
- 1关于ssh的使用及github上传_github ssh
- 2【人工智能】大脑传:人类对大脑的认识与历史_大脑这个词是什么时候发明的
- 3【Node-RED】安全登陆时,账号密码设置_nodered设置密码
- 4Hbase概念、分布式集群部署和使用_hbase检查hregionserver数据库存储目录与hadoop的core-site.xml一致
- 5Git 随笔
- 6python实现图片自动轮番播放_python cv图片动态轮播
- 7一篇文章教会你如何安装zookeeper和hbase(超详细版)_hbase安装与配置文件
- 8Prometheus.yml配置文件示例_kube-prometheus 中prometheus.yml文件找不到
- 9Checkpoint Tuning and Troubleshooting Guide(Metalink:147468.1)
- 10大厂的面试程序员流程和技巧,我来聊聊三轮面试都要注意什么_程序员三面面试分别是什么
使用python实现语音识别_python语音识别
赞
踩
语音识别技术,也被称为自动语音识别,目标是以电脑自动将以人类的语音内容转换为相应的文字和文字转换为语音。
一. 文本转换为语音
1.1 使用pyttsx
使用名为pyttsx的python包,可以将文本转换为语音。
安装pyttsx包
pip install pyttsx3
- 1
示例
import pyttsx3 as pyttsx
engine \= pyttsx.init()
engine.say("Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。")
engine.runAndWait()
- 1
- 2
- 3
- 4
运行之后可以播放语音。
1.2 使用SAPI
在python 中,也可以使用SAPI 来将文本转换为语音。
使用Win32com.client包,不需要另外安装。
示例
from win32com.client import Dispatch
msg \="Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。"
speaker \= Dispatch("SAPI.SpVoice")
speaker.Speak(msg)
del speaker
- 1
- 2
- 3
- 4
- 5
使用SpeechLib可以将文本转换为语音文件
使用SpeechLib,可以从文本文件中获取输入,再将其转换为语音文件。先使用pip安装,命令如下:
pip install comtypes
- 1
示例
from comtypes.client import CreateObject
from comtypes.gen import SpeechLib
infile \= 'C:\\\\Users\\\\10619\\\\Desktop\\\\fileText.txt'
f \= open(infile, 'r')
theText \= f.read()
f.close()
outfile \= 'demo\_audio.wav'
engine \= CreateObject("SAPI.SpVoice")
stream \= CreateObject("SAPI.SpFileStream")
stream.Open(outfile,SpeechLib.SSFMCreateForWrite)
engine.AudioOutputStream \= stream
engine.speak(theText)
stream.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行之后,会输出demo_audio.wav语音文件,打开demo_audio.wav文件并播放。
二. 语音转换为文本
使用PocketSphinx包, PocketSphinx是一个用于语音转换文本的开源API。它是一个轻量级的语音识别引擎,尽管在桌面端也能很好的工作,它还专门为手机和移动设备做过调优。首先使用pip命令安装所需模块,命令如下:
pip install PocketSphinx
pip install SpeechRecognition
- 1
- 2
在安装PocketSphinx 可能会报错(ERROR: Could not build wheels for pocketsphinx, which is required to install pyproject.toml-based projects)。解决方法:通过查看pip可安装文件,查看可安装的文件命令:pip debug --verbose,然后查看Compatible tags: 33下可以安装的版本。

然后到https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx,下载对应版本的whl文件包安装。

然后再安装PocketSphinx和SpeechRecognition包。

脚本示例
import speech\_recognition as sr
r \= sr.Recognizer()
audio\_file \= 'demo\_audio.wav'
with sr.AudioFile(audio\_file) as source:
audio \= r.record(source)
try:
print("文本内容:",r.recognize\_sphinx(audio,language\='zh-CN'))
#默认会识别为英文,如果要识别中文,需要下载普通话识别文件
except Exception as e:
print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
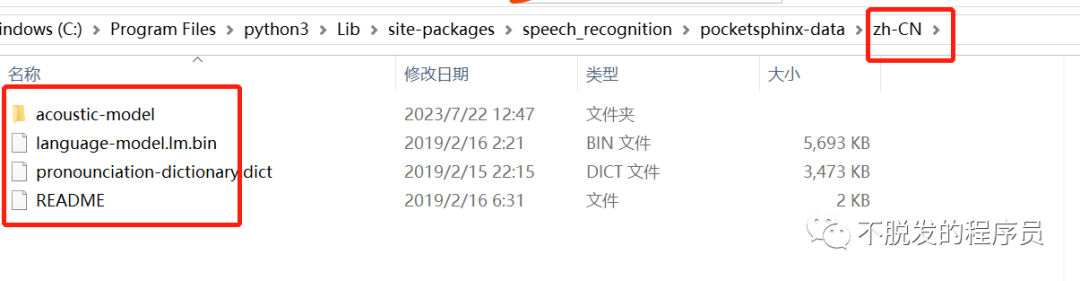
下载普通话识别文件。
下载路径:https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/

解压之后,修改文件名称,cmusphinx-zh-cn-5.2 改为 zh-CN, zh_cn.cd_cont_5000文件夹改为acoustic-model,zh_cn.dic改为pronounciation-dictionary.dict,zh_cn.lm.bin改为language-model.lm.bin。然后移动zn-CN文件夹到python3\Lib\site-packages\speech_recognition\pocketsphinx-data下。

运行python之后,可以查看输出的文本内容。
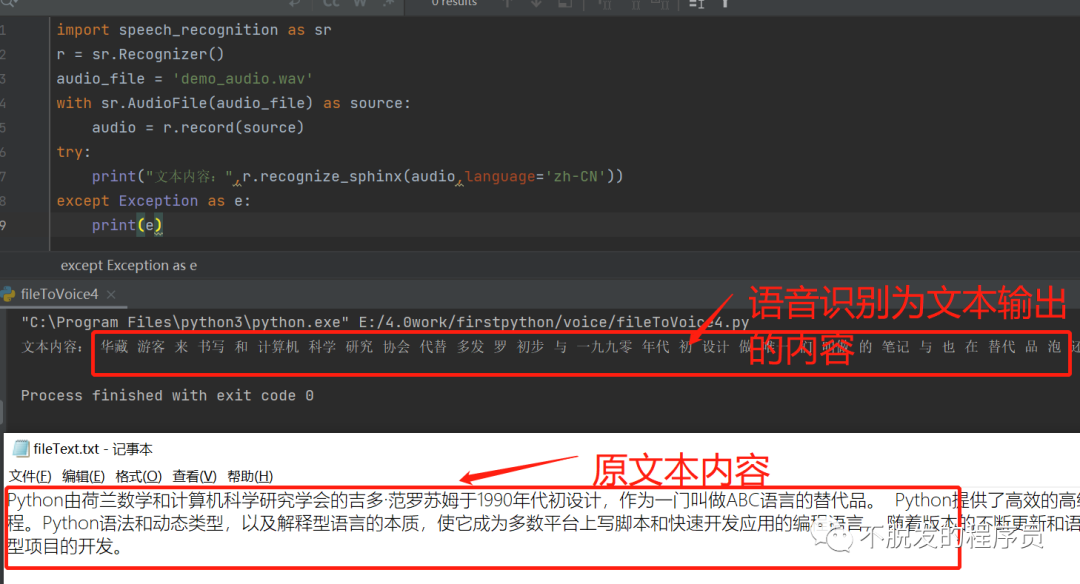
通过输出的语音转换之后的文本和原文本比较发现,语音识别的后文本还是有一定差异的。
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上脚本呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除


