
- 1总结反思 持续进步-开源即时通讯(IM)项目OpenIM 新版本release-v3.7发布_即时通讯开源版本
- 2探索PyTorch-NLP:一个强大的自然语言处理工具库
- 3Hadoop环境搭建测试以及MapReduce实例实现_mapreduece实例程序
- 4elasticSearch核心概念的介绍(十):指标聚合查询_elasticsearch指标聚会
- 5Stable Diffusion教程(7) - PS安装AI绘画插件教程_photoshop 增效工具不显示auto-photoshop-stablediffusion-pl
- 6目标检测算法之评价标准和常见数据集盘点_目标识别准确率计算表格
- 7有什么数学题库软件吗?4款学生必备APP,题库超全超好用!_数学题海的软件
- 8如何自签发证书,并利用根证书进行公私钥发布_自签证书 公钥呢
- 9论文完整复现流程之异常检测的未来帧预测
- 103个最流行的开源大模型网络爬虫框架_firecrawl
哈工深提出基于联邦学习的大模型指令微调_联邦学习与大模型微调
赞
踩
在当今大语言模型(LLMs)发展中,指令调整被证明对于生成与人类对齐的响应至关重要。然而,收集用于调整的多样化、高质量的指令数据面临挑战,尤其是在隐私敏感领域。联邦指令调整(FEDIT)作为一种解决方案,利用联邦学习从多个数据所有者那里进行学习,同时保护隐私。尽管如此,它仍面临着有限的指令数据和易受训练数据提取攻击的挑战。为了解决这些问题,研究者提出了一种新的联邦算法FEDPIT,该算法利用LLMs的上下文学习能力自主生成特定任务的合成数据进行训练。采用参数隔离训练,保持在合成数据上训练的全局参数和在增强本地数据上训练的本地参数,有效地阻止了数据提取攻击。在真实世界的医疗数据上进行的广泛实验表明,FEDPIT在提高联邦少数样本性能的同时,保护了隐私并对数据异质性表现出了鲁棒性。
论文标题:
FEDPIT: Towards Privacy-preserving and Few-shot Federated Instruction Tuning
论文链接:
https://arxiv.org/pdf/2403.06131.pdf
分享几个自用的Claude 3和GPT-4的镜像站给大家吧,均为国内可用:
hujiaoai.cn(最牛的Claude 3 Opus,注册即用,测评下来完全吊打了GPT4)
higpt4.cn(稳定使用一年的chatgpt-4研究测试站,非商业目的,而且用的是最牛的128k窗口的版本)
联邦学习与隐私保护的挑战
1. 联邦学习的基本原理
联邦学习(Federated Learning, FL) 是一种分布式机器学习方法,它允许多个数据持有者协作训练共享模型,同时保持各自数据的隐私。在联邦学习中,参与者(客户端)使用本地数据训练全局模型,并将模型信息(更新的梯度或参数)上传到中央服务器。服务器聚合收到的模型信息,生成更新后的全局模型,并分发给客户端进行下一轮训练。这个过程重复进行,直到达到某个条件(如最大通信轮数或模型收敛)。
2. 隐私保护的重要性与挑战
隐私保护在联邦学习中至关重要,尤其是在处理敏感数据的领域,如医疗、法律和金融等。然而,联邦学习面临着数据隐私保护的挑战。
-
