
- 1VueRouter4 - 动态路由刷新变空白或404_vue动态路由刷新404
- 2PHP文件包含漏洞(利用phpinfo)复现&&文件上传(条件竞争)_phpinfophp漏洞利用
- 3python椭圆曲线加密算法_ECC椭圆曲线加密学习笔记
- 4建设现代智能工业-智能化、数字化、自动化节能减排
- 5机器学习——numpy_numpycsdn
- 6ChatGPT 有什么新奇的使用方式?_chatgpt网页转api
- 7Yaml语法详细介绍_yaml ${}
- 8【mplug_owl2.1&mplug_owl_2_1推理】多模态大模型,图生文代码示例
- 9VScode 看这一篇就够了_vscode是什么
- 10【esp8266】史上最详细的Arduino uno R3接入机智云教程_ardunion nao r3 主板连接
ICCV 2023 | 最全AIGC梳理,5w字30个diffusion扩散模型方向,近百篇论文!
赞
踩
在最新的视觉顶会 ICCV 2023 会议中,涌现出大量基于生成式AIGC的CV论文,尤其是扩散模型diffusion为代表!除直接生成,还广泛应用在其它各类 low-level、high-level 视觉任务!
本文集齐和梳理ICCV 2023里共30+方向、近百篇的AIGC论文!下述论文均已分类打包好!
关注公众号【机器学习与AI生成创作】公众号,在后台回复 AIGC扩散 (长按红字、选中复制)即可获取分类、按文件夹汇总好的论文集,gan起来吧!!!
文章很长,梳理不易,越到后面的方向越有趣!麻烦各位看官,转发、分享、在看三连,多多鼓励小编!!!
目录
1、风格迁移
2、视频生成/转换
3、扩散模型改进
4、自监督学习
5、表征学习
6、布局生成
7、可控生成
8、动作检测
9、目标检测
10、异常检测
11、deepfake检测
12、年龄迁移
13、虚拟试衣
14、图像分割
15、图像分类
16、图像编辑
17、人像生成
18、人脸识别
19、少样本生成
20、视频检索
21、说话人生成
22、纹理合成
23、医学图像
24、鱼眼图像校正
25、语音相关
26、对抗相关
27、图像超分
28、图像恢复
29、图像去模糊
30、阴影去除
31、图像延展/外推/外扩
32、图像组合
33、视图生成
一、风格迁移
1、StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models
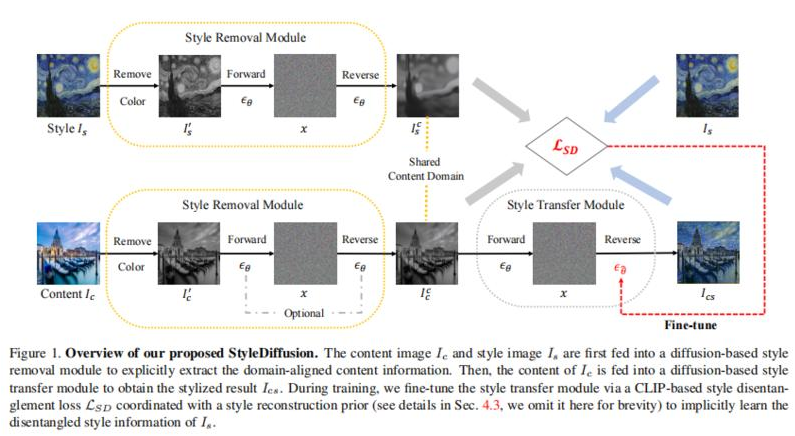
内容和风格(Content and style disentanglement,C-S)解耦是风格迁移的一个基本问题和关键挑战。基于显式定义(例如Gram矩阵)或隐式学习(例如GANs)的现有方法既不易解释也不易控制,导致表示交织在一起并且结果不尽如人意。
本文提出一种新的C-S解耦框架,不使用先前假设。关键是明确提取内容信息和隐式学习互补的风格信息,从而实现可解释和可控的C-S解耦和风格迁移。提出一种简单而有效的基于CLIP的风格解耦损失,其与风格重建先验一起协调解耦C-S在CLIP图像空间中。通过进一步利用扩散模型强大的风格去除和生成能力,实现了优于现有技术的结果,并实现了灵活的C-S解耦和权衡控制。
工作为风格迁移中的C-S解耦提供了新的见解,并展示了扩散模型在学习良好解耦的C-S特征方面的潜力。
2、Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer

扩散模型在文本引导的图像风格迁移中显示出巨大潜力,但由于其随机的性质,风格转换和内容保留之间存在权衡。现有方法需要通过耗时的扩散模型微调或额外的神经网络来解决这个问题。
为解决这个问题,提出一种零样本对比损失的扩散模型方法,该方法不需要额外的微调或辅助网络。通过利用预训练扩散模型中生成样本与原始图像嵌入之间的分块对比损失,方法可以以零样本的方式生成具有与源图像相同语义内容的图像。
方法不仅在图像风格迁移方面优于现有方法,而且在图像到图像的转换和操作方面也能保持内容并且不需要额外的训练。实验结果验证了方法有效性。https://github.com/YSerin/ZeCon
3、Diffusion in Style

提出"Diffusion in Style",可以将Stable Diffusion调整到任何所需的风格,只需一小组目标图像。
基于这样一个关键观察:由Stable Diffusion生成的图像的风格与初始潜在张量相关联。如果不将这个初始潜在张量调整到风格,则微调会变得缓慢、昂贵且不切实际,特别是当只有少数目标样式图像可用时。相反,如果调整这个初始潜在张量,则微调会变得更加容易。
Diffusion in Style在样本效率和速度上具有数个数量级的提升。与现有方法相比,它还可以生成更加令人满意的图像,这一点在定性和定量比较中得到了证实。https://ivrl.github.io/diffusion-in-style/
4、PODIA-3D: Domain Adaptation of 3D Generative Model Across Large Domain Gap Using Pose-Preserved Text-to-Image Diffusion

最近,在3D生成模型方面取得重大进展,然而在多领域训练这些模型是一项具有挑战的工作,需要大量的训练数据和对姿势分布的了解。
文本引导的域自适应方法通过使用文本提示将生成器适应于目标域,避免收集大量数据。最近,DATID-3D在文本引导域中生成令人印象深刻的视图一致图像,利用文本到图像扩散模型保持文本的多样性。然而,将3D生成器调整到与源域存在显著领域差异的领域,仍具挑战,包括:1)转换中的形状和姿势权衡,2)姿势偏差,以及3)目标域中的实例偏差,导致生成的样本中3D形状差、文本图像对应性差和域内多样性低。
为解决这些问题,提出PODIA-3D流程,用保留姿势的文本到图像扩散式域适应的方法来进行3D生成模型训练。构建一个保留姿势的文本到图像扩散模型,在进行领域变化时使用极高级别的噪声。提出专用于一般的采样策略,以改善生成样本的细节。此外,为克服实例偏差,引入一种文本引导的去偏方法,以提高域内多样性。因此,方法生成出色的文本图像对应性和3D形状,而基线模型大多失败。定性结果和用户研究表明,方法在文本图像对应性、逼真程度、生成样本的多样性和3D形状的深度感方面优于现有的3D文本引导域自适应方法。https://gwang-kim.github.io/podia_3d/
5、DS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion

介绍一种新方法,通过将一个或多个字体的字母进行风格化,视觉上传达输入单词语义,并确保输出保持可读性,自动生成艺术字体。
为应对一系列挑战,包括冲突的目标(艺术化风格化 vs. 可读性)、缺乏事实根据和庞大的搜索空间,方法利用大型语言模型将文本和视觉图像进行风格化,并基于扩散模型骨干构建一个无监督的生成模型。具体而言,采用潜在扩散模型(LDM)中的去噪生成器,并加入一个基于CNN的判别器,将输入风格调整到输入文本上。判别器使用给定字体的光栅化图像作为真实样本,将去噪生成器的输出作为伪样本。模型被称为DS-Fusion,表示具有有区分度和风格化的扩散。
大量示例、定性定量评估及消融研究展示方法质量和多样性。与CLIPDraw、DALL-E 2、Stable Diffusion以及由艺术家精心制作的字体进行的用户研究显示DS-Fusion的强大性能。https://ds-fusion.github.io/
二、视频生成/转换
6、Pix2Video: Video Editing using Image Diffusion
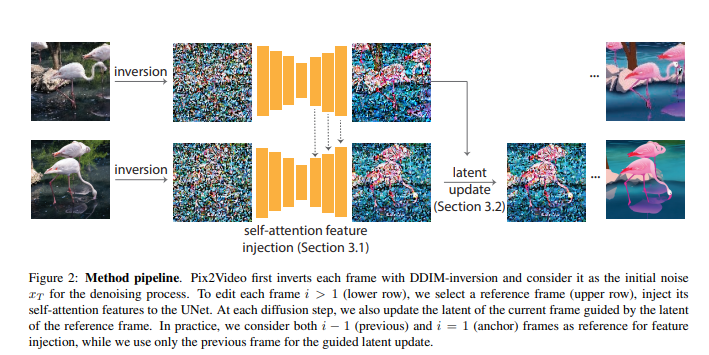
基于大规模图像库训练的图像扩散模型已成为质量和多样性方面最为通用的图像生成模型。它们支持反转真实图像和条件生成(例如,文本生成),使其在高质量图像编辑应用中具有吸引力。本文研究如何利用这些预训练的图像模型进行文本引导的视频编辑。
关键挑战在于在保留源视频内容的同时实现目标编辑。方法分为两个简单的步骤:首先,用预训练的结构引导(例如,深度)图像扩散模型对锚点帧进行文本引导编辑;然后,在关键步骤中,通过将变化逐步传播到未来帧来适应扩散模型的核心去噪步骤,使用自注意力特征注入。然后,在继续处理之前,通过调整帧的潜在编码来巩固这些变化。
方法无需训练,可以推广到各种编辑。通过广泛的实验证明了该方法的有效性,并将其与四种不同的先前和并行努力(在ArXiv上)进行比较。证明实现逼真的文本引导视频编辑是可行的,无需进行任何计算密集的预处理或特定于视频的微调。开源在:https://duyguceylan.github.io/pix2video.github.io/
7、StableVideo: Text-driven Consistency-aware Diffusion Video Editing

扩散方法可生成逼真的图像和视频,但在保持现有对象外观的同时编辑视频中的对象时遇到困难。这阻碍了将扩散模型应用于实际场景中的自然视频编辑。本文通过为现有的文本驱动扩散模型引入时序依赖性来解决这个问题,这使它们能够为编辑后的对象生成一致的外观。
具体来说,开发一种新的帧间传播机制,用于视频编辑,利用分层表示的概念将外观信息从一个帧传播到下一个帧。然后,基于此机制构建了一个基于文本驱动的视频编辑框架,即StableVideo,它可以实现具有一致性意识的视频编辑。大量实验证明方法的强大编辑能力。与最先进的视频编辑方法相比,展示了更好的定性和定量结果。开源在:https://github.com/rese1f/StableVideo
8、Structure and Content-Guided Video Synthesis with Diffusion Models

文本引导的生成扩散模型,为图像的创作和编辑提供了强大的工具。最近一些方法可编辑镜头内容并保留结构,但每次输入都需要昂贵的重新训练,或者依赖于易出错的图像编辑在帧之间的传播。
这项工作提出一种基于结构和内容引导的视频扩散模型,根据所期望输出的描述来编辑视频。由于结构与内容之间的解耦不足,用户提供的内容编辑与结构表示之间会发生冲突。作为解决方案,展示了使用具有不同详细级别的单眼深度估计进行训练可以提供对结构和内容准确性的控制。通过联合视频和图像训练而启用的一种新颖的引导方法,可以对时间一致性进行明确控制。
实验展示了各种成功案例;对输出特征的细粒度控制,基于少量参考图像的定制,以及用户对模型结果的强烈偏好。https://research.runwayml.com/gen1
9、The Power of Sound (TPoS):Audio Reactive Video Generation with Stable Diffusion

视频生成已成为一种重要生成工具,受到极大关注。然而,对于音频到视频生成,很少有考虑,尽管音频具有时间语义和幅度等独特性质。
提出The Power of Sound(TPoS)模型,将包含可变时间语义和幅度的音频输入纳入其中。为生成视频帧,TPoS利用了具有文本语义信息的潜在稳定扩散模型,然后通过预训练的音频编码器产生的顺序音频嵌入进行引导。结果,该方法生成与音频相关的视频内容。
通过各种任务展示了TPoS的有效性,并将其结果与当前音频到视频生成领域的最先进技术进行了比较。开源在:https://ku-vai.github.io/TPoS/
10、Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models
 提出PYoCo,一种大规模文本到视频扩散模型,该模型是从现有的图像生成模型eDiff-I进行微调的,并引入了一种新的视频噪声先验。结合之前的设计选择,包括使用时间注意力、联合图像-视频微调、级联生成架构和专家去噪器的集成,PYoCo在几个基准数据集上建立了新的最先进,优于其他竞争方法的视频生成水平。
提出PYoCo,一种大规模文本到视频扩散模型,该模型是从现有的图像生成模型eDiff-I进行微调的,并引入了一种新的视频噪声先验。结合之前的设计选择,包括使用时间注意力、联合图像-视频微调、级联生成架构和专家去噪器的集成,PYoCo在几个基准数据集上建立了新的最先进,优于其他竞争方法的视频生成水平。
PYoCo能够以卓越的照片真实感和时间一致性实现高质量的零样视频综合能力。项目在:https://research.nvidia.com/labs/dir/pyoco/
11、Text2Video-Zero:Text-to-Image Diffusion Models are Zero-Shot Video Generators

文本到视频生成方法依赖于计算密集型训练,并需要大规模的视频数据集。本文介绍一个新的任务,零样本文本到视频生成,并提出一种低成本的方法(无需任何训练或优化),通过利用现有的文本到图像合成方法,使其适用于视频领域。
关键修改包括:(i)通过动态运动丰富生成帧的潜在编码,以保持全局场景和背景时间的一致性;(ii)重新编程帧级自注意力,使用每一帧对第一帧的新的跨帧注意力,以保留前景对象的上下文、外观和身份。达到了低开销但高质量和非常一致的视频生成。
此外,方法不仅限于文本到视频合成,还适用于其他任务,例如条件和内容专项的视频生成,以及视频指导像素到像素,即指令引导的视频编辑。实验证明,尽管没有在额外的视频数据上训练,方法与最近方法相比具有可比或更好的性能。开源在:https://github.com/Picsart-AI-Research/Text2Video-Zero
12、Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation

为复制文本到图像生成的成功,最近工作采用大规模视频数据集来训练文本到视频生成器。尽管这些方法有着很好的结果,但这种方法计算上是昂贵的。
这项工作提出一种新的文本到视频生成设置——One-Shot Video Tuning,在这种设置下只呈现一个文本到视频对。模型是基于最先进的文本到图像扩散模型,在大规模图像数据上进行预训练的。做出了两个关键观察:1)文本到图像模型可以生成表示动词概念的静态图像;2)扩展文本到图像模型以同时生成多个图像表现出惊人的内容一致性。
为进一步学习连续的运动,引入了调整视频的Tune-A-Video方法,包括一个定制的时空注意机制和一个高效的One-Shot Video Tuning。在推理过程中,用DDIM逆变换来提供采样的结构指导。广泛的定性和定量实验证明了方法在各种应用中的显著能力。开源在:https://tuneavideo.github.io/
三、扩散模型改进
13、Discriminative Class Tokens for Text-to-Image Diffusion Models

文本到图像扩散模型,使得生成多样且高质量的图像成为可能。然而,这些图像往往在描绘细节方面不够精细,并且容易出现由于输入文本的歧义导致的错误。缓解这些问题的一种方法是在带类标签的数据集上训练扩散模型。这种方法有两个缺点:(i)监督数据集通常与大规模抓取的文本-图像数据集相比较小,影响生成图像的质量和多样性,或者(ii)输入是一个硬编码标签,而不是自由形式的文本,限制了对生成图像的控制。
这项工作提出一种非侵入式的微调技术,充分发挥自由形式文本的表达能力,同时通过来自预训练分类器的判别信号实现高准确性。这是通过迭代修改文本到图像扩散模型的一个额外输入token的嵌入向量来完成的,将生成的图像朝着给定的目标类别进行导引。
与先前的微调方法相比,方法速度较快,且不需一组类内图像或重新训练抗噪声分类器。实证结果表明生成的图像比标准扩散模型的图像更准确且质量更高,可以在资源有限的情况下用于增强训练数据,并揭示了用于训练指导分类器的数据的信息。已开源在:https://github.com/idansc/discriminative_class_tokens
14、Score-Based Diffusion Models as Principled Priors for Inverse Imaging

