
- 1资源分配 (c实现)_请使用c语言动态规划策略编写算法,实现资源分配问题。要求:输入资源个数与资金金
- 2[Java反序列化]JavaCC链学习(8u71前)_java8u71版本之前
- 3【git】恢复因git reset --hard 但未提交全部文件到仓库导致的文件丢失问题_git reset --hard 文件去哪了
- 4大数据技术应用4-2MapRuduce编程组件、运行模式、性能优化策略_mapreduce编程组件中,哪个组件主要用于描述输入数据的格式,什么组件主要用于
- 5【网络信息安全】身份认证
- 6教你用Python画哆啦A梦、海绵宝宝、皮卡丘、史迪仔!(附完整源码)_python哆啦a梦代码
- 7sklearn中TF-IDF值的计算方式_如何计算 seo tf-idf sklearn
- 8手把手教你:个人信贷违约预测模型
- 9探索Go与Web的无缝融合:golang-wasm-example项目深度解析与推荐
- 10MySQL-触发器:触发器概述、触发器的创建、查看删除触发器、 触发器的优缺点_mysql 创建触发器
一文看懂时序预测 or 销量预测场景下的的评估指标_销量预测模型的评价指标
赞
踩
前言
在时序预测或者销量预测场景中,我们会通过确定一些准确率指标来评估我们的预测值。在学术界和工业界,我们常用指标有:均方根误差(RMSE)、加权分位数损失(wQL)、平均绝对百分比误差(MAPE)、平均绝对缩放误差(MASE)、加权绝对百分比误差。本文将会详细介绍这些指标的具体含义和计算逻辑,以及适应的应用场景。
1.加权分位数损失(wQL)
wQL可以在指定的分位数下衡量模型的准确性,当低估和预测偏高有不同的成本时,这个指标尤其有用。我们通过设置权重 τ \tau τ的wQL函数,对于低估和预测偏高可以纳入不同的处罚权重,损失函数的计算方法如下:
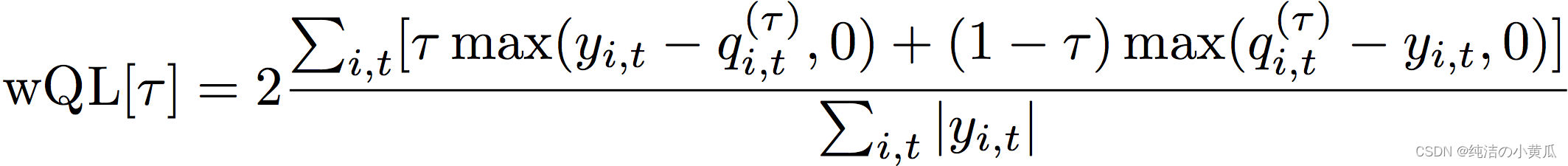
其中
τ
\tau
τ:代表集合中的分位数
q
i
,
t
τ
q_{i,t^{\tau}}
qi,tτ:代表模型预测的分位数
y
i
.
