
- 1数据结构 易错题合集(持续更新)_数据结构易错题
- 2跟着医生学kivy:kivy-garden 究竟怎样安装?_kivy garden安装
- 3在 QML 中,ComboBox 是一种常用的用户界面控件,通常用于提供一个下拉式的选择框,允许用户从预定义的选项列表中选择一个值_qml 下拉框
- 4当35岁中年危机码农遇上GPT.....
- 5基于大语言模型的智能问答系统设计与实践_基于大模型的智能问答技术
- 6c++有趣的代码_C++开源项目:十行代码15个BUG,你入坑了吗?
- 7基于SpringBoot面向智慧教育的实习实践系统
- 8在红帽上搭建dm7的主备的一些问题_dm7主备搭建守护进程报错无法绑定端口
- 9openlayers入门添加百度地图绘制点线面_openlayers 添加百度地图
- 10如何用python进行接口测试(详细教程)_python接口测试
ICLR 2023 | Batch Norm层等暴露TTA短板,开放环境下解决方案来了
赞
踩

©作者 | 机器之心编辑部
来源 | 机器之心
测试时自适应(Test-Time Adaptation, TTA)方法在测试阶段指导模型进行快速无监督 / 自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。然而在动态开放场景中,稳定性不足仍是现有 TTA 方法的一大短板,严重阻碍了其实际部署。为此,来自华南理工大学、腾讯 AI Lab 及新加坡国立大学的研究团队,从统一的角度对现有 TTA 方法在动态场景下不稳定原因进行分析,指出依赖于 Batch 的归一化层是导致不稳定的关键原因之一,另外测试数据流中某些具有噪声 / 大规模梯度的样本容易将模型优化至退化的平凡解。
基于此进一步提出锐度敏感且可靠的测试时熵最小化方法 SAR,实现动态开放场景下稳定、高效的测试时模型在线迁移泛化。本工作已入选 ICLR 2023 Oral (Top-5% among accepted papers)。

论文标题:
Towards Stable Test-time Adaptation in Dynamic Wild World
论文链接:
https://openreview.net/forum?id=g2YraF75Tj
代码链接:
https://github.com/mr-eggplant/SAR

什么是Test-Time Adaptation?
传统机器学习技术通常在预先收集好的大量训练数据上进行学习,之后固定模型进行推理预测。这种范式在测试与训练数据来自相同数据分布时,往往取得十分优异的表现。
但在实际应用中,测试数据的分布很容易偏离原始训练数据的分布(distribution shift),例如在采集测试数据的时候:1)天气的变化使得图像中包含有雨雪、雾的遮挡;2)由于拍摄不当使得图像模糊,或传感器退化导致图像中包含噪声;3)模型基于北方城市采集数据进行训练,却被部署到了南方城市。
以上种种情况十分常见,但对于深度模型而言往往是很致命的,因为在这些场景下其性能可能会大幅下降,严重制约了其在现实世界中(尤其是类似于自动驾驶等高风险应用)的广泛部署。
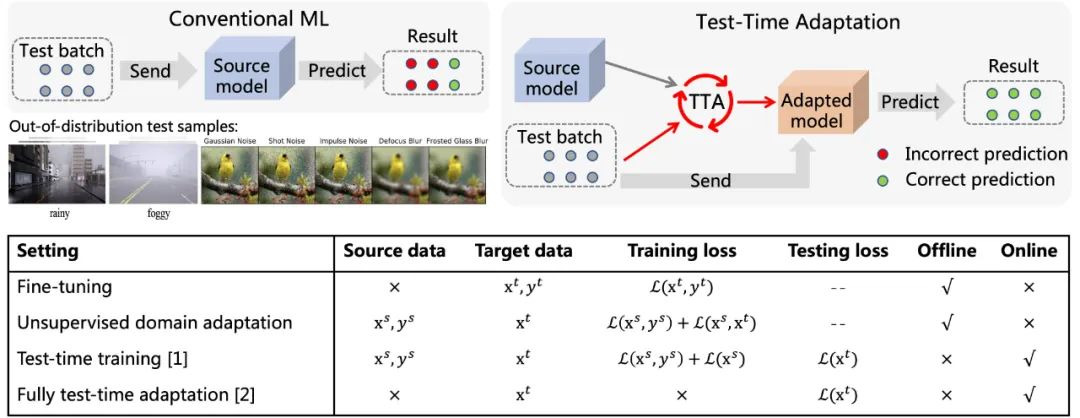
▲ 图1. Test-Time Adaptation 示意图(参考 [5])及其与现有方法特点对比
不同于传统机器学习范式,如图 1 所示在测试样本到来后,Test-Time Adaptation (TTA) 首先基于该数据利用自监督或无监督的方式对模型进行精细化微调,而后再使用更新后的模型做出最终预测。典型的自 / 无监督学习目标包括:旋转预测、对比学习、熵最小化等等。这些方法均展现出了优异的分布外泛化(Out-of-Distribution Generalization)性能。
相较于传统的 Fine-Tuning 以及 Unsupervised Domain Adaptation 方法,Test-Time Adaptation 能够做到在线迁移,效率更高也更加普适。另外完全测试时适应方法 [2] 其可以针对任意预训练模型进行适应,无需原始训练数据也无需干涉模型原始的训练过程。以上优点极大增强了 TTA 方法的现实通用性,再加上其展现出来的优异性能,使得 TTA 成为迁移、泛化等相关领域极为热点的研究方向。