先验Priors在从噪声和/或不完整测量中重建图像中起着至关重要的作用。先验的选择决定了恢复图像的质量和不确定性。提出将基于分数的扩散模型转化为有原则的图像先验(“基于分数的先验”),用于分析给定测量的图像后验。
以前,概率先验局限于手工制作的正则化器和简单的概率分布。这项工作中,经验证明了基于分数的扩散模型的理论上证明的概率函数。展示了如何使用这个概率函数进行变分推断从而从得到的后验中进行采样。包括去噪、去模糊和干涉成像的实验,表明基于分数的先验能够通过一个复杂的基于数据的图像先验进行有原则的推断。开源在:https://github.com/berthyf96/score_prior
15、Masked Diffusion Transformer is a Strong Image Synthesizer
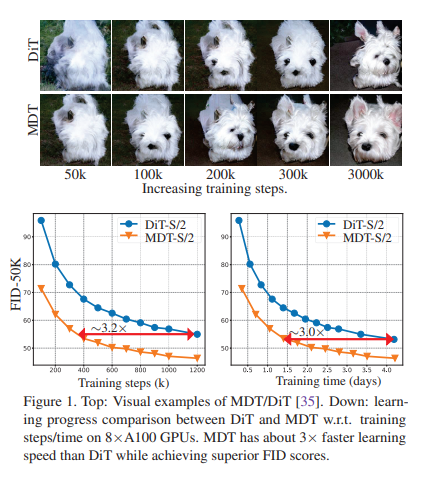
尽管在图像生成方面取得成功,但观察到扩散概率模型(DPM)在学习图像中对象部分之间的关系时常常缺乏上下文推理能力,导致学习过程较慢。为解决这个问题,提出一个称为Masked Diffusion Transformer(MDT)的方法,通过引入蒙版潜在建模方案,明确增强DPM在图像中对象语义部分之间的上下文关系学习能力。
在训练过程中,MDT在潜在空间中操作以遮盖某些tokens。然后,设计了一个非对称的Masked Diffusion Transformer,用于根据未遮盖的tokens预测遮盖的tokens,同时保持扩散生成过程。MDT可以从不完整的上下文输入中重构图像的全部信息,从而使其能够学习图像token之间的关联关系。
实验结果表明,MDT在图像合成性能方面表现出优越性能,例如在ImageNet数据集上的新的SOTA FID分数,并且比之前的SOTA DiT具有约3倍的学习速度。开源在:https://github.com/sail-sg/MDT
16、SVDiff: Compact Parameter Space for Diffusion Fine-Tuning

扩散模型在文本到图像生成方面取得了显著的成功,能够通过文本提示或其他模态创建高质量的图像。然而,现有的定制这些模型的方法在处理多个个性化主体和过拟合的风险方面存在局限。此外,它们的大量参数对于模型的存储来说是低效的。
本文提出一种解决现有文本到图像扩散模型个性化问题的新方法。方法涉及微调权重矩阵的奇异值,以得到一个紧凑而高效的参数空间,从而减少过度拟合和语言漂移的风险。还提出一种Cut-Mix-Unmix数据增强技术,以增强多主体图像生成的质量,并提出了一个简单的基于文本的图像编辑框架。
SVDiff方法与现有方法相比具有显著较小的模型大小(与vanilla DreamBooth相比,参数减少了约2,200倍),使其更适合实际应用。
17、Efficient Diffusion Training via Min-SNR Weighting Strategy

去噪扩散模型是图像生成的主流方法,然而,训练这些模型往往收敛速度较慢。本文发现这种收敛速度慢的原因部分是由于时间步之间存在冲突的优化方向。为解决这个问题,将扩散训练视为一种多任务学习问题,并引入了一种简单而有效的方法,称为Min-SNR-γ。这种方法基于固定的信噪比调整时间步的损失权重,有效地平衡了时间步之间的冲突。
结果表明,在收敛速度方面有显著的改进,比之前的加权策略快3.4倍。它也更有效,使用比之前最先进方法更小的架构,在ImageNet 256×256基准测试中实现了2.06的新FID分数。开源在:https://github.com/TiankaiHang/Min-SNR-Diffusion-Training
18、Improving Sample Quality of Diffusion Models Using Self-Attention Guidance

去噪扩散模型(DDMs)因其出色的生成质量和多样性而备受关注。这一成功主要归功于使用类别或文本条件的扩散引导方法,例如分类器和无分类器引导。本文提出一个更全面的视角,超越传统的引导方法。
引入了新的无条件和无训练策略,以增强生成图像的质量。作为一种简单的解决方案,模糊引导提高了中间样本针对其细节和结构的信息的适应性,使扩散模型能够生成更高质量的样本。在此基础上,使用自注意力引导(SAG)使用扩散模型的中间自注意力图来增强其稳定性和效果。具体来说,SAG仅对扩散模型在每次迭代中关注的区域进行对抗性模糊,并相应地引导它们。
实验结果表明,SAG改善各种扩散模型性能,包括ADM、IDDPM、Stable Diffusion和DiT。此外,将SAG与传统引导方法相结合可以进一步提高性能。开源在:https://github.com/KU-CVLAB/Self-Attention-Guidance/
19、DiffDis: Empowering Generative Diffusion Model with Cross-Modal Discrimination Capability
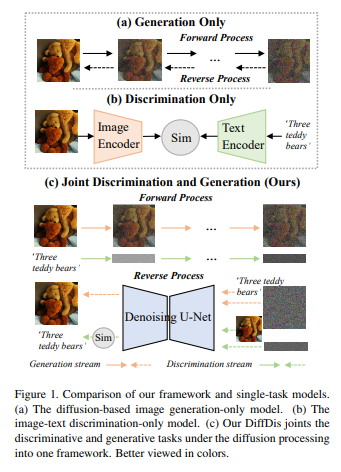
近来,大规模扩散模型在图像生成方面取得了显著结果。另一方面,大规模交叉模态预训练模型(例如CLIP、ALIGN和FILIP)通过学习将视觉和语言嵌入对齐,能够胜任各种下游任务。本文探索联合建模生成和判别的可能性。
提出DiffDis,将跨模态生成和判别预训练统一到扩散过程的框架中。DiffDis首先将图像-文本判别问题形式化为基于文本嵌入的生成扩散过程,该嵌入来自于以图像为条件的文本编码器。然后,提出一种新的双流网络架构,将噪声文本嵌入与来自不同尺度的潜在图像的知识融合在一起,用于图像-文本判别学习。此外,生成和判别任务可以在多模态模型中高效共享图像分支网络结构。由于基于扩散的统一训练,DiffDis在一个架构中实现了更好的生成能力和跨模态语义对齐。
实验结果表明,DiffDis在图像生成和图像-文本判别任务上优于单任务模型,例如在12个数据集上的零样本分类平均准确率提高了1.65%,零样本图像生成的FID提高了2.42。
20、AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
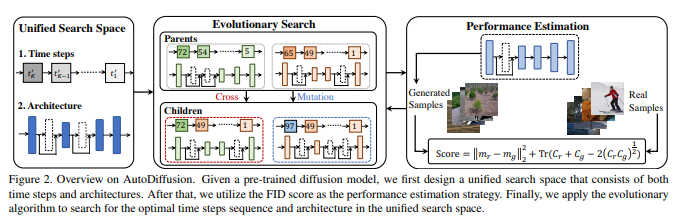
扩散模型生成一张图像通常需要大量的时间步骤(推理步骤)。为加速这个繁琐的过程,统一地减少步骤被认为是扩散模型的不争之论的原则。然而,这样的统一假设在实践中并不是最优解;也就是说,对于不同的模型,可以找到不同的最优时间步长。因此,提出在统一的框架中搜索最优的时间步长序列和压缩模型架构,以实现对扩散模型的有效图像生成而无需任何进一步的训练。
具体而言,首先设计一个统一搜索空间,其中包含所有可能的时间步长和各种架构。然后,引入了一个两阶段的进化算法来在设计的搜索空间中寻找最优解。为进一步加速搜索过程,用生成和真实样本之间的FID分数来估计采样样例的性能。结果表明,所提出方法是(i)无需训练,可以在没有任何训练过程的情况下获得最优的时间步长和模型架构;(ii)与大多数先进的扩散采样器正交,并且可以集成以获得更好的样本质量;(iii)具有广义性,通过为不同的扩散模型应用相同的指导比例,可以直接应用搜索的时间步长和架构。
实验结果表明,方法仅使用少量时间步长就实现出色的性能,例如在ImageNet 64×64上使用仅四个步骤,FID得分达到了17.86,而使用DDIM则为138.66。
21、DPM-OT: A New Diffusion Probabilistic Model Based on Optimal Transport

从扩散概率模型(DPMs)中进行采样可以看作是一个分段分布转换,通常需要反扩散轨迹的几百或几千步才能得到高质量的图像。最近在设计DPMs的快速采样器方面取得的进展通过知识蒸馏或调整方差计划或去噪方程的方式在采样速度和样本质量之间取得了折衷。然而,这在两方面都不能达到最优,并且在短时间步中经常出现模式混合的问题。
为解决这个问题,将反扩散视为不同阶段之间潜在变量之间的最优输运(OT)问题,并提出了DPM-OT,这是一个用于快速DPMs的统一学习框架。通过计算数据潜变量和白噪声之间的半离散最优输运图,获得了从先验分布到数据分布的高速路径,同时显著减轻了模式混合问题。此外,给出了所提方法的误差界,从理论上保证了算法的稳定性。
大量实验证实了DPM-OT在速度和质量(FID和模式混合)方面的有效性和优势,从而为生成建模提供了一种高效的解决方案。开源在:https://github.com/cognaclee/DPM-OT
22、Q-Diffusion: Quantizing Diffusion Models
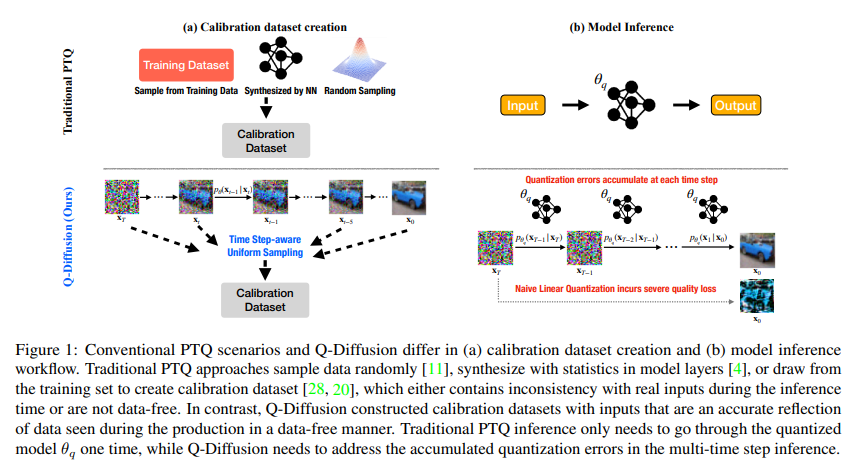
扩散模型通过用深度神经网络进行迭代噪声估计在图像生成方面取得了巨大的成功。然而,噪声估计模型的推理速度慢、内存消耗大和计算强度高,阻碍了扩散模型的高效应用。尽管后训练量化(PTQ)被认为是其他任务的首选压缩方法,但它在扩散模型上无法直接使用。
提出一种专门针对扩散模型的独特多时间步骤流程和模型架构的PTQ方法,通过压缩噪声估计网络来加速生成过程。实验结果表明,提出方法能够将完全精度的无条件扩散模型压缩为4位,同时保持可比较的性能(FID变化最多为2.34,而传统PTQ为>100),且无需训练。方法还可以应用于文本引导的图像生成,在4位权重下以高生成质量运行stable diffusion。
23、A Complete Recipe for Diffusion Generative Models

基于得分的生成模型(Score-based Generative Models,SGMs)在各种任务上展示了出色的生成结果。然而,目前的SGMs前向扩散过程设计领域尚未充分发挥,并且通常依赖于物理启发式或简化假设。借鉴可扩展贝叶斯后验抽样器的发展见解,提出一个完整配方,用于制定SGMs的前向过程,确保收敛到所需的目标分布。
方法揭示了几个现有SGMs可以看作是所提出框架的特定表现形式。基于这种方法,引入相空间朗之万扩散(PSLD),它依赖于在增强的空间内的得分建模,其中包含类似于物理相空间的辅助变量。实证结果展示了PSLD相对于各种竞争方法在已建立的图像合成基准上表现出的优越的样本质量和速度-质量平衡改进。值得注意的是,PSLD在无条件CIFAR-10生成方面实现了与最先进的SGMs相当的样本质量(FID:2.10)。
最后,演示PSLD在条件合成中使用预训练得分网络的适用性,为未来进展提供了一种有吸引力的SGM骨干方法的替代选择。开源在:https://github.com/mandt-lab/PSLD
24、Scalable Diffusion Models with Transformers

基于Transformer架构探索一种新的扩散模型。训练以图像为基础的潜在扩散模型,用Transformer代替常用的U-Net骨干网络,该Transformer在潜在图块上操作。通过前向传递复杂度的可伸缩性来分析扩散Transformer(DiTs)。发现通过增加Transformer的深度/宽度或增加输入tokens的数量,具有更高Gflops的DiTs一贯具有较低的FID。
除了具有良好的可伸缩性属性外,最大的DiT-XL/2模型在类别条件图像网512×512和256×256基准测试上胜过了所有先前的扩散模型,在后者上达到了2.27的最新成果。
已开源在:https://github.com/facebookresearch/DiT
25、End-to-End Diffusion Latent Optimization Improves Classifier Guidance

分类器引导(Classifier guidance),用图像分类器的梯度来引导扩散模型的生成和编辑,有潜力大幅扩展图像生成和编辑的创造性控制。然而,目前分类器引导要么需要训练新的噪声感知模型以获得准确的梯度,要么使用最终生成的一步去噪逼近,这会导致梯度不一致和次优的控制。本文强调这种逼近方法的不足,并提出了一种新的引导方法:扩散潜空间的直接优化(Direct Optimization of Diffusion Latents, DOODL),通过优化扩散潜空间相对于预训练分类器在真实生成像素上的梯度,使用可逆扩散过程实现了高效的内存反向传播,实现即插即过的引导。
展示更精确引导潜力的DOODL在计算和人类评估指标上优于一步分类器引导,在不同的引导形式上:使用CLIP引导改进DrawBench复杂提示的生成,使用精细的视觉分类器扩展扩散的词汇,使用CLIP视觉编码器实现基于图像的生成,并使用美学评分网络改善图像美学。
26、DiffFit: Unlocking Transferability of Large Diffusion Models via Simple Parameter-Efficient Fine-Tuning