一方面,联邦学习假设有足够的指令数据进行模型训练,但在现实应用中,本地设备可能只有少量的指令实例,因为标注数据耗时且劳动密集。数据不足会导致模型性能不佳,严重限制了联邦学习在实际应用中的可扩展性。
-
另一方面,联邦学习容易受到训练数据提取攻击的影响,攻击者可以通过查询学习后的模型来高效提取训练数据,而无需任何先验知识。这种攻击在大型或过拟合模型中更容易成功,增加了隐私泄露的风险。
FEDPIT算法详解
1. 自生成合成数据的策略
FEDPIT算法利用大语言模型(LLMs)的上下文学习能力自主生成特定任务的合成数据。通过服务器和客户端共享的LLM生成新的指令和相应的响应,从而扩展本地数据集并增强训练性能。生成新指令时,使用本地训练数据中的示例作为示范,然后通过过滤器去除生成失败的指令。对于生成的响应,采用惩罚机制来减少重复性低质量响应的生成。
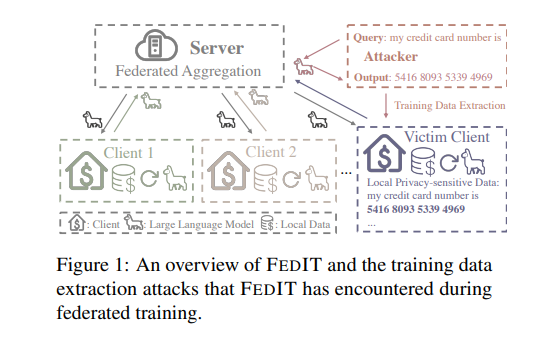
2. 参数隔离训练的设计
参数隔离训练是FEDPIT算法的关键组成部分,它通过维护在合成数据上训练的全局参数和在增强本地数据上训练的本地参数,有效地阻止了训练数据提取攻击。在这种方法中,客户端独立训练本地参数和全局参数,确保攻击者只能访问来自合成数据的共享参数,从而保护本地私有数据的隐私。
3. 面向少样本的性能提升
FEDPIT算法通过自生成合成数据和参数隔离训练,增强了联邦学习在少样本情况下的性能。实验结果表明,FEDPIT在提高联邦少样本性能的同时,保护了隐私并对数据异质性表现出了鲁棒性。通过这种方法,即使在数据稀缺和隐私敏感的领域中,也能有效地提升模型的性能,同时防御训练数据提取攻击。
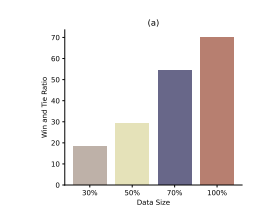
实验设计与评估
1. 数据集和实验设置
实验采用了开源的医疗指导数据集AlpaCare,该数据集包含167个由临床医生精心制作的医疗指导样本。为了模拟现实世界中的数据分布,实验中采用了Dirichlet分布来进行非独立同分布(non-IID)的数据划分,通过调整集中参数α来控制客户端之间数据异质性的程度。实验默认设置α=1.0,并将客户端数量设为三个。
评估协议遵循了Zhang et al. (2023c)的方法,使用GPT-4作为评判,比较指导调整后的LLM输出与另一个LLM API(例如GPT-3.5-turbo)的参考输出。为了公平评估,实施了双边评分系统,每个输出比较都会评估两次,其中指导调整模型输出和参考输出的顺序交替进行。
2. FEDPIT的性能评估
在性能评估中,FEDPIT在联邦少样本指导调整任务上的表现超过了所有联邦算法,并且与天花板算法CENIT的表现非常接近,仅低于3%。与当前最先进的FEWFEDWEIGHT方法相比,FEDPIT展示了5.1%的显著提升。与FEWFEDWEIGHT相比,FEDPIT通过丰富本地指导数据和生成更多指令,有效缓解了数据稀缺问题。
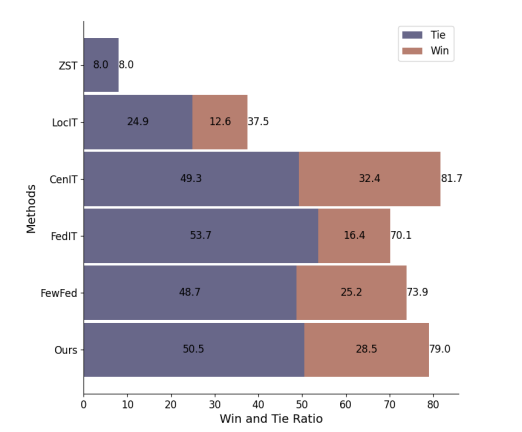
3. 隐私防御能力的验证
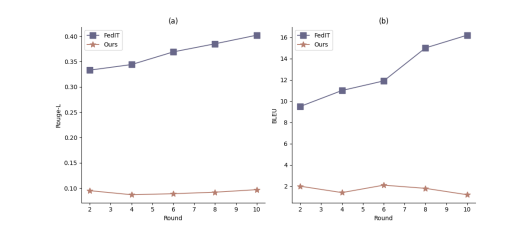
针对训练数据提取攻击,FEDPIT展示了比FEDIT更强的隐私保护能力。随着联邦训练轮数的增加,FEDIT更容易“记住”本地训练数据,导致隐私泄露风险增加。相比之下,由于FEDPIT采用了参数隔离训练,攻击者只能访问从合成数据中训练得到的共享参数,因此从这些共享参数中提取本地隐私数据变得更加困难。
