
- 1Ubuntu 20.04 QGIS update 报错 GPG error: https://ubuntu.qgis.org/ubuntu jammy InRelea_jammy inrelease
- 2支付宝二维码生成,可以自定义金额和备注(不限制生成数量)_支付宝uid获取二维码
- 3Mac查看本机ip地址_mac查询ipv6
- 4Unity功能记录(一) ------ 截图/录屏保存到相册(Android/iOS横屏竖屏都可以)
- 5求职简历应该怎么填写受HR喜爱?HR喜欢邮箱格式应该怎么写?_hr邮箱怎么填写
- 6【视频讲解】偏最小二乘结构方程模型PLS-SEM分析白茶产业数字化对共同富裕的影响|附代码数据...
- 7Eclipse:this compilation unit is not the build
- 8Rabbitmq的优点_rabbitmq 是阿里巴巴的吗
- 9DevOps搭建(三)-Docker环境安装细步骤_devops安装步骤
- 10Python用GRU神经网络模型预测比特币价格时间序列数据2案例可视化|附代码数据...
击败3位人类世界冠军,登上Nature封面!开启自动驾驶新纪元?
赞
踩
来源:新智元
在下棋,办公,游戏这类脑力活动中,人类被AI碾压已经早就不是什么新闻了。
现在连极限竞速领域,人类的阵地也失守了!
今天Nature的封面论文,内容是AI驾驶系统在无人机竞速领域击败了人类SOTA。

论文地址:https://www.nature.com/articles/s41586-023-06419-4
来自苏黎世大学和英特尔的研究团队开发的Swift系统,成功地在第一人称视角(FPV)无人机比赛中,击败了3位人类世界冠军,单圈速度比人类快了半秒!
AI无人机内心OS「遥遥领先!」
比赛当中,驾驶选手需要驾驶高速无人机完成一个三维空间内的立体赛道。人类驾驶员和AI都只能通过机载摄像头的拍摄的视频流来观察环境,操纵无人机的飞行。

2019年,当时成绩最好的Alphapilot系统,如果不依靠外部的追踪系统来精确控制无人机的飞行轨迹,完成比赛的时间几乎是人类的两倍。
Swift系统和人类选手一样,仅通过对机载摄像头收集的数据做出实时反应,让完成比赛的时间有了质的飞跃。
它的集成的惯性测量单元(inertial measurement unit)测量无人机的加速度和速度,神经网络通过来自摄像头的数据来定位无人机在空中的位置,并检测跑道上的需要通过的门。
这些信息被汇总到基于深度强化学习(DeepRL)的控制单元,做出最佳的反馈指令,从而尽可能快地完成赛道。

FPV无人机比赛中使用的是四轴飞行器,是市面上最为灵活的无人机。比赛中无人机受到的加速力,可能超过自身重力的5倍还多,飞行时速超过100公里每小时!