扩散模型在生成高质量图像方面已被证明非常有效。然而将大规模预训练的扩散模型适应到新的领域仍是一个开放的挑战,这对于实际应用来说至关重要。
本文提出DiffFit,用于微调大规模预训练的扩散模型,快速适应新领域。DiffFit非常简单,仅微调特定层中的偏置项和新添加的缩放因子,但可以显著提升训练速度并减少模型存储成本。与完全微调相比,DiffFit实现了2倍的训练加速和仅需存储总模型参数的约0.12%。
提供了直观的理论分析,以证明缩放因子在快速适应上的有效性。在8个下游数据集上,DiffFit在与完全微调相比的性能上达到了卓越或有竞争力的表现,同时更加高效。展示了DiffFit可以通过极小的成本将预训练的低分辨率生成模型适应为高分辨率模型。在基于扩散的方法中,DiffFit在ImageNet 512×512基准测试上通过仅从公共预训练的ImageNet 256×256检查点微调25个epoch,获得了新的最新成果,同时训练效率比最接近的竞争者高30倍。
四、自监督学习
27、Diffusion Models as Masked Autoencoders
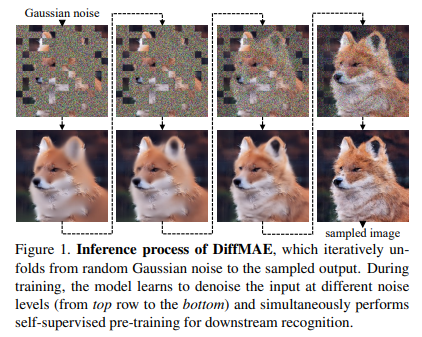
生成是否可以促进对视觉数据的真正理解?本文重新审视了视觉表示的生成预训练方法。虽然直接使用扩散模型进行预训练不能产生强大的表示,但将扩散模型以掩蔽输入为条件,并将其形式化为掩蔽自编码器(DiffMAE)。
方法能够(i)作为下游识别任务的强大初始化,(ii)进行高质量的图像修复,(iii)轻松扩展到视频,其中它产生了最先进的分类准确率。还对设计选择的利弊进行了全面研究,并建立了扩散模型和掩蔽自编码器之间的联系。
28、Denoising Diffusion Autoencoders are Unified Self-supervised Learners
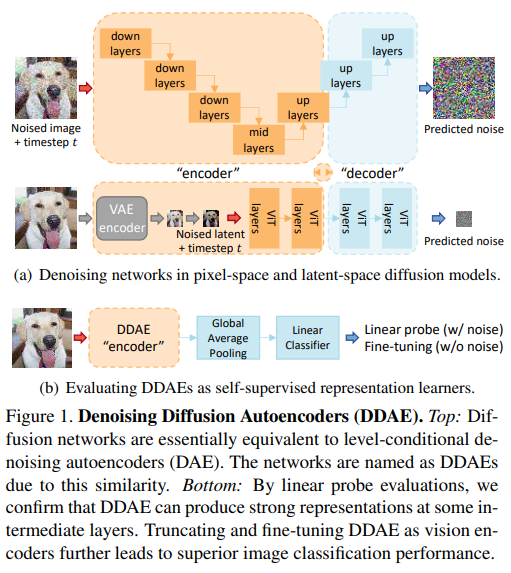
受到扩散模型最近进展启发,让人联想到去噪自编码器,研究它们是否能够通过生成预训练来获得用于分类的有区别的表示。本文表明,扩散模型中的网络,即去噪扩散自编码器(DDAE),是统一的自监督学习器:通过在无条件图像生成上进行预训练,DDAE已经在中间层学到了强大的线性可分离表示,而无需辅助编码器,从而使得扩散预训练成为一种生成和判别双向学习的通用方法。
为验证这点,进行线性探测和微调评估。基于扩散方法在CIFAR10和Tiny-ImageNet上分别达到了95.9%和50.0%的线性评估准确率,并且与对比学习和掩蔽自编码器具有可比性。从ImageNet进行迁移学习也验证了DDAE适用于Vision Transformers,表明将DDAE扩展为统一的基础模型具有潜力。开源在:https://github.com/FutureXiang/ddae
五、表征学习
29、Diffusion Model as Representation Learner
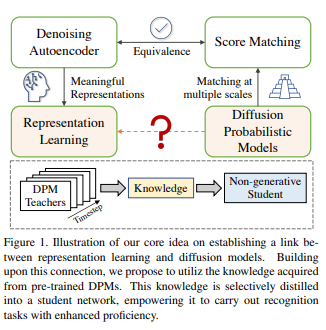
扩散概率模型(DPMs)在各种生成任务上展现了令人印象深刻的结果。尽管有着许多潜在的优势,但预训练DPMs的学习表示还没完全被理解。本文对DPMs的表示能力进行深入研究,并提出了一种新的知识迁移方法,该方法利用了生成DPMs获得的知识来进行识别任务。
研究始于对DPMs的特征空间进行的探索,揭示DPMs本质上是平衡表示学习与正则化模型容量的去噪自编码器。为此,引入了一种名为RepFusion的新型知识迁移范式。范式从现成的DPMs中提取不同时间步的表示,并动态地将它们作为学生网络的监督,其中最佳时间由强化学习确定。
在几个图像分类、语义分割和关键点检测基准上评估了方法,并证明其优于最先进的方法。结果揭示DPMs作为表示学习强大工具的潜力,并深入探讨生成模型在样本生成之外的用途的有用性。已开源在:https://github.com/Adamdad/Repfusion
六、布局可控生成
30、Zero-shot spatial layout conditioning for text-to-image diffusion models
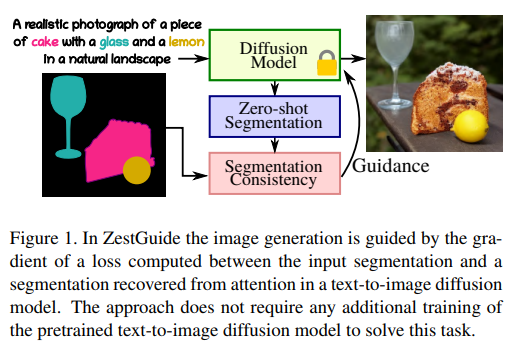
大规模的文本到图像扩散模型在生成图像建模方面取得重大突破,并做到用直观而强大的用户界面驱动图像生成过程。用文本表达空间约束,例如将特定对象放置在特定位置,文本方式很繁琐;而当前的基于文本的图像生成模型无法准确地遵循这样的指令。
本文考虑从与图像画布上的段相关联的文本生成图像,这将直观的自然语言界面与对生成内容具有精确空间控制相结合。提出ZestGuide,一种可以插入预训练文本到图像扩散模型中的“零样本”分割引导方法,无需任何额外的训练。它利用可以从跨注意力层中提取的隐式分割图,使用它们来将生成与输入掩模对齐。
实验结果在图像质量与生成内容与输入分割的准确对齐方面都具有很高的表现,并在定量和定性上优于以前的方法,包括在带有相应分割的图像上进行训练的方法。与以字为画笔的方法相比,它具有零样本分割条件下图像生成的先进状态,在COCO数据集上的mIoU分数上提高了5到10个点。
31、DLT: Conditioned layout generation with Joint Discrete-Continuous Diffusion Layout Transformer
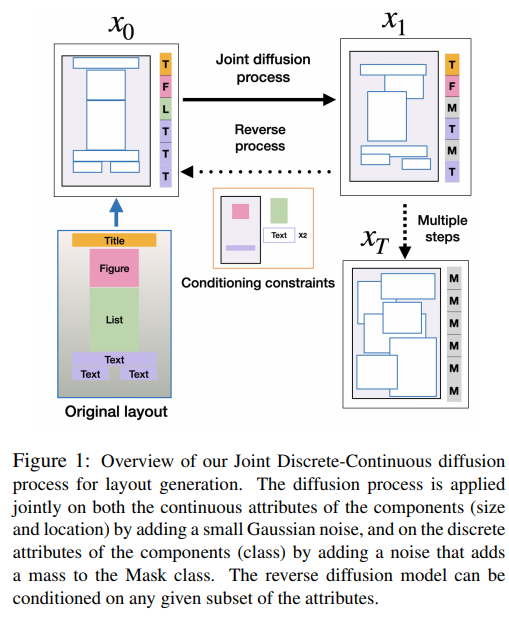
生成视觉布局是图形设计的一个关键要素。在涉及用户交互的实际应用中,能够在部分组件属性的条件下进行布局生成至关重要。最近,扩散模型在各个领域展示了高质量的生成性能。然而,如何将扩散模型应用于包含离散(类别)和连续(位置、大小)属性混合的布局的自然表示仍不清楚。
为解决条件布局生成问题,引入一个联合离散-连续扩散模型DLT。DLT是一个基于Transformer的模型,具有灵活的条件机制,允许在所有布局组件类别、位置和大小的给定子集上进行条件。方法在各种布局生成数据集上的不同度量和条件设置方面优于最先进的生成模型。
此外验证所提出的条件机制和联合连续扩散过程的有效性。该联合过程可以用于大范围的混合离散-连续生成任务。已开源在:https://github.com/wix-incubator/DLT
32、LAW-Diffusion: Complex Scene Generation by Diffusion with Layouts
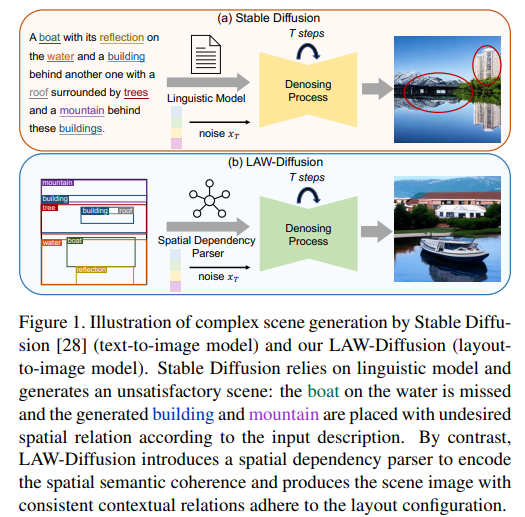
扩散模型的快速发展,图像生成取得前所未有的进步。以往工作主要依赖于预训练语言模型,但文本通常过于抽象,无法准确地指定图像的所有空间属性,例如场景的布局配置,导致复杂场景生成的次优结果。
本文通过提出一种语义可控的布局感知扩散模型(LAW-Diffusion)来实现准确的复杂场景生成。与以往主要探索类别感知关系的布局到图像生成(L2I)方法不同,LAW-Diffusion引入了一个空间依赖解析器,将位置感知的语义一致性作为布局嵌入,生成具有感知和上下文关系的场景对象样式。具体而言,把每个对象的区域语义细化为对象区域图,并利用一个位置感知的跨对象注意模块来捕捉这些解耦表示之间的空间依赖关系。
进一步提出一个自适应的布局引导调度,用于缓解区域语义对齐和生成对象的纹理保真度之间的权衡。此外,LAW-Diffusion允许在保持合成图像中的其他区域的情况下对实例进行重新配置,通过引入布局感知的潜在嫁接机制来重新组合其局部区域语义。为更好地验证生成场景的合理性,提出一种用于L2I任务的新评估指标,称为场景关系得分(SRS),用于衡量图像在保持上下文对象之间合理和和谐关系方面的能力。
在COCO-Stuff和Visual-Genome上进行的广泛实验证明,LAW-Diffusion在生成性能方面表现出卓越的性能,尤其是在一致的对象关系方面。
33、LayoutDiffusion: Improving Graphic Layout Generation by Discrete Diffusion Probabilistic Models
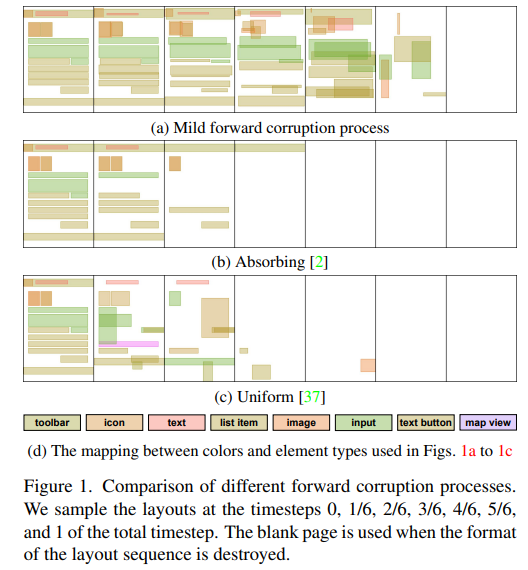
创建图形布局是图形设计的基本步骤。这项工作提出一种名为LayoutDiffusion的新型生成模型,用于自动布局生成。由于布局通常被表示为一系列离散token,LayoutDiffusion将布局生成建模为一种离散去噪扩散过程。它学习颠倒正向过程,在正向步骤增加的过程中布局变得越来越混乱,并且相邻步骤中的布局并不相差太多。然而,设计这样一个正向过程非常具有挑战性,因为布局具有分类属性和序数属性。
为解决这个挑战,总结三个实现布局正向过程的关键因素,即 legality, coordinate proximity 和 type disruption。基于这些因素,提出一个block-wise transition matrix coupled 和 piece-wise linear noise schedule。在RICO和PubLayNet数据集上的实验证明,LayoutDiffusion明显优于现有方法。此外,它使得两个条件布局生成任务能够以即插即用的方式进行,无需重新训练,并且具有比现有方法更好的性能。
已开源在:https://github.com/microsoft/LayoutGeneration/tree/main/LayoutDiffusion
七、可控文生图
34、Adding Conditional Control to Text-to-Image Diffusion Models

经典再回顾!ICCV 2023最佳论文ControlNet,用于向大型预训练的文本到图像扩散模型添加空间条件控制。ControlNet锁定了就绪的大型扩散模型,并重用它们深层和稳健的编码层,这些层已经通过数十亿张图像进行了预训练,作为学习多样的条件控制的强大支撑。神经架构与“零卷积”(从零初始化的卷积层)相连,从零开始逐渐增加参数,确保没有有害的噪声会影响微调过程。
使用Stable Diffusion测试各种条件控制,如边缘、深度、分割、人体姿势等,使用单个或多个条件,有或没有提示。展示ControlNet的训练在小规模(<50k)和大规模(>1m)数据集上都很稳健。广泛结果表明,ControlNet可以促进更广泛的应用,以控制图像扩散模型。已开源在:https://github.com/lllyasviel/ControlNet
35、MagicFusion: Boosting Text-to-Image Generation Performance by Fusing Diffusion Models
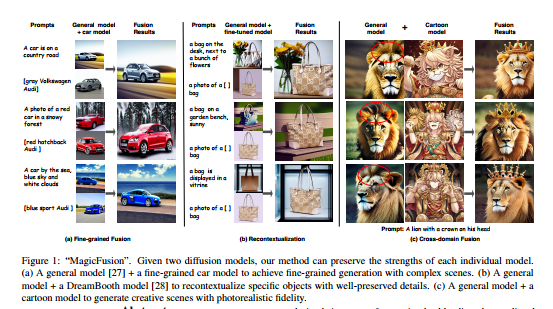
许多强大的基于文本引导的扩散模型,是在各种数据集上训练的。然而,鲜有关于组合这些模型以发挥它们的优势的探索。本研究提出一种称为感知注意噪声融合(SNB)的简单而有效的方法,可以使融合的文本引导扩散模型实现更可控的生成。
具体而言,通过实验证明,无分类器引导的响应与生成图像的显著性密切相关。因此,以一种感知性导向的方式混合两个扩散模型的预测噪声,以在它们的专业领域中信任不同模型。SNB不需要训练,并且可以在DDIM采样过程中完成。此外,它可以自动在两个噪声空间上对齐语义,而不需要额外的注释,如掩码。大量实验证明SNB在各种应用中的显著有效性。已开源在:https://github.com/MagicFusion/MagicFusion.github.io
36、Erasing Concepts from Diffusion Models

大规模扩散模型可能生成不受欢迎的输出(例如性暗示内容或受版权保护的艺术风格),研究从扩散模型权重中抹除特定概念的问题。
提出一种微调方法,从预训练的扩散模型中抹除某个视觉概念,只需提供风格的名称,并使用负向指导作为教师。将方法与之前删除性暗示内容的方法进行比较,并展示了其有效性,与Safe Latent Diffusion和经过审查的训练相媲美。
为评估艺术风格的去除效果,进行实验,从网络中删除了五位现代艺术家,并进行了用户研究,评估了被去除的风格在人类感知中的影响。与之前的方法不同,方法可以永久地从扩散模型中删除概念,而不是在推理时修改输出,所以即使用户可以访问模型权重,也无法规避。已开源在:https://github.com/rohitgandikota/erasing
37、Ablating Concepts in Text-to-Image Diffusion Models

大规模文本到图像扩散模型可生成具有强大组合能力的高保真度图像。然而,这些模型通常是训练在大量的互联网数据上,往往包含受版权保护的材料、许可的图片和个人照片。此外,它们被发现可以复制各种现实艺术家的风格或记住精确的训练样本。如何在不重新训练模型的情况下去除这些受版权保护的概念或图像?
为实现这一目标,提出一种高效的消除预训练模型中概念的方法,即阻止生成目标概念。算法学习将目标风格、实例或文本提示生成的图像分布与与锚定概念相对应的分布相匹配。这样,模型就不能根据其文本条件生成目标概念。实验表明,方法能够成功地阻止生成被消除的概念,同时保留与之密切相关的概念在模型中。
38、Editing Implicit Assumptions in Text-to-Image Diffusion Models

文本到图像的扩散模型,在生成图像时往往做出一些隐含假设。尽管某些假设有用(例如,天空是蓝色的),但也可能过时、不正确或反映在训练数据中存在的偏见。因此,有必要在不需要明确用户输入或昂贵的重新训练的情况下对这些假设进行控制。
这项工作目标是编辑预训练的扩散模型中的某个隐含假设。提出方法(Text-to-Image Model Editing,TIME)接收一对输入:一个“源”模糊的提示,对于这个提示,模型做出一个隐含假设(例如,“一束玫瑰”),以及一个“目的地”提示,描述相同场景,但包含一个指定的期望属性(例如,“一束蓝色的玫瑰”)。TIME然后更新模型的交叉注意力层,因为这些层将视觉含义分配给文本token。通过编辑这些层中的投影矩阵,使源提示接近目标提示。方法非常高效,仅在不到一秒的时间内修改模型的2.2%参数。
为评估模型编辑方法,引入TIMED(TIME数据集),包含来自不同领域的147个源和目标提示对。实验(使用稳定扩散)表明,TIME在模型编辑方面取得成功,对在编辑过程中看不见的相关提示具有很好的泛化能力,并对不相关的生成产生了最小的影响。已开源在:https://github.com/bahjat-kawar/time-diffusion
39、Localizing Object-level Shape Variations with Text-to-Image Diffusion Models
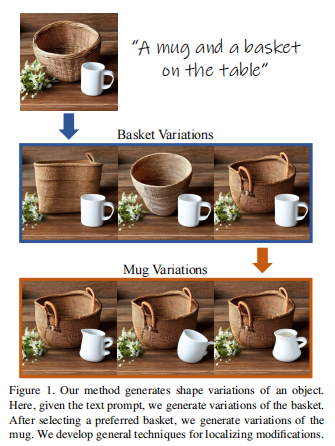
文本到图像模型,通常需要在大量生成的图像中筛选。文本到图像生成过程的全局性质,使用户无法将他们的探索限定在图像中的特定对象。
本文提出一种技术,用于生成形状特定对象的一系列变化的图像集合,从而实现对象级别的形状探索过程。创建可信的变化是具有挑战性的,因为它需要对生成对象的形状进行控制,同时保持其语义。在生成对象变化时,一个特殊的挑战是准确地定位应用于对象形状的操作。介绍了一种混合提示技术,通过在去噪过程中在不同的提示之间切换,来获得多种形状选择。
为定位图像空间的操作,提出了两种使用自注意力层和交叉注意力层的定位技术。此外还表明,这些定位技术在超出生成对象变化范围的情况下也是通用且有效的。广泛结果和比较证明方法在生成对象变化方面的有效性,以及定位技术的竞争力。已开源在:https://github.com/orpatashnik/local-prompt-mixing
40、Harnessing the Spatial-Temporal Attention of Diffusion Models for High-Fidelity Text-to-Image Synthesis

