- 1回溯算法的五类问题:组合、排列、子集、分割、棋盘_回溯算法图排列问题
- 2c语言/c++(数据结构篇) 之 排序方法的实现实例(直接插入排序;冒泡排序;希尔排序;快速排序;简单选择排序)(6/7)_数据结构要求在一个程序中实现四种排序算法直接插入希尔冒泡快速
- 3ollama 使用技巧集锦_ollama指定路径
- 4vivado约束方法_vivado cell位置约束
- 5《数学建模与数学实验》第5版 非线性规划 习题4.4_数学建模与数学实验第五版课后答案
- 6sqoop从mysql导入hdfs_sqoop 从mysql导入数据到hdfs、hive
- 7对于MySQL的了解你知道多少?_你对mysql了解多少
- 8ym——android源代码大放送(实战开发必备)
- 9评测 香橙派OrangePi在智能交通上的应用_and 5~85 indexes correspond object's confidence
- 10rabbitmq动态创建queue和监听queue_springboot动态创建rabbitmq队列监听
Amazon Aurora 故障恢复之降低 DNS 切换对应用影响篇
赞
踩


点击上方入口立即【自由构建 探索无限】
一起共赴年度科技盛宴!
1. 前言
数据库,尤其是 OLTP 的数据库是应用程序的基石。尽管成熟的数据库通常运行起来都相对稳定,但是否能容忍更多的底层故障,是否能快速地从故障中恢复出来,对应用程序而言是非常重要的。Amazon Aurora 作为亚马逊自研的云原生数据库,除兼容性、性能、扩展性外,它在设计之初,就以极致的可用性作为目标,尽可能减少故障对应用程序的影响。
Amazon Aurora 在故障恢复方面的设计理念主要包括:
1.能在较大范围故障时仍然提供服务:跨3个可用区的6备份存储使它在一个可用区和另一个额外备份发生故障时仍能提供服务;跨区域的全球数据库能在主区域发生故障时快速切换到从区域;
2.加快故障恢复的速度:将数据拆分成10 GB 粒度存储单元使单个存储单元能在秒级别恢复;通过分布式存储进行并行恢复等;快速找到健康计算节点先进行节点替换来使整个集群尽快提供服务。
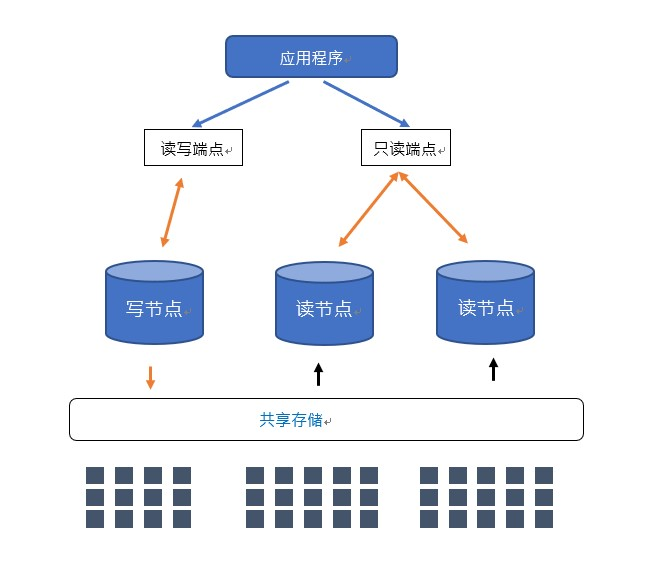
Amazon Aurora 的架构示意图如上所示,它以端点 endpoint 的形式对外提供服务,用户可以通过读写端点来访问 Aurora 写节点;通过只读端点访问 Aurora 读节点。当写节点发生故障时,Aurora 会进行如下的 failover 过程:
根据不同节点 failover 优先级和复制延迟来选择一个读节点,将其提升成新的写节点。因为该节点角色发生切换,需要重启该节点。
尝试恢复原来的写节点并让它成为新的读节点。这里也会涉及到节点重启。
待新的写节点重启成功以后,定位读写端点指向新的写节点。这里涉及到域名的更新,依赖于 Route53 的实现。
待新的读节点重启成功以后,定位只读端点指向新的读节点。这里同样涉及到域名更新,依赖于 Route53 的实现。
通常情况下,Aurora 的 failover 通常能在30-60秒内完成,能对应用程序产生较低影响。那么,是否有可能进一步加快 Aurora failover 的速度呢?本篇文章会重点介绍如何在 Aurora 进行故障恢复的时候避免或者减少 DNS 的影响(步骤3),从而加快故障切换速度。具体内容涵盖故障切换各步骤的时间消耗、花费时间的分析排查以及减少对应用程序影响的几种方案。
2. Aurora failover 的过程
在 Aurora 发生 failover 的时候,我们可以通过观测 Event 事件来查看 failover 过程中 Aurora 的读写节点究竟发生了哪些操作。以一写一读的集群为例,如果我们在控制台点击 failover,可以观测到如下事件。
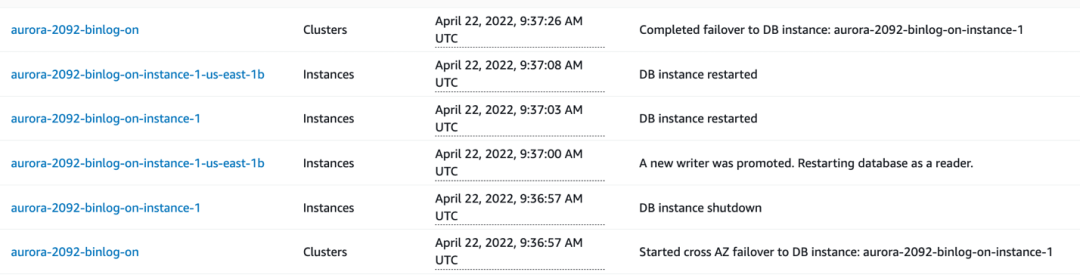
