
- 1基于SpringBoot+Dubbo构建的电商平台-微服务架构、商城、电商、微服务、高并发、kafka、Elasticsearc+源代码+文档说明_电商平台搭建架构 es
- 2《近匠》专访启明星辰安全研究中心副总监侯浩俊——物联网安全攻防的“线上幽灵”...
- 3家庭环境如何异地组网装修?
- 4DM_SQl(一)_dmsql
- 5栈:如何实现浏览器的前进和后退功能?_用c语言实现:浏览器的前进、后退功能,我想你肯定很熟悉吧?当你依次访问完一串页面
- 6【翻译】DiffusionDet: Diffusion Model for Object Detection_detr meets diffusion: object detection with score
- 7git使用_git remove vcs
- 8DDR3芯片读写控制及调试总结 — Xilinx FPGA(MIS)_xilinx ddr3 原理图设计
- 9计算机教师信息化大赛作品,我校计算机与设计学院教师获信息化教学大赛二等奖...
- 10required android.app.fragment,required android.support.v4.app.fragment
数据结构与算法——二叉树、堆、优先队列_结点的直接前驱
赞
踩
七、树
7.1 树
7.1.1 树的定义
树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物,例如族谱、单位的组织架构、等等。
树是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树
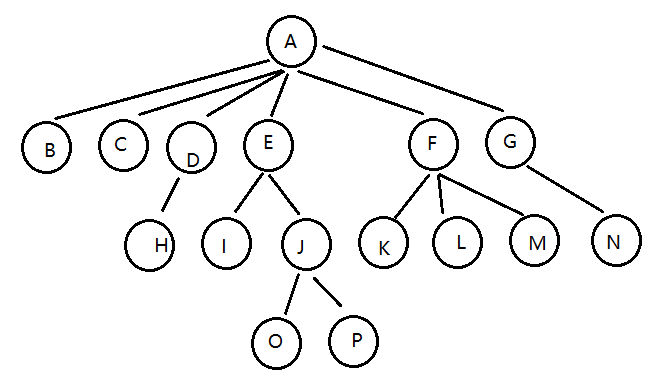
树具有以下特点:
- 每个结点有零个或多个子结点;
- 没有父结点的结点为根结点;
- 每一个非根结点只有一个父结点;
- 每个结点及其后代结点整体上可以看做是一棵树,称为当前结点的父结点的一个子树;
7.1.2 树的相关术语
结点的度:
一个结点含有的子树的个数称为该结点的度;
叶结点:
度为0的结点称为叶结点,也可以叫做终端结点
分支结点:
度不为0的结点称为分支结点,也可以叫做非终端结点
结点的层次:
从根结点开始,根结点的层次为1,根的直接后继层次为2,以此类推
结点的层序编号:
将树中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数。
树的度:
树中所有结点的度的最大值
树的高度(深度):
树中结点的最大层次
森林:
m(m>=0)个互不相交的树的集合,将一颗非空树的根结点删去,树就变成一个森林;给森林增加一个统一的根 结点,森林就变成一棵树
孩子结点:
一个结点的直接后继结点称为该结点的孩子结点
双亲结点(父结点):
一个结点的直接前驱称为该结点的双亲结点
兄弟结点:
同一双亲结点的孩子结点间互称兄弟结点
7.2 二叉树
7.2.1 二叉树的基本定义
二叉树就是度不超过2的树(每个结点最多有两个子结点)
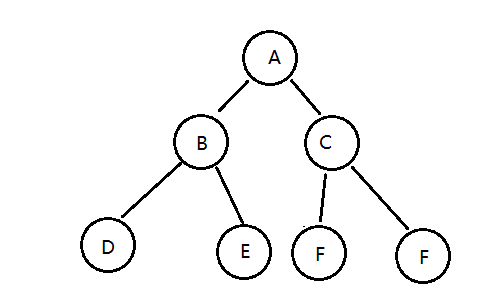
满二叉树:
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
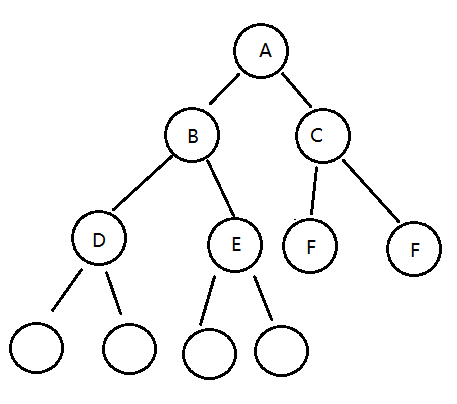
完全二叉树:
叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
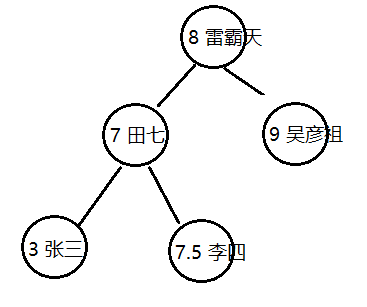
7.2.2 二叉查找树
二叉查找树是一种特殊的二叉树,相对较小的值保存在左节点中,较大的值保存在右节点中。
根据对图的观察,我们发现二叉树其实就是由一个一个的结点及其之间的关系组成的,按照面向对象的思想,我们 设计一个结点类来描述结点这个事物。
结点类API设计
| 类名 | Node<Key,Value> |
|---|---|
| 构造方法 | Node(Key key, Value value, Node left, Node right):创建Node对象 |
| 成员变量 | 1.public Node left:记录左子结点 2.public Node right:记录右子结点 3.public Key key:存储键 4.public Value value:存储值 |
二叉树API设计
| 类名 | BinaryTree<Key,Value> |
|---|---|
| 构造方法 | BinaryTree():创建BinaryTree对象 |
| 成员变量 | 1.private Node root:记录根结点 2.private int N:记录树中元素的个数 |
| 成员方法 | 1. public void put(Key key,Value value):向树中插入一个键值对 2.private Node put(Node x, Key key, Value val):给指定树x上,添加键一个键值对,并返回添加后的新树 3.public Value get(Key key):根据key,从树中找出对应的值 4.private Value get(Node x, Key key):从指定的树x中,找出key对应的值 5.public void delete(Key key):根据key,删除树中对应的键值对 6.private Node delete(Node x, Key key):删除指定树x上的键为key的键值对,并返回删除后的新树 7.public int size():获取树中元素的个数 |
7.2.3 代码实现
插入方法put实现思想:
-
如果当前树中没有任何一个结点,则直接把新结点当做根结点使用
-
如果当前树不为空,则从根结点开始:
2.1 如果新结点的key小于当前结点的key,则继续找当前结点的左子结点;
2.2 如果新结点的key大于当前结点的key,则继续找当前结点的右子结点;
2.3 如果新结点的key等于当前结点的key,则树中已经存在这样的结点,替换该结点的value值即可。

查询方法get实现思想:
从根节点开始:
- 如果要查询的key小于当前结点的key,则继续找当前结点的左子结点;
- 如果要查询的key大于当前结点的key,则继续找当前结点的右子结点;
- 如果要查询的key等于当前结点的key,则树中返回当前结点的value。
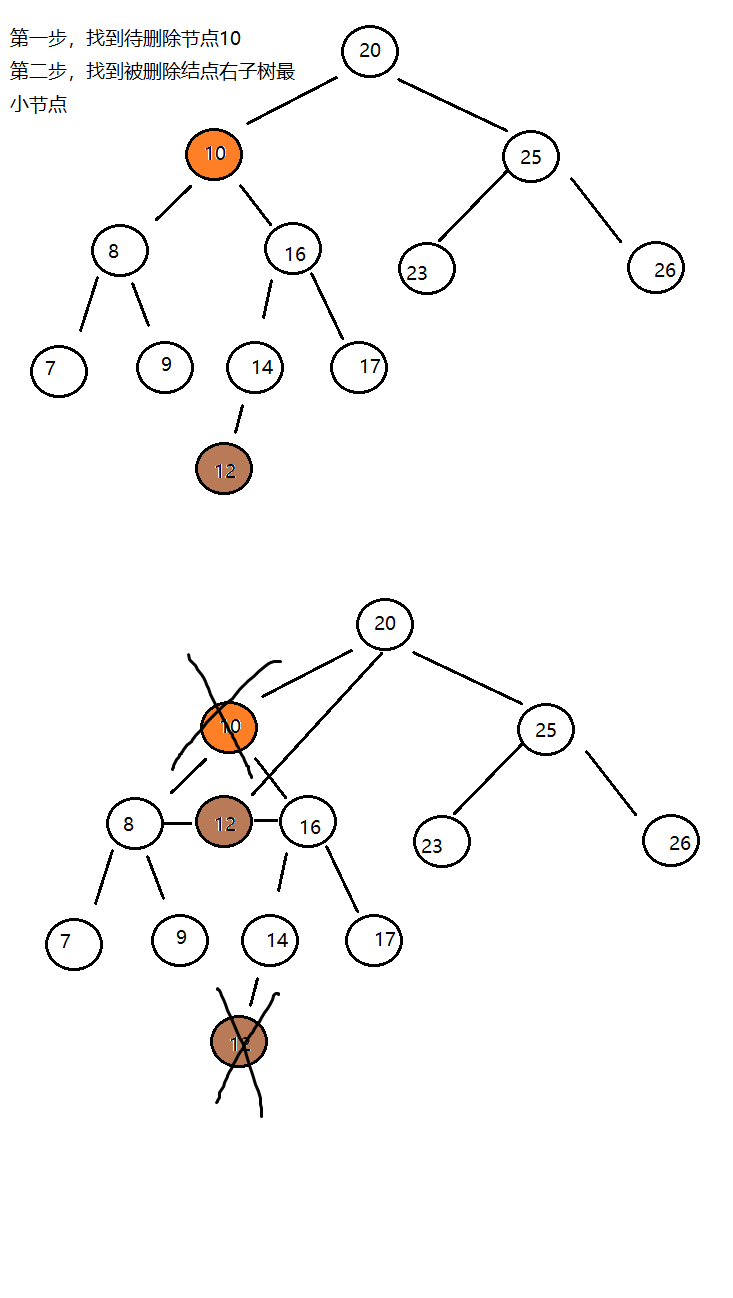
删除方法delete实现思想:
- 找到被删除结点;
- 找到被删除结点右子树中的最小结点minNode
- 删除右子树中的最小结点
- 让被删除结点的左子树成为最小结点minNode的左子树,让被删除结点的右子树称为最小结点minNode的右子树
- 让被删除结点的父节点指向最小结点minNode