为什么要Wild Test-Time Adaptation?
尽管现有 TTA 方法在分布外泛化方面已表现出了极大的潜力,但这种优异的性能往往是在一些特定的测试条件下所获得的,例如测试数据流在一段时间内的样本均来自于同一种分布偏移类型、测试样本的真实类别分布是均匀且随机的,以及每次需要有一个 mini-batch 的样本后才可以进行适应。
但事实上,以上这些潜在假设在现实开放世界中是很难被一直满足的。在实际中,测试数据流可能以任意的组合方式到来,而理想情况下模型不应对测试数据流的到来形式做出任何假设。
如图 2 所示,测试数据流完全可能遇到:(a)样本来自不同的分布偏移(即混合样本偏移);(b)样本 batch size 非常小(甚至为 1);(c)样本在一段时间内的真实类别分布是不均衡的且会动态变化的。本文将上述场景下的 TTA 统称为 Wild TTA。
但不幸的是,现有 TTA 方法在这些 Wild 场景下经常会表现得十分脆弱、不稳定,迁移性能有限,甚至可能损坏原始模型的性能。因此,若想真正实现 TTA 方法在实际场景中的大范围、深度化应用部署,则解决 Wild TTA 问题即是其中不可避免的重要一环。
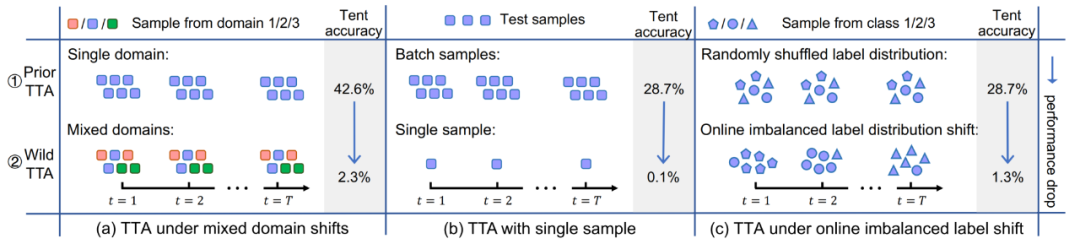
▲ 图2. 模型测试时自适应中的动态开放场景

解决思路与技术方案
本文从统一角度对 TTA 在众多 Wild 场景下失败原因进行分析,进而给出解决方案。
1. 为何 Wild TTA 会不稳定?
(1)Batch Normalization (BN) 是导致动态场景下 TTA 不稳定的关键原因之一:现有 TTA 方法通常是建立在 BN 统计量自适应基础之上的,即使用测试数据来计算 BN 层中的均值及标准差。然而,在 3 种实际动态场景中,BN 层内的统计量估计准确性均会出现偏差,从而引发不稳定的 TTA:
场景(a):由于 BN 的统计量实际上代表了某一种测试数据分布,使用一组统计量参数同时估计多个分布不可避免会获得有限的性能,参见图 3;
场景(b):BN 的统计量依赖于 batch size 大小,在小 batch size 样本上很难得到准确的 BN 的统计量估计,参见图 4;
场景(c):非均衡标签分布的样本会导致 BN 层内统计量存在偏差,即统计量偏向某一特定类别(该 batch 中占比较大的类别),参见图 5;
为进一步验证上述分析,本文考虑 3 种广泛应用的模型(搭载不同的 Batch\Layer\Group Norm),基于两种代表性 TTA 方法(TTT [1] 和 Tent [2])进行分析验证。
最终得出结论为:batch 无关的 Norm 层(Group 和 Layer Norm)一定程度上规避了 Batch Norm 局限性,更适合在动态开放场景中执行 TTA,其稳定性也更高。因此,本文也将基于搭载 Group\Layer Norm 的模型进行方法设计。