其中,aurora-2092-binlog-on 为 Aurora 集群,aurora-2092-binlog-on-instance-1 为原来的读节点,aurora-2092-binlog-on-instance-1-us-east-1b 为原来的写节点。
从事件中我们可以看到,当 Aurora 集群发生故障切换时,会先后有如下事件生成:
集群开始 failover
原来读节点重启(会成为新的写节点)
原来写节点重启(会成为新的读节点)
新写节点重启成功
新读节点重启成功
集群 failover 完成
整个集群 failover 过程在29秒完成。其中,新的写节点重启成功用了6秒,也就是新的写节点在6秒以后就可以接受请求。但是,由于用户访问 Aurora 是利用域名的方式(Aurora 的读写域名和只读域名),新写节点启动后需要更新域名,而域名更新需要一定的时间,所以应用程序用域名连接 Aurora 时体验到的连接中断时间会高于6秒。

3. 如何分析故障切换时
时间消耗在哪里?
当遇到 Aurora 集群故障切换影响应用程序较长时间时,我们可以采用如下几步甄别最长的时间花费在哪里,再对症下药,进行优化。
3.1 信息收集
除了第2节讲的对 event 的观测以外,我们可以在访问 Aurora 集群的客户端环境中打印 DNS 对应 IP 的信息,来获得 DNS 域名切换的时间。
可以采用如下代码:
- cat nslookup.sh
- #!/bin/bash
- while true
- do
- rwendpoint=$(nslookup aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com)
- roendpoint=$(nslookup aurora-2092-binlog-on.cluster-ro-cttuqplcao81.us-east-1.rds.amazonaws.com)
- now=$(date +"%Y-%m-%d %H:%M:%S")
- echo "$now \n $ rwendpoint \n $ roendpoint "
- echo "----------------------"
- sleep 1
- done
*左滑查看更多
另外,Aurora 的写节点和读节点的信息可以从这张系统表中 information_schema.replica_host_status 推理得到,也可以设计类似于监控域名变化的逻辑实时监控读写节点的状态。这张表里读写节点的变化是不依赖于 DNS 的,应该与 Event 中的节点重启的时间能够匹配。
- MySQL [(none)]> select server_id AS Instance_Identifier, if(session_id = 'MASTER_SESSION_ID','writer', 'reader') as Role from information_schema.replica_host_status;
- +---------------------------------------------+--------+
- | Instance_Identifier | Role |
- +---------------------------------------------+--------+
- | aurora-2092-binlog-on-instance-1 | writer |
- | aurora-2092-binlog-on-instance-1-us-east-1b | reader |
- +---------------------------------------------+--------+
- 2 rows in set (0.00 sec)
*左滑查看更多
3.2 分析排查
Aurora 的 event 发生的时间是分析排查的基础。总体来讲,进行分析排查可以分两步走:
