
- 1漏洞复现- - -CVE-2016-5195 Dirty Cow脏牛提权漏洞
- 2百万年薪挖了个P8程序员,难道是“水货”?
- 3CSS实现隐藏滚动条并可以滚动内容效果(三种方式)_css隐藏滚动条
- 4WebGL 与 WebGPU比对[4] - Uniform_webgpu和webgl区别
- 5Elasticsearch如何聚合查询多个统计值,如何嵌套聚合?并相互引用,统计索引中某一个字段的空值率?语法是怎么样的
- 6java操作二叉树_java二叉树操作
- 727岁Python独立开发者,年收入超900万,过着令人羡慕的生活_python之父的收入(2)
- 8yyds!Github+AI大模型完整学习教程_github ai大模型
- 9小程序自定义底部导航。。。干货。。。custom-tab-bar得使用
- 10netty通讯--tcp心跳异常断开问题排查_netty 频繁断开
MySQL基础_amberdb
赞
踩
目录
Mysql安装及配置
1,Mysql5.7地址:https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.19-winx64.zip
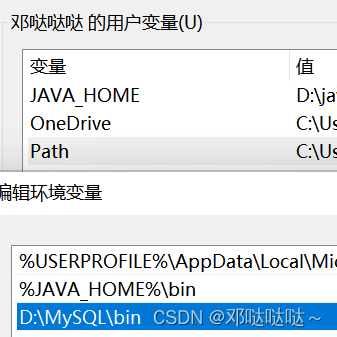
2,添加环境变量 : 电脑-属性-高级系统设置-环境变量,在Path 环境变量增加mysql的安装目录\bin目录, 如下图
3,在安装目录下下创建 my.ini 文件, 需要我们自己创建
- [client]
- port=3306
- default-character-set=utf8
- [mysqld]
- # 设置为自己MYSQL的安装目录
- basedir=D:\MySQL\mysql-5.7.19-winx64\
- # 设置为MYSQL的数据目录
- datadir=D:\MySQL\mysql-5.7.19-winx64\data\
- port=3306
- character_set_server=utf8
- #跳过安全检查
- skip-grant-tables
4,使用管理员身份打开 cmd , 并切换到 D:\MySQL\mysql-5.7.19-winx64\bin目录下, 执行mysqld -install
5,初始化数据库: mysqld --initialize-insecure --user=mysql

如果执行成功,会生成 data目录:

6,启动mysql 服务: net start mysql 【停止mysql服务指令 net stop mysql】

7,进入mysql管理终端,修改密码
- 进入mysql 管理终端: mysql -u root -p 【当前root 用户密码为 空】
- 修改root 用户密码
| use mysql; update user set authentication_string=password(' ') where user='root' and Host='localhost'; 上面的语句就是修改 root用户的密码为‘ ’里面的单词 注意:在后面需要带 分号,回车即可执行该指令 执行: flush privileges; 刷新权限 退出: quit |
3.修改my.ini , 再次进入就会进行权限验证了(删除#skip-grant-tables ) 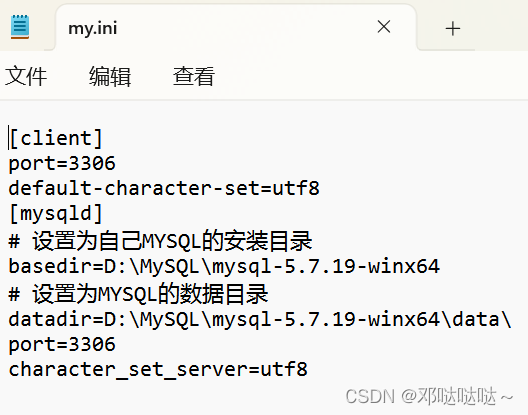
总结:下载的时候可以跟着视频下载(比如韩顺平),如果下载错误或者哪一步不正确,不要试图通过碎片化的解决方法解决问题,我的解决方案就是卸载重新下载(别问我是怎么知道的,浪费了不少时间呢)想要卸载干净,推荐这个博客http://t.csdn.cn/2322K
在学习数据库前,需要学习navicat,推荐博客http://t.csdn.cn/EMvKO
数据库
1,创建数据库
- #删除数据库指令
- DROP DATABASE amber_db01;
- #使用指令创建数据库
- CREATE DATABASE amber_db01;
- #创建一个使用utf8字符集的amber_db02数据库
- CREATE DATABASE amber_db02 CHARACTER SET utf8;
- #创建一个使用utf8字符集并带校对规则的amber_db03数据库
- #校对规则utf8_bin区分大小写,默认utf8_general_ci不区分大小写
- CREATE DATABASE amber_db03 CHARACTER SET utf8 COLLATE utf8_bin;
2,查询数据库
- #查看当前数据库服务器中的所有数据库
- SHOW DATABASES
- #查看前面创建的 amber_db01 数据库的定义信息
- SHOW CREATE DATABASE `amber_db01` #老师说明 在创建数据库,表的时候,为了规避关键字,可以使用反引号解决
- #删除前面创建的 hsp_db01 数据库
- DROP DATABASE amber_db01
删除数据库前一定要三思而后行
3,备份恢复数据库
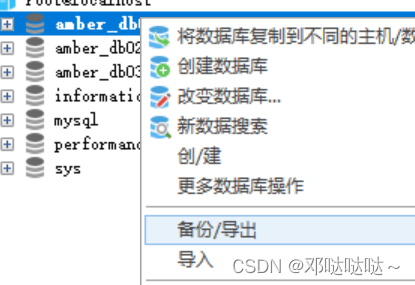
备份数据库命令行(在DOS下执行)
备份amber_db03,amber_db02数据库
- #备份, 要在 Dos 下执行 mysqldump 指令其实在 mysql 安装目录\bin
- #这个备份的文件,就是对应的 sql 语句
- mysqldump -u root -p -B amber_db02 amber_db03 > d:\\SQL练习\bak.sql
备份到了bak.sql文件中