▲ 图3. 不同方法和模型(不同归一化层)在混合分布偏移下性能表现

▲ 图4. 不同方法和模型(不同归一化层)在不同 batch size 下性能表现。图中阴影区域表示该模型性能的标准差,ResNet50-BN 和 ResNet50-GN 的标准差过小导致在图中不显著(下图同)

▲ 图5. 不同方法和模型(不同归一化层)在在线不平衡标签分布偏移下性能表现,图中横轴 Imbalance Ratio 越大代表的标签不平衡程度越严重
(2)在线熵最小化易将模型优化至退化的平凡解,即将任意样本预测到同一个类:根据图 6 (a) 和 (b) 显示,在分布偏移程度严重(level 5)时,在线自适应过程中突然出现了模型退化崩溃现象,即所有样本(真实类别不同)被预测到同一类;同时,模型梯度的 范数在模型崩溃前后快速增大而后降至几乎为 0,见图 6(c),侧面说明可能是某些大尺度 / 噪声梯度破坏了模型参数,进而导致模型崩溃。

▲ 图6. 在线测试时熵最小化中的失败案例分析
2. 锐度敏感且可靠的测试时熵最小化方法
为了缓解上述模型退化问题,本文提出了锐度敏感且可靠的测试时熵最小化方法 (Sharpness-aware and Reliable Entropy Minimization Method, SAR)。其从两个方面缓解这一问题:1)可靠熵最小化从模型自适应更新中移除部分产生较大 / 噪声梯度的样本;2)模型锐度优化使得模型对剩余样本中所产生的某些噪声梯度不敏感。具体细节阐述如下:
可靠熵最小化:基于 Entropy 建立梯度选择的替代判断指标,将高熵样本(包含图 6 (d) 中区域 1 和 2 的样本)排除在模型自适应之外不参与模型更新:

其中 x 表示测试样本, 表示模型参数, 表示指示函数, 表示样本预测结果的熵, 为超参数。仅当 时样本才会参与反向传播计算。
锐度敏感的熵优化:通过可靠样本选择机制过滤后的样本中,无法避免仍含有图 6 (d) 区域 4 中的样本,这些样本可能产生噪声 / 较大梯度继续干扰模型。为此,本文考虑将模型优化至一个 flat minimum,使其能够对噪声梯度带来的模型更新不敏感,即不影响其原始模型性能,优化目标为:
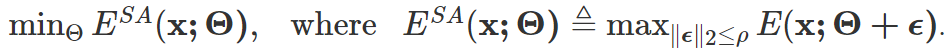
上述目标的最终梯度更新形式如下:
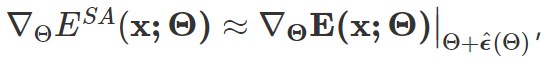
其中 受启发于 SAM [4] 通过一阶泰勒展开近似求解得到,具体细节可参见本论文原文与代码。
至此,本文的总体优化目标为:
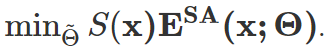
此外,为了防止极端条件下上述方案仍可能失败的情况,进一步引入了一个模型复原策略:通过移动监测模型是否出现退化崩溃,决定在必要时刻对模型更新参数进行原始值恢复。

