
热门标签
热门文章
- 1C++简单实现LRU缓存结构_lru缓存结构 c++
- 2Python_Redis使用_python redis库
- 3四辆小车,每辆车加满油可以走一公里,问怎么能让一辆小车走最远
- 4【数据结构-D】链表之单链表知识点梳理_非循环链表的最后一个元素的后继指针是什么
- 5python queue 生产者 消费者_Python 队列queue与多线程组合(生产者+消费者模式)
- 6Flink Standalone集群部署和任务提交
- 7Python 异步 redis_redis.asyncio
- 8macOS上如何安装(不需要编译安装或者brew)、使用ffmpeg转码的教程,以及如何使用硬件加速_macos mkv解码器
- 9Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling论文阅读
- 10区块链 | IPFS 工作原理入门_区块链与ipfs
当前位置: article > 正文
Sqoop Import HDFS
作者:你好赵伟 | 2024-06-09 09:05:21
赞
踩
sqoop import hdfs
Sqoop import应用场景——密码访问
注:测试用表为本地数据库中的表
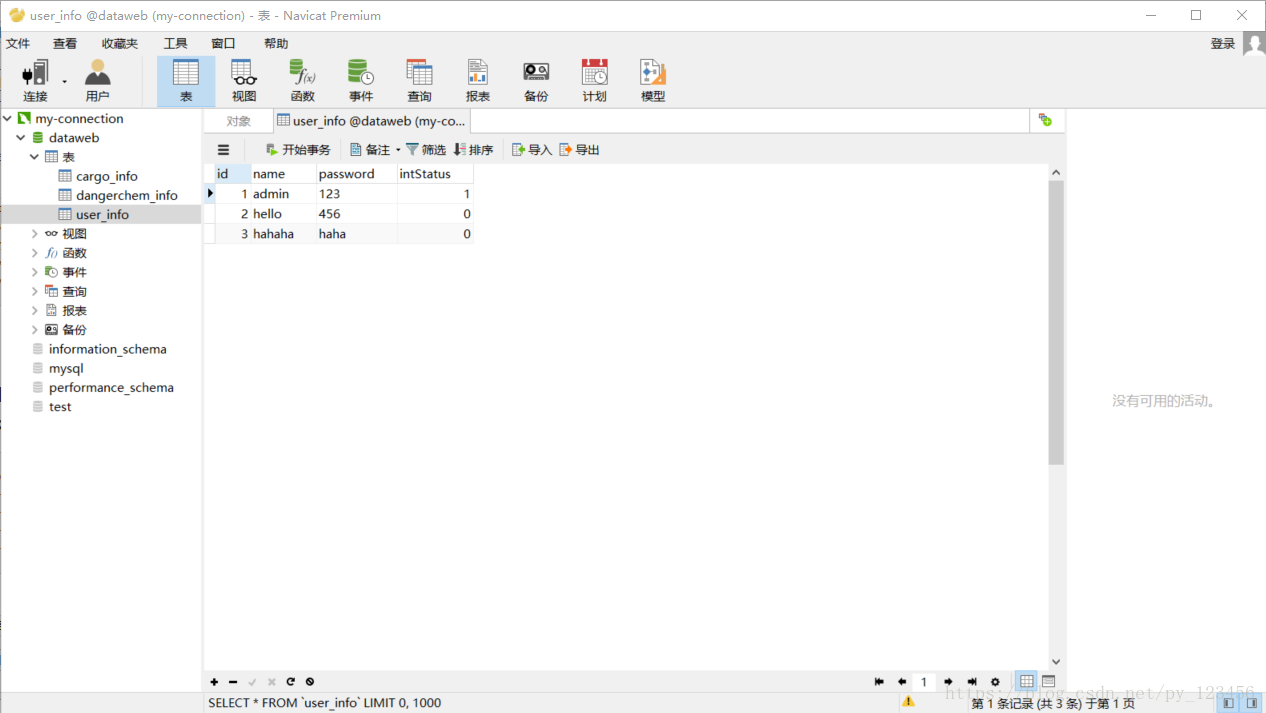
1.明码访问
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password 20134997- 1
- 2
- 3
- 4
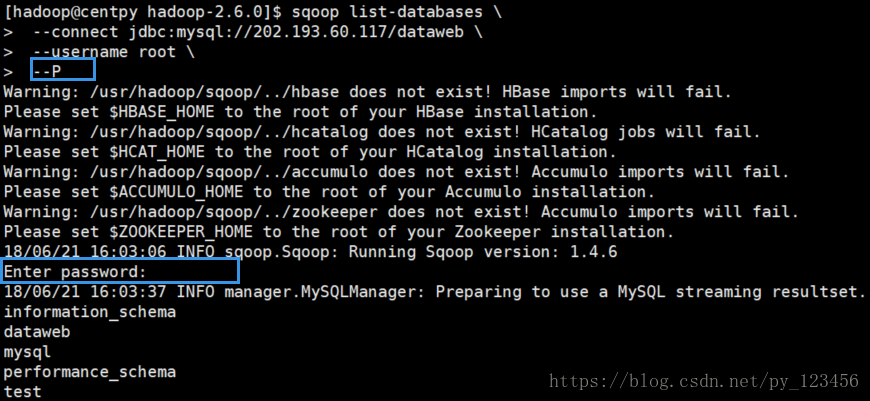
2.交互式密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--P- 1
- 2
- 3
- 4
3.文件授权密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /usr/hadoop/.password- 1
- 2
- 3
- 4
在运行之前先要在指定路径下创建.password文件。
[hadoop@centpy ~]$ cd /usr/hadoop/
[hadoop@centpy hadoop]$ ls
flume hadoop-2.6.0 sqoop
[hadoop@centpy hadoop]$ echo -n "20134997" > .password
[hadoop@centpy hadoop]$ ls -a
. .. flume hadoop-2.6.0 .password sqoop
[hadoop@centpy hadoop]$ more .password
20134997
[hadoop@centpy hadoop]$ chmod 400 .password //根据官方文档说明赋予400权限- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试运行之后一定会报以下错误:
18/06/21 16:12:48 WARN tool.BaseSqoopTool: Failed to load password file
java.io.IOException: The provided password file /usr/hadoop/.password does not exist!
at org.apache.sqoop.util.password.FilePasswordLoader.verifyPath(FilePasswordLoader.java:51)
at org.apache.sqoop.util.password.FilePasswordLoader.loadPassword(FilePasswordLoader.java:85)
at org.apache.sqoop.util.CredentialsUtil.fetchPasswordFromLoader(CredentialsUtil.java:81)
at org.apache.sqoop.util.CredentialsUtil.fetchPassword(CredentialsUtil.java:66)
at org.apache.sqoop.tool.BaseSqoopTool.applyCredentialsOptions(BaseSqoopTool.java:1040)
at org.apache.sqoop.tool.BaseSqoopTool.applyCommonOptions(BaseSqoopTool.java:995)
at org.apache.sqoop.tool.ListDatabasesTool.applyOptions(ListDatabasesTool.java:76)
at org.apache.sqoop.tool.SqoopTool.parseArguments(SqoopTool.java:435)