赛道由7个正方形的门组成,场地大小为30*30*7的三维空间,飞行距离超过75米。无人机必须按顺序通过每个门,连续跑完3圈,才能完成比赛。

人类驾驶员佩戴头显,来获得实时的视频信号。头显能提供身临其境的「第一人称视角」体验。
超越人类世界冠军选手的Swift系统,主要由两个关键模块组成:
1. 将高维度视觉和加速度信息转化为低维度表示的感知系统
2. 获取低维度表示并生成控制命令的控制AI系统
这个控制AI系统由前馈神经网络进行表征,使用无模型的On-Policy深度强化学习进行模拟训练,不断提高跑圈成绩。

研究人员通过使用从物理世界收集的数据估计的非参数经验噪声模型(non-parametric empircal noise medels),来缩小模拟与物理世界中的感知和动力学差异。
这些噪声模型能有效地将模拟中的控制策略转化为现实中的控制指令。
人类选手在赛道上进行了一周的练习,在完成了一周的训练后,每个飞行员都与Swift进行了多场正面1V1的比赛。

Swift的胜利标志着AI控制的自主操控系统首次在与人类的竞技比赛中获得了胜利。
Swift系统
机器人领域中主要的挑战之一是虚拟和现实两者之间存在差距,传统的端到端学习方法难以将虚拟环境的映射转移到现实世界。
Swift是一个端到端的自主控制系统,它能让无人机像人类选手一样参加FPV无人机赛事并取得具有竞争力的成绩。
它的系统中主要包含以下两个模块:
1. 感知系统
感知系统由一个VIO模块组成,该模块通过相机图像和惯性测量单元(IMU)获得的高频测量值计算无人机状态的度量估计值。
VIO和门检测结果经卡尔曼滤波整合为无人机状态。随后,控制策略网络将状态和之前动作作为输入,输出控制命令。
这个系统能将来自无人机上的摄像头和惯性传感器等复杂高维信息,转化成无人机当前状态的低维表示。