实验评估
在动态开放场景下的性能对比
SAR 基于上述三种动态开放场景,即 a)混合分布偏移、b)单样本适应和 c)在线不平衡类别分布偏移,在 ImageNet-C 数据集上进行实验验证,结果如表 1, 2, 3 所示。SAR 在三种场景中均取得显著效果,特别是在场景 b)和 c)中,SAR 以 VitBase 作为基础模型,准确率超过当前 SOTA 方法 EATA 接近 10%。
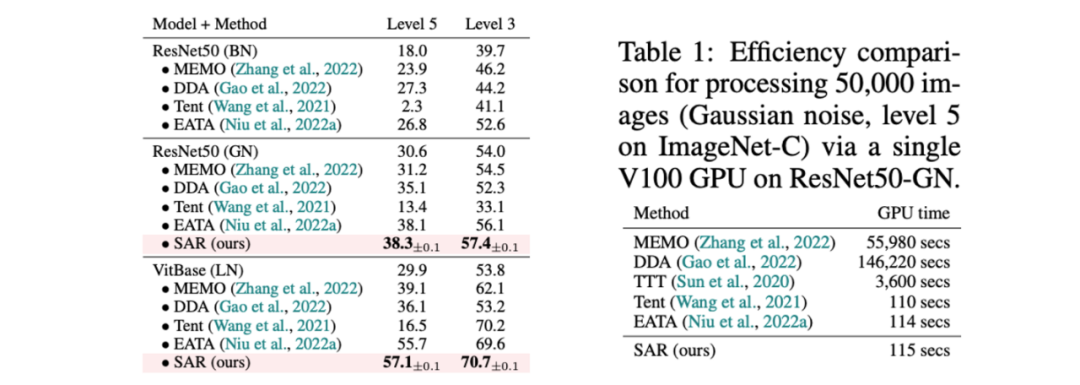
▲ 表1. SAR 与现有方法在 ImageNet-C 的 15 种损坏类型混合场景下性能对比,对应动态场景 (a);以及和现有方法的效率对比
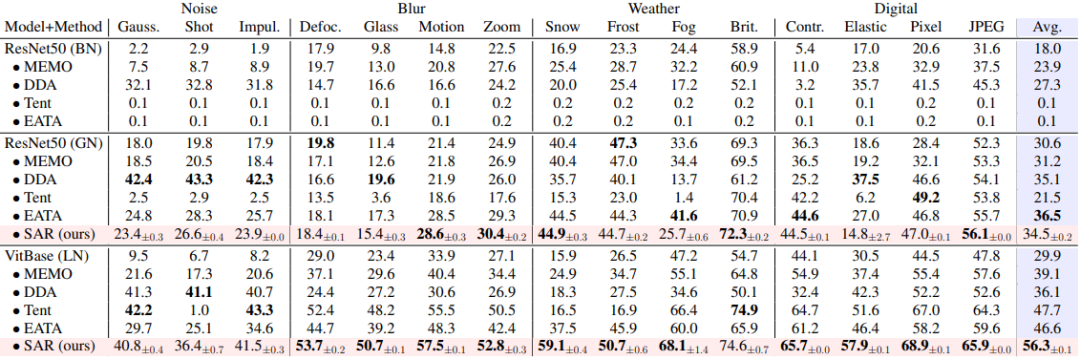
▲ 表2. SAR 与现有方法在 ImageNet-C 上单样本适应场景中的性能对比,对应动态场景 (b)
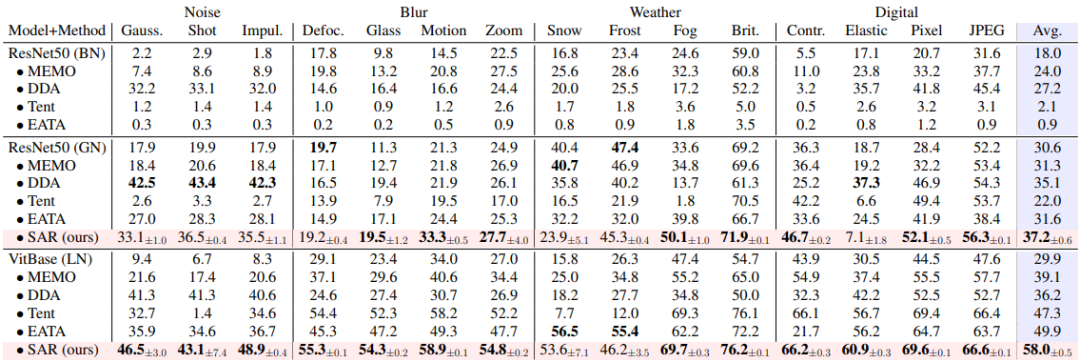
▲ 表3. SAR 与现有方法在 ImageNet-C 上在线非均衡类别分布偏移场景中性能对比,对应动态场景(c)
消融实验
与梯度裁剪方法的对比:梯度裁剪避免大梯度影响模型更新(甚至导致坍塌)的一种简单且直接的方法。此处与梯度裁剪的两个变种(即:by value or by norm)进行对比。如下图所示,梯度裁剪对于梯度裁剪阈值 δ 的选取很敏感,较小的 δ 与模型不更新的结果相当,较大的 δ 又难以避免模型坍塌。相反,SAR 不需要繁杂的超参数筛选过程且性能显著优于梯度裁剪。
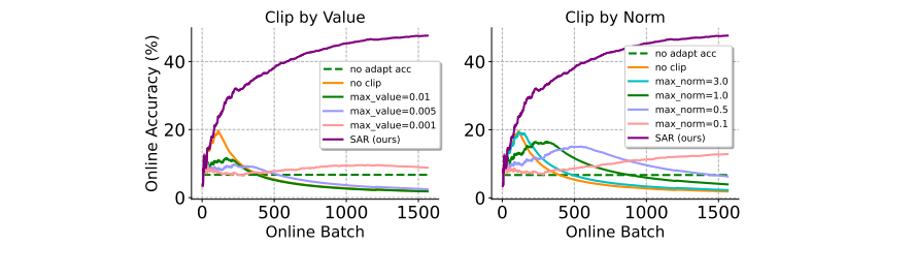
▲ 图7. 与梯度裁剪方法的在 ImageNet-C(shot nosise, level 5) 上在线不平衡标签分布偏移场景中的性能对比。其中准确率是基于所有之前的测试样本在线计算得出
不同模块对算法性能的影响:如下表所示,SAR 的不同模块协同作用,有效提升了动态开放场景下测试时模型自适应稳定性。