备份库中的表
mysqldump -u 用户名 -p密码 数据库 表1 表2 >d:\\文件名.sql4, 恢复数据库(进入Mysql命令行再执行)
进入Mysql命令

执行恢复命令

另一种恢复方法
讲备份里的内容全部复制,拷贝到一个新的编辑器中
5,创建表
图形化(简单,常用)
指令
表头名字为id,name,password,birthday,类型为整形,字符型,字符型,日期

Mysql常用的数据类型(列类型)

DATA[日期 年月日]
YEAR[年]
TIME[时间 时分秒]
DATATIME【年月日 时分秒】
例:使用TINYINT
- CREATE TABLE t1(
- id TINYUNT);有符号
-
- CREATE TABLE t2(
- id TINYUNT UNSIGNED);无符号
注释快捷键:shift+ctrl+c,注销注释:shift+ctrl+r
表
创建表
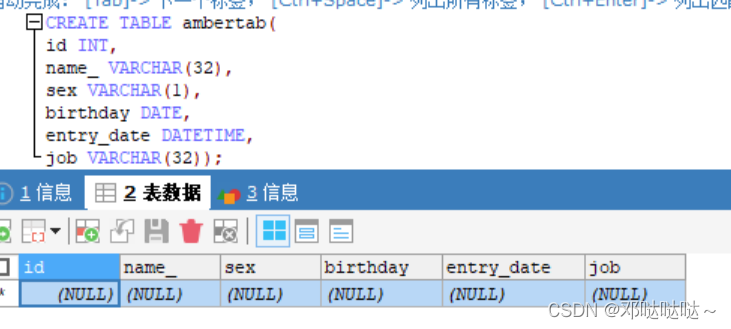
修改表

练习
1,在job后新建image(修改ambertab表,增加image表在job字段之后)
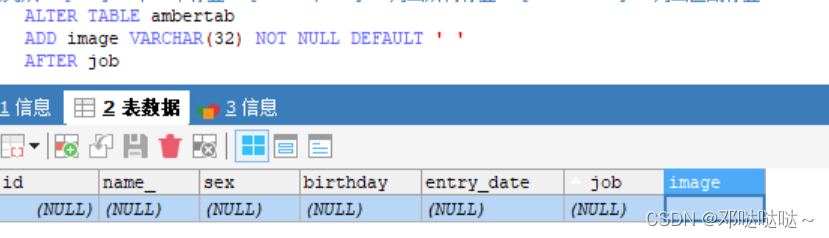
2,删除sex
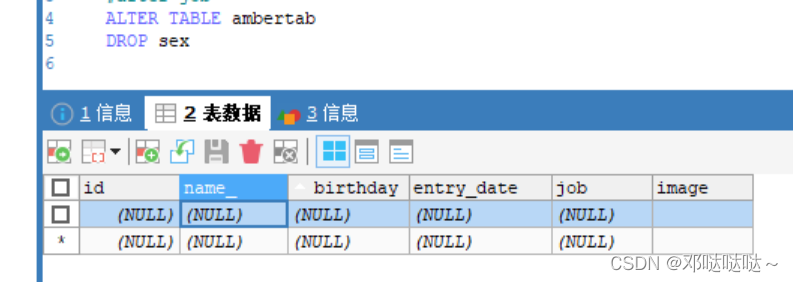
3, 修改表名

