
热门标签
热门文章
- 1python中pip安装、升级包用法详解_pip upgrade
- 2vue项目中安装sass方法_vue安装sass
- 3秒杀系统如何设计?
- 4市场份额被微软步步蚕食,Zoom已到生死存亡关头
- 5docker run 命令转为docker-compose.yml配置文件_docker run 转换yaml
- 6SQL 教程-入门基础篇_sql学习
- 7There is no getter for property named ‘xxxxx’ in ‘class com.xxx.xx.xx.xxxx‘”,_there is no getter for property named 'student_id'
- 8如何查看linux系统CPU利用率
- 9PyTorch 2.2 中文官方教程(十五)
- 10【新知实验室】腾讯云TRTC服务体验_trtc和webrtc
当前位置: article > 正文
Kafka系列之:记录一次Kafka Topic分区扩容,但是下游flink消费者没有自动消费新的分区的解决方法_flume 感知kafka分区变化
作者:你好赵伟 | 2024-02-12 20:46:48
赞
踩
flume 感知kafka分区变化
Kafka系列之:记录一次Kafka Topic分区扩容,但是下游flink消费者没有自动消费新的分区的解决方法
一、背景
- 生产环境Kafka集群压力大,Topic读写压力大,消费的lag比较大,因此通过扩容Topic的分区,增大Topic的读写性能
- 理论上下游消费者应该能够自动消费到新的分区,例如flume消费到了新的分区,但是实际情况是存在flink消费者没有消费到新的分区
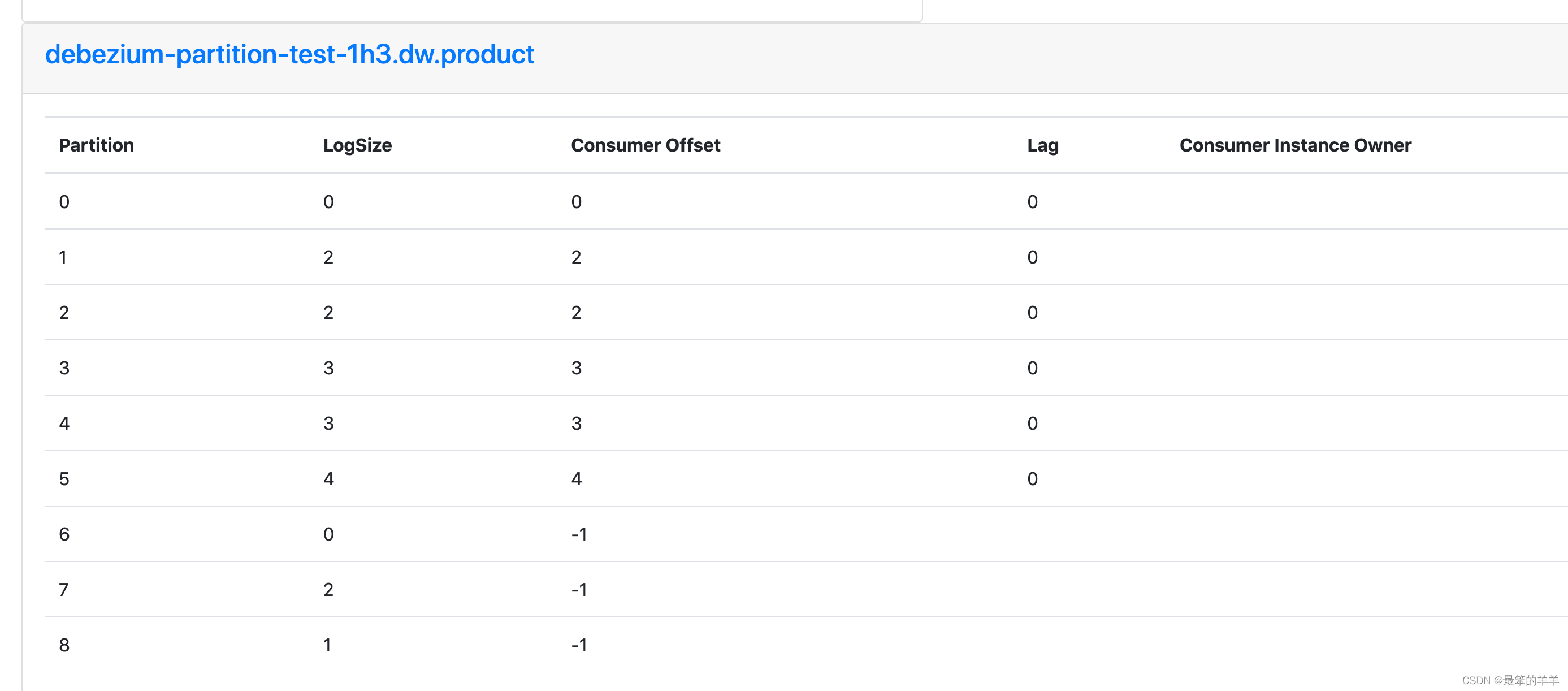
二、解决方法
出现无法消费topic新的分区这种情况,最简单的解决方法是
- 重启flink消费者程序
三、实现自动发现新的分区
flink程序增加自动发现分区参数:
- flink.partition-discovery.interval-millis是一个配置属性,用于设置Flink作业中的分区发现间隔时间(以毫秒为单位)。
- 在Flink作业中,数据源(例如Kafka或文件系统)的分区可能会发生变化。为了及时感知分区的变化情况,
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/78502
推荐阅读
- swagger:swagger 引入
[详细] 赞
踩
相关标签