package com.jg.tree; /** * 二叉树 * * @Author: 杨德石 * @Date: 2020/7/5 15:00 * @Version 1.0 */ public class BinaryTree { /** * 记录根结点 */ private Node root; /** * 记录树中的元素个数 */ private int n; public BinaryTree() { } /** * 向树中插入一个键值对 * * @param key * @param value */ public void put(Integer key, String value) { root = put(root, key, value); } /** * 给指定的数x上,添加一个键值对,并返回添加后的新数 * * @param tree * @param key * @param value * @return */ private Node put(Node tree, Integer key, String value) { if (tree == null) { // 直接把新结点当成根结点使用 // 个数+1 n++; return new Node(null, null, key, value); } // 新结点的key大于当前结点的key,继续找当前结点的右子结点 if (key > tree.key) { tree.right = put(tree.right, key, value); } else if (key < tree.key) { // 新结点的key小于当前结点的key,继续找当前结点的左子结点 tree.left = put(tree.left, key, value); } else { // 新结点的key等于当前结点的key tree.value = value; } return tree; } /** * 从树中找到对应的值 * * @param key * @return */ public String get(Integer key) { return get(root, key); } /** * 从指定的树x中,找出key对应的值 * * @param tree * @param key * @return */ private String get(Node tree, Integer key) { if (tree == null) { return null; } // 如果要查询的key大于当前节点的key。则继续查找当前节点的右子结点 if (key > tree.key) { return get(tree.right, key); } else if (key < tree.key) { // 如果要查询的key小于当前节点的key。则继续查找当前节点的左子结点 return get(tree.left, key); } else { // 要查找的key和当前结点的key相等,返回value return tree.value; } } /** * 根据key,删除树中对应的键值对 * * @param key */ public void delete(Integer key) { root = delete(root, key); } private Node delete(Node tree, Integer key) { if (tree == null) { return null; } // 待删除的key大于当前节点的key,继续找当前节点的右子结点 if (key > tree.key) { tree.right = delete(tree.right, key); } else if (key < tree.key) { tree.left = delete(tree.left, key); } else { // 待删除的key等于当前节点的key,说明当前结点就是要删除的结点 // 1. 如果当前结点的右子树不存在,则直接返回当前结点的左子节点 if (tree.right == null) { n--; return tree.left; } // 2. 如果当前结点的左子树不存在,则直接返回当前结点的右子节点 if (tree.left == null) { n--; return tree.right; } // 3. 当前结点的左右子树都存在 // 3.1 找到右子树中最小的结点 Node minNode = tree.right; // 二叉查找树的左节点一定比右节点小,所以这里只需要遍历左节点 if (minNode.left != null) { minNode = minNode.left; } // 到这里,就找到了当前节点右子树中最小的节点minNode // 3.2 删除右子树中最小的节点 Node node = tree.right; while (node.left != null) { if (node.left.left == null) { // 说明n的左节点就是我们要找的最小结点 node.left = null; } else { node = node.left; } } // 到这里,最小结点已经被删除 // 3.3 让被删除结点的左子树成为最小结点的左子树。让被删除结点的右子树,成为最小结点的右子树 minNode.left = tree.left; minNode.right = tree.right; // 3.4 让被删除结点的父节点指向最小结点 tree = minNode; // 个数-1 n--; } return tree; } public int size() { return n; } private static class Node { public Node left; public Node right; public Integer key; public String value; public Node(Node left, Node right, Integer key, String value) { this.left = left; this.right = right; this.key = key; this.value = value; } } } class Test11 { public static void main(String[] args) { BinaryTree tree = new BinaryTree(); tree.put(8, "雷霸天"); tree.put(3, "张三"); tree.put(7, "李四"); tree.put(6, "田七"); tree.put(9, "吴彦祖"); System.out.println(tree.get(7)); tree.delete(3); System.out.println(tree.size()); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
7.2.4 二叉查找树其他方法
查找二叉树中最小的键
在某些情况下,我们需要查找出树中存储所有元素的键的最小值,比如我们的树中存储的是学生的排名和姓名数 据,那么需要查找出排名最低是多少名?这里我们设计如下两个方法来完成:
| 方法 | 作用 |
|---|---|
| public Key min() | 找出树中最小的键 |
| private Node min(Node x) | 找出指定树X中,最小键所在的节点 |
- 1
查找二叉树中最大的键
在某些情况下,我们需要查找出树中存储所有元素的键的最大值,比如比如我们的树中存储的是学生的成绩和学生 的姓名,那么需要查找出最高的分数是多少?这里我们同样设计两个方法来完成:
| 方法 | 作用 |