首先判断是否 Aurora 新写节点启动本身消耗时间比较久。对比集群开始 failover 的时间和新写节点重启完成的时间。如果此部分花费时间过长,有可能是在发生故障时应用的并发负载比较大,所以新的写节点启动之前需要处理发生故障时正在执行的事务的信息,比如 redolog, undolog以及 binlog 的处理和恢复等。对于这种情况,可以考虑进行应用负载的优化或者是查看 Aurora 新的版本是否有相应的优化,考虑升级。例如,Aurora 的版本1.23以上版本及2.08以上版本对于大的事务(单个事务对应的 binlog 文件大于0.5 GB)恢复速度有明显提升,如果您的 Aurora 集群中打开了 binlog 并且有大事务,可以考虑升级 Aurora 版本。或者如果 binlog 不是必须的,可以直接通过参数修改把 binlog 关闭。
接下来判断故障恢复时间是否由 DNS 更新延迟引发。可以结合 Aurora event 打印时间和 nslookup.sh 的输出对比进行分析。以第2节的 failover 的事件发生时为例,nslookup.sh 的脚本输出为:
- 2022-04-22 09:37:11 \n Server: 172.31.0.2
- Address: 172.31.0.2#53
-
- Non-authoritative answer:
- aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com canonical name = aurora-2092-binlog-on-instance-1-us-east-1b.cttuqplcao81.us-east-1.rds.amazonaws.com.
- Name: aurora-2092-binlog-on-instance-1-us-east-1b.cttuqplcao81.us-east-1.rds.amazonaws.com
- Address: 172.31.11.251 \n Server: 172.31.0.2
- Address: 172.31.0.2#53
-
- Non-authoritative answer:
- aurora-2092-binlog-on.cluster-ro-cttuqplcao81.us-east-1.rds.amazonaws.com canonical name = aurora-2092-binlog-on-instance-1.cttuqplcao81.us-east-1.rds.amazonaws.com.
- Name: aurora-2092-binlog-on-instance-1.cttuqplcao81.us-east-1.rds.amazonaws.com
- Address: 172.31.12.155
-
- ----------------------
- 2022-04-22 09:37:12 \n Server: 172.31.0.2
- Address: 172.31.0.2#53
-
- Non-authoritative answer:
- aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com canonical name = aurora-2092-binlog-on-instance-1.cttuqplcao81.us-east-1.rds.amazonaws.com.
- Name: aurora-2092-binlog-on-instance-1.cttuqplcao81.us-east-1.rds.amazonaws.com
- Address: 172.31.12.155 \n Server: 172.31.0.2
- Address: 172.31.0.2#53
-
- Non-authoritative answer:
- aurora-2092-binlog-on.cluster-ro-cttuqplcao81.us-east-1.rds.amazonaws.com canonical name = aurora-2092-binlog-on-instance-1.cttuqplcao81.us-east-1.rds.amazonaws.com.