扩散模型的一个关键局限,生成图像与文本描述之间的准确度不高,如缺失对象、属性不匹配和对象位置不正确。造成这些不一致的一个关键原因是跨注意力在空间维度和时间维度上对文本的不准确处理。空间维度控制着对象应出现在哪个像素区域,而时间维度控制着在去噪步骤中添加不同级别的细节。
本文提出一种新的文本到图像算法,为扩散模型增加了对空时交叉注意力的明确控制。首先,用布局预测器来预测文本中提到的对象的像素区域。然后,通过将对整个文本描述的注意力与对该特定对象在相应像素区域的局部描述之间的注意力相结合来实施空间注意力控制。通过允许组合权重在每个去噪步骤中发生变化,并且通过优化组合权重来确保图像与文本之间的高准确度,进一步增加了时间注意力控制。
实验证明,与扩散模型为基础的基线方法相比,方法在生成图像时具有更高的准确度。已开源在:https://github.com/UCSB-NLP-Chang/Diffusion-SpaceTime-Attn
41、BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion

文本到图像扩散模型方面,研究人员主要研究了只用文本提示生成图像的方法。虽有些尝试用其他模态作为条件,但需大量配对数据,如边界框/遮罩图像对,且需精调训练。由于配对数据需要耗费时间和精力才能获取,并且受限于封闭集合,这可能成为在开放世界中应用的瓶颈。
本文针对最简单的用户提供条件的形式,如边界框或涂鸦,提出一种无需训练的方法来控制合成图像中的对象和背景,以便符合给定的空间条件。具体而言,本文设计了三种空间约束,即内部框、外部框和角点约束,并将其无缝地集成到扩散模型的去噪步骤中,不需要额外的训练和大量的标注布局数据。实验结果表明,所提出的约束可以控制图像中要呈现的内容和位置,同时保持扩散模型合成高保真度和多样的概念覆盖能力的能力。已开源在:https://github.com/showlab/BoxDiff
42、Versatile Diffusion: Text, Images and Variations All in One Diffusion Model

近年来,扩散模型的进展在许多生成任务中取得了令人瞩目的里程碑,备受关注的作品如DALL-E2,Imagen和Stable Diffusion等。尽管领域正在迅速变化,但最近的新方法主要关注扩展和性能,而非容量,因此需要针对不同任务单独建模。
本文将现有的单流扩散流水线扩展为多任务多模态网络,命名为Versatile Diffusion (VD),用于处理文本到图像、图像到文本等多个流,并在一个统一模型中处理多种变化。VD的流水线设计实例化了一个统一的多流扩散框架,包含可共享和可交换的层模块,实现了跨模态的通用性,超越图像和文本。
广泛实验证明,VD成功实现了以下几点:a) VD胜过基线方法,并能够以具有竞争力的质量处理所有基本任务;b) VD实现了一些新的扩展,如风格和语义的解离、双重和多重上下文融合等;c) 本文的多流多模态框架在图像和文本上的成功可能会在扩散为基础的通用AI研究中激发更多的思考。已开源在:https://github.com/SHI-Labs/Versatile-Diffusion
43、FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model

条件扩散模型的出色生成能力,在许多应用中受到广泛关注。然而,许多现有方法都需进行训练。这增加了构建条件扩散模型的成本,并且在不同条件下的转移不方便。一些现有方法试图通过提出无需训练的解决方案来克服这个限制,但大多数只能应用于特定类别的任务,而不能应用于更一般的条件。
本文提出一种无需训练的条件扩散模型(FreeDoM),用于各种条件。具体而言,利用现成的预训练网络,如人脸检测模型,构建时间独立的能量函数,指导生成过程而无需进行训练。此外,由于能量函数的构建非常灵活,适应各种条件,提出的FreeDoM比现有的无需训练方法具有更广泛的应用范围。
FreeDoM具有简单性、有效性和低成本的优势。实验证明,FreeDoM对各种条件有效,并适用于包括图像和潜码在内的各种数据域的扩散模型。已开源在:https://github.com/vvictoryuki/FreeDoM
八、动作检测
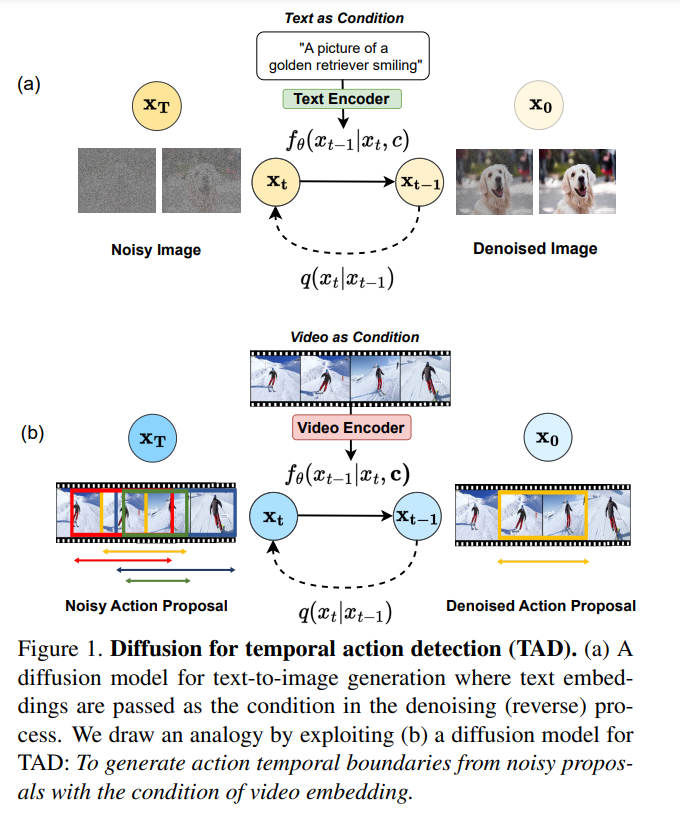
44、DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
基于扩散方法提出一种新的时序动作检测(TAD)算法,简称DiffTAD。以随机时序proposals作为输入,可以在未修剪的长视频中准确生成动作proposals。从生成建模的视角,与先前的判别学习方法不同。
首先将真实proposals从正向扩散到随机proposals(即前向/噪声过程),然后学习逆转噪声过程(即反向/去噪过程)来实现这种能力。通过在Transformer解码器(如DETR)中引入具有更快收敛性的时间位置查询设计来建立去噪过程。进一步提出一种用于推理加速的交叉步选择条件算法。
在ActivityNet和THUMOS上的大量评估表明,与先前的方法相比,DiffTAD实现了最佳性能。已开源在:https://github.com/sauradip/DiffusionTAD
九、目标检测
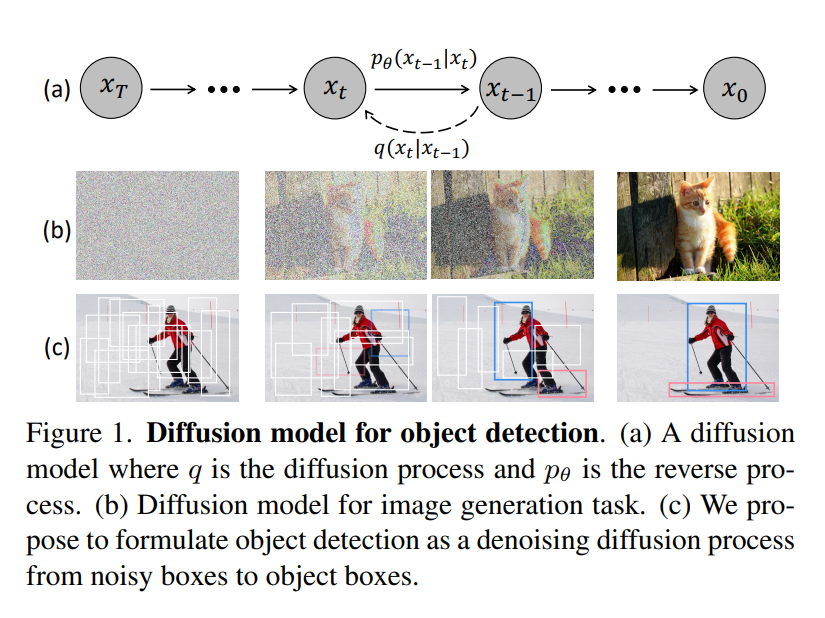
45、DiffusionDet: Diffusion Model for Object Detection
提出DiffusionDet,一种将目标检测作为从噪声框到目标框的去噪扩散过程的新框架。在训练阶段,目标框从真实边界框扩散到随机分布,模型学习逆转这个噪声过程。在推理中,模型以渐进的方式将一组随机生成的边界框优化到输出结果中。
方法具有灵活性的吸引力,可以动态调整边界框的数量和迭代评估。在标准基准测试中进行的广泛实验表明,与先前的成熟检测器相比,DiffusionDet取得了有利的性能。例如,在从COCO到CrowdHuman的零样本迁移设置下,DiffusionDet在较多的边界框和迭代步骤下分别达到了5.3 AP和4.8 AP的增益。已开源在:https://github.com/ShoufaChen/DiffusionDet
十、异常检测
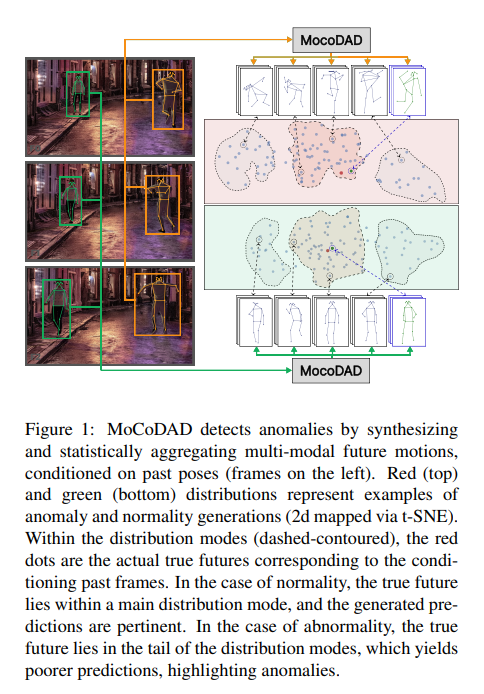
46、Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
异常情况很少见,因此异常检测通常作为单分类(OCC)来构造,即仅在正常情况下进行训练。提出了一种新的视频异常检测(VAD)生成模型,假设正常和异常都是多模态的。考虑骨骼表示,并利用最先进的扩散概率模型生成多模态的未来人体姿势。对人的过去动作进行了新的条件化,并利用扩散过程的改进模式覆盖能力生成不同但可靠的未来运动。
通过对未来模态进行统计聚合,当生成的一组运动与实际未来不相关时,检测到异常。在四个已建立的基准测试:UBnormal,HR-UBnormal,HR-STC和HR-Avenue上验证模型,并进行广泛实验,结果超过现有技术水平。已开源在:https://github.com/aleflabo/MoCoDAD
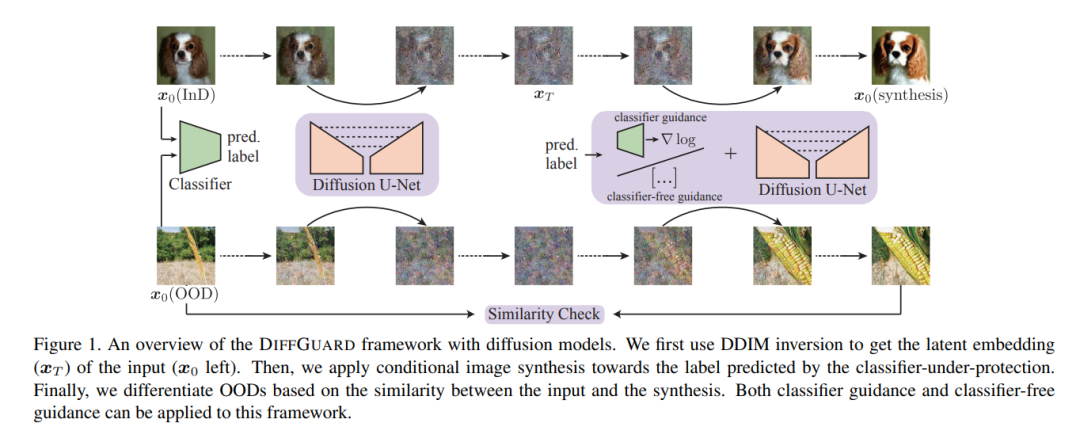
47、DIFFGUARD: Semantic Mismatch-Guided Out-of-Distribution Detection using Pre-trained Diffusion Models
给定一个分类器,语义上的Out-of-Distribution(OOD)样本的固有属性是其内容与所有合法类别在语义上有所不同,即语义不匹配。最近工作将其直接应用于OOD检测,该方法采用条件生成对抗网络(cGAN)来扩大图像空间中的语义不匹配。尽管在小型数据集上取得一些效果,但对于IMAGENET规模的数据集来说,由于训练同时具备输入图像和标签作为条件的cGAN的困难,该方法不适用。
鉴于扩散模型比cGANs更易于训练和适用于各种条件,本研究提出一种名为DIFFGUARD的方法,直接利用预训练扩散模型进行语义不匹配引导的OOD检测。具体而言,给定一个OOD输入图像和分类器的预测标签,扩大在这些条件下重建的OOD图像与原始输入图像之间的语义差异。还提出一些测试时的技术来进一步增强这种差异。
实验证明,DIFFGUARD对于CIFAR-10和大规模IMAGENET的复杂案例都很有效,并且可以与现有的OOD检测技术轻松结合,达到最先进的OOD检测结果。已开源在:https://github.com/cure-lab/DiffGuard
48、Feature Prediction Diffusion Model for Video Anomaly Detection
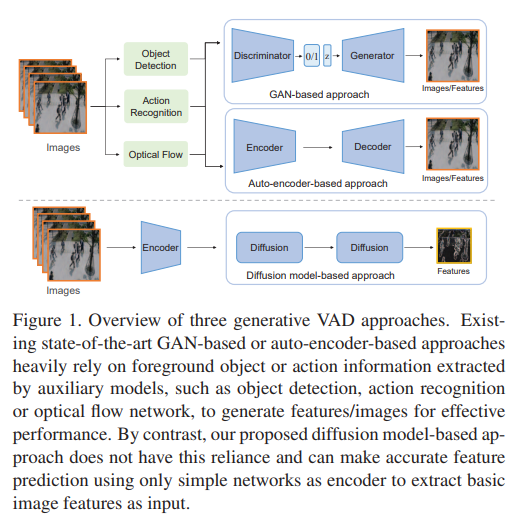
在视频中进行异常检测,是一个重要的研究领域和实际应用中的挑战性任务。由于缺乏大规模标注的异常事件样本,大多数现有的视频异常检测(VAD)方法侧重于学习正常样本的分布,以检测明显偏离的异常样本。为学习正常运动和外观的分布,许多辅助网络被用于提取前景对象或动作信息。这些高级语义特征可以有效地过滤背景噪声,减少其对检测模型的影响。然而,这些额外的语义模型的能力严重影响了VAD方法的性能。
受扩散模型(DM)启发,本研究引入一种基于DM的新方法来预测用于异常检测的视频帧特征。目标是在不涉及任何额外高级语义特征提取模型的情况下学习正常样本的分布。为此,构建两个去噪扩散隐式模块来预测和改善特征。第一个模块专注于特征运动学习,最后一个模块专注于特征外观学习。
这是第一个基于DM的VAD帧特征预测方法。扩散模型的强大能力使方法能比非DM的特征预测VAD方法更准确地预测正常特征。实验证明,方法在具有挑战性的MVTec数据集上实现了最先进的性能,特别是在定位精度上。
49、Unsupervised Surface Anomaly Detection with Diffusion Probabilistic Model
无监督表面异常检测,仅用无异常的训练样本来发现和定位异常模式。基于重建的模型是最受欢迎和成功的方法之一,其依赖于异常区域更难重建的假设。然而,这种方法在实际应用中面临三个主要挑战:1)需要进一步改进重建质量,因为它对最终结果有很大影响,特别是对于具有结构变化的图像;2)观察到对于许多神经网络,异常样本也可以很好地重建,这严重违反了基本假设;3)由于重建是一个病态问题,一个测试实例可能对应多个正常模式,但大多数当前的基于重建的方法忽略了这个关键事实。
本文提出DiffAD,一种基于潜在扩散模型的无监督异常检测方法,受到其生成高质量和多样化图像的能力的启发。进一步提出噪声条件嵌入和插值通道来解决常规重建流程中所面临的挑战。广泛实验证明,方法在具有挑战性的MVTec数据集上实现最先进的性能,特别是在定位准确性方面。
十一、deepfake检测
50、DIRE for Diffusion-Generated Image Detection
扩散模型在视觉生成方面取得成功,但也引发了可能滥用于恶意目的的担忧。本文旨在构建一个检测器,用于区分真实图像和扩散生成的图像。发现现有的检测器很难检测到由扩散模型生成的图像,即使在它们的训练数据中包括了来自特定扩散模型生成的图像。
为解决这个问题,提出一种新的图像表示方法,称为扩散重构误差(DIRE),它通过预训练的扩散模型来衡量输入图像及其重构对应物之间的误差。观察到,扩散生成的图像可以通过扩散模型进行近似重构,而真实图像则不能。这提供了一个线索,表明DIRE可以作为区分生成图像和真实图像的桥梁。DIRE为检测大多数扩散模型生成的图像提供了一种有效的方法,并且适用于检测来自未知扩散模型的生成图像,并且能够抵抗各种扰动。
此外,建立一个扩散生成基准,包括由各种扩散模型生成的图像,以评估扩散生成的图像检测器的性能。在收集的基准上进行了大量实验证明,DIRE优于先前的生成图像检测器。已开源在:https://github.com/ZhendongWang6/DIRE