|---|---|
| public Key max() | 找出树中最大的键 |
| public Node max(Node x) | 找出指定树中最大键所在的节点 |
- 1
7.2.5 二叉树的基础遍历☆
很多情况下,我们可能需要像遍历数组数组一样,遍历树,从而拿出树中存储的每一个元素,由于树状结构和线性 结构不一样,它没有办法从头开始依次向后遍历,所以存在如何遍历,也就是按照什么样的搜索路径进行遍历的问 题。
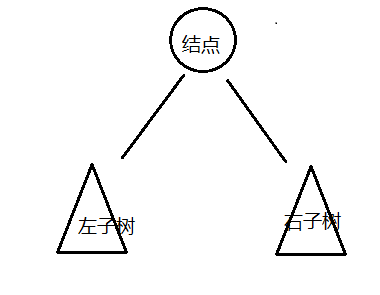
我们把树简单的画作上图中的样子,由一个根节点、一个左子树、一个右子树组成,那么按照根节点什么时候被访
问,我们可以把二叉树的遍历分为以下三种方式:
- 前序遍历; 先访问根结点,然后再访问左子树,最后访问右子树
- 中序遍历; 先访问左子树,中间访问根节点,最后访问右子树
- 后序遍历; 先访问左子树,再访问右子树,最后访问根节点
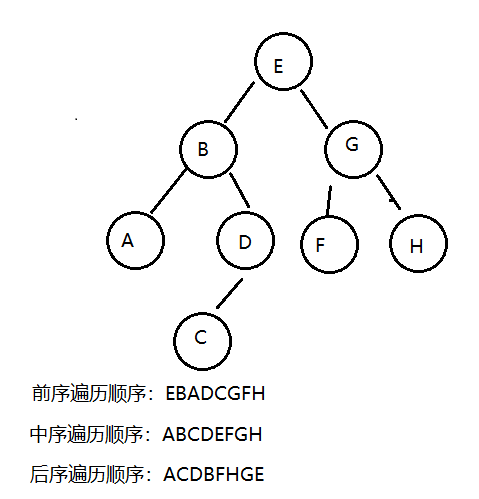
如果我们分别对下面的树使用三种遍历方式进行遍历,得到的结果如下:
7.2.5.1 前序遍历
遍历API
| 方法 | 作用 |
|---|---|
| public Queue preErgodic() | 使用前序遍历,获取整个树中的所有键 |
| private void preErgodic(Node x,Queue keys) | 使用前序遍历,把指定树x中的所有键放入到keys队列中 |
实现过程中,我们通过前序遍历,把每个结点的键取出,放入到队列中返回即可。
实现步骤:
- 把当前结点的key放入到队列中;
- 找到当前结点的左子树,如果不为空,递归遍历左子树
- 找到当前结点的右子树,如果不为空,递归遍历右子树
/** * 前序遍历 * * @return */ public Queue preErgodic() { Queue keys = new Queue(); preErgodic(root, keys); return keys; } private void preErgodic(Node tree, Queue keys) { if (tree == null) { return; } // 1.把当前结点的key放入到队列中 keys.enqueue(tree.key + ""); // 2.找到当前节点的左子树,如果不为空,递归遍历左子树 if (tree.left != null) { preErgodic(tree.left, keys); } // 3.找到当前结点的右子树,如果不为空,递归遍历右子树 if (tree.right != null) { preErgodic(tree.right, keys); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
7.2.5.2 中序遍历
| 方法 | 作用 |
|---|---|
| public Queue midErgodic() | 使用中序遍历,获取整个树中的所有键 |
| private void midErgodic(Node x,Queue keys) | 使用中序遍历,把指定树x中的所有键放入到keys队列中 |
实现步骤:
- 找到当前结点的左子树,如果不为空,递归遍历左子树
- 把当前结点的key放入到队列中;
- 找到当前结点的右子树,如果不为空,递归遍历右子树
/** * 中序遍历 * * @return */ public Queue midErgodic() { Queue keys = new Queue(); midErgodic(root, keys); return keys; } private void midErgodic(Node tree, Queue keys) { if (tree == null) { return; } // 1.找到当前结点的左子树,如果不为空,递归遍历左子树 if (tree.left != null) { midErgodic(tree.left, keys); } // 2.把当前结点的key放入到队列中 keys.enqueue(tree.key + ""); // 3.找到当前结点的右子树,如果不为空,递归遍历右子树 if (tree.right != null) { midErgodic(tree.right, keys); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
7.2.5.3 后序遍历
| 方法 | 作用 |
|---|---|
| public Queue afterErgodic() | 使用后序遍历,获取整个树中的所有键 |
| private void afterErgodic(Node x,Queue keys) | 使用后序遍历,把指定树x中的所有键放入到keys队列中 |
实现步骤:
- 找到当前结点的左子树,如果不为空,递归遍历左子树
- 找到当前结点的右子树,如果不为空,递归遍历右子树
- 把当前结点的key放入到队列中;
代码
/** * 后序遍历 * * @return */ public Queue afterErgodic() { Queue keys = new Queue(); afterErgodic(root, keys); return keys; } private void afterErgodic(Node tree, Queue keys) { if (tree == null) { return; } // 1.找到当前结点的左子树,如果不为空,递归遍历左子树 if (tree.left != null) { afterErgodic(tree.left, keys); } // 2.找到当前结点的右子树,如果不为空,递归遍历右子树 if (tree.right != null) { afterErgodic(tree.right, keys); } // 3.把当前结点的key放入到队列中 keys.enqueue(tree.key + ""); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
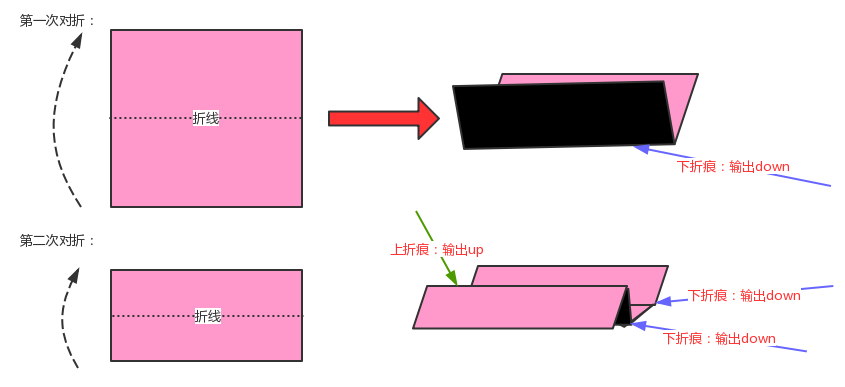
7.2.5.4 层序遍历
所谓的层序遍历,就是从根节点(第一层)开始,依次向下,获取每一层所有结点的值,有二叉树如下:
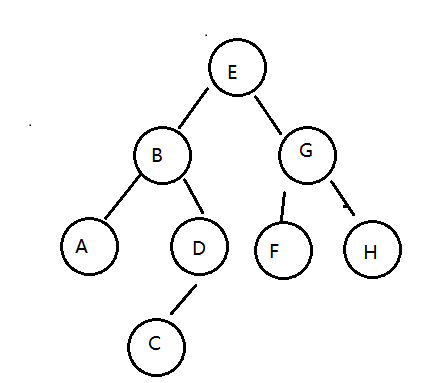
那么层序遍历的结果是:EBGADFHC
API
| 方法 | 作用 |
|---|---|
| public Queue layerErgodic() | 使用层序遍历,获取整个树中的所有键 |
实现步骤:
-
创建队列,存储每一层的结点;
-
使用循环从队列中弹出一个结点:
2.1获取当前结点的key;
2.2如果当前结点的左子结点不为空,则把左子结点放入到队列中
2.3如果当前结点的右子结点不为空,则把右子结点放入到队列中
代码