CRUD
- insert
- update
- delete
- select
insert update delete
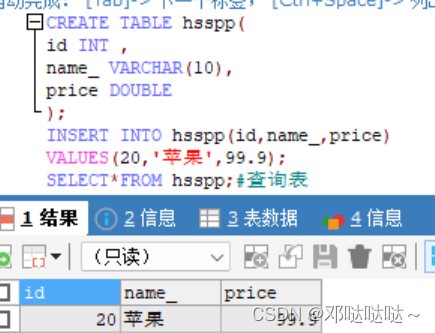
Mysql常用指令大全,参考博客http://t.csdn.cn/Rg435
SELECT(单表)
基本用法练习
1,使用表达式对查询的列进行运算
![]()
2,在 select 语句中可使用 as 语句
![]()
一大波练习即将来袭
1,创建表,插入数据 2,查询
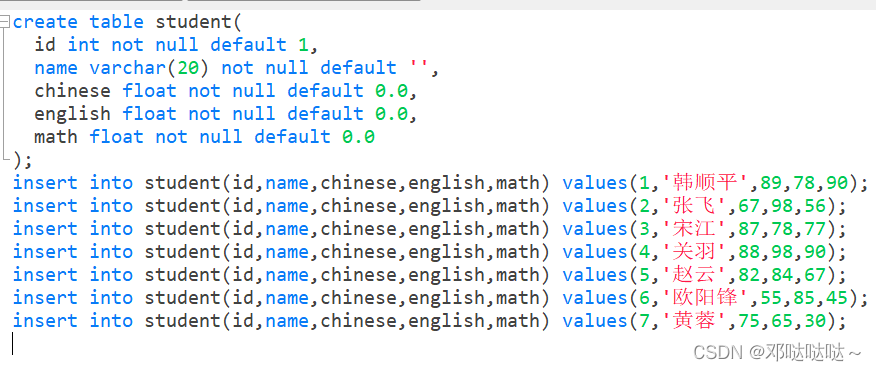
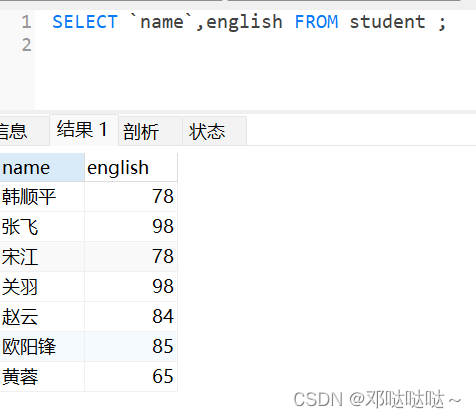
SELECT DISTINCT *** FROM ***
查询记录,去掉重复的,每个字段都相同,才能去掉重复的

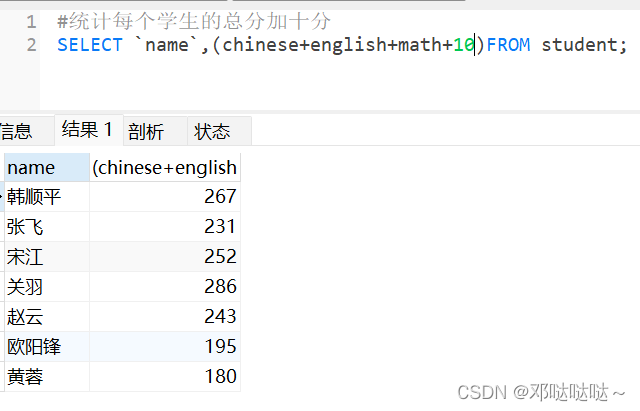
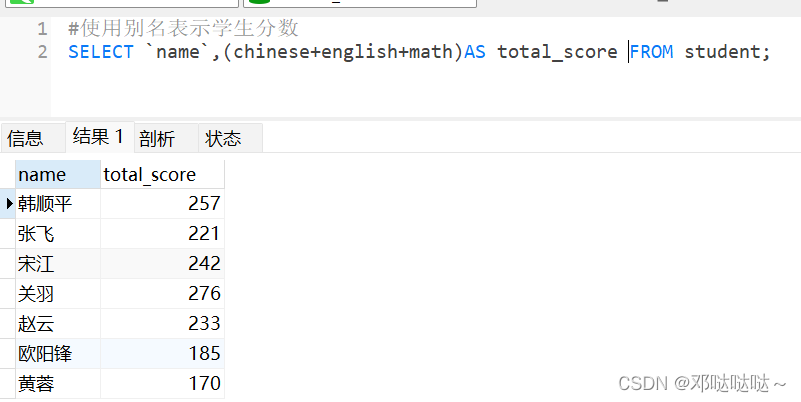
改名:原名 AS 新名
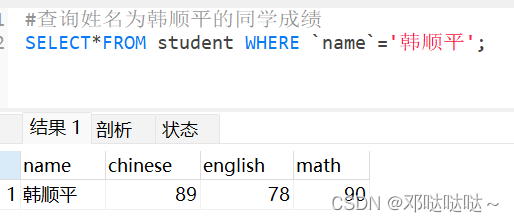