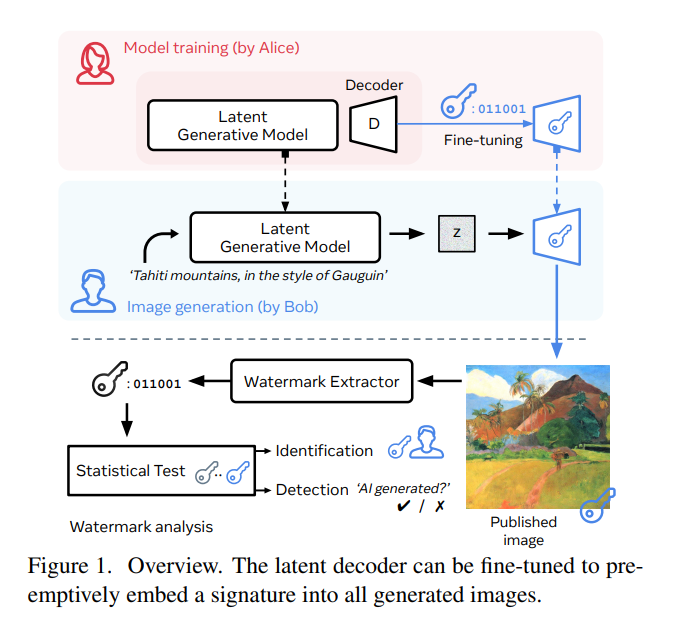
51、The Stable Signature: Rooting Watermarks in Latent Diffusion Models
生成图像可实现广泛应用,但也引发了关于负责、伦理关注。引入一种结合图像水印和潜在扩散模型的主动内容追踪方法。其目标是使所有生成的图像都隐藏了一个不可见的水印,以便未来进行检测和/或识别。
该方法通过对二进制签名进行条件化,快速调整图像生成器的潜在解码器。一个预训练的水印提取器从任何生成的图像中恢复出隐藏的签名,然后经过统计检验确定其是否来自生成模型。评估了水印在各种生成任务上的隐形性和稳健性,并显示出稳定签名对图像修改具有较高的鲁棒性。例如,它可以检测到从文本提示生成的图像的来源,然后截取其中10%的内容,以90+%的准确率在误报率低于10^(-6)时进行检测。https://github.com/facebookresearch/stable_signature
十二、年龄迁移
52、Pluralistic Aging Diffusion Autoencoder

人脸老化问题是一个无法确定问题,因为多个可能的老化模式可能与给定的输入对应。大多数现有方法通常产生一个确定性的估计。本文提出一种新的CLIP驱动的多样化老化扩散自编码器(PADA),以增强老化模式的多样性。
首先,用扩散模型通过顺序去噪反向过程生成多样化的低级老化细节。其次,提出概率老化嵌入(PAE),以在共同的CLIP潜空间中将年龄信息表示为概率分布。设计一种文本引导的KL散度损失来指导这个学习过程。定性和定量实验证明,方法可以生成更多样化和高质量的合理老化结果。
十三、 虚拟试衣
53、DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
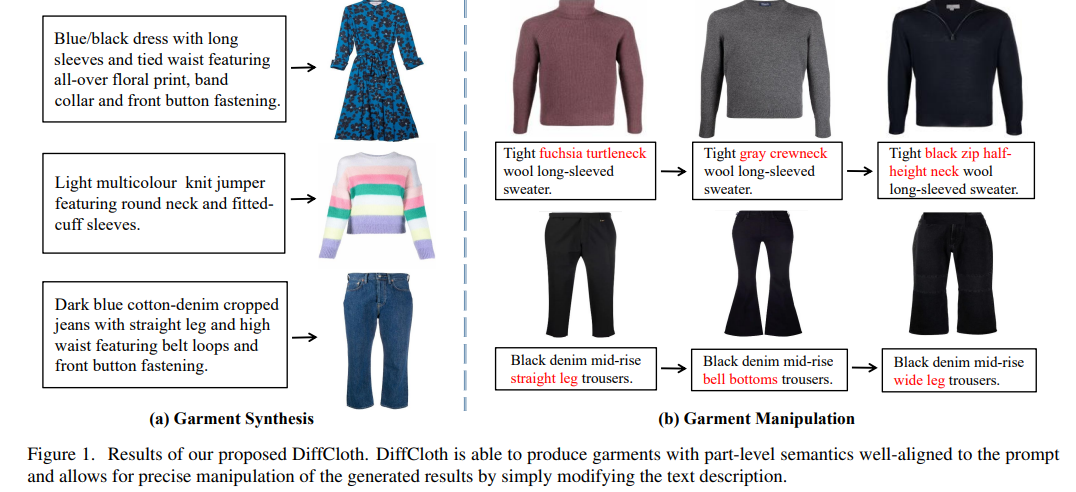
跨模态的服装合成和操作,极大改善设计师通过灵活的语言界面生成服装和修改设计的方式。然而,尽管用扩散模型在通用图像生成方面取得显著进展,但是生成与输入的文本提示良好对齐的具有服装局部语义的服装图像,并灵活编辑仍是问题。
当前方法遵循通用的文本到图像范式,并通过简单交叉注意力模块挖掘跨模态关系,忽视时尚设计领域中视觉和文本表示之间的结构对应关系。本文提出DiffCloth,一种用于跨模态服装合成和操作、基于扩散的流水线,通过结构对齐跨模态语义,为扩散模型赋予了在时尚领域中的灵活组合性。
具体而言,将部分级跨模态对齐问题定义为语言属性短语(AP)和基于组成性解析和语义分割获得的视觉服装部件之间的二部图匹配问题。为减轻属性混淆的问题,进一步提出语义绑定的交叉注意力,以保留每个AP中属性形容词和部位名词的注意力映射之间的空间结构相似性。
此外,DiffCloth允许通过简单地替换文本提示中的AP来操纵生成的结果。使用AP的捆绑注意力图获得的混合掩码可以识别不需要操纵的区域并保持不变。在CM-Fashion基准上的广泛实验表明,DiffCloth通过利用固有的结构信息产生了最先进的服装合成结果,并支持具有区域一致性的灵活操作。
54、DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
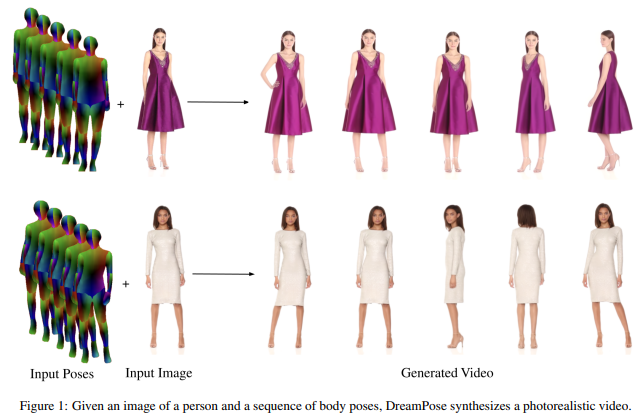
提出DreamPose,一种基于扩散的方法,用于从静止图像生成驱动的时装视频。给定一张图像和一系列人体姿势,方法合成一个包含人体和面料运动的视频。为实现这一点,将预训练的文本到图像模型(稳定扩散)转化为一个以姿势和图像为导向的视频合成模型,采用一种新的微调策略,一组支持新增条件信号的架构更改,以及鼓励时间一致性的技术。
在UBC时尚数据集的一组时尚视频上进行微调。在各种服装风格和姿势上评估方法,并证明方法在时装视频驱动方面取得最先进结果。已开源在:https://grail.cs.washington.edu/projects/dreampose/
55、Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing

时尚插图被设计师用于传达他们的愿景,并将设计理念从概念化转化为实现,展示服装与人体的互动。在这个背景下,计算机视觉可以用来改进时尚设计的过程。与之前主要关注虚拟试穿服装的作品不同,提出多模态条件时尚图像编辑的任务,通过文本、人体姿势和服装草图等多模态提示来引导人体中心的时尚图像的生成。
通过提出一种基于潜在扩散模型的新架构来解决这个问题。鉴于现有数据集不适合这个任务,还以半自动的方式扩展了两个现有的时尚数据集,即Dress Code和VITON-HD,以收集多模态标注。这些新数据集上的实验结果证明方法有效性,无论是从逼真度还是与给定的多模态输入的一致性方面。已开源在:https://github.com/aimagelab/multimodal-garment-designer
十四、图像分割
56、DDP: Diffusion Model for Dense Visual Prediction
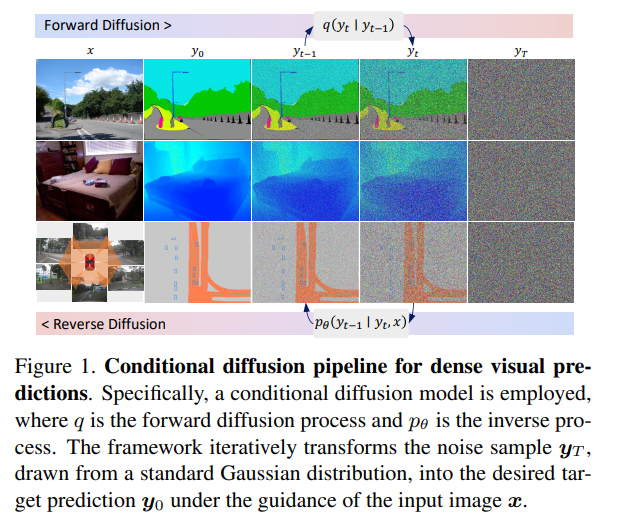
提出一种简单、高效但功能强大的基于条件扩散流程(density visual predictions)的框架。方法采用“噪声到分割图”(noise-to-map)的生成范式进行预测,通过逐步从随机高斯分布中去除噪声来引导图像生成。这种方法称为DDP,无需特定于任务的设计和架构定制,易于推广到大多数密集预测任务,例如语义分割和深度估计。
DDP在六个不同的基准任务上展示了三个代表性任务的顶级结果。例如,语义分割在Cityscapes上的mIoU达到83.9,BEV地图分割在nuScenes上的mIoU达到70.6,深度估计在KITTI上的REL达到0.05。https://github.com/JiYuanFeng/DDP
57、Unleashing Text-to-Image Diffusion Models for Visual Perception
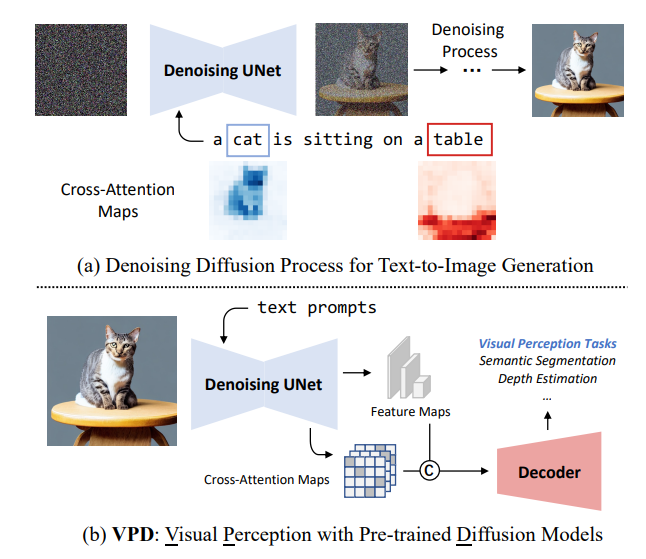
本文提出VPD(视觉感知与预训练的扩散模型),利用预训练的文本到图像扩散模型,在视觉感知任务中利用语义信息。不使用扩散预训练去噪自编码器,而将其简单地用作主干,并旨在研究如何充分利用所学知识。
用适当的文本输入提示去噪解码器,并通过适配器改进文本特征,从而更好地与预训练阶段对齐,并使视觉内容与文本提示进行交互。还提出利用视觉特征和文本特征之间的交叉注意力图来提供明确的引导。与其他预训练方法相比,展示了利用视觉语言预训练的扩散模型可以更快地适应基于视觉感知任务的提出的VPD的有效性。
对语义分割、引用图像分割和深度估计的广泛实验证明了方法的有效性。值得注意的是,VPD在NYUv2深度估计上达到了0.254的RMSE和RefCOCO-val引用图像分割上的73.3%的oIoU,创造了这两个基准的新纪录。已开源在:https://github.com/wl-zhao/VPD
58、Open-vocabulary Object Segmentation with Diffusion Models
 本文的目标是从预训练文本到图像扩散模型中提取视觉语言对应关系,以分割图的形式,即同时生成图像和分割掩模,描述文本提示中相应的视觉实体。
本文的目标是从预训练文本到图像扩散模型中提取视觉语言对应关系,以分割图的形式,即同时生成图像和分割掩模,描述文本提示中相应的视觉实体。
(i)将现有的扩散模型与一种新的基于定位的模块配对,只需要少量目标类别的训练可以使扩散模型的视觉和文本嵌入空间对齐;(ii)建立一个自动的流水线来构建数据集,其中包含{图像、分割掩模、文本提示}三元组,以训练所提出的定位模块;(iii)评估从文本到图像扩散模型生成的图像上的开放词汇定位的性能,并展示了该模块可以很好地对训练时已见过的类别之外的类别的对象进行分割;(iv)采用增强的扩散模型构建了一个合成的语义分割数据集,并展示了在这样的数据集上训练标准分割模型在零样本分割(ZS3)基准测试中表现出有竞争力的性能,为采用强大的扩散模型用于判别任务开辟了新的机会。
已开源在:https://github.com/Lipurple/Grounded-Diffusion
59、Diffusion Action Segmentation

时间动作分割对于理解长事件视频至关重要。以往针对这个任务的作品通常采用迭代细化范式,使用多阶段模型。本文提出一种通过去噪扩散模型的新框架,然而它与这种迭代优化的本质精神是相同的。
根据输入视频特征,动作预测是从随机噪声中迭代生成。为增强对人类动作的三个显著特征建模,包括位置先验、边界模糊度和关系依赖性,为条件输入设计了统一的遮罩策略。对GTEA、50Salads和Breakfast三个基准数据集进行大量实验,方法在性能上达到了优于或与最先进方法可比的结果,显示了采用生成方法进行动作分割的有效性。已开源在:https://github.com/Finspire13/DiffAct
60、LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation

大规模的预训练任务,如图像分类、描述生成或自监督技术,并不鼓励学习对象的语义边界。然而,使用基于文本的潜在扩散技术构建的最新生成基础模型可能会学习语义边界。这是因为它们必须基于文本描述综合生成图像中所有对象的细节。因此,提出一种在互联网规模数据集上训练的潜在扩散模型(LDMs)来对实际图像和AI生成图像进行分割的技术。
首先表明LDMs的潜在空间(z空间)作为输入表示相对于其他特征表示如RGB图像或CLIP编码而言更好用于基于文本的图像分割。通过在潜在z空间上训练分割模型,该模型在各种形式的艺术、卡通、插图和照片等不同领域之间创建了压缩表示,也能够弥合实际图像和AI生成图像之间的领域差距。
展示了LDMs的内部特征包含丰富的语义信息,并提出LD-ZNet,进一步提高基于文本的分割的性能。总体而言,在自然图像的文本到图像分割上显示了超过标准基线的6%改进。对于AI生成的图像,与最先进技术相比,接近20%改进。已开源在:https://github.com/koutilya-pnvr/LD-ZNet
61、Diffusion-based Image Translation with Label Guidance for Domain Adaptive Semantic Segmentation
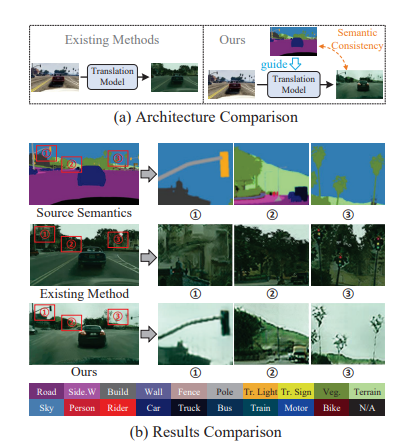
将图像从源域转换到目标域以学习目标模型是域自适应语义分割(DASS)中最常见的策略之一。然而,现有方法仍然很难在原始图像和转换后的图像之间保持语义一致的局部细节。
这项工作提出一种新方法,通过使用源域标签作为显式引导来进行图像转换,以解决这个挑战。具体而言,将跨域图像转换形式化为去噪扩散过程,并利用一种新颖的语义梯度引导(SGG)方法来约束转换过程,将其作为像素级源标签的条件。此外,设计渐进式转换学习(PTL)策略,使SGG方法能够在具有较大差距的域之间可靠地工作。广泛实验证明了方法优越性。
62、DiffuMask: Synthesizing Images with Pixel-level Annotations for Semantic Segmentation Using Diffusion Models

收集和标注像素级标签的图像耗时且费力。相比下,用生成模型(例如DALL-E、Stable Diffusion)可自由生成数据。本文展示通过Off-the-shelf Stable Diffusion模型生成,自动获取准确的语义掩膜,该模型在训练过程中仅用文本-图像对。
方法称为DiffuMask,利用文本和图像之间的交叉注意力图的潜力,将文本驱动的图像合成扩展到语义掩膜生成中。DiffuMask利用文本引导的交叉注意力信息来定位类别/词特定的区域,结合实用技术创建一个新的高分辨率和类别区分的像素级掩膜。这些方法有助于显著降低数据收集和标注成本。实验表明,使用DiffuMask的合成数据训练的现有分割方法在与真实数据(VOC 2012、Cityscapes)相比的性能上取得了竞争力。对于某些类别(例如鸟类),DiffuMask呈现出有希望的性能,接近真实数据的最新结果(mIoU误差在3%以内)。
此外,在开放式词汇分割(零点)设置中,DiffuMask在VOC 2012的未见类别上取得了新的最新结果。已开源在:https://weijiawu.github.io/DiffusionMask/
63、Stochastic Segmentation with Conditional Categorical Diffusion Models
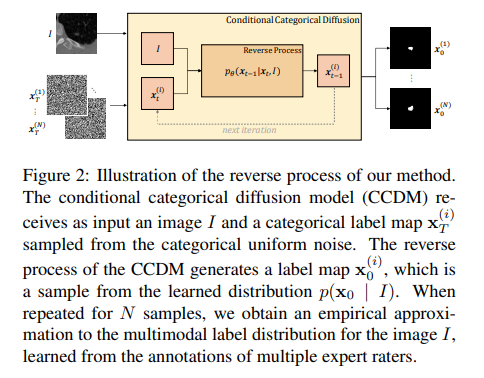
近年来深度神经网络发展,语义分割取得重大进展,但对于医学诊断和自动驾驶等安全关键领域而言,生成与图像内容精确匹配的单一分割输出可能并不合适。相反,可能需要多个正确的分割图来反映标注图的真实分布。在这种情况下,随机语义分割方法必须学习预测在给定图像的条件下标签的条件分布,但是由于通常是多模态分布、高维输出空间和有限的标注数据,这是一项具有挑战性的任务。
为解决这些挑战,提出一种基于去噪扩散概率模型的条件分类扩散模型(CCDM),用于语义分割。模型以输入图像为条件,能够生成多个分割标签图,考虑到由不同的真实标注产生的aleatoric不确定性。实验结果表明,CCDM在LIDC(一种随机语义分割数据集)上取得了最新的最佳性能,并在经典分割数据集Cityscapes上优于已经建立的基线。
十五、图像分类
64、EGC: Image Generation and Classification via a Diffusion Energy-Based Model

用相同的网络参数集进行图像分类和图像生成的学习面临着巨大的挑战。在一个任务上表现出色,但在另一个任务上表现不佳。本研究引入一种基于能量的分类器和生成器,称为EGC,它用单个神经网络在两个任务中实现卓越的性能。与产生一个标签给定图像的传统分类器(即条件分布p(y|x))不同,EGC中的前向传播是一个分类模型,产生一个联合分布p(x, y),同时通过边缘化标签y来估计评分函数中的扩散模型。
此外,EGC可以通过将标签视为潜在变量来适应无监督学习。在ImageNet-1k、CelebA-HQ和LSUN Church上,EGC在生成方面取得了与最先进方法相竞争的结果,同时在CIFAR-10上实现了更高的分类准确性和对抗攻击的鲁棒性。本研究是使用统一的网络参数集掌握这两个领域的重要进展。已开源在:https://github.com/GuoQiushan/EGC
65、Your Diffusion Model is Secretly a Zero-Shot Classifier
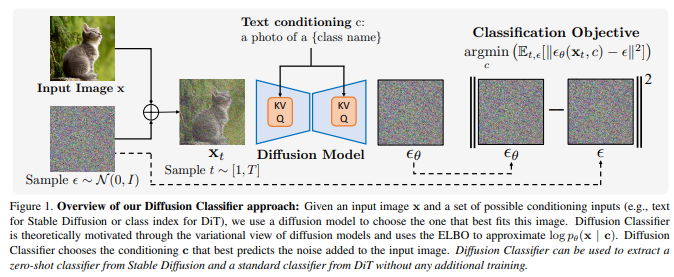
大规模文本到图像扩散模型,增强了基于文本的图像生成能力。这些模型根据各种提示生成逼真图像,展示出令人印象深刻的泛化能力。到目前为止,几乎所有的应用都集中在采样上,然而,扩散模型也可以提供条件密度估计,这对于超越图像生成的任务非常有用。
本文展示大规模文本到图像扩散模型(如Stable Diffusion)的密度估计可以用于在没有任何额外训练的情况下进行零样本分类。提出的分类生成方法Diffusion Classifier在各种基准测试中取得不错的效果,并优于从扩散模型中提取知识的其他方法。虽然生成式和判别式方法在零样本识别任务上仍存在差距,但基于扩散的方法具有比竞争的判别式方法更强的多模态组合推理能力。最后,用Diffusion Classifier从基于类条件扩散模型在ImageNet上进行训练的标准分类器中提取,这些模型接近优秀判别式分类器的性能,并在面对分布偏移时表现出较强的“有效鲁棒性”。已开源在:https://github.com/diffusion-classifier/diffusion-classifier
十六、图像编辑
66、Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models

最近,大规模扩散模型大大改进了图像生成能力,能在各领域生成逼真照片。基于这一成功,当前的图像编辑方法用文本实现对图像的直观且多功能的修改。要用扩散模型编辑真实图像,首先必须将图像反转/逆映射为一个带噪声的潜在向量,然后用目标文本提示进行采样生成编辑后的图像。然而,大多数方法缺乏以下几点之一:用户友好性(例如,需要额外的遮罩或对输入图像的精确描述)、对更大领域的泛化能力,或者对输入图像的高保真度。
本文设计一种精确且快速的反转技术——Prompt Tuning Inversion,用于文本驱动的图像编辑。具体而言,提出的编辑方法包括重构阶段和编辑阶段。在第一阶段,通过Prompt Tuning Inversion将输入图像的信息编码为可学习的条件嵌入。在第二阶段,应用无分类器指导来采样编辑后的图像,其中条件嵌入是通过线性插值计算目标嵌入和第一阶段获得的优化嵌入之间的插值得到的。
这种技术确保了方法的可编辑性与对输入图像的高保真度之间的卓越平衡。例如,可以在仅有目标文本提示的指导下,在保持其原始形状和背景的同时改变特定对象的颜色。在ImageNet上的大量实验表明,与最先进的基线方法相比,方法具有卓越的编辑性能。
67、Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis

条件生成模型通常需要大量的标注训练集,才能实现高质量的合成。因此,设计即插即用生成的模型(即用预定义或预训练模型)以引导生成过程(例如,使用语言)引起了极大的兴趣。然而,这种引导通常只对合成高级语义而不是编辑细粒度细节(如图像到图像的转换任务)有用。
为此,基于最近基于扩散的生成模型提供的强大细粒度生成控制,并借鉴了这一特性,引入引导扩散(Steered Diffusion)技术,一种用于使用经训练用于非条件生成的扩散模型进行逼真的零样本条件图像生成的广义框架。关键思想是通过使用刻画条件任务的预训练逆模型来设计损失函数,从而在推断时引导扩散模型的图像生成。这个损失函数调制了扩散过程的采样轨迹。框架允许在推断过程中轻松地结合多个条件。
使用引导扩散在多个任务上进行了实验,包括修复、着色、文本引导的语义编辑和图像超分辨率。结果表明,在几乎没有增加额外计算成本的情况下,与现有最先进的基于扩散的即插即用模型相比,方法在定性和定量方面都有明显的改进。
68、Effective Real Image Editing with Accelerated Iterative Diffusion Inversion

尽管近年取得许多进展,但生成模型编辑和处理自然图像仍具有挑战。用生成对抗网络(GAN)时,一个主要障碍在于将真实图像映射到潜空间中的相应噪声向量的逆映射inversion过程,因为要重构图像以编辑其内容。类似地,对于去噪扩散隐式模型(Denoising Diffusion Implicit Models,DDIM),每个逆映射步骤中的线性化假设使整个确定性过程不可靠。已有的解决逆映射稳定性问题的方法,常常在计算效率上存在重大权衡。
这项工作提出AIDI,加速迭代扩散逆映射,在空间和时间复杂性方面显著提高了重构准确性,并且几乎没有额外开销。通过用一种新的混合指导技术,展示了在各种图像编辑任务中可以获得有效结果,并且不需要大型无分类器指导进行逆映射。此外,与其他基于扩散逆映射的工作相比,提出的过程在10和20个扩散步骤的快速图像编辑中显示出更强的稳健性。
69、Not All Steps are Created Equal: Selective Diffusion Distillation for Image Manipulation

条件扩散模型在图像编辑任务中表现出令人印象深刻的性能。一般流程是向图像添加噪声,然后对其进行去噪处理。然而,这种方法面临着一个权衡问题:添加太多噪声会影响图像的保真度,而添加太少会影响其可编辑性。这在很大程度上限制了它们的实际适用性。
本文提出Selective Diffusion Distillation(SDD),可以确保图像的保真性和可编辑性。不是直接用扩散模型对图像进行编辑,而是在扩散模型的指导下训练一个前馈图像处理网络。此外,提出一种有效指标,用于选择与语义相关的时间步,以获取正确的语义指导。这种方法成功地避免了扩散过程造成的困境。广泛实验证明优势。https://github.com/EnVision-Research/Selective-Diffusion-Distillation
70、A Latent Space of Stochastic Diffusion Models for Zero-Shot Image Editing and Guidance

扩散模型通过迭代去噪生成图像。最近研究表明,在使去噪过程确定性的情况下,可以将实际图像编码为相同大小的潜在编码,这可以用于图像编辑。本文探讨在去噪过程仍随机的情况下定义潜空间的可能性。在随机扩散模型中,每个去噪步骤中都添加了高斯噪声,可以将所有噪声连接起来形成一个潜在编码。这导致了比原始图像高得多的潜在空间维度。证明随机扩散模型的这种潜在空间可以在两个应用中与确定性扩散模型的潜在空间相同的方式使用。
提出一种名为CycleDiffusion的零样本和非成对图像编辑方法,使用随机扩散模型的性能优于其确定性对应物。其次,证明了在确定性和随机扩散模型的潜在空间中实现了统一的即插即用的指导。已开源在:https://github.com/humansensinglab/cycle-diffusion
十七、人像生成
71、Controllable Person Image Synthesis with Pose-Constrained Latent Diffusion
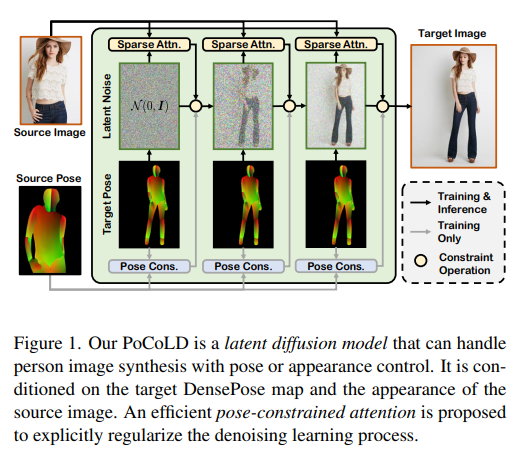
可控人像生成,旨在根据用户指定的身体姿势或外貌变化渲染源图像。先前方法利用基于像素级的去噪扩散模型,并通过交叉注意力对粗略骨架进行条件约束。这导致了两个限制:低效率和不准确的条件信息。
为解决这两个问题,引入了一种新的姿势约束潜在扩散模型(PoCoLD)。与使用骨架作为稀疏姿势表示的方法不同,利用DensePose提供更丰富的身体结构信息。为有效利用DensePose,并且成本较低,提出一种高效的姿势约束注意力模块,能够模拟外貌和姿势之间的复杂相互作用。
实验表明,PoCoLD在图像合成的保真度上优于最先进的竞争方法。关键是,它在推理过程中运行速度比最新的基于扩散模型的替代方法快2倍,并且存储器占用量比最新方法小3.6倍。已开源在:https://github.com/BrandonHanx/PoCoLD
72、HumanSD: A Native Skeleton-Guided Diffusion Model for Human Image Generation

可控人像生成,在现实生活中有很多应用。现有解决方案,如ControlNet和T2I-Adapter,在冻结的预训练扩散(SD)模型之上引入了一个额外的可学习分支,可以强制执行各种条件,包括HIG的骨架指导。尽管这种即插即用的方法很吸引人,但从冻结的SD分支产生的原始图像与给定条件之间的不可避免和不确定的冲突给可学习分支带来了重大挑战,这实质上是为了进行给定条件的图像特征编辑。
这项工作提出一种用于可控HIG的本地骨架引导扩散模型,称为HumanSD。并不通过双分支扩散进行图像编辑,而利用一种新的热图引导去噪损失来对原始SD模型进行微调。这种策略在模型训练过程中有效而高效地加强了给定的骨架条件,并减轻了灾难性遗忘效应。
HumanSD在三个大规模人体中心数据集的组合上进行了微调,这些数据集具有文本-图像-姿势信息,其中两个是在本工作中建立的。在准确的姿势控制和图像质量方面,HumanSD优于ControlNet,特别是当给定的骨架指导复杂时。已开源在:https://github.com/IDEA-Research/HumanSD
十八、人脸识别
73、IDiff-Face: Synthetic-based Face Recognition through Fizzy Identity-Conditioned Diffusion Models
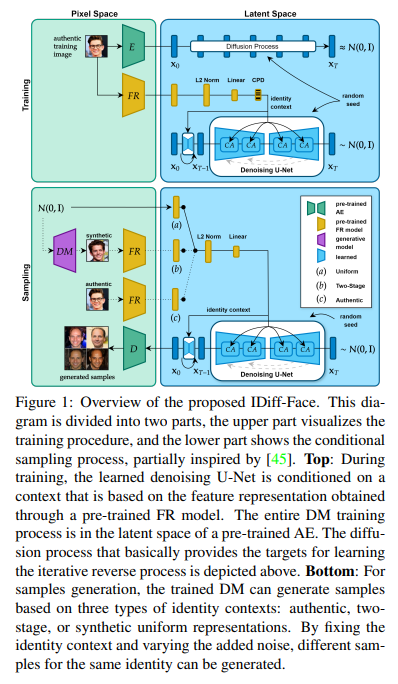
大规模真实人脸数据库的可用性,对过去十年人脸识别研究取得重大进展至关重要。然而,法律和伦理问题导致最近许多这些数据库被创建者撤回,这引发了继续进行人脸识别研究的连续性问题。
生成数据集已成为开发人脸识别的隐私敏感真实数据的有希望的替代方法。然而,最近用于训练人脸识别模型的合成数据集要么在类内多样性上有限,要么在跨类(身份)区分上有所不足,导致准确性不佳,远低于在真实数据上训练的模型所达到的准确度。
本文针对这个问题提出了名为IDiff-Face的新方法,基于条件潜在扩散模型进行合成身份生成,以实现具有真实身份变化的合成数据用于人脸识别训练。通过广泛评估,提出的基于合成的人脸识别方法将先进性能再次提升,例如,在Labeled Faces in the Wild(LFW)基准测试上达到了98.00%的准确率,远远超过最近基于合成的人脸识别解决方案的95.40%,并与基于真实数据的人脸识别的99.82%准确率之间的差距缩小。已开源在:https://github.com/fdbtrs/idiff-face
十九、少样本生成
74、Phasic Content Fusing Diffusion Model with Directional Distribution Consistency for Few-Shot Model Adaption