t
y_{i.t}
yi.t:代表t时刻第i个观测值
wQL的分位数( τ \tau τ)范围可以在0.1(P10)和0.99(P90)之间,一般来讲,我们会计算P10,P50,P90。
-
P10 (0.1)-预期真实值将在 10% 的时间内低于预测值。
-
P50 (0.5)-预期真实值将在 50% 的时间内低于预测值。这也称作预测中位数。
-
P90 (0.9)-预期真实值将在 90% 的时间内低于预测值。
在零售业,库存不足的成本通常高于库存积压的成本,因此预测 P75(τ= 0.75)可能比在中位数分位数(P50)上的预测更具信息性。在这些情况下,WQL [0.75] 为预测不足分配更大的罚款权重 (0.75),对过度预测分配较小的罚款权重 (0.25)。
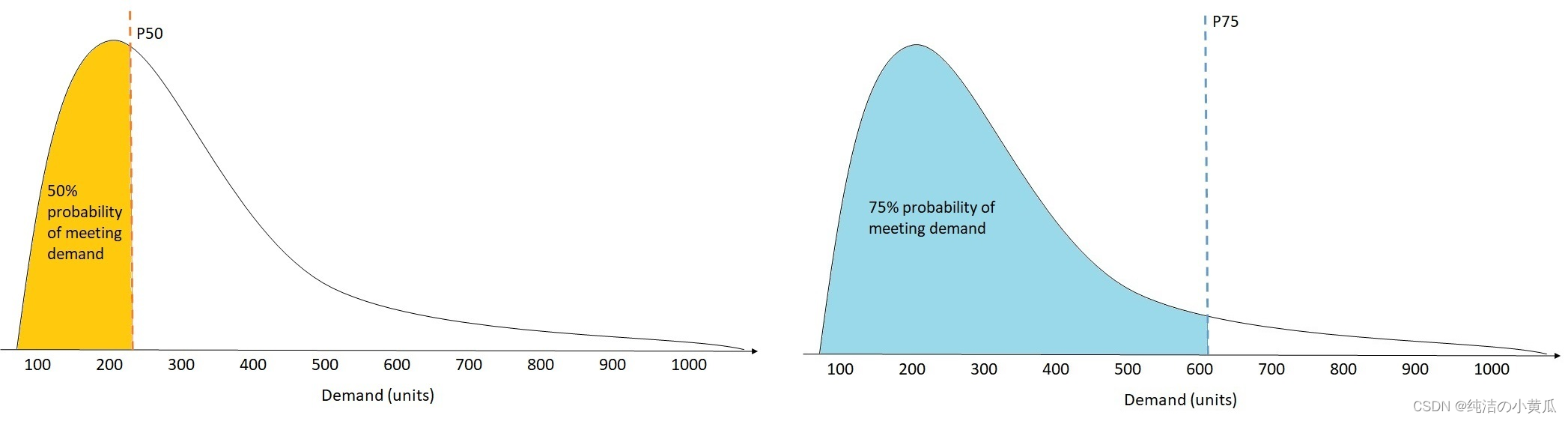
上图显示了 wQL [0.50] 和 wQL [0.75] 的不同需求预测。P75 的预测值明显高于 P50 的预测值,因为 P75 预测预计将在 75% 的时间内满足需求,而 P50 预测预计只能满足 50% 的需求。
当给定反向测试窗口中的所有项和时间点上的观测值的总和大约为零时,加权分位数损失表达式是未定义的。在这些情况下,Forecast 将输出未加权分位数损失,这是 wQL 表达式中的分子。
Forecast 还计算平均 wQL,这是所有指定分位数的加权分位数损失的平均值。默认情况下,这将是 ql0.10]、wQL [0.50] 和 wQL [0.90] 的平均值。
2.加权绝对百分比误差(WAPE)
加权绝对百分比误差 (WAPE) 是衡量预测值与观测值的总体偏差。WAPE 的计算方法是取观测值和预测值的总和,然后计算这两个值之间的误差。值越低表示模型更准确。
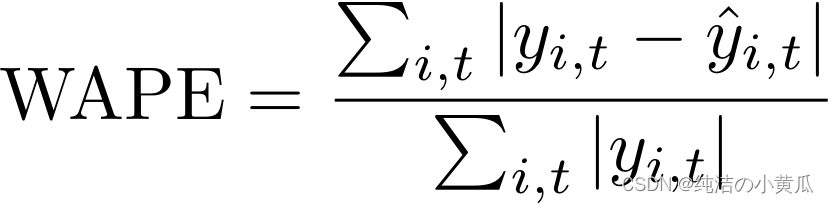
其中,
y
i
,
t
y_{i,t}
yi,t:代表t时刻第i个观测值
y
^
i
,
t
\hat{y}_{i,t}
y^i,t:代表t时刻第i个预测值
如上公式所示,当观测值总和为零时,分母为零,此时WAPE的计算公式是无意义的,因此我们只输出分子的总和。
3.均方根误差(RMSE)
均方根误差 (RMSE) 是平方误差平均值的平方根,因此对异常值比其他准确度指标更敏感。值越低表示模型更准确。
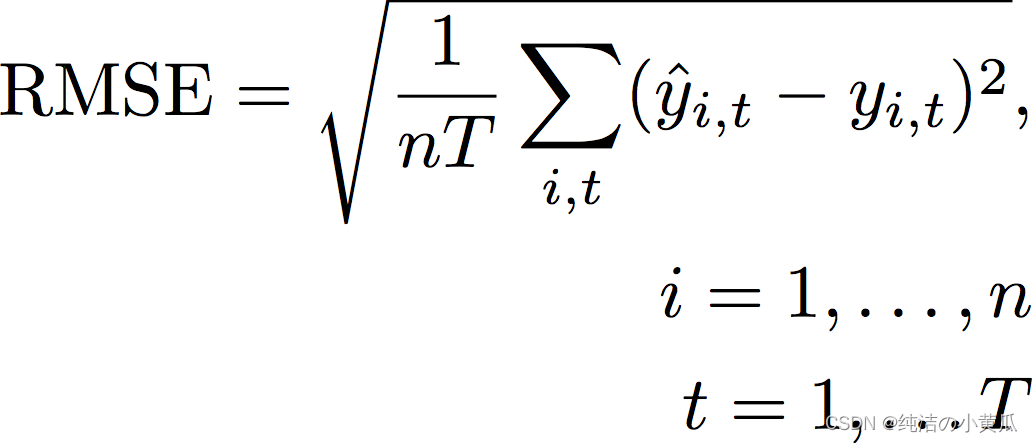
其中,
y
i
,
t
y_{i,t}
yi,t:代表t时刻第i个观测值
y
^