at org.apache.sqoop.Sqoop.run(Sqoop.java:131)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227)
at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
Error while loading password file: The provided password file /usr/hadoop/.password does not exist!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
为了解决该错误,我们需要将.password文件放到HDFS上面去,这样就能找到该文件了。
[hadoop@centpy hadoop]$ hdfs dfs -ls /
Found 12 items
drwxr-xr-x - Zimo supergroup 0 2018-05-12 10:57 /actor
drwxr-xr-x - Zimo supergroup 0 2018-05-08 16:51 /counter
drwxr-xr-x - hadoop supergroup 0 2018-06-19 15:55 /flume
drwxr-xr-x - hadoop hadoop 0 2018-04-14 14:20 /hdfsOutput
drwxr-xr-x - Zimo supergroup 0 2018-05-12 15:01 /join
drwxr-xr-x - hadoop supergroup 0 2018-04-25 10:43 /maven
drwxr-xr-x - Zimo supergroup 0 2018-05-09 09:32 /mergeSmallFiles
drwxrwxrwx - hadoop supergroup 0 2018-04-13 22:10 /phone
drwxr-xr-x - hadoop hadoop 0 2018-04-14 14:43 /test
drwx------ - hadoop hadoop 0 2018-04-13 22:10 /tmp
drwxr-xr-x - hadoop hadoop 0 2018-04-14 14:34 /weather
drwxr-xr-x - hadoop hadoop 0 2018-05-07 10:44 /weibo
[hadoop@centpy hadoop]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -put .password /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -chmod 400 /user/hadoop/.password- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
现在测试运行一下,注意路径改为HDFS上的/user/hadoop。
[hadoop@centpy hadoop-2.6.0]$ sqoop list-databases --connect jdbc:mysql://202.193.60.117/dataweb --username root --password-file /user/hadoop/.password
Warning: /usr/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
18/06/21 16:22:12 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
18/06/21 16:22:14 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
dataweb
mysql
performance_schema
test- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
可以看到成功了。
Sqoop import应用场景——导入全表
1.不指定目录
sqoop import \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /user/hadoop/.password \
--table user_info- 1
- 2
- 3
- 4
- 5
运行过程如下
18/06/21 16:36:20 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/06/21 16:36:24 INFO db.DBInputFormat: Using read commited transaction isolation
18/06/21 16:36:24 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `user_info`