包括无人机在赛道上的位置、速度、姿态等,并使用了视觉惯性系统和神经网络进行图像处理和状态估计。
2. 控制策略
每个timestep中,策略网络会根据状态和之前动作输出。
Swift中的价值网络评估这个动作的价值,之后两个网络的参数会通过强化学习进行优化。
这个策略用一个简单的两层全连接神经网络表示,输入是感知系统输出的无人机当前状态,输出是给无人机的控制命令(推力和体积转速)。它通过在模拟环境中用强化学习的方式进行训练。
此外,为了把Swift的感知和行动跨域迁移到真实世界,研究人员使用了两个残差模型来处理动力学和感知上的偏差:
感知残差模型:使用高斯过程拟合真实飞行中惯性系统的误差,并在模拟中加入。
动力学残差模型:使用k近邻回归拟合真实飞行中动力学的误差,并在模拟中加入。
通过这种方式,Swift可以适应真实世界中的不确定性,实现从模拟到物理系统的有效迁移。
经过训练后,它可以像专业选手一样驾驶无人机进行FPV赛事,甚至在部分场景下超越了人类冠军的表现。
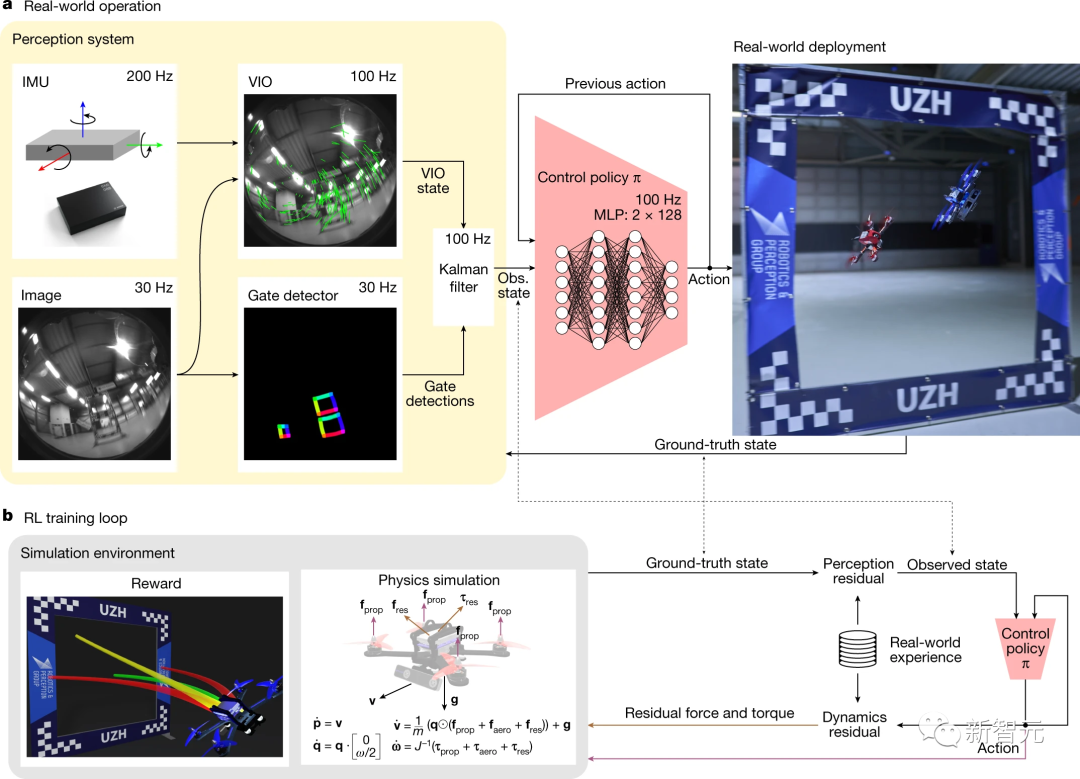 图a:Swift在实际使用中从传感器获取数据并生成控制命令的过程
图a:Swift在实际使用中从传感器获取数据并生成控制命令的过程
图b:在仿真环境中使用强化学习训练控制策略的过程
结果
研究人员将Swift与计时赛中的人类飞行员的成绩进行了比较。
单圈时间表示连续三圈热火中达到的最佳单圈时间和最佳平均时间。如下图a所示,Swift不仅平均单圈时间更快,平均三圈时间也更稳定。
正面交锋的结果则如下图b所示,在与A.Vanover的9场比赛中,Swift赢了5场;在与T.Bitmatta的7场比赛中,Swift赢了4场;在与M.Schaepper的9场比赛中,Swift赢了6场。