/** * 层序遍历 * * @return */ public Queue layerErgodic() { // 创建一个队列,存储每一层的节点 ArrayQueue<Node> nodes = new ArrayQueue<>(n); // 创建一个队列,用于存储遍历的节点 Queue keys = new Queue(); // 将当前节点存储到nodes中 nodes.add(root); // 遍历queue while (!nodes.isEmpty()) { // 出列 Node currentNode = nodes.remove(0); // 把节点的key存入到keys中 keys.enqueue(currentNode.key + ""); // 如果当前节点的左子节点不为空,则把左子节点放入到队列中 if (currentNode.left != null) { nodes.add(currentNode.left); } // 如果当前节点的右子节点不为空,把右子节点放到队列中 if (currentNode.right != null) { nodes.add(currentNode.right); } } return keys; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
非面向对象语言实现
/** * 层序遍历 * 对于面向对象语言 * * @return */ public Queue layerErgodic() { // 创建一个队列,存储每一层的节点 Queue nodes = new Queue(); // 创建一个队列,用于存储遍历的节点 Queue keys = new Queue(); // 将当前节点存储到nodes中 nodes.enqueue(root.key + ""); // 遍历queue while (!nodes.isEmpty()) { // 出列 String key = nodes.dequeue(); Node currentNode = getNode(root, Integer.parseInt(key)); // 把节点的key存入到keys中 keys.enqueue(currentNode.key + ""); // 如果当前节点的左子节点不为空,则把左子节点放入到队列中 if (currentNode.left != null) { nodes.enqueue(currentNode.left.key + ""); } // 如果当前节点的右子节点不为空,把右子节点放到队列中 if (currentNode.right != null) { nodes.enqueue(currentNode.right.key + ""); } } return keys; } private Node getNode(Node tree, Integer key) { if (tree == null) { return null; } // 如果要查询的key大于当前节点的key。则继续查找当前节点的右子结点 if (key > tree.key) { return getNode(tree.right, key); } else if (key < tree.key) { // 如果要查询的key小于当前节点的key。则继续查找当前节点的左子结点 return getNode(tree.left, key); } else { // 要查找的key和当前结点的key相等,返回value return tree; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
7.2.5.5 最大深度问题 ☆
给定一棵树,请计算树的最大深度(树的根节点到最远叶子结点的最长路径上的结点数);如下面这棵树的最大深度就是4
API设计
| 方法 | 作用 |
|---|---|
| public int maxDepth() | 计算整个树的最大深度 |
| private int maxDepth(Node x) | 计算指定树x的最大深度 |
实现步骤:
- 如果根结点为空,则最大深度为0;
- 计算左子树的最大深度;
- 计算右子树的最大深度;
- 当前树的最大深度=左子树的最大深度和右子树的最大深度中的较大者+1
/** * 计算最大深度 * * @return */ public int maxDepth() { return maxDepth(root); } private int maxDepth(Node tree) { if (tree == null) { return 0; } // 计算左右子树的最大深度 int max = 0; int leftMax = 0; int rightMax = 0; // 计算左子树最大深度 if (tree.left != null) { leftMax = maxDepth(tree.left); } // 计算右子树最大深度 if (tree.right != null) { rightMax = maxDepth(tree.right); } // 将二者较大的一方赋值给max。当前树的最大深度就是max+1 max = leftMax > rightMax ? leftMax + 1 : rightMax + 1; return max; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
7.2.6 折纸问题
需求:
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。此时 折痕是凹下去的,即折 痕突起的方向指向纸条的背面。如果从纸条的下边向上方连续对折2 次,压出折痕后展开,此时有三条折痕,从上 到下依次是下折痕、下折痕和上折痕。 给定一 个输入参数N,代表纸条都从下边向上方连续对折N次,请从上到下打印所有折痕的方向 例如:N=1时,打印: down;N=2时,打印: down down up
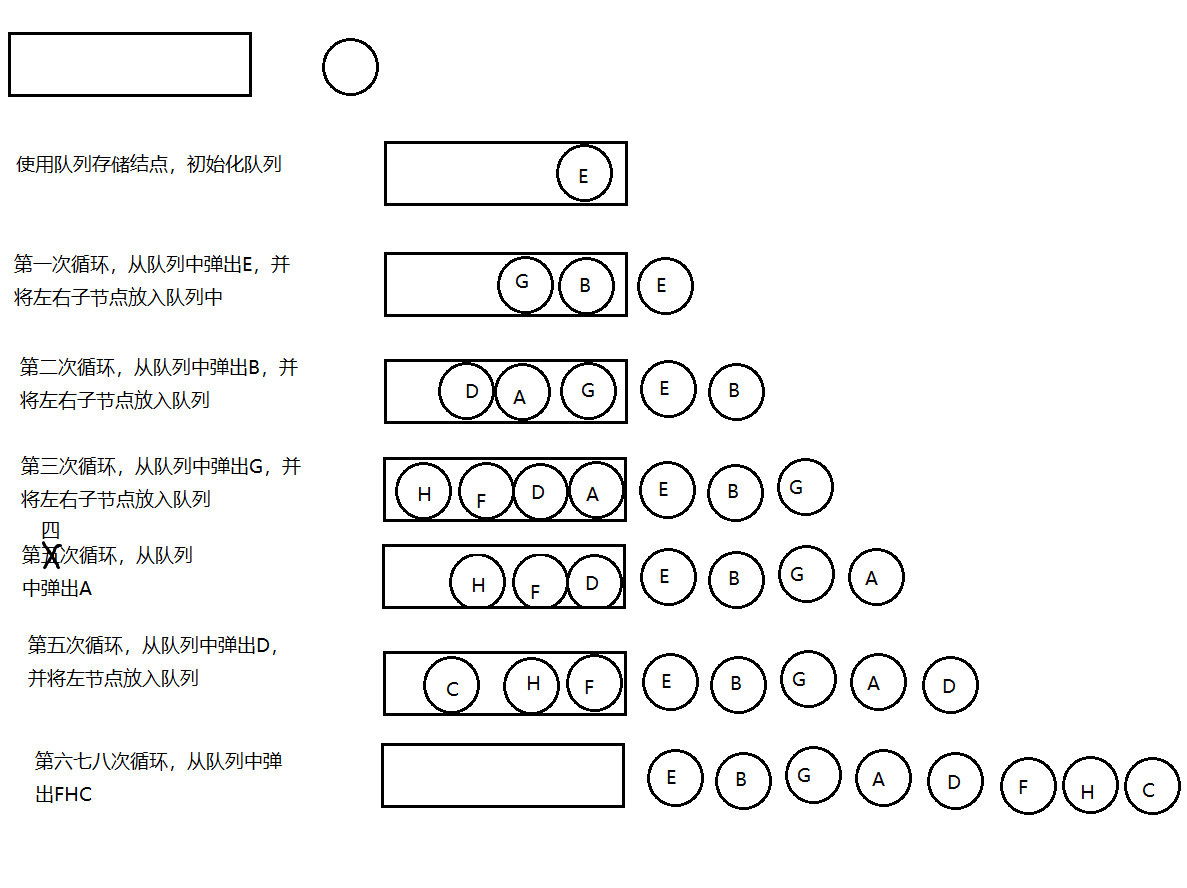
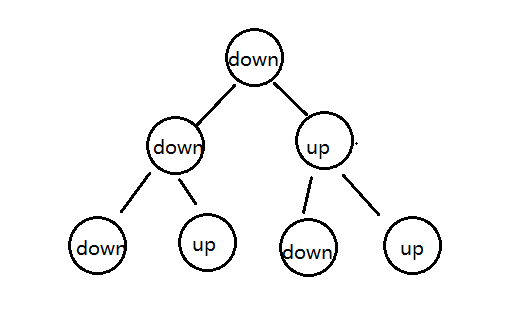
我们把对折后的纸张翻过来,让粉色朝下,这时把第一次对折产生的折痕看做是根结点,那第二次对折产生的下折 痕就是该结点的左子结点,而第二次对折产生的上折痕就是该结点的右子结点,这样我们就可以使用树型数据结构 来描述对折后产生的折痕。
这棵树有这样的特点:
- 根结点为下折痕;
- 每一个结点的左子结点为下折痕;
- 每一个结点的右子结点为上折痕;
实现步骤:
- 定义结点类
- 构建深度为N的折痕(树结构)
- 使用中序遍历,打印出树中所有结点的内容
构建深度为N的折痕树:
- 第一次对折,只有一条折痕,创建根节点
- 如果不是第一次对折,判断当前节点左右子树是不是空
- 如果是空,就给当前节点构建一个左子树(down)和一个右子树(up)
- 获取当前树的左右子树,重复第2步骤
代码