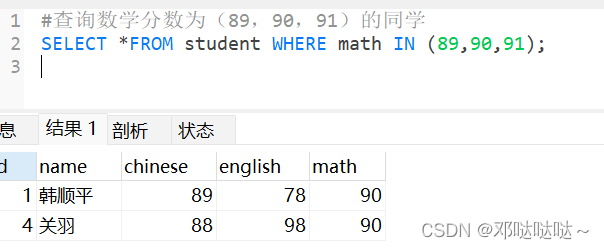
LIKE

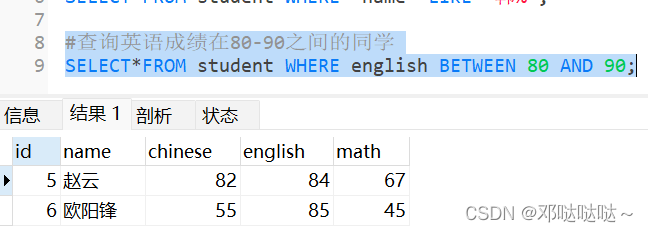
between...and...是闭区间
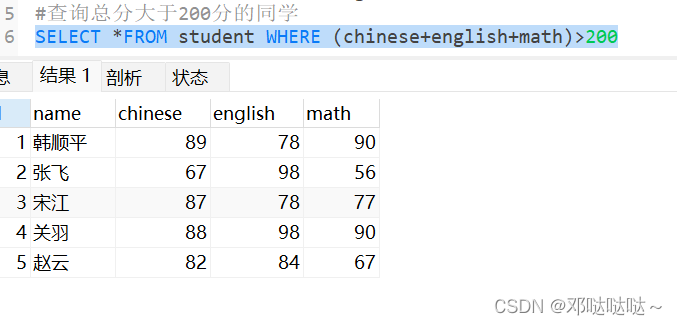
使用 order by 子句排序查询结果
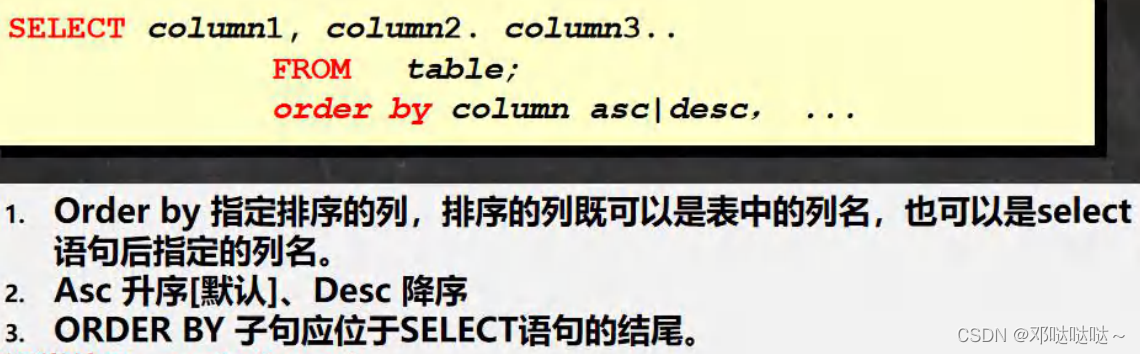

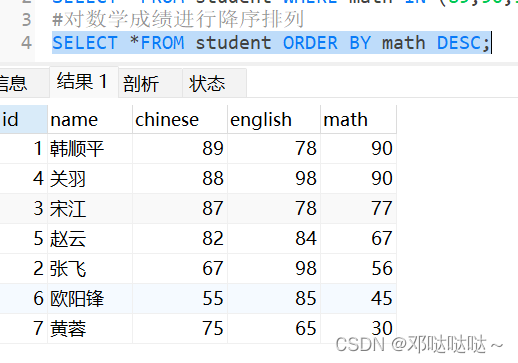
根据总分降序排列
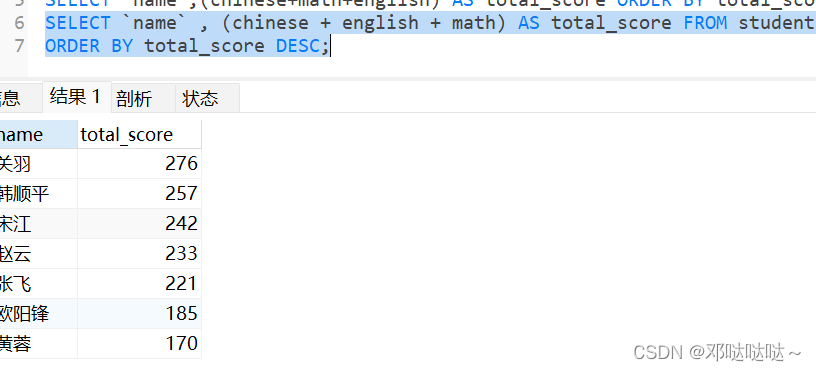
合计/统计函数-count

count(*) 和 count( 列 ) 的区别解释 :count(*) 返回满足条件的记录的行数count(列 ): 统计满足条件的某列有多少个,但是会排除 为 null 的情况
合计/统计函数-sum
sum函数返回满足where条件的行的和(一般使用在数值列)


合计/统计函数-AVG
AVG函数返回满足where条件的一列的平均值

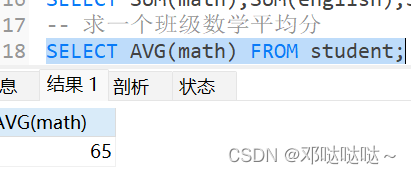
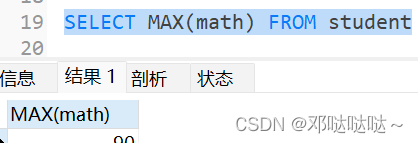
合计/统计函数-max/min
max/min函数返回满足where条件的一列的最大/小值

