个逻辑段落,逻辑段落大小不一,如果按句子或段落拆分,有可能会把逻辑段落拆开,如可能把问题和答案拆成了 2 个文本块存储,或可能把上一逻辑段落的一部分加上下一个逻辑段落的一部分存储,导致检索时不能正确根据问题找到相应的答案。错误拆分示意图如下:
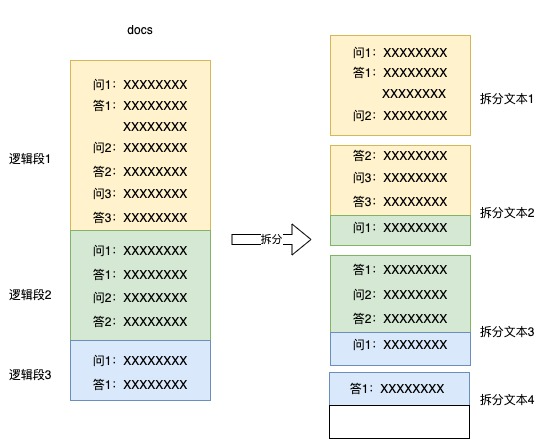
解决方案:
将 docs 文档处理转为 csv 格式存储,每个逻辑段的内容放到一行中,人工分隔逻辑段。
将拆分文本块中按句子或段落拆为多个向量化文本进行向量化,将整个逻辑块文本作为检索文本,将向量文本、向量和检索文本作为一条文本信息存储。
检索时,使用文本向量与问题向量进行匹配,使用整个逻辑块文本作为检索文本送到大模型推理。
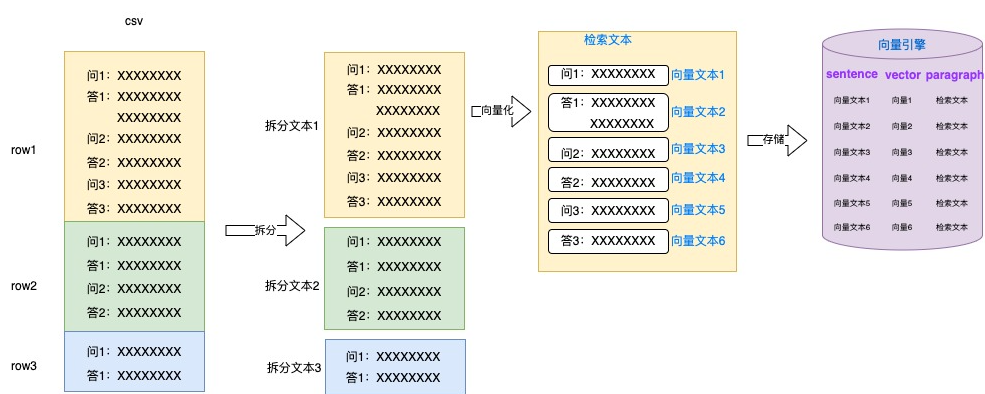
通过人工分隔逻辑块、细颗粒度文本向量、粗颗粒度文本召回等措施,大大提升了相关文本召回的准确率。
2. 如何评估大语言模型输出的答案是否胡编乱造?
通过计算答案置信度的方式来评估答案是否可靠,计算的维度包含以下 3 方面:
计算问题与答案的相似度,通常情况大语言模型生成的答案与问题的相似度会比较高,偶尔出现相似度比较低的情况,这种情况答案大概率与问题无关,另外偶尔出现相似度非常高的情况,这时答案文本基本是问题文本的重复,这种情况的答案也不能用。
计算答案文本与大模型推理使用的相关文本的相似度。如果答案文本与大模型推理使用的相关文本相似度较低,答案文本大概率是模型编造出来的。
计算答案文本在数据库召回的相关文本列表,与问题文本在数据库召回的相关文本列表的重合率。如果 2 个列表的重合率低,答案的置信度也会较低。
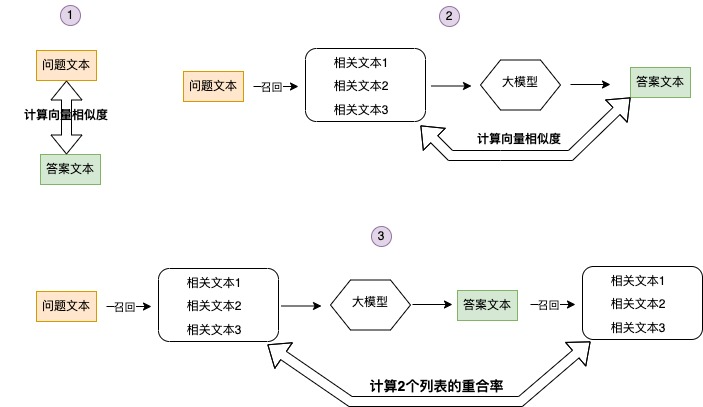
根据不同场景合理调整 3 个分数的阀值,来判断答案是否置信。
总结
目前,集成 LangChain 的基于智能搜索的大语言模型增强解决方案指南除在上面介绍的电商行业落地外,在制造、金融、教育和医疗等行业均有落地案例,同时方案已与 Amazon Kendra 服务集成,详情请大家关注我们即将推出的后续博客。
本篇作者

何波
亚马逊云科技行业解决方案架构师,曾就职于阿里六年,负责推荐算法,搜索算法和多模态匹配算法的开发工作,在电商行业各种场景的机器学习模型应用工作有丰富的经验。

姬军翔
亚马逊云科技资深解决方案架构师,在快速原型团队负责创新场景的端到端设计与实现。

田冰
亚马逊云科技应用科学家,长期从事自然语言处理、计算机视觉等领域的研究和开发工作。支持数据实验室项目,在大语言模型、目标检测等方向有丰富的算法及落地经验。

郑昊
Amazon GCR AI/ML Specialist SA。主要专注于 Language Model 的训练及推理、搜推算法及系统基于 Amzon AI/ML 技术栈的相关优化及方案构建。在阿里,平安有多年算法研发经验。


听说,点完下面4个按钮
就不会碰到bug了!