public class PaperFold { public static void main(String[] args) { Node node = initTree(3); print(node); } /** * 使用中序遍历打印出所有的节点 * @param tree */ private static void print(Node tree) { if(tree == null) { return; } print(tree.left); System.out.print(tree.item+","); print(tree.right); } /** * 构建深度为N的折痕树 * * @param n 需要构建的树的深度 */ private static Node initTree(int n) { // 根节点 Node root = null; // 循环n次 for (int i = 0; i < n; i++) { if (i == 0) { // 第一次对折,创建根节点 root = new Node("down", null, null); } else { // 不是第一次 // 创建一个队列,将根节点存放到队列中 PaperQueue queue = new PaperQueue(); // 根节点入列 queue.enqueue(root); // 遍历队列 while (!queue.isEmpty()) { // 从队列中取出一个节点 Node node = queue.dequeue(); // 3. 获取当前树的左右子树,重复第2步骤 Node left = node.left; Node right = node.right; // 判断左右子树是否为空,如果不为空,存入队列 if (left != null) { queue.enqueue(left); } if (right != null) { queue.enqueue(right); } // 1. 如果不是第一次对折,判断当前节点左右子树是不是空 if (node.left == null && node.right == null) { // 2. 如果是空,就给当前节点构建一个左子树(down)和一个右子树(up) node.left = new Node("down", null, null); node.right = new Node("up", null, null); } } } } return root; } // 定义结点类 private static class Node { public String item; public Node left; public Node right; public Node(String item, Node left, Node right) { this.item = item; this.left = left; this.right = right; } } /** * 存放节点的队列 */ private static class PaperQueue { /** * 首结点 */ private QueueNode head; /** * 当前队列的元素个数 */ private int n; /** * 记录最后一个结点 */ private QueueNode last; public PaperQueue() { head = new QueueNode(null, null); last = null; n = 0; } /** * 判断队列是否为空 * * @return */ public boolean isEmpty() { return n == 0; } /** * 从队列中拿出一个元素 * * @return */ public Node dequeue() { if (isEmpty()) { return null; } // 不是空,出列 // 获取当前的第一个元素(对应图中的1元素) QueueNode oldFirst = head.next; // 让head结点指向下一个结点(对应图中的2元素) head.next = head.next.next; // 个数-1 n--; if (isEmpty()) { last = null; } return oldFirst.item; } /** * 往队列中插入一个元素 * * @param t */ public void enqueue(Node t) { // 判断last是否为null if (last == null) { // last为空,要插入的元素就是last last = new QueueNode(t, null); // 让首结点指向last head.next = last; } else { // 不是第一个元素 // 取出旧结点(last) QueueNode oldLast = last; // 创建新的结点给last last = new QueueNode(t, null); // 让旧的last元素指向新的结点 oldLast.next = last; } // 个数+1 n++; } private class QueueNode { public Node item; public QueueNode next; public QueueNode(Node item, QueueNode next) { this.item = item; this.next = next; } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
7.3 堆
7.3.1 堆的定义
堆是计算机科学中一类特殊的数据结构的统称,堆通常可以被看做是一棵完全二叉树的数组对象。
堆的特性:
-
它是完全二叉树,除了树的最后一层结点不需要是满的,其它的每一层从左到右都是满的,如果最后一层结点不是满的,那么要求左满右不满。

-
它通常用数组来实现。
具体方法就是将二叉树的结点按照层级顺序放入数组中,根结点在位置1,它的子结点在位置2和3,而子结点的子 结点则分别在位置4,5,6和7,以此类推。
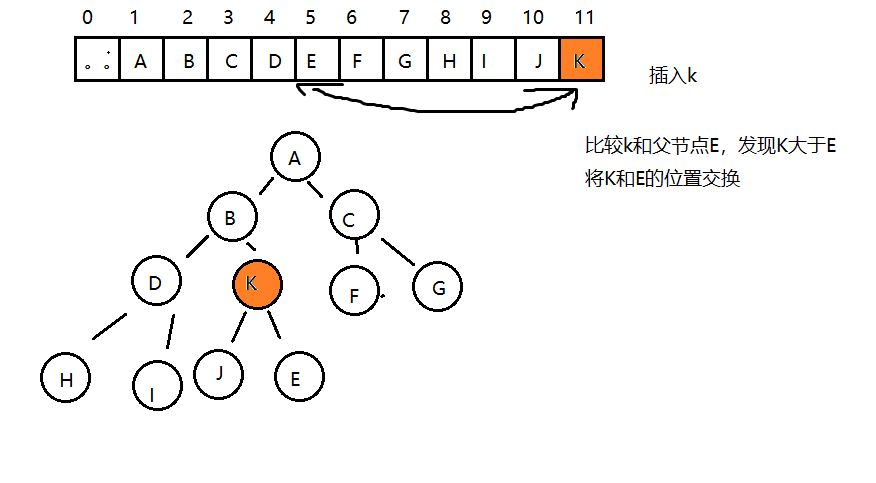
如果一个结点的位置为k,则它的父结点的位置为[k/2],而它的两个子结点的位置则分别为2k和2k+1。这样,在不 使用指针的情况下,我们也可以通过计算数组的索引在树中上下移动:从a[k]向上一层,就令k等于k/2,向下一层就 令k等于2k或2k+1。
- 每个结点都大于等于它的两个子结点。这里要注意堆中仅仅规定了每个结点大于等于它的两个子结点,但这两个子结点的顺序并没有做规定,跟我们之前学习的二叉查找树是有区别的。
API设计
| 类名 | Heap |
|---|---|
| 构造方法 | Heap(int capacity):创建容量为capacity的Heap对象 |
| 成员方法 | 1.private boolean less(int i,int j):判断堆中索引i处的元素是否小于索引j处的元素 2.private void exch(int i,int j):交换堆中i索引和j索引处的值 3.public T delMax():删除堆中最大的元素,并返回这个最大元素 4.public void insert(T t):往堆中插入一个元素 5.private void swim(int k):使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置 6.private void sink(int k):使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置 |
| 成员变量 | 1.private T[] imtes : 用来存储元素的数组 2.private int N:记录堆中元素的个数 |