▲ 表4. SAR 在 ImageNet-C (level 5) 上在线不平衡标签分布偏移场景下的消融实验
Loss 表面的锐度可视化:通过在模型权重增加扰动对损失函数可视化的结果如下图所示。其中,SAR 相较于 Tent 在最低损失等高线内的区域(深蓝色区域)更大,表明 SAR 获得的解更加平坦,对于噪声 / 较大梯度更加鲁棒,抗干扰能力更强。
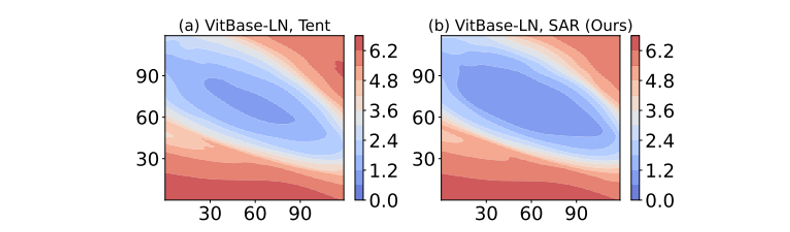
▲ 图8. 熵损失表面可视化

结语
本文致力于解决在动态开放场景中模型在线测试时自适应不稳定的难题。为此,本文首先从统一的角度对已有方法在实际动态场景失效的原因进行分析,并设计完备的实验对其进行深度验证。基于这些分析,本文最终提出锐度敏感且可靠的测试时熵最小化方法,通过抑制某些具有较大梯度 / 噪声测试样本对模型更新的影响,实现了稳定、高效的模型在线测试时自适应。

参考文献
[1] Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. In International Conference on Machine Learning, pp. 9229–9248, 2020.
[2] Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. In International Conference on Learning Representations, 2021.
[3] Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. In International Conference on Machine Learning, pp. 16888–16905, 2022.
[4] Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization. In International Conference on Learning Representations, 2021.
[5] Tong Wu, Feiran Jia, Xiangyu Qi, Jiachen T. Wang, Vikash Sehwag, Saeed Mahloujifar, and Prateek Mittal. Uncovering adversarial risks of test-time adaptation. arXiv preprint arXiv:2301.12576, 2023.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