i
,
t
\hat{y}_{i,t}
y^i,t:代表t时刻第i个预测值
n
T
nT
nT代表测试集中的数据点数
RMSE 使用残差的平方值,这会放大异常值的影响。在一些预测极其异常且代价昂贵的场景中,RMSE 是更相关的指标。
4.平均绝对误差(MAE)
平均绝对误差(MAE), 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度度越高。
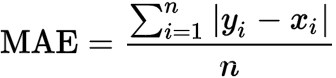
其中,
y
i
y_{i}
yi:代表第i个观测值
y
^
i
\hat{y}_{i}
y^i:代表第i个预测值
n
n
n代表时间窗口内的数据点数
5.平均百分比误差(MAPE)
平均绝对百分比误差 (MAPE) 取每个时间单位的观测值和预测值之间的百分比误差的绝对值,然后平均这些值。值越低表示模型更准确。
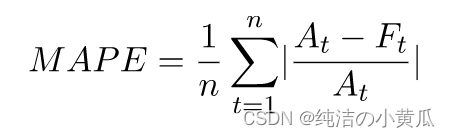
其中,
y
i
,
t
y_{i,t}
yi,t:代表t时刻第i个观测值
y
^
i
,
t
\hat{y}_{i,t}
y^i,t:代表t时刻第i个预测值
n
n
n代表时间窗口内的数据点数
MAPE 对于时间点之间的值差异显著且异常值具有显著影响的情况非常有用。
6.平均绝对缩放误差(MASE)
平均绝对缩放误差 (MASE) 的计算方法是将平均误差除以缩放因子。这个比例因素取决于季节性值,m,根据预测频率进行选择。值越低表示模型更准确。
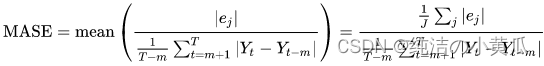
其中,
Y
t
Y_{t}
Yt:代表t时刻观测值
Y
^
t
−
m
\hat{Y}_{t-m}
Y^t−m:代表t-m时刻观测值
e
j
e_j
ej: 代表t时刻第j个点上的误差(观测值-预测值)
m
m
m:季节性值
MASE 是周期性质或具有季节性属性的数据集的理想选择。例如,对夏季需求量高的物品和冬季需求量低的物品进行预测可以从考虑季节性影响中受益。
总结
在实际预测场景中,我们还是要根据预测类型来创建预测和评估预测变量。Forecast 类型有以下两种形式:
-
均预测类型-以平均值作为预期值的预测。通常用作给定时间点的点预测。
-
分位数预测类型-指定分位数的预测。通常用于提供预测间隔,这是一系列可能的值来考虑预测不确定性。例如,在0.65分位数将估计一个低于 65% 时间的观察值的值。
具体选择哪个指标来进行预测还需要根据实际业务场景进行分析和判断。