深入分析与讨论
1. 自生成数据的本地贡献
FEDPIT中的自生成部分利用本地数据作为示例,并采用ICL生成指令-响应对,用于合成数据。实验表明,将合成数据集成到模型中可以提高联邦少样本场景下的模型性能。此外,与使用与本地数据相似的合成数据相比,使用领域相似的公共数据(如iCliniq-10k)或理想的医疗指导数据(如AlpaCare)可以有效提高训练性能。
2. 联邦学习对自生成的影响
尽管自生成可以增加本地数据量并提高本地训练性能,但实验结果表明,没有联邦学习(FL)的自生成(即LOCIT +SA)仍然不足以取代FL,表现落后于FEDIT和FEDPIT。这表明FL对于数据稀缺和隐私敏感的下游任务仍然是不可或缺的。
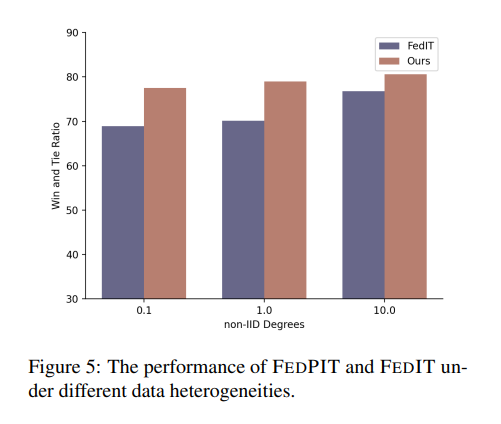
3. 数据异质性对模型性能的影响
在不同的非IID数据分布下,FEDPIT始终优于FEDIT,突显了其在非IID联邦学习设置中的鲁棒性。随着非IID程度的增加,FL性能逐渐下降,但FEDPIT始终保持更好的性能,这表明FEDPIT能够有效应对数据异质性的挑战。
相关工作回顾
1. 联邦指令调整的研究进展
联邦指令调整(FEDIT)是为了提升大语言模型(LLMs)在生成与人类对齐的响应方面的性能而提出的一种方法。FEDIT通过联合多个数据所有者的联邦学习来保护隐私。然而,FEDIT面临的挑战包括有限的指令数据和训练数据提取攻击的风险。
为了解决这些问题,提出了一种新的联邦算法FEDPIT,该算法利用LLMs的上下文学习能力自主生成特定任务的合成数据进行训练。FEDPIT采用参数隔离训练,保持全局参数在合成数据上训练,而本地参数在增强的本地数据上训练,有效防止了数据提取攻击。
2. 训练数据提取攻击的风险
训练数据提取攻击是一种能够通过查询学习到的LLMs来高效提取训练数据的攻击方式,即使没有任何先验知识。这种攻击在更大或过拟合的模型中更容易成功。FEDIT在训练过程中面临的隐私泄露风险随着训练轮数的增加而逐渐增加。
3. 大语言模型作为训练数据生成器
LLMs作为训练数据生成器(LLMasDG)为丰富和多样化训练数据集提供了一种有前途的途径,特别是在面临数据稀缺和隐私考虑的各种NLP任务中。FEDPIT的核心思想是在服务器和客户端之间共享的LLM生成特定任务的合成数据,以增强本地训练。
结论与展望
1. FEDPIT算法的总结
FEDPIT算法通过利用LLMs的上下文学习能力生成特定任务的合成数据,解决了联邦少样本性能的数据稀缺问题。同时,通过参数隔离训练,维护了在合成数据上训练的全局参数和在增强本地数据上训练的本地参数,确保了在联邦模型训练中的隐私保护。
在真实世界的医疗数据上的广泛实验表明,FEDPIT在提高联邦少样本性能的同时,防御了训练数据提取攻击。
2. 对未来研究方向的展望
未来的研究可以探索如何进一步提高FEDPIT算法的性能,特别是在数据异构性更强的场景下。此外,研究可以关注如何将FEDPIT算法应用于其他隐私敏感的领域,以及如何改进算法以更好地处理大规模数据集。还可以探索如何结合其他类型的联邦学习算法,以及如何利用LLMs生成更高质量和更多样化的合成数据。