用有限数量的样本训练生成模型是一项具有挑战性的任务。目前方法主要依赖少样本模型适应来训练网络。然而,在数据极度有限(少于10个)的情况下,生成网络往往容易过拟合并且内容降级。
为了解决这些问题,提出一种新的内容融合少样本扩散模型,结合方向分布一致性损失,在扩散模型的不同训练阶段针对不同的学习目标。具体而言,设计了一种周期性训练策略,利用周期性内容融合来帮助模型在t较大时学习内容和风格信息,在t较小时学习目标域的局部细节,提高对内容、风格和局部细节的捕捉能力。
此外,引入一种新的方向分布一致性损失,以更高效、更稳定地确保生成和源分布之间的一致性,防止模型过拟合。最后,提出一种跨域结构引导策略,在域自适应过程中增强结构一致性。理论分析、定性和定量实验证明了方法在少样本生成模型适应任务中的优越性,与最先进的方法相比。
https://github.com/sjtuplayer/few-shot-diffusion
二十、视频检索
75、DiffusionRet: Generative Text-Video Retrieval with Diffusion Model

现有的文本-视频检索解决方案,本质上是以最大化条件似然概率p(candidates|query)为重点的判别模型。虽然直接,但这种范式忽视了底层的数据分布p(query),使得识别超出分布外的数据具有挑战性。
为解决这个限制,从生成角度处理这个任务,将文本和视频之间的相关性模拟为它们的联合概率p(candidates, query)。通过一种基于扩散的文本-视频检索框架(DiffusionRet)实现,将检索任务建模为逐渐从噪声中生成联合分布的过程。在训练期间,DiffusionRet从生成和判别两个角度优化,生成器通过生成损失进行优化,特征提取器则通过对比损失进行训练。这样,DiffusionRet利用生成和判别方法的优势。
在包括MSRVTT、LSMDC、MSVD、ActivityNet Captions和DiDeMo等五个常用的文本-视频检索基准上进行了大量实验证明了方法有效性,并且在域外检索设置中,DiffusionRet甚至能够表现良好。https://github.com/jpthu17/DiffusionRet
二十一、说话人生成
76、Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors
介绍一种新框架,用于单样本音频驱动的说话头生成(one-shot audiodriven talking head generation)。与以往方法不同,不需要额外的驱动源以确定方式进行控制合成,而是对所有整体上与嘴唇无关的面部动作(如姿势、表情、眨眼、凝视等)进行采样,以与输入音频语义匹配,并保持音频嘴唇同步的逼真和整体自然性。通过新提出的在音频和非嘴唇表示之间映射上训练的音频到视觉扩散先验实现的。
由于扩散先验的概率性质,框架一个重要优势是,它可以在相同的音频片段下合成多样的面部运动序列,这对于许多实际应用非常方便。通过对公共基准的全面评估,得出以下结论:(1)扩散先验在所有相关度量标准上都显著优于自回归先验;(2)整体系统在音频嘴唇同步方面与现有方法相比具有竞争力,但可以有效地采样出与音频输入语义协调的丰富自然的与嘴唇无关的面部动作。
二十二、纹理生成
77、Text2Tex: Text-driven Texture Synthesis via Diffusion Models
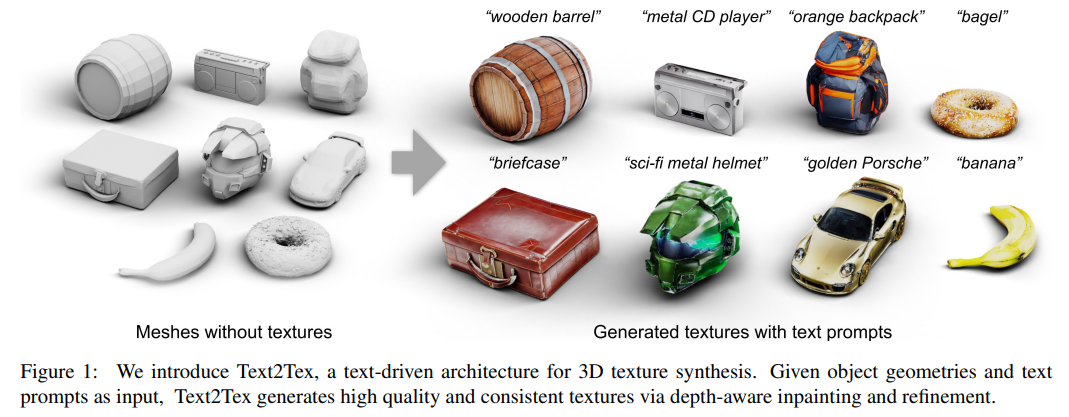
提出一种新方法Text2Tex,从给定的文本提示生成3D网格的高质量纹理。方法将修复嵌入到预训练的深度感知图像扩散模型中,逐步合成来自多个视角的高分辨率部分纹理。
为避免在不同视图之间积累不一致和拉伸的伪影,动态地将渲染视图分割为生成掩模,表示每个可见像素的生成状态。这种分区视图表示引导深度感知修复模型为相应区域生成和更新部分纹理。此外,提出一种自动视图序列生成方案,用于确定更新部分纹理的最佳下一个视图。实验证明方法在纹理驱动的方法和基于GAN的方法上显著优于现有的文本驱动方法。已开源在:https://github.com/daveredrum/Text2Tex
二十三、医学图像
78、DDFM: Denoising Diffusion Model for Multi-Modality Image Fusion
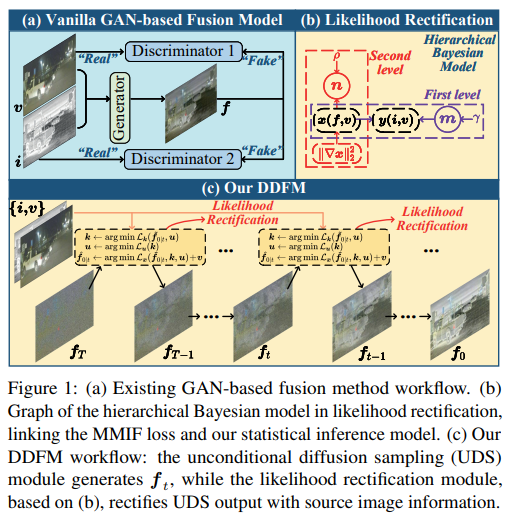
多模态图像融合,旨在将不同模态的图像组合起来,产生保留每种模态的互补特征(如功能亮点和纹理细节)的融合图像。为利用强大的生成先验知识并解决基于GAN的生成方法存在的训练不稳定和缺乏解释性等挑战,提出一种基于去噪扩散概率模型(DDPM)的新型融合算法。
融合任务被构建为基于DDPM采样框架下的条件生成问题,进一步划分为无条件生成子问题和最大似然子问题。后者以潜在变量的分层贝叶斯方式建模,并通过期望最大化(EM)算法进行推断。通过将推断解决方案整合到扩散采样迭代中,方法能够生成具有自然图像生成先验和源图像的跨模态信息的高质量融合图像。需要注意的是,只需要一个无条件预训练的生成模型,无需进行微调。
广泛实验证明,方法在红外-可见图像融合和医学图像融合方面取得有希望的融合效果。https://github.com/Zhaozixiang1228/MMIF-DDFM
79、DOLCE: A Model-Based Probabilistic Diffusion Framework for Limited-Angle CT Reconstruction
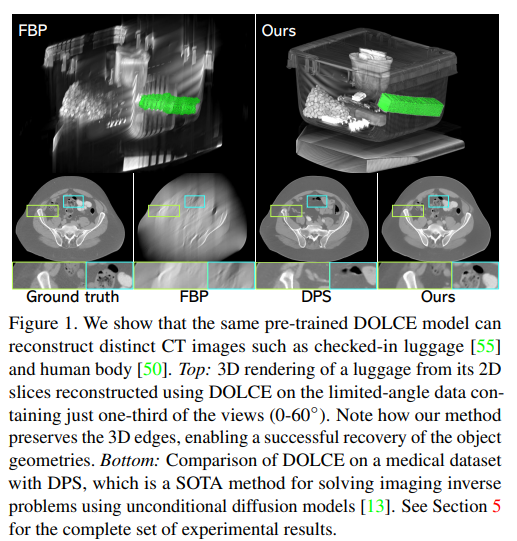
Limited-Angle Computed Tomography 计算机断层扫描(LACT)是一种非破坏性的3D成像技术,广泛应用于从安全领域到医学领域的各种应用。LACT中的有限角度覆盖通常是重建图像中严重伪影的主要来源,使其成为一个具有挑战性的imaging inverse问题。扩散模型是一类最新的深度生成模型,使用图像去噪器合成逼真图像。
这项工作提出DOLCE,第一个集成条件训练的扩散模型和显式物理测量模型以解决imaging inverse的框架。DOLCE通过交替使用以变换后的正弦图对条件化的扩散模型的数据适应性和采样更新,实现了在高度不适定的LACT上的SOTA性能。实验表明,与现有方法不同,DOLCE可以仅用2D条件预训练的扩散模型合成高质量和结构一致的3D体积。进一步在几个具有挑战性的真实LACT数据集上展示,相同预训练的DOLCE模型在截然不同类型的图像上实现了SOTA性能。已开源在:https://github.com/wustl-cig/DOLCE
二十四、鱼眼图像校正
80、Innovating Real Fisheye Image Correction with Dual Diffusion Architecture
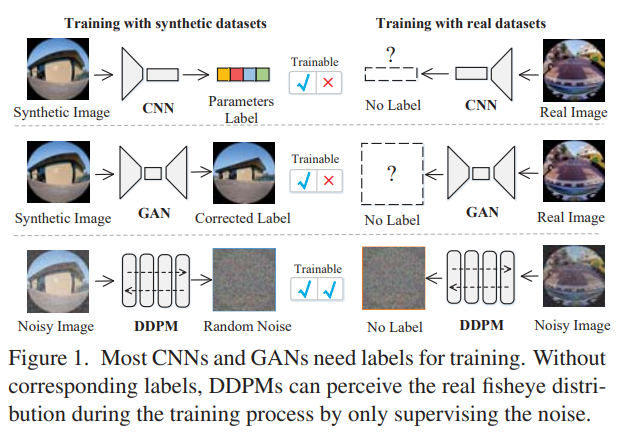
鱼眼图像校正,合成模型在真实场景校正中产生较差结果。为解决这个问题,提出一种双扩散架构(DDA),用于鱼眼校正,具有更好的实用性。DDA利用去噪扩散概率模型(DDPM)逐渐引入双向噪声,使合成图像和真实图像发展成一致的噪声分布。因此,网络能够感知未标记真实鱼眼图像的分布。
此外,设计一种无监督的单通网络,生成一个合理的新条件,来增强引导并解决先验条件和目标之间的非可忽略的不确定性。这可以显著影响校正任务,特别是在径向畸变引起较大伪影的情况下。该网络可以被看作是一种快速产生可靠结果的替代方案,而无需迭代推理。与最先进的方法相比,方法在合成和真实鱼眼图像校正方面取得了优越的性能。
二十五、语音相关
81、DiffV2S: Diffusion-based Video-to-Speech Synthesis with Vision-guided Speaker Embedding
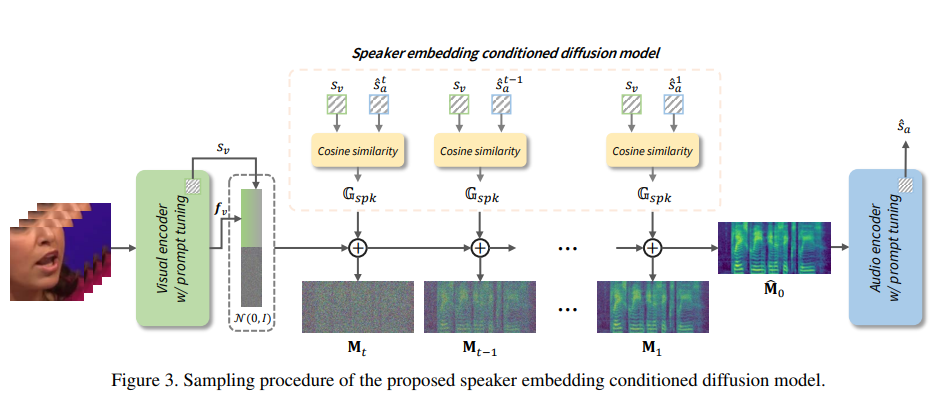
从视觉输入中重建语音,也叫视频到语音合成的课题,由于缺乏足够指导,模型很难能够推断出正确的内容和适当的声音,先前工作一直在准确合成语音方面遇到困难。采用额外扬声器嵌入作为来自参考听觉信息的讲话风格指导。但往往无法从相应的视频输入中获取音频信息。
本文提出一种用自监督预训练模型和prompt tuning技术的新型视觉引导扬声器嵌入提取器(vision-guided speaker embedding extractor)。通过这样做,丰富的扬声器嵌入信息可以完全从输入的视觉信息中产生,而在推断时不需要额外的音频信息。在使用提取的视觉引导扬声器嵌入表示的基础上,进一步开发一种基于扩散的视频到语音合成模型,称为DiffV2S,该模型基于这些扬声器嵌入和从输入视频中提取的视觉表示进行条件设置。
所提出的DiffV2S不仅保留了输入视频帧中的语音细节,还创建了一个高度可理解的mel频谱图,其中多个扬声器的身份都得到了保留。实验结果表明,与先前的视频到语音合成技术相比,DiffV2S实现了最先进的性能。
二十六、对抗相关
82、AdvDiffuser: Natural Adversarial Example Synthesis with Diffusion Models
先前关于对抗样本的工作,常涉及固定的规范扰动,这不能捕捉到人们感知扰动的方式。最近工作转向了自然非限制性的对抗样本(natural unrestricted adversarial examples,UAEs)。目前方法用GAN或VAE通过扰动潜在编码生成UAEs。然而,这会导致高级信息的丢失,从而产生低质量和不自然的UAEs。
提出AdvDiffuser,一种用扩散模型合成自然UAEs的新方法。它可以从头开始生成UAEs,也可以根据参考图像进行条件合成。为生成自然的UAEs,通过扰动预测的图像将其潜在编码引导到特定分类器的对抗样本空间。还提出基于类激活映射的对抗修复,以保留图像的显著区域,同时扰动不重要的区域。在CIFAR-10、CelebA和ImageNet上,展示了能够以近100%的成功率击败RobustBench排行榜上最强大的模型。此外,与当前最先进的攻击相比,合成的UAEs不仅更加自然,而且更强大。
83、Robust Evaluation of Diffusion-Based Adversarial Purification
基于扩散的purification方法旨在在测试时从输入数据中去除对抗性效应,本文对扩散purification方法的评估实践提出质疑。由于训练和测试之间的分离,这种方法越来越受到关注。通常用白盒攻击来测量purification的鲁棒性。然而,尚不清楚这些攻击是否对扩散purification有效,因为这些攻击通常是为对抗性训练量身定制的。
分析当前的实践并提供了一个新的指导方针,用于衡量purification方法在对抗性攻击的鲁棒性。基于分析,进一步提出一种新的purification策略,提高鲁棒性。
二十七、图像超分
84、HSR-Diff: Hyperspectral Image Super-Resolution via Conditional Diffusion Models
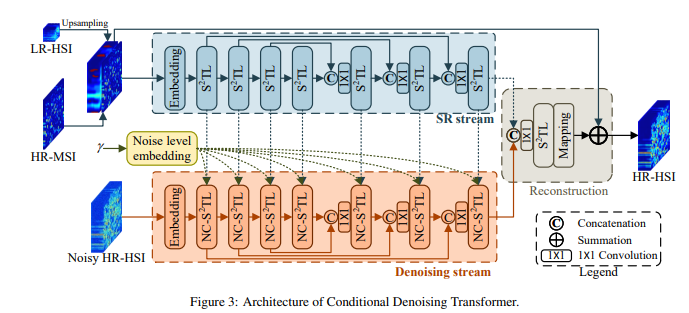
尽管高光谱图像(hyperspectral image,HSIs)在执行各种计算机视觉任务中的重要性已被证明,但由于在空间域中具有低分辨率(LR)属性,其潜力受到不利影响,这是由多种物理因素引起的。
受到深度生成模型最新进展的启发,提出一种基于条件扩散模型的HSI超分辨率(SR)方法,称为HSR-Diff,将高分辨率(HR)多光谱图像(MSI)与相应的LR-HSI合并。HSR-Diff通过重复精化生成HR-HSI,其中HR-HSI通过纯高斯噪声进行初始化,并进行迭代精化。在每次迭代中,使用基于条件的去噪变换器(CDFormer)去除噪声,该变换器在不同噪声水平下训练,并以HR-MSI和LR-HSI的分层特征图为条件。此外,采用渐进学习策略来利用全分辨率图像的全局信息。在四个公共数据集上进行了系统性实验,结果表明HSR-Diff优于现有方法。
二十八、图像恢复
85、DDS2M: Self-Supervised Denoising Diffusion Spatio-Spectral Model for Hyperspectral Image Restoration
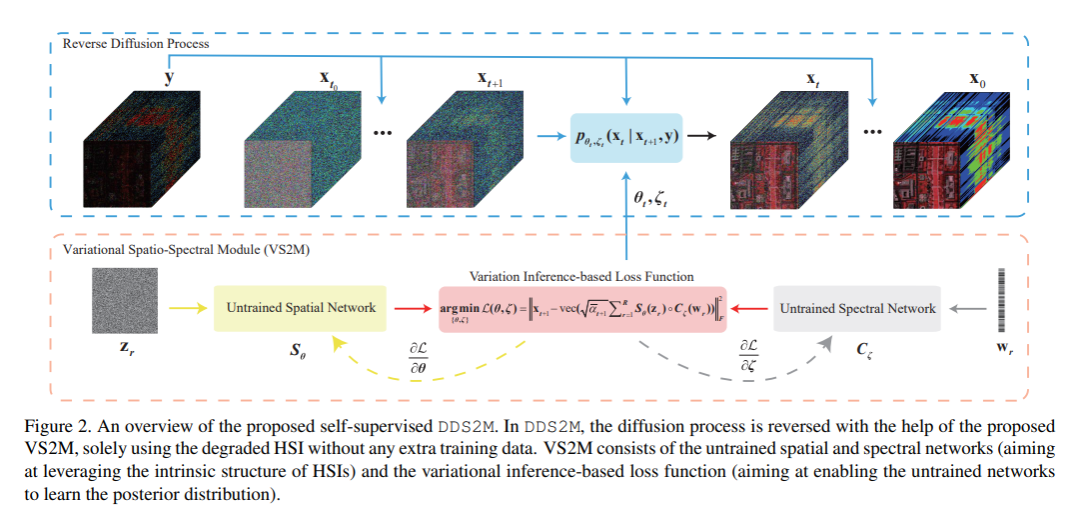
扩散模型近来受到极大关注,其在图像恢复方面表现出色,尤其是在噪声鲁棒性方面。然而,现有基于扩散的方法是在大量训练数据上训练的,并且在分布内表现非常好,但对分布的转移很敏感。这对于缺乏数据的高光谱图像(HSI)恢复尤为不适用。
为解决这个问题,本研究提出一种用于HSI恢复的自监督扩散模型,即去噪扩散空间-光谱模型(DDS2M),它通过在逆向扩散过程中推断出所提出的变分空间-光谱模块(VS2M)的参数来工作,仅使用受损HSI而没有任何额外的训练数据。在VS2M中,使用变分推断的损失函数被定制为使未经训练的空间和光谱网络能够学习后验分布,该分布用作采样链的转换,帮助逆向扩散过程。由于其自监督性质和扩散过程的优势,DDS2M对各种HSI具有更强的泛化能力,与现有的基于扩散的方法相比,对噪声具有更强的鲁棒性。在多种HSI的去噪、有噪HSI完成和超分辨率方面进行了广泛实验,结果表明DDS2M优于现有的任务特定最先进技术。已开源在:https://github.com/miaoyuchun/DDS2M
86、DiFaReli: Diffusion Face Relighting