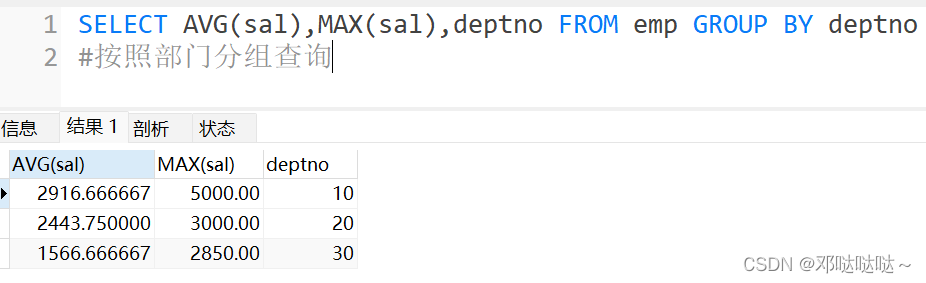
使用 group by 子句对列进行分组
![]()
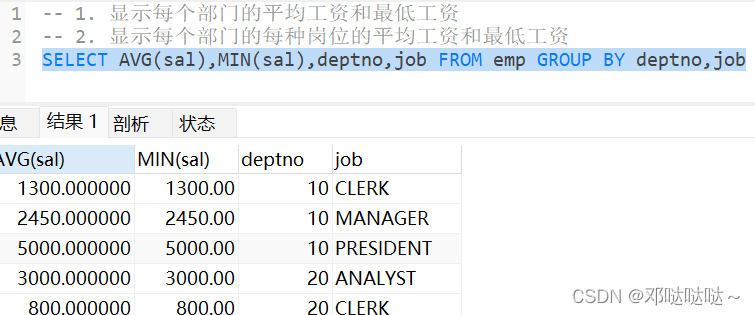
使用 having 子句对分组后的结果进行过滤

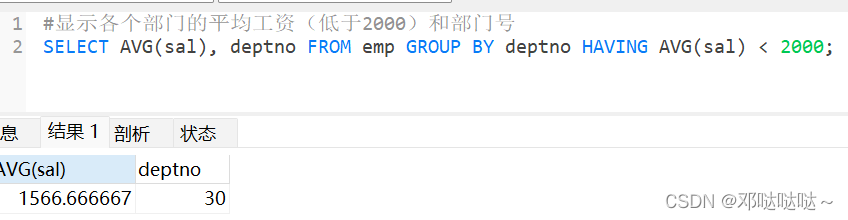
字符串相关函数

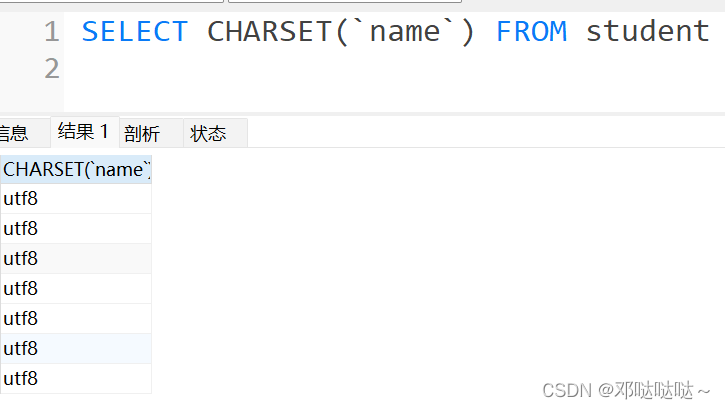
TRIM(string)去除前后端空格
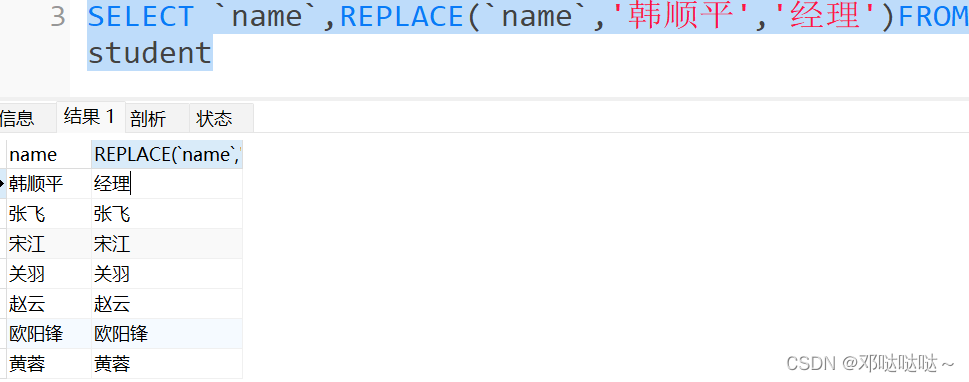
练习
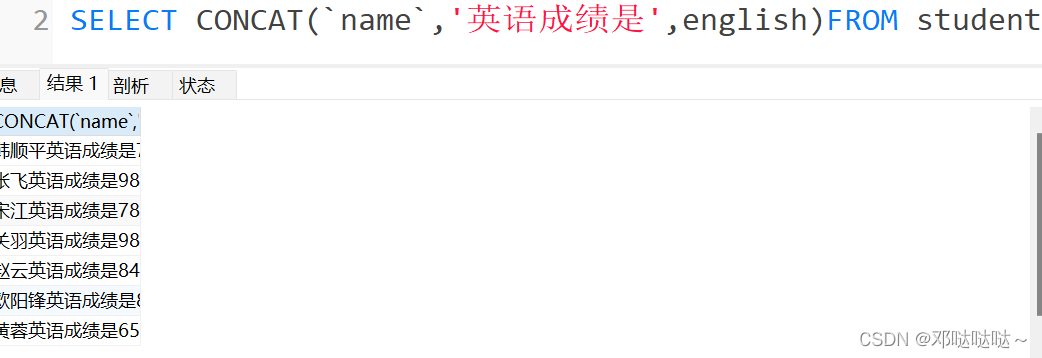
- -- UCASE (string2 ) 转换成大写
- SELECT UCASE(ename) FROM emp;
- -- LCASE (string2 ) 转换成小写
- SELECT LCASE(ename) FROM emp;
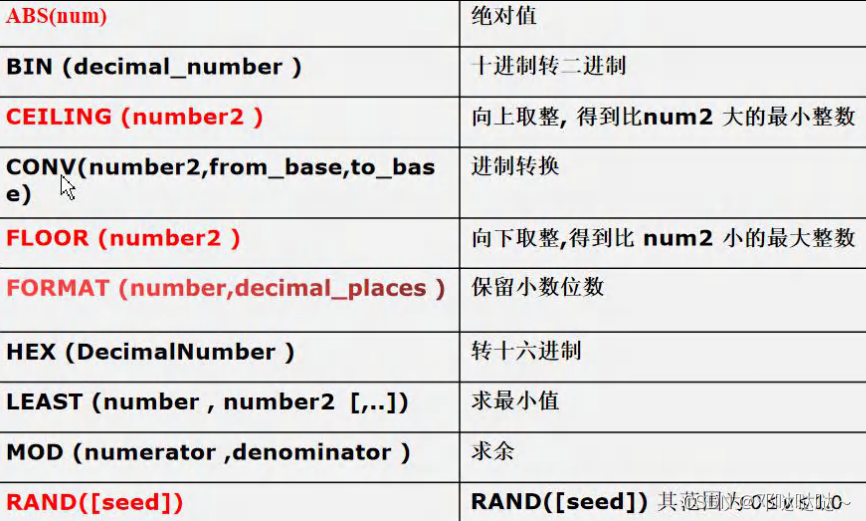
数学函数