7.3.2 代码实现
7.3.2.1 insert方法实现
堆是用数组完成数据元素的存储的,由于数组的底层是一串连续的内存地址,所以我们要往堆中插入数据,我们只 能往数组中从索引0处开始,依次往后存放数据,但是堆中对元素的顺序是有要求的,每一个结点的数据要大于等 于它的两个子结点的数据,所以每次插入一个元素,都会使得堆中的数据顺序变乱,这个时候我们就需要通过一些 方法让刚才插入的这个数据放入到合适的位置
所以,如果往堆中新插入元素,我们只需要不断的比较新结点a[k]和它的父结点a[k/2]的大小,然后根据结果完成 数据元素的交换,就可以完成堆的有序调整。
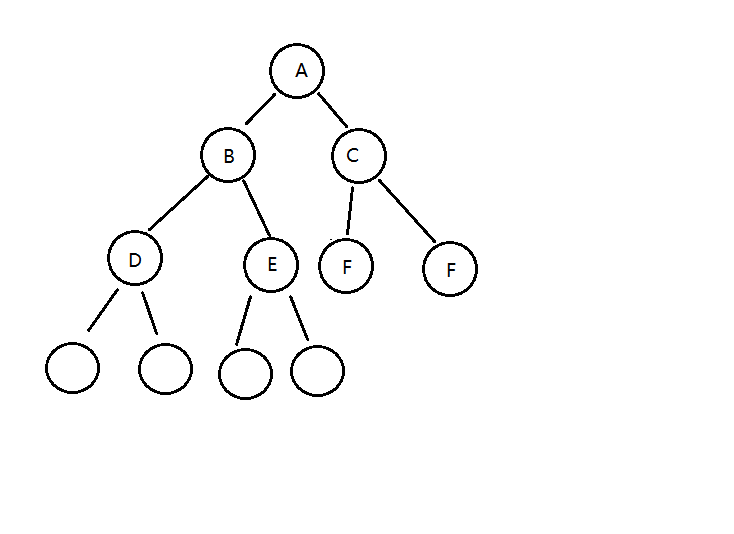
7.3.2.2 delMax删除最大元素方法
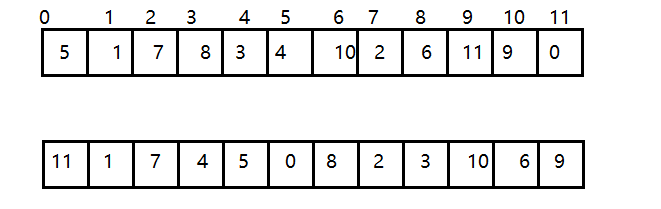
由堆的特性我们可以知道,索引1处的元素,也就是根结点就是最大的元素,当我们把根结点的元素删除后,需要 有一个新的根结点出现,这时我们可以暂时把堆中最后一个元素放到索引1处,充当根结点,但是它有可能不满足 堆的有序性需求,这个时候我们就需要通过一些方法,让这个新的根结点放入到合适的位置。
所以,当删除掉最大元素后,只需要将最后一个元素放到索引1处,并不断的拿着当前结点a[k]与它的子结点a[2k] 和a[2k+1]中的较大者交换位置,即可完成堆的有序调整。
7.3.2.3 具体代码
public class Heap { /** * 存储元素 */ private Integer[] items; /** * 记录堆中的元素个数 */ private int n; public Heap(int capacity) { items = new Integer[capacity + 1]; n = 0; } /** * 判断堆中索引i处的元素是否小于索引j处的元素 * * @param i * @param j * @return */ private boolean less(int i, int j) { return items[i] < items[j]; } /** * 交换堆中索引i处和索引j处的值 * * @param i * @param j */ private void exch(int i, int j) { int temp = items[i]; items[i] = items[j]; items[j] = temp; } /** * 判断堆中最大的元素,并返回这个最大元素 * * @return */ public Integer delMax() { // 获取最大值 Integer max = items[1]; // 交换索引1 处和索引n处的值 exch(1, n); // 删除索引n处的值 items[n] = null; // 个数-1 n--; // 下沉 sink(1); return max; } public int size() { return n; } /** * 往堆中插入一个元素 * * @param item */ public void insert(Integer item) { items[++n] = item; // 上浮 swim(n); } /** * 使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置 * * @param k */ private void swim(int k) { // 判断k是否大于1,大于1的情况下再上浮 while (k > 1) { // 比较当前节点和父节点,如果父节点比当前结点小,那么就交换 if (less(k / 2, k)) { exch(k / 2, k); } k = k / 2; } } /** * 使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置 * * @param k */ private void sink(int k) { // 判断当前是不是数组末尾 while (k * 2 <= n) { // 找到子节点中的较大者 int maxIndex; if (k * 2 + 1 <= n) { // 存在右子结点 if (less(k * 2, k * 2 + 1)) { // 左节点比右节点小 maxIndex = k * 2 + 1; } else { maxIndex = k * 2; } } else { // 不存在右结点 maxIndex = k * 2; } // 比较当前节点和子节点中的较大者,如果当前结点不小,就结束循环 if (!less(k, maxIndex)) { break; } // 当前节点小,交换位置 exch(k, maxIndex); k = maxIndex; } } public static void main(String[] args) { Heap heap = new Heap(11); heap.insert(5); heap.insert(1); heap.insert(2); heap.insert(8); heap.insert(7); heap.insert(9); heap.insert(11); heap.insert(4); heap.insert(6); heap.insert(10); heap.insert(3); while (heap.size() > 0) { int delValue = heap.delMax(); System.out.println(delValue); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
7.3.3 堆排序☆
给定一个数组:
String[] arr = {“S”,“O”,“R”,“T”,“E”,“X”,“A”,“M”,“P”,“L”,“E”}
请对数组中的字符按从小到大排序。
实现步骤:
- 构造堆;
- 得到堆顶元素,这个值就是最大值;
- 交换堆顶元素和数组中的最后一个元素,此时所有元素中的最大元素已经放到合适的位置;
- 对堆进行调整,重新让除了最后一个元素的剩余元素中的最大值放到堆顶;
- 重复2~4这个步骤,直到堆中剩一个元素为止。
API设计
| 类名 | HeapSort |
|---|---|
| 成员方法 | 1.public static void sort(int[] source):对source数组中的数据从小到大排序 2.private static void createHeap(int[] source, int[] heap):根据原数组source,构造出堆heap 3.private static boolean less(int[] heap, int i, int j):判断heap堆中索引i处的元素是否小于索引j处的元素 4.private static void exch(int[] heap, int i, int j):交换heap堆中i索引和j索引处的值 5.private static void sink(int[] heap, int target, int range):在heap堆中,对target处的元素做下沉,范围是0~range。 |