提出一种新方法来处理自然场景中单视角人脸重打光(single-view face relighting)问题。在人脸重打光中,处理非漫反射效应(如全局照明或投影阴影)一直是个挑战。之前工作通常假设Lambertian surfaces、简化的光照模型或涉及估计3D形状、反照率或阴影图。然而,这种估计往往容易出错,并且需要很多带有光照真值的训练样本才能很好地推广。
本文仅用二维图像进行训练,无需任何光照设备数据、多视图图像或光照真值。关键思想是利用条件扩散隐式模型(DDIM)来解码解缠的光照编码以及从现成的估计器中推断出的与3D形状和面部身份相关的其他编码。还提出一种新条件技术,通过使用渲染的阴影参考空间调制DDIM,从而简化了光照和几何之间复杂相互作用的建模过程。在标准基准数据集Multi-PIE上实现最先进的性能,并能够对自然场景图像进行逼真的光照调整。已开源在:https://github.com/diffusion-face-relighting/difareli_code
87、DiffIR: Efficient Diffusion Model for Image Restoration

图像恢复(image restoration,IR)中,传统的DM在大型模型上运行大量迭代以估计整个图像或特征图是低效的。为解决这个问题,提出一种高效的IR扩散模型(DiffIR),包括紧凑的IR先验提取网络(IR prior extraction network,CPEN)、dynamic IR transformer(DIRformer)和去噪网络。
具体而言,DiffIR有两个训练阶段:预训练和训练DM。在预训练中,将真实图像输入到CPENS1中,以捕获紧凑的IR先验表示(IPR)来指导DIRformer。在第二阶段,训练DM直接估计与预训练的CPENS1相同的IRP,只使用LQ图像。观察到,由于IPR只是一个紧凑的向量,DiffIR可以使用比传统DM更少的迭代次数来获得准确的估计并生成更稳定和逼真的结果。
由于迭代次数很少,DiffIR可以对CPENS2、DIRformer和去噪网络进行联合优化,从而进一步降低估计误差的影响。在几个IR任务上进行大量实验证明,并在消耗更少的计算成本的同时实现最先进的性能。已开源在:https://github.com/Zj-BinXia/DiffIR
88、Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model

本文重新思考低光图像增强任务,并提出一种基于物理可解释性和生成扩散模型的低光图像增强方法,称为Diff-Retinex。旨在结合物理模型和生成网络的优势。此外,希望通过生成网络补充甚至推断出低光图像中丢失的信息。因此,Diff-Retinex将低光图像增强问题转化为Retinex分解和条件图像生成问题。
在Retinex分解中,将Transformer中的注意力优越性与精心设计的Retinex Transformer分解网络(TDN)相结合,将图像分解为照明和反射图。然后,设计多路径生成扩散网络来重建正常光照的Retinex概率分布,并分别解决这些组成部分的各种退化问题,包括暗照明、噪声、颜色偏差、场景内容丢失等等。由于生成扩散模型,Diff-Retinex能够实现低光细节的恢复。在现实低光数据集上进行广泛实验,定性和定量证明所提方法有效性、优越性和泛化性。
89、Towards Authentic Face Restoration with Iterative Diffusion Models and Beyond

在许多计算机视觉应用中,如图像增强、视频通信和肖像摄影,需要一个真实的面部修复系统。大多数先进的面部修复模型可以从低质量的面部图像中恢复出高质量的面部,但通常不能真实地生成用户喜欢的逼真和高频细节。
为实现真实的修复,提出一种基于去噪扩散模型(DDM)的迭代学习面部修复系统(IDM)。定义了真实面部修复系统的标准,并认为去噪扩散模型天生具有两个方面的这一特性:内在迭代细化和外在迭代增强。内在学习可以很好地保留内容并逐渐改进高质量的细节,而外在增强有助于清理数据并进一步改善修复任务。在盲面部修复任务中展示了优越的性能。
除了修复之外,发现所提修复系统通过修复干净的数据还有助于图像生成任务,具有训练稳定性和样本质量方面的优势。在不修改模型的情况下,在FFHQ和ImageNet生成任务中使用GAN或扩散模型的质量比最先进方法更好。
二十九、图像去模糊
90、Multiscale Structure Guided Diffusion for Image Deblurring

扩散概率模型(DPMs)已被用于图像去模糊,构建成一个以模糊输入为条件的图像生成过程,将高斯噪声映射到高质量图像上。与基于回归的方法相比,基于图像条件的DPM(icDPM)在对配对的域内数据进行训练时展现出更逼真的结果。然而,当面临域外图像时,它们在恢复图像方面的鲁棒性尚不清楚,因为它们没有施加特定的退化模型或中间约束条件。
引入一个简单而有效的多尺度结构引导作为隐式偏差,向icDPM提供了有关中间层锐利图像的粗略结构信息。这种引导形式显著改善了去模糊结果,特别是在未知领域上。引导信息是从回归网络的潜在空间中提取的,该回归网络在多个较低分辨率下训练,从而保持最显著的锐利结构。有了模糊输入和多尺度引导,icDPM模型可以更好地理解模糊并恢复清晰图像。
在多样化数据集上评估单数据集训练模型,以及在未见数据上展现出更强的去模糊结果和更少的伪影。方法超过了现有的基线方法,在保持竞争性畸变度量的同时实现了最先进的知觉质量。
三十、分布外检测/迁移学习
91、Deep Feature Deblurring Diffusion for Detecting Out-of-Distribution Objects
为了推广检测器的安全应用,最近提出了一项无监督的超出分布对象检测(OOD-OD)任务,其目标是在不访问任何辅助OOD数据的情况下检测未见过的OOD对象。对这个任务,挑战主要在于如何仅利用已知的分布(ID)数据准确地检测OOD对象,而不影响ID对象的检测,这可以被视为深层特征合成问题。因此,这个挑战可以通过扩散模型中的前向和反向过程来解决。
本文提出一种新的深度特征去模糊扩散(DFDD)方法,包括前向模糊和反向去模糊过程。具体来说,前向过程逐渐对提取的特征执行高斯模糊,这对于保留足够的输入相关信息至关重要。通过这种方式,前向过程可以合成接近于ID和OOD对象之间分类边界的虚拟OOD特征,从而提高检测OOD对象的性能。在反向过程中,基于模糊特征,设计了一个专门的去模糊模型来持续恢复前向过程中丢失的细节。去模糊特征和原始特征都被用作训练的输入,增强了区分能力。
实验中,方法在OOD-OD、开放集对象检测和增量对象检测上进行了评估。与基线方法相比,显著的性能提升说明了方法优势。
三十一、阴影去除
92、Boundary-Aware Divide and Conquer: A Diffusion-based Solution for Unsupervised Shadow Removal
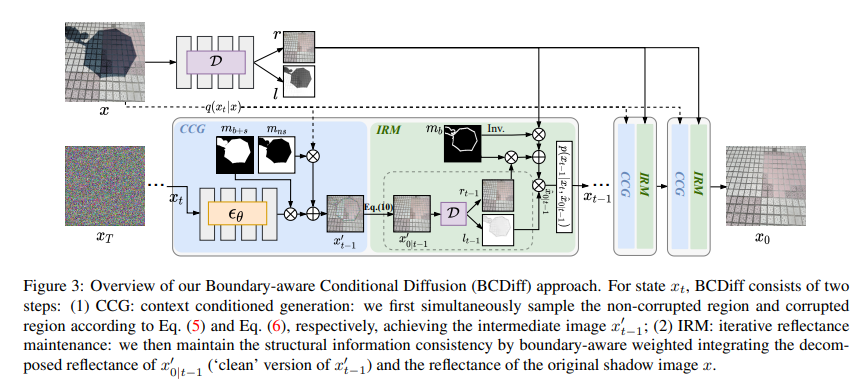
最近的深度学习方法在去除阴影方面取得优秀结果。然而,大多数这些监督方法依赖于对大量阴影和无阴影图像对进行训练,这需要繁琐的注释并可能导致模型泛化性差。事实上,阴影只在图像中形成局部的退化,而它们的非阴影区域为无监督学习提供了丰富的结构信息。
本文提出一种新的基于扩散的无监督阴影去除解决方案,用于分别建模阴影、非阴影和它们的边界区域。使用预训练的无条件扩散模型与未受损信息融合,生成自然无阴影图像。虽然扩散模型可以通过利用其相邻的未受损上下文信息来恢复边界区域的清晰结构,但由于非受损上下文的隔离,它无法处理阴影内部区域。因此,进一步提出一个阴影不变内在分解模块,以利用阴影区域中的基本反射来在扩散采样过程中保持结构一致性。
公开可用的阴影去除数据集的实验,证明方法的显著改进,甚至与一些现有的监督方法相当。
三十二、图像延展/图像外修复
93、DiffDreamer: Towards Consistent Unsupervised Single-view Scene Extrapolation with Conditional Diffusion Models

场景外推/外插值/外延/外修复(Scene extrapolation)是生成新视图的思路,一项有前途但具有挑战性的任务。对于每个预测帧,需要解决一个联合修复和三维细化问题,该问题具有不适定性和很高的歧义性。此外,长距离场景的训练数据很难获得,并且通常缺乏足够的视图来推断准确的相机姿态。
引入了DiffDreamer,一个无监督框架,能够仅用自然场景的互联网采集图像进行训练,合成描述长摄像机轨迹的新视图。利用引导去噪步骤的随机特性,训练扩散模型来优化投影的RGBD图像,但在推断过程中将去噪步骤与多个过去和未来帧相关联。证明图像条件化的扩散模型可以有效地进行长距离场景外推,并且相较于基于GAN的先前方法能够更好地保持一致性。
DiffDreamer是一个功能强大且高效的场景外推解决方案,尽管受到了有限的监督,但产生了令人印象深刻的结果。
三十三、图像组合
94、TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition

扩散模型展示令人印象深刻的生成能力,使得各种图像编辑任务成为可能。本文提出TF-ICON,一种全新的无需训练的图像组合框架,利用了文字驱动的扩散模型的强大能力,实现不同领域的跨域图像组合(crossdomain image-guided composition)。
任务旨在将用户提供的对象无缝地融入到特定的视觉环境中。目前,基于扩散的方法往往涉及昂贵的基于实例的优化或在定制数据集上微调预训练模型,这可能削弱其丰富的先验知识。相比之下,TF-ICON可以利用现成的扩散模型进行跨域图像导向组合,无需额外的训练、微调或优化。此外,介绍一个特殊的提示,它不包含任何信息,可以帮助准确地将真实图像反转为潜在表示,为组合提供基础。
实验证明,将扩散与特殊提示结合使用优于各种数据集(CelebA-HQ、COCO和ImageNet)上的先进反转方法,TF-ICON在多样的视觉领域中超过了基线方法。已开源在:https://github.com/Shilin-LU/TF-ICON
三十四、视图生成
95、Generative Novel View Synthesis with 3D-Aware Diffusion Models

提出一种基于扩散的模型,用于从仅一个输入图像生成具有3D感知的新视图。模型从与输入一致的可能渲染分布中进行采样,并且即使在存在不确定性的情况下,也能生成多样且合理的新视图。
方法利用了现有的2D扩散骨架,但关键在于将几何先验引入到3D特征体中。这个潜在的特征场捕获了可能的场景表示分布,并提高了方法生成符合视图一致性要求的新渲染的能力。除生成新视图,方法还能够自回归地合成具有3D一致性的序列。
在合成渲染和室内场景方面展示了最先进的结果;展示了对于具有挑战性的真实世界对象的引人注目的结果。
96、Long-Term Photometric Consistent Novel View Synthesis with Diffusion Models

从单个输入图像生成新视图,是一项具有挑战性的任务。合成任务的高度不确定性,由场景内未观察到的元素(即遮挡)和观察区域之外的元素引起,因此用生成模型能够捕获可能输出的多样性是有吸引力的。
本文提出一种新生成模型,能根据指定的相机轨迹和单个起始图像生成一系列与之一致的照片级真实图像。方法基于自回归条件化的基于扩散的模型,能够插值可见场景元素,并以几何一致的方式外推视图中未观察到的区域。条件限制于捕获单个相机视图的图像和新相机视图的(相对)姿态。为了衡量生成视图序列的一致性,引入一种新的度量标准——阈值对称极线距离(TSED),用于衡量序列中一致的帧对数。
尽管先前的方法已被证明能够产生高质量的图像和一致的语义视图对,但用本文度量标准在实证上证明它们通常与所需的相机姿态不一致。证明方法能够生成既逼真又视图一致的图像。已开源在:https://github.com/YorkUCVIL/Photoconsistent-NVS
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!