18/06/21 16:36:25 INFO mapreduce.JobSubmitter: number of splits:3
18/06/21 16:36:25 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1529567189245_0001
18/06/21 16:36:26 INFO impl.YarnClientImpl: Submitted application application_1529567189245_0001
18/06/21 16:36:27 INFO mapreduce.Job: The url to track the job: http://centpy:8088/proxy/application_1529567189245_0001/
18/06/21 16:36:27 INFO mapreduce.Job: Running job: job_1529567189245_0001
18/06/21 16:36:45 INFO mapreduce.Job: Job job_1529567189245_0001 running in uber mode : false
18/06/21 16:36:45 INFO mapreduce.Job: map 0% reduce 0%
18/06/21 16:37:11 INFO mapreduce.Job: map 33% reduce 0%
18/06/21 16:37:12 INFO mapreduce.Job: map 67% reduce 0%
18/06/21 16:37:13 INFO mapreduce.Job: map 100% reduce 0%
18/06/21 16:37:14 INFO mapreduce.Job: Job job_1529567189245_0001 completed successfully
18/06/21 16:37:14 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=371994
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=295
HDFS: Number of bytes written=44
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=3
Other local map tasks=3
Total time spent by all maps in occupied slots (ms)=70339
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=70339
Total vcore-seconds taken by all map tasks=70339
Total megabyte-seconds taken by all map tasks=72027136
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=295
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=2162
CPU time spent (ms)=3930
Physical memory (bytes) snapshot=303173632
Virtual memory (bytes) snapshot=6191120384
Total committed heap usage (bytes)=85327872
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=44
18/06/21 16:37:14 INFO mapreduce.ImportJobBase: Transferred 44 bytes in 54.3141 seconds (0.8101 bytes/sec)
18/06/21 16:37:14 INFO mapreduce.ImportJobBase: Retrieved 3 records.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
再查看一下HDFS下的运行结果
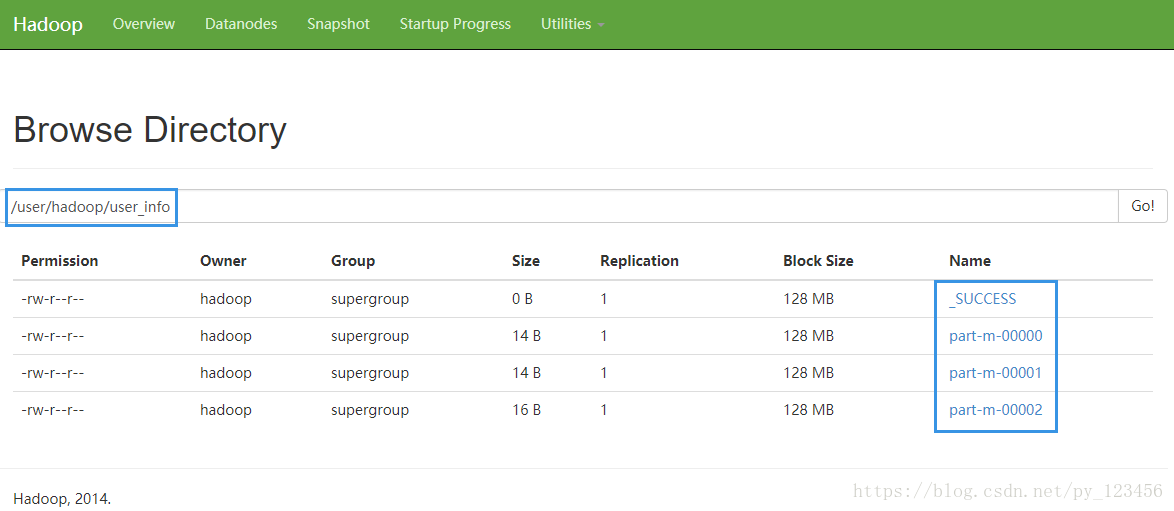
[hadoop@centpy hadoop-2.6.0]$ hdfs dfs -cat /user/hadoop/user_info/part-m-*
1,admin,123,1
2,hello,456,0
3,hahaha,haha,0- 1
- 2
- 3
- 4
运行结果和数据库内容匹配。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/693398
推荐阅读
相关标签