构造堆,最直观的就是直接把数组中的每一个元素都insert到堆中,这样新的数组就是一个堆。这样时间复杂度有点高了。
我们可以直接将原数组拷贝到items中,再从items中长度的一半位置处,从右往左扫描,对每一个元素进行下沉处理
代码实现
public static void main(String[] args) { Integer[] arr = {3, 6, 1, 2, 9, 7, 8, 4, 5, 10, 11}; sort(arr); for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); } } public static void sort(Integer[] arr) { // 构造堆 // 创建一个比原数组大1的堆 Heap heap = new Heap(arr.length); heap.initHeap(arr); // 构造堆 int index = heap.size(); while (index != 1) { heap.exch(1, index); index--; // 交换完了,下沉 heap.sink(1, index); } // 堆中的数据已经有序,拷贝到arr中 for (int i = 0; i < arr.length; i++) { arr[i] = heap.get(i + 1); } } /** * 根据数组构造堆 * * @param arr */ public void initHeap(Integer[] arr) { // 遍历数组,将数组中的元素添加到堆中 for (int i = 0; i < arr.length; i++) { items[i + 1] = arr[i]; n++; } // 从items的n/2位置遍历到1位置 for (int i = n / 2; i > 0 ; i--) { sink(i, n); } } /** * 使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置 * * @param k */ public void sink(int k, int end) { // 判断当前是不是数组末尾 while (k * 2 <= end) { // 找到子节点中的较大者 int maxIndex; if (k * 2 + 1 <= end) { // 存在右子结点 if (less(k * 2, k * 2 + 1)) { // 左节点比右节点小 maxIndex = k * 2 + 1; } else { maxIndex = k * 2; } } else { // 不存在右结点 maxIndex = k * 2; } // 比较当前节点和子节点中的较大者,如果当前结点不小,就结束循环 if (!less(k, maxIndex)) { break; } // 当前节点小,交换位置 exch(k, maxIndex); k = maxIndex; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
7.4 优先队列
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在某些情况下,我们可能需要找出 队列中的最大值或者最小值,例如使用一个队列保存计算机的任务,一般情况下计算机的任务都是有优先级的,我 们需要在这些计算机的任务中找出优先级最高的任务先执行,执行完毕后就需要把这个任务从队列中移除。普通的 队列要完成这样的功能,需要每次遍历队列中的所有元素,比较并找出最大值,效率不是很高,这个时候,我们就 可以使用一种特殊的队列来完成这种需求,优先队列。
优先队列按照其作用不同,可以分为以下三种:
最大优先队列:
可以获取并删除队列中最大的值
最小优先队列:
可以获取并删除队列中最小的值
索引优先队列:
可以根据索引去操作队列中元素的值
7.4.1 最大优先队列
最大优先队列的实现就是堆的实现,前面已经讲解过了,这里不再重复介绍。
7.4.2 最小优先队列
最小优先队列实现起来也比较简单,我们同样也可以基于堆来完成最小优先队列。
我们前面学习堆的时候,堆中存放数据元素的数组要满足都满足如下特性:
- 最大的元素放在数组的索引 1 处
- 每个结点的数据总是大于或者等于它的两个子结点数据。
其实我们之前实现的堆可以把它叫做最大堆,我们可以用相反的思想实现最小堆,让堆中存放数据元素的数组满足 如下特性:
- 最小的元素放在数组的索引 1 处
- 每个结点的数据总是小于或者等于它的两个子结点数据。
这样我们就能快速的访问到堆中最小的数据。
API设计
| 类名 | MinPriorityQueue |
|---|---|
| 构造方法 | MinPriorityQueue(int capacity):创建容量为capacity的MinPriorityQueue对象 |
| 成员方法 | 1.private boolean less(int i,int j):判断堆中索引i处的元素是否小于索引j处的元素 2.private void exch(int i,int j):交换堆中i索引和j索引处的值 3.public T delMin():删除队列中最小的元素,并返回这个最小元素 4.public void insert(T t):往队列中插入一个元素 5.private void swim(int k):使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置 6.private void sink(int k):使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置 7.public int size():获取队列中元素的个数 8.public boolean isEmpty():判断队列是否为空 |
| 成员变量 | 1.private T[] imtes : 用来存储元素的数组 2.private int N:记录堆中元素的个数 |
代码实现
public class MinPriorityQueue { /** * 存储元素 */ private Integer[] items; /** * 记录堆中的元素个数 */ private int n; public MinPriorityQueue(int capacity) { items = new Integer[capacity + 1]; n = 0; } /** * 判断堆中索引i处的元素是否小于索引j处的元素 * * @param i * @param j * @return */ private boolean less(int i, int j) { return items[i] < items[j]; } /** * 交换堆中索引i处和索引j处的值 * * @param i * @param j */ private void exch(int i, int j) { int temp = items[i]; items[i] = items[j]; items[j] = temp; } public int size() { return n; } public boolean isEmpty() { return n == 