研究人员解释,在Swift输掉的10场比赛中,40%是因为与对手发生碰撞,40%是因为与闸门发生碰撞,20%是因为无人机的速度比人类飞行员慢。
总的来说,Swift在与人类飞行员的比赛中获胜最多。Swift还取得了最快的比赛时间记录,比人类飞行员(A.Vanover)的最佳时间领先半秒。
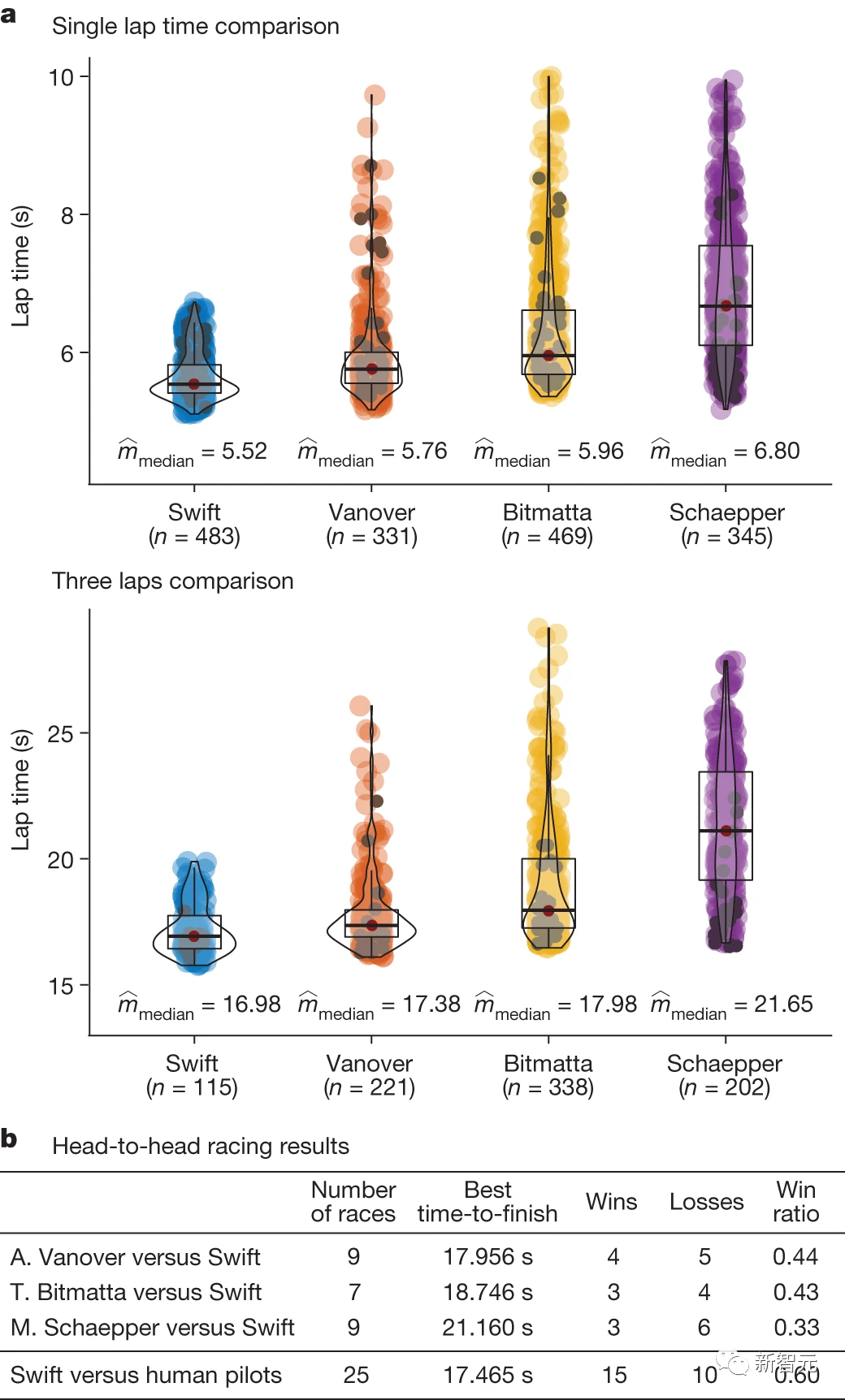
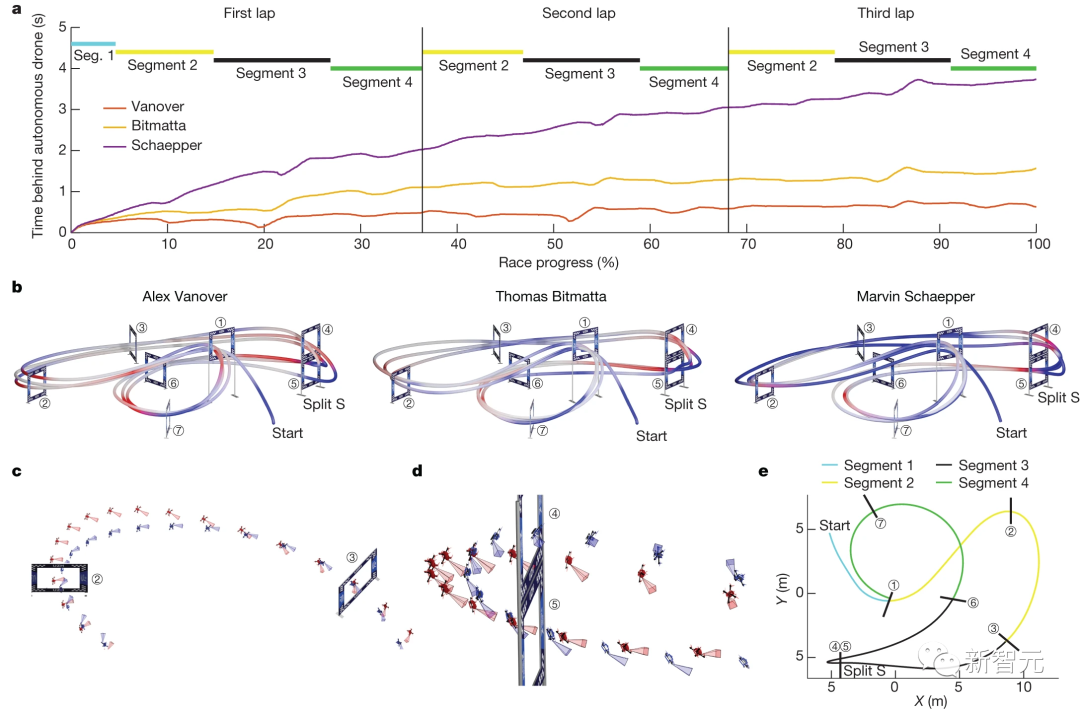
研究人员分析了Swift和每个人类飞行员飞行的最快圈速。
从整体上看,Swift比所有人类飞行员都要快,但它在赛道的所有单个赛段上的速度并不快。
在起跑时,Swift的反应时间较短,平均比人类飞行员早120毫秒从领奖台起飞。并且它的加速更快,进入第一个闸门时的速度更高。
如下图c、d所示,在急转弯时,Swift的机动更紧凑。
研究人员推测,造成这一结果的原因是Swift在选择轨迹时的时间更长。
因为它可以根据价值函数来优化长期回报,而人类飞行员最多预测一个未来,所以规划的时间尺度更短。
在下图b,d中可以看到,人类飞行员在动作开始和结束时速度较快,但总体速度较慢。
同时,与人类相比,Swift在执行某些机动动作时也能依靠其他线索,例如惯性数据和针对周围环境特征的视觉里程测量。
这些都帮助了自主无人机在比赛中实现了最高的平均速度、最短的赛线,并在整个比赛过程中设法将飞机保持在更接近其驱动极限的状态。
讨论
研究人员开发的这个自主控制系统,能够在FPV无人机竞速中实现冠军级别的表现,甚至在某些情况下超越人类世界冠军。
这个系统相对于人类选手具有一定的结构优势。
首先,它利用了来自机载惯性测量单元(IMU)的惯性数据。这类似于人类前庭系统(vestibular system),但人类选手没有办法使用自身的这个系统,因为他们没有乘坐在飞行器内部,无法亲身感受到飞行器的加速度。