- Name: aurora-2092-binlog-on-instance-1.cttuqplcao81.us-east-1.rds.amazonaws.com
- Address: 172.31.12.155

*左滑查看更多
我们可以看到,在9:37:12的时候发生的读写 DNS 域名的切换,读写 DNS 均指向了新的写节点,在此之前,读写 DNS 指向的还是原来的写节点。事实上,从第2节我们可以看到,新的写节点在9:37:03的时候就已经重启成功了,所以对于应用程序来说,这9秒的时间是在等待 DNS 的更新。
4. 减少 DNS 切换的影响,
提升 Failover 的速度
如果经过第3节的分析发现 DNS 的切换速度比较慢,也就是写节点重启成功以后 DNS 还需要经过一段时间才能更换,我们可以采用下面几种方式进行改进。
4.1 控制客户端 DNS TTL 的时间
检查客户端是否缓存了 DNS 及设置时间。如果设置较久的话,可以考虑将客户端的 DNS 的 TTL 调小。如果您的客户端应用程序正在缓存数据库实例的域名服务 (DNS) 数据,请将生存时间 (TTL) 值设置为小于 30 秒。数据库实例的底层 IP 地址在故障转移后可能会发生变化。因此,如果您的应用程序试图连接到不再使用的 IP 地址,那么缓存 DNS 数据达较长时间可能导致连接失败。如果连接使用读取器终端节点,并且只读副本实例之一处于维护状态或已删除,那么具有多个只读副本的 Aurora 数据库集群也会遭遇连接失败。
4.2 使用 RDS Proxy
RDS Proxy 是基于 Aurora/RDS 之上提供的一个代理层,它有三个特性:
1)连接池能够实现连接的多路复用。如果应用对数据库的并发请求比较多,直接打到 Aurora 数据库上会耗费很多资源。可以使用 RDS Proxy 来实现连接复用,支持更多的并发应用,并减少新建连接的需要。
2)增强的安全性。如果不希望直接把底层数据库的密码直接暴露,可以使用 RDS Proxy,通过使 RDS Proxy 访问 Secrets Manager 里的密码来增强安全性。
3)快速的故障恢复时间。RDS Proxy 避开了 Aurora 发生故障切换时节点切换带来的域名 DNS 记录更新的问题,用户通过连接 RDS Proxy 可以避免域名更新的时间消耗。
在现有的 Aurora 集群上开启 RDS Proxy,您可以参考此篇文档中的步骤来实现。应用程序端所做的更改是将 Aurora读写的端点替换成 RDS Proxy 的端点,因为 RDS Proxy 也提供对 Aurora 只读端点的访问和封装。如果您的应用程序中使用了 Aurora 的只读端点,也是可以使用 RDS Proxy 的读取端点来进行配置的。
为测试 RDS Proxy 的效果,可以利用类似下面小程序来对比在Aurora故障恢复期间直接连接 Aurora 集群和连接 RDS Proxy 对应的影响。程序很简单,每隔 1s 连接到 Aurora 或者 RDS Proxy 集群运行一次 update+select now() 的操作。连接到 Aurora 的程序:
文档:
https://docs.aws.amazon.com/zh_cn/AmazonRDS/latest/AuroraUserGuide/rds-proxy-setup.html
- cat testAurora.sh
- #!/bin/bash
- while true
- do
- mysql -h aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com -uadmin -p12345678 -Dlili -e "update wr_table_aurora set c='new' where a=2; select now();"
- now=$(date +"%T")
- echo "update done: $now"
- sleep 1
- done
*左滑查看更多
在第2节的故障恢复的恢复过程中,可以看到连接到脚本的执行输出为:
- ./testAurora.sh >testAurora.out
- [ec2-user@ip-172-31-1-113 rdsproxy-failover]$ ./testAurora.sh >testAurora.out
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-2092-binlog-on.cluster-cttuqplcao81.us-east-1.rds.amazonaws.com' (111)
- ERROR 1290 (HY000) at line 1: The MySQL server is running with the —read-only option so it cannot execute this statement