了解一下DUAL表:http://t.csdn.cn/3uWMS
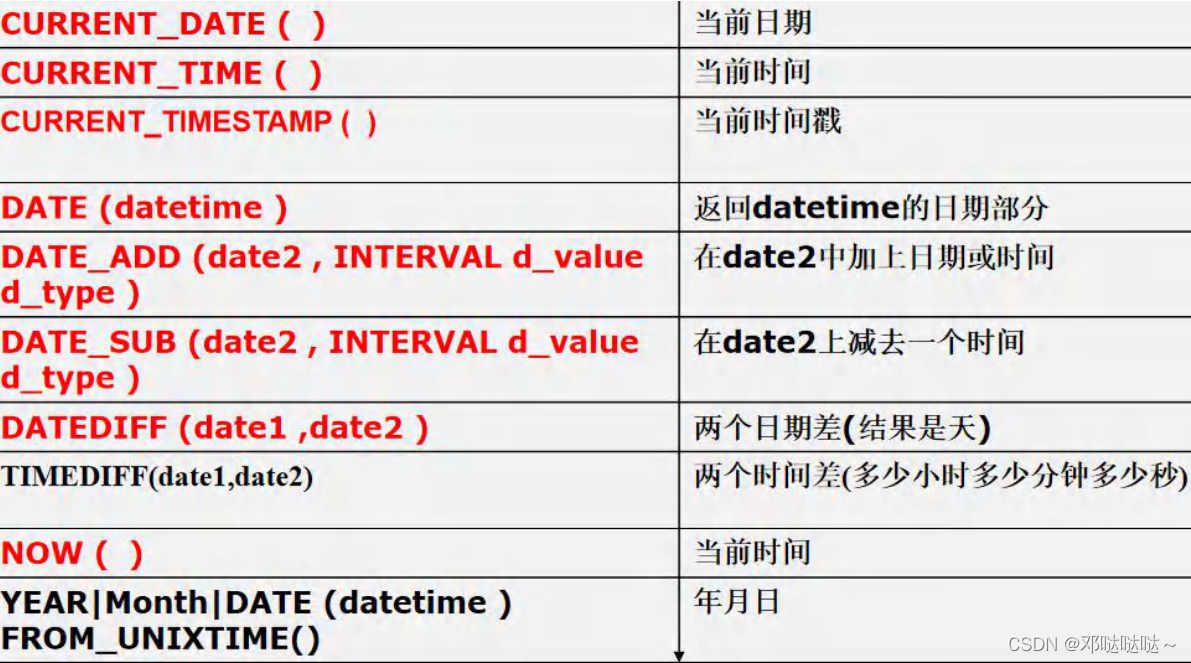
时间日期相关函数