其次,Swift系统具有更低的感觉运动延迟(Swift为40毫秒,而专业人类选手平均为220毫秒)。另一方面,Swift使用的摄像头刷新率有限(30赫兹),相比之下,人类飞行员的摄像头刷新率快了四倍(120赫兹),从而提高了他们的反应时间。
人类飞行员的适应能力非常强:无人机全速出事故坠落后,如果硬件仍然正常工作,他们还能继续飞行并完成赛道。而Swift不具备出事故坠毁后恢复比赛能力。

人类飞行员还能够适应环境条件的变化,比如会显著改变赛道外观的光照变化等。
Swift的感知系统假设比赛环境的外观与训练时观察到的是完全一致的。如果环境发生了变化,系统可能会无法工作。
不过可以通过在各种条件下训练门探测器和残余观测模型(residual observation model)来提供对于比赛环境变化的适应能力。
尽管研究人员研发的系统还存在一些限制和待解决的工作,但一个自主移动机器人能够达到体育项目中世界冠军级别的表现是机器人技术和AI领域的一个重要里程碑。
这项工作可能会激发在其他物理系统(自动驾驶车辆、飞行器和机器人等)中部署基于混合学习的解决方案,从而在更加广泛的应用领域发挥更大的作用。
方法
训练算法
训练是使用近端策略优化(Proximal Policy Optimization,PPO)方法进行的。这种actor-critic方法在训练期间需要同时优化两个神经网络:策略网络(将观测映射到动作)和值网络(作为「critic」评估策略采取的动作)。
经过训练后,只有策略网络被部署到无人机上。
观察、行动和奖励
在时间t从环境中获得的观测值
- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