0; } /** * 上浮算法,使索引k处的元素能在堆中处于一个正确的位置 * * @param k */ private void swim(int k) { // 如果没有父结点,就不再上浮 while (k > 1) { // 如果当前节点比父结点小,就交换 if (less(k, k / 2)) { exch(k, k / 2); } k = k / 2; } } /** * 下沉算法 * * @param k */ private void sink(int k) { // 如果没有子结点,就不需要下沉 while (k * 2 <= n) { // 找出子结点中最小值的索引 int minIndex = 2 * k; // 如果有右结点,并且右结点小于左节点 if (k * 2 + 1 <= n && less(k * 2 + 1, k * 2)) { minIndex = 2 * k + 1; } // 如果当前节点小于子节点中的最小值,则结束循环 if (less(k, minIndex)) { break; } // 当前节点大,交换 exch(minIndex, k); ; k = minIndex; } } /** * 插入方法 * * @param item */ public void insert(Integer item) { items[++n] = item; swim(n); } public Integer delMin() { // 取出最小值 Integer min = items[1]; // 交换最小值和最后一个值 exch(1, n); // 删掉最后一个元素 items[n] = null; // 元素个数-1 n--; // 下沉 sink(1); return min; } } class Test12 { public static void main(String[] args) { MinPriorityQueue queue = new MinPriorityQueue(11); queue.insert(5); queue.insert(1); queue.insert(2); queue.insert(8); queue.insert(7); queue.insert(9); queue.insert(11); queue.insert(4); queue.insert(6); queue.insert(10); queue.insert(3); while (queue.size() > 0) { int delValue = queue.delMin(); System.out.println(delValue); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
7.4.3 索引优先队列
在之前实现的最大优先队列和最小优先队列,他们可以分别快速访问到队列中最大元素和最小元素,但是他们有一 个缺点,就是没有办法通过索引访问已存在于优先队列中的对象,并更新它们。为了实现这个目的,在优先队列的 基础上,学习一种新的数据结构,索引优先队列。接下来我们以最小索引优先队列举列。
实现思路
步骤一:
存储数据时,给每一个数据元素关联一个整数,例如insert(int k,T t),我们可以看做k是t关联的整数,那么我们的实 现需要通过k这个值,快速获取到队列中t这个元素,此时有个k这个值需要具有唯一性。
最直观的想法就是我们可以用一个T[] items数组来保存数据元素,在insert(int k,T t)完成插入时,可以把k看做是 items数组的索引,把t元素放到items数组的索引k处,这样我们再根据k获取元素t时就很方便了,直接就可以拿到 items[k]即可。
步骤二:
步骤一完成后的结果,虽然我们给每个元素关联了一个整数,并且可以使用这个整数快速的获取到该元素,但是, items数组中的元素顺序是随机的,并不是堆有序的,所以,为了完成这个需求,我们可以增加一个数组int[]pq,来 保存每个元素在items数组中的索引,pq数组需要堆有序,也就是说,pq[1]对应的数据元素items[pq[1]]要小于等 于pq[2]和pq[3]对应的数据元素items[pq[2]]和items[pq[3]]
步骤三:
通过步骤二的分析,我们可以发现,其实我们通过上浮和下沉做堆调整的时候,其实调整的是pq数组。如果需要 对items中的元素进行修改,比如让items[0]=12,那么很显然,我们需要对pq中的数据做堆调整,而且是调整 pq[5]中元素的位置。但现在就会遇到一个问题,我们修改的是items数组中0索引处的值,如何才能快速的知道需 要挑中pq[5]中元素的位置呢?
最直观的想法就是遍历pq数组,拿出每一个元素和0做比较,如果当前元素是0,那么调整该索引处的元素即可, 但是效率很低。
我们可以另外增加一个数组,int[] qp,用来存储pq的逆序。例如: 在pq数组中:pq[2]=7; 那么在qp数组中,把7作为索引,2作为值,结果是:qp[7]=2;

当有了pq数组后,如果我们修改items[0]=12,那么就可以先通过索引0,在qp数组中找到qp的索引:qp[0]=5, 那么直接调整pq[5]即可。
API设计
| 类名 | IndexMinPriorityQueue |
|---|---|
| 构造方法 | IndexMinPriorityQueue(int capacity):创建容量为capacity的IndexMinPriorityQueue对象 |
| 成员方法 | 1.private boolean less(int i,int j):判断堆中索引i处的元素是否小于索引j处的元素 2.private void exch(int i,int j):交换堆中i索引和j索引处的值 3.public int delMin():删除队列中最小的元素,并返回该元素关联的索引 4.public void insert(int i,T t):往队列中插入一个元素,并关联索引i 5.private void swim(int k):使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置 6.private void sink(int k):使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置 7.public int size():获取队列中元素的个数 8.public boolean isEmpty():判断队列是否为空 9.public boolean contains(int k):判断k对应的元素是否存在 10.public void changeItem(int i, T t):把与索引i关联的元素修改为为t 11.public int minIndex():最小元素关联的索引 12.public void delete(int i):删除索引i关联的元素 |
| 成员变量 | 1.private T[] imtes : 用来存储元素的数组 2.private int[] pq:保存每个元素在items数组中的索引,pq数组需要堆有序 3.private int [] qp:保存qp的逆序,pq的值作为索引,pq的索引作为值 4.private int N:记录堆中元素的个数 |