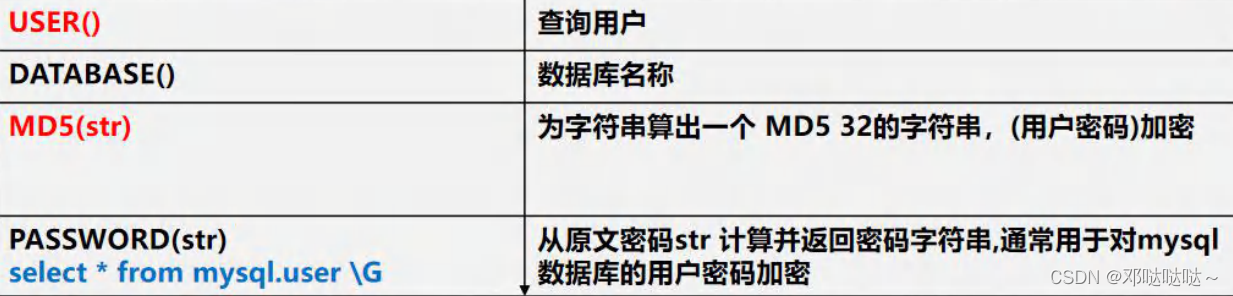
加密和系统函数
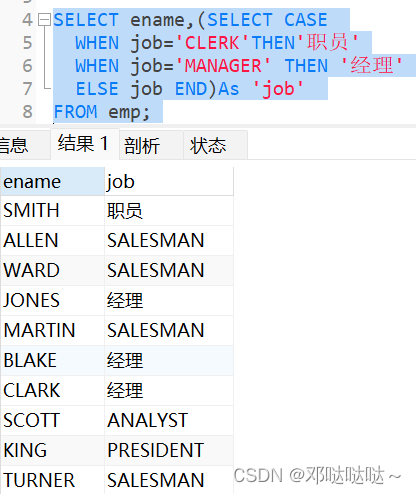
流程控制函数

练习
SELECT(单表-加强)
%表示0到多个字符
-表示单个字符
练习
- #显示首字符为 S 的员工姓名和工资
- SELECT ename,sal FROM emp WHERE ename LIKE 'S%'
- #显示第三个字符为大写 O 的所有员工的姓名和工资
- SELECT ename,sal FROM emp WHERE ename LIKE '__o%'
- #显示没有上级的雇员的情况(判断是否为空,要用IS NULL)
- SELECT *FROM emp WHERE mgr IS NULL
- #查询表的结构
- DESC emp
- #按照部门号升序而雇员的工资降序排列 , 显示雇员信息
- SELECT * FROM emp ORDER BY deptno ASC , sal DESC;
分页查询