- ERROR 1290 (HY000) at line 1: The MySQL server is running with the —read-only option so it cannot execute this statement
- ERROR 1290 (HY000) at line 1: The MySQL server is running with the —read-only option so it cannot execute this statement
- ERROR 1290 (HY000) at line 1: The MySQL server is running with the —read-only option so it cannot execute this statement
- ERROR 1290 (HY000) at line 1: The MySQL server is running with the —read-only option so it cannot execute this statement
*左滑查看更多
查看 testAurora.out 的输出片段:
- now()
- 2022-04-22 09:36:57
- update done: 09:36:57
- now()
- 2022-04-22 09:36:58
- update done: 09:36:58
- update done: 09:36:59
- update done: 09:37:00
- update done: 09:37:01
- update done: 09:37:02
- update done: 09:37:03
- update done: 09:37:04
- update done: 09:37:05
- update done: 09:37:06
- update done: 09:37:08
- update done: 09:37:09
- update done: 09:37:10
- update done: 09:37:11
- update done: 09:37:12
- now()
- 2022-04-22 09:37:13
- update done: 09:37:13
- now()
- 2022-04-22 09:37:14
- update done: 09:37:14
从9:36:59一直到9:37:12,应用程序一直是不可用的状态,一开始会报后台数据库连接不上的错误,然后会报只读 read-only 错误,原因在于在原来的写节点重启的过程中,应用程序是不停去连接的,所以报连接失败错误,而当写节点也就是新的读节点重启成功以后,因为域名还在指向它,所以会报只读错误,直至9:37:12域名更新以后应用程序才恢复正常。
使用 RDS Proxy 测试的脚本内容为:
- cat testRDSProxy.sh
- #!/bin/bash
- while true
- do
- mysql -h aurora-proxy-2.proxy-cttuqplcao81.us-east-1.rds.amazonaws.com -uadmin -p12345678 -Dlili -e "update wr_table set c='new' where a=2; select now();"
- now=$(date +"%T")
- echo "update done: $now"
- sleep 1
- done
*左滑查看更多
在 failover 的过程中运行脚本:
./testRDSProxy.sh >testRDSProxy.out查看 testRDSProxy.out 的输出片段:
- 2022-04-22 09:36:57
- update done: 09:36:57
- now()
- 2022-04-22 09:36:58
- update done: 09:36:58
- now()
- 2022-04-22 09:37:03
- update done: 09:37:03
- now()
- 2022-04-22 09:37:04
- update done: 09:37:04
- now()
- 2022-04-22 09:37:05
- update done: 09:37:05
- now()
应用程序同样在9:36:59开始没有结果返回,但是在9:37:03即恢复正常,这个时间也就是第2节提到的新写节点启动的时间,4秒的 failover 时间相对于直接连接 Aurora 集群的13秒的时间节约了9秒的时间。此外,在使用 RDS Proxy 的过程中,从9:36:59到9:37:03之间的应用并没有报错信息,这是因为 RDS Proxy 会在底层 Aurora 故障切换的过程中对新发送过来的应用程序进行缓存,当新的写节点启动后,直接将缓存的 SQL 语句发送给新的写节点,这样能一定程度上降低应用程序直接出错带来的影响。
