
热门标签
热门文章
- 1【ChatGPT】 Microsoft Edge 浏览器扩展使用 GPT_edge插件使用gpt
- 2本地运行Llama3极简中文傻瓜手把手教程,超越GPT4?能力如何?|文末赠2024AI工程师完整视频教程+源码资料_ollama3
- 3[AcWing]802. 区间和(C++实现)区间和模板题_c++区间怎么表示
- 4linux内核解析设备树节点_xilinx ethernet device tree
- 5基于Flask的上市公司数据分析与可视化系统设计与实现开题报告_完成本课题所需工作条件(如工具书、计算机、实验、调研等)及解决办法
- 6怎么在网上赚钱?7种方法总有一种适合你!
- 7机器学习 Christopher Bishop PRML_bishop 机器学习
- 8【Java】时间格式化注解_java 时间字段格式化注解
- 9python爬取人脸识别图片数据集_python 怎么把捕捉到的人脸数据放到数据库中
- 10Flink基础系列-DataSet广播变量_flink中广播流 建议缓存多少数据呀
当前位置: article > 正文
Transformer 预测过程 详解_transformer预测过程
作者:你好赵伟 | 2024-06-01 08:01:20
赞
踩
transformer预测过程
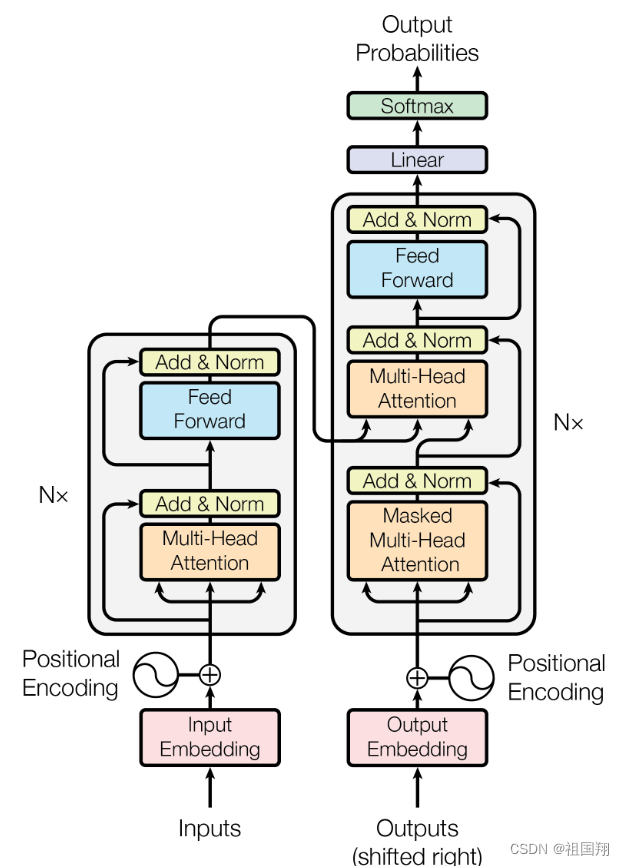
我们看到很多文章讲了transformer架构的概述,包括其中一些主要组件。但大部分文章没有讲整个预测过程是如何一步步进行的。让我们通过一个简单的例子来详细了解一下。在这个例子中,你将会看到一个翻译任务或者序列到序列任务,这恰好是transformer架构设计者最初的目标。
你将使用一个transformer模型将法语短语翻译成英语。首先,你将使用与训练网络相同的分词器对输入单词进行标记。这些标记然后被添加到网络的编码器端的输入中,通过嵌入层(嵌入层通常用于将词语或字符转换为密集的向量表示,这些向量在连续空间中捕捉了词语之间的语义和语法关系),然后传递到多头注意力层。多头注意力层的输出通过前馈网络传递到编码器的输出。这时,离开编码器的数据是输入序列结构和含义的深度表示。这个表示被插入到解码器的中间,影响解码器的自注意机制。接下来,在解码器的输入中添加了一个序列开始标记。这会触发解码器预测下一个标记,它会基于来自编码器的上下文理解来进行预测。解码器的自注意力层的输出通过解码器前馈网络和最终的softmax输出层。这时,我们得到了第一个标记。你将继续这个循环,将输出标记传递回解码器的输入,触发生成下一个标记,直到模型预测出一个序列结束标记。这时,最终的输出序列可以被还原成单词,你就得到了输出。
让我们总结一下上面的内容。完整的transformer架构包括编码器和解码器组件。编码器将输入序列编码为输入结构和含义的深度表示。解码器在接收到输入标记触发后,利用编码器的上下文理解生成新的标记。它会在循环中进行,直到达到某个停止条件。
阅读上面内容,要对照Transformer 模型图,边读边看边理解,因此我们把模型图放一下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/656766
推荐阅读
相关标签