多子句查询

SELECT(多表)
- 在默认情况下:当两个表查询时,规则
1,从第一张表中,取出一行和第二张表的每一行进行组合,返回结果(含有两张表的使用列)
2,一共返回的记录数:第一张表行数*第二张表行数
3,这样多表查询默认处理返回的结果,称为笛卡尔集
4,解决这个多表的关键就是要写出正确的过滤条件 where
5,多表查询的条件不能少于 表的个数-1,否则会出现笛卡尔集
- 自连接
1,自连接是指在同一张表的连接查询(将一张表看成两张表)
2, 需要给表起别名:表名 表别名
3, 列名不明确,可以指定列名 : 列名 AS 列的别名
练习:查询两张表的员工名字,老板名字,把一个表看成两张表,一个成为worker,另一个成为boss
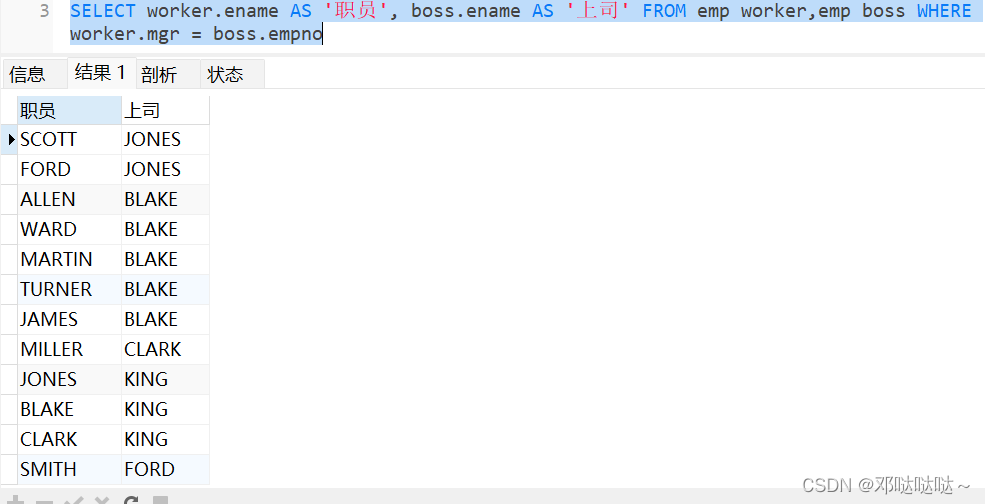
子查询
子查询是指嵌入在其他sql语句中的select语句(嵌套查询)
1,单行子查询
单行子查询是指只返回一行数据的子查询语句
2,多行子查询
多行子查询指返回多行数据的子查询 使用关键字 in
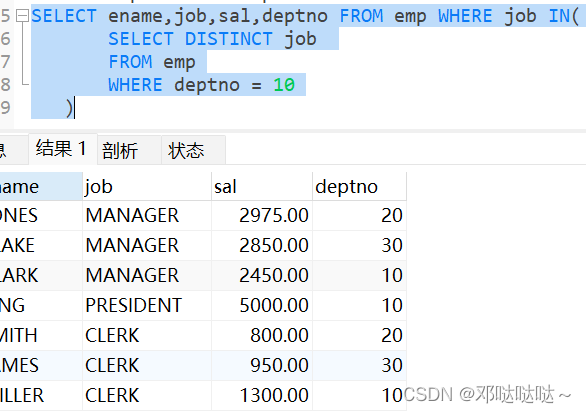
可以把子查询当成一个临时表
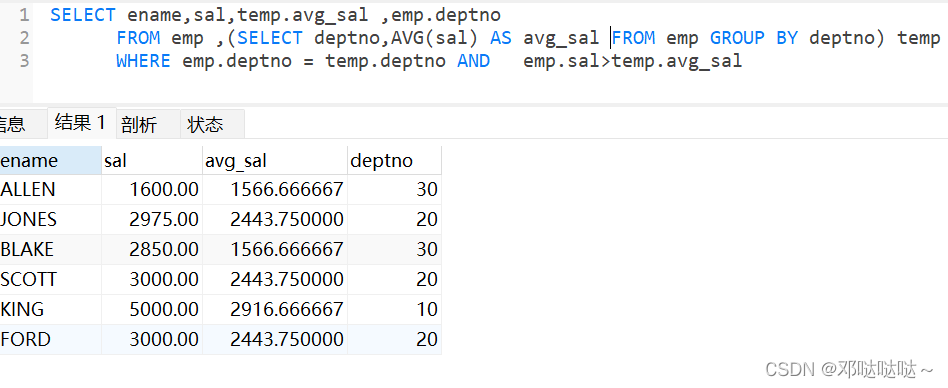
练习
查询每个部门工资高于本部门平均工资的人的资料
1,查询每个部门的平均工资,按照部门号分组
2,把以上子查询当做一个临时表,并起名为temp
3,where后面的条件是部门号要相等,并且员工的工资大于平均工资
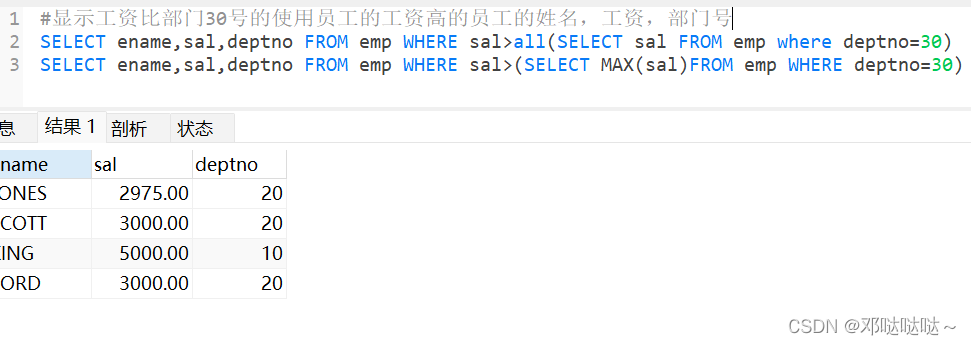
all/any操作符 (类似于任意与存在)
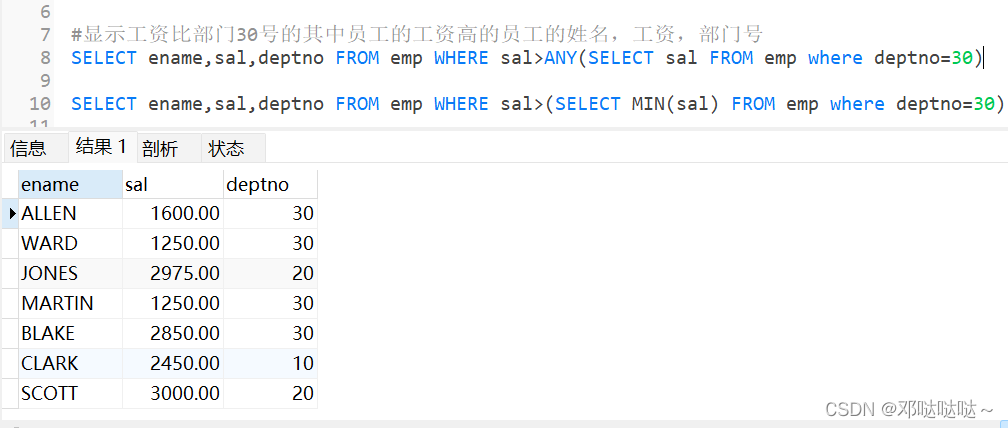
多列子查询
语法(字段1,字段2,.......)=(select 字段1,字段2,.......from .....where...)

表.*表示将表的所有列都显示出来
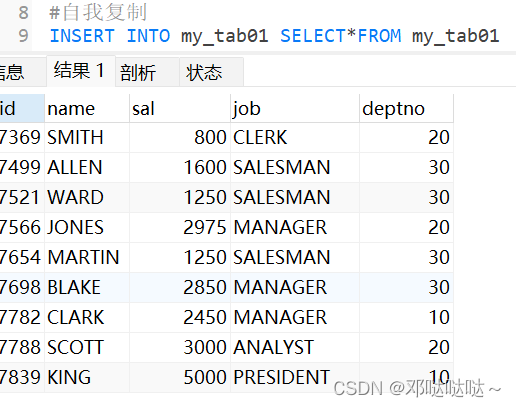