RDS Proxy 的实现逻辑是它能够动态连接到底层 Aurora 数据库的各个实例,进而在实例状态发生变化时及时捕捉,并更新内部的路由定向机制,所以成功避免了 DNS 域名切换的时间,提升了 Aurora 故障切换的速度。此外,RDS Proxy 是 Serverless 的架构,开启较为简单,而且可以根据应用程序对数据库的负载弹性伸缩,可以做为您在考虑降低 failover DNS 切换时间的一个选择。
4.3 使用智能驱动
如果您的应用程序采用的是 Java 语言,除 RDS Proxy 外,也可以考虑使用亚马逊提供的智能驱动。智能驱动在连接到 Aurora 集群时,会拿到整个集群的拓扑和各个节点的角色信息(是写节点还是读节点)维持在缓存中。有了这个拓扑,在节点发生变化时,就可以快速拿到变化的节点的角色信息,而无需再依赖的 DNS 的解析。
智能驱动:
https://awslabs.github.io/aws-mysql-jdbc/
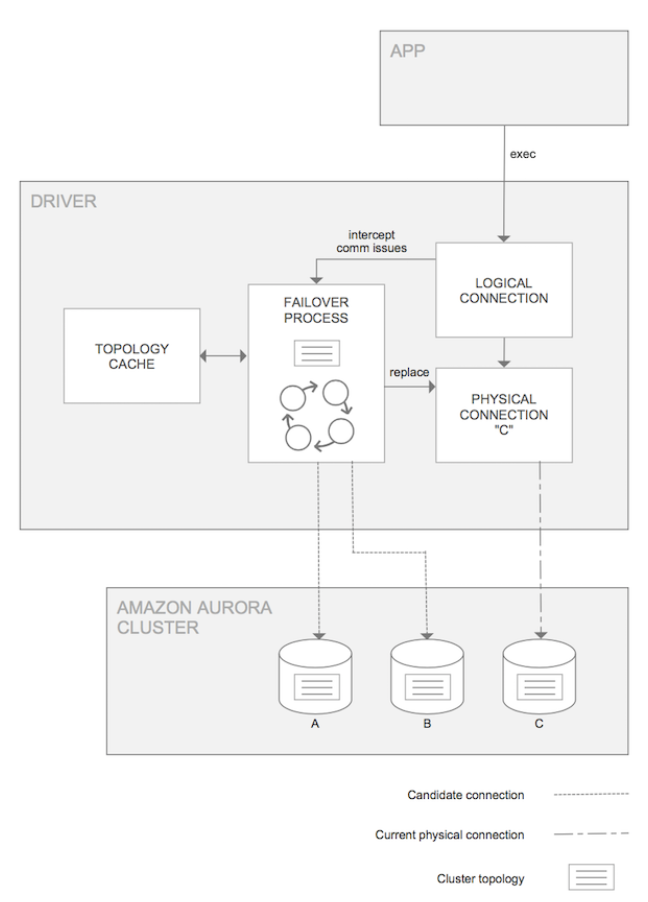
上图是智能驱动自身的逻辑示意,应用程序连接到它时,会维护一个逻辑的连接和物理的连接。比如现在的写节点是 C,但同时它的拓扑缓存中会存放着节点 A 和 B 的信息,这样如果节点 C 发生了故障,能够及时检测并将物理连接切换到 A 或 B 节点(取决于 Aurora 决定 failover 到哪个节点)而逻辑连接是保持不变的。
智能驱动与 MySQL 的普通驱动使用方法是一样的,您只需要更换驱动,并将连接字符串更换为如下格式即可。注意这里的 url 的字符串前面是 jdbc:mysql:aws。缺省情况下,故障切换的能力是开启的,也可以通过参数调整的方式进行关闭。
jdbc:mysql:aws://* 集群名称*.*集群 id*.us-east-2.rds.amazonaws.com:3306/* 数据库名 *?useSSL=false&characterEncoding=utf-8
这篇博客里测试对比了智能驱动与普通依赖于 DNS 解析的驱动对应用程序影响的时间。和 RDS Proxy 类似,平均影响时间会降至4秒。详细测试方法可以查阅该博客。
博客:
https://aws.amazon.com/cn/blogs/database/improve-application-availability-with-the-aws-jdbc-driver-for-amazon-aurora-mysql/

亚马逊的智能驱动是开源的,采用的 Apache 协议。如果您的应用程序不是用 Java 语言,也可以采用类似逻辑来进行实现,即拿到 Aurora 集群的拓扑结构和各个节点的角色信息,然后阶段性连接(比如每隔1秒),看是否发生变化,如果发生变化构建新的物理连接。
4.4 事件捕捉,触发连接重置
另外一种可以考虑的思路是利用事件监控机制,触发 Lambda 方法,在 Lambda 方法中检测到新写节点重启成功或者是集群重启成功以后,触发应用程序的重联机制。这篇博客的最后一个小节里提供了一个示例来使用 Lambda 方法来触发 ShardingSphere-Proxy 到 Aurora 的数据源创建的 DistSQL 语句,从而避免了只读错误不断抛出的问题。
博客:
https://aws.amazon.com/cn/blogs/china/make-further-progress-shardingsphere-proxy-chapter-of-amazon-auroras-reading-and-writing-ability-expansion/
如果有些语言的驱动进行了 IP 地址的缓存,在 DNS 切换时并不能检测到,仍然使用原来 IP 进行连接的话,会一直报只读的错误。这种情况,也可以考虑使用 SQL 错误码分析并重置连接的方式来做为一个短期解决问题的方案。以 MySQL 8.0 为例,一般需要关注的信息有:
1836错误码。数据库在只读模式。
1792错误码。事务在只读模式。
Analyze/optimize 表的输出中含有 read-only 的错误。
下面是抛出错误的一些示例:
- MySQL [(none)]> create database test;
- ERROR 1836 (HY000): Running in read-only mode
-
- MySQL [aaa]> begin;
- Query OK, 0 rows affected (0.00 sec)
- MySQL [aaa]> select count() from wr_table;
- +----------+
- | count() |
- +----------+
- | 1277 |
- +----------+
- 1 row in set (0.01 sec)
-
- MySQL [aaa]> insert into wr_table values(51);
- ERROR 1792 (25006): Cannot execute statement in a READ ONLY transaction.
-
- MySQL [aaa]> analyze table wr_table;
- +--------------+---------+----------+----------------------------------------------------------------+
- | Table | Op | Msg_type | Msg_text |
- +--------------+---------+----------+----------------------------------------------------------------+
- | aaa.wr_table | analyze | Warning | InnoDB: Running in read-only mode |
- | aaa.wr_table | analyze | Error | Running in read-only mode |
- | aaa.wr_table | analyze | Error | Unable to store dynamic table statistics into data dictionary. |
- | aaa.wr_table | analyze | status | Unable to write table statistics to DD tables |
- +--------------+---------+----------+----------------------------------------------------------------+
- 4 rows in set (0.00 sec)
-
- MySQL [aaa]> optimize table wr_table;
- +--------------+----------+----------+-----------------------------------+
- | Table | Op | Msg_type | Msg_text |
- +--------------+----------+----------+-----------------------------------+
- | aaa.wr_table | optimize | Warning | InnoDB: Running in read-only mode |
- | aaa.wr_table | optimize | Warning | InnoDB: Running in read-only mode |
- | aaa.wr_table | optimize | Error | Running in read-only mode |
- | aaa.wr_table | optimize | error | Corrupt |
- +--------------+----------+----------+-----------------------------------+
- 4 rows in set (0.00 sec)
*左滑查看更多
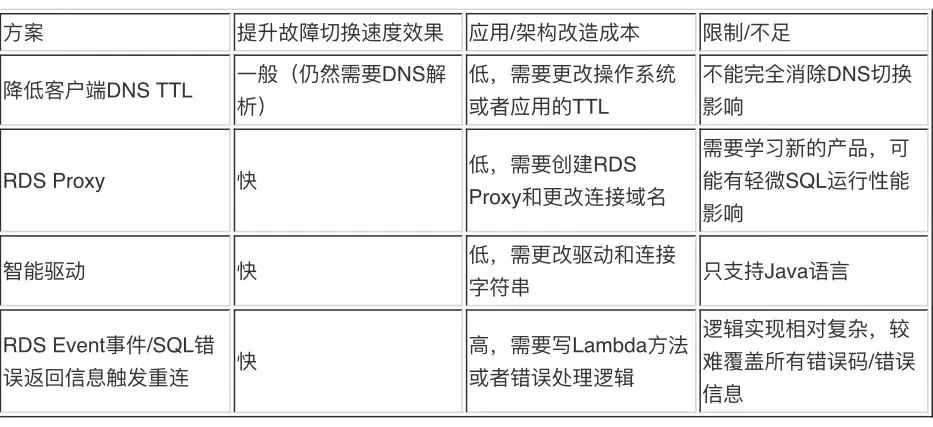
下面这张表里总结了几种不同的方案和各自的优缺点,供您在降低 Aurora 故障切换 DNS 切换时间的影响时进行参考。总体而言,如果应用程序是 Java 语言写的,推荐您使用智能驱动;如果是非 Java 语言,推荐您使用 RDS Proxy;如果对性能要求很高,可以在短期内考虑事件触发重联,长期考虑参照亚马逊的智能驱动逻辑自己实现一个依赖于 Aurora 系统表元信息变更而不是域名切换的智能驱动。
5. 结语
Amazon Aurora 独特的计算存储分离的架构、日志即数据库的设计以及其他的一些优化,能够使它在发生主节点故障时进行快速的故障恢复,然而切换后的节点是否能够快速地被应用程序检测到是受 DNS 域名解析的限制的。
本文分析了 Aurora 故障切换时发生的 event 事件,提出了排查的思路,并提出了几种不同的方案来减轻 DNS 解析的影响,比如减少客户端 DNS 缓存 TTL,增加 RDS Proxy 层避免 DNS 的影响,使用智能驱动来绕过 DNS 解析的时间延迟,或者是通过事件通知机制、错误码分析等。您可以在实际应用中,针对不同的需求选择合适的方案来更近一步地利用到 Aurora 的快速故障切换,提升数据库的可用性,降低对应用程序的影响。
本篇作者

马丽丽
亚马逊云科技数据库解决方案架构师,十余年数据库行业经验,先后涉猎 NoSQL 数据库 Hadoop/Hive、企业级数据库DB2、分布式数仓Greenplum/Apache HAWQ 以及亚马逊云原生数据库的开发和研究。

点击上方【立即报名】
直通大咖云集的亚马逊云科技中国峰会!

听说,点完下面4个按钮
就不会碰到bug了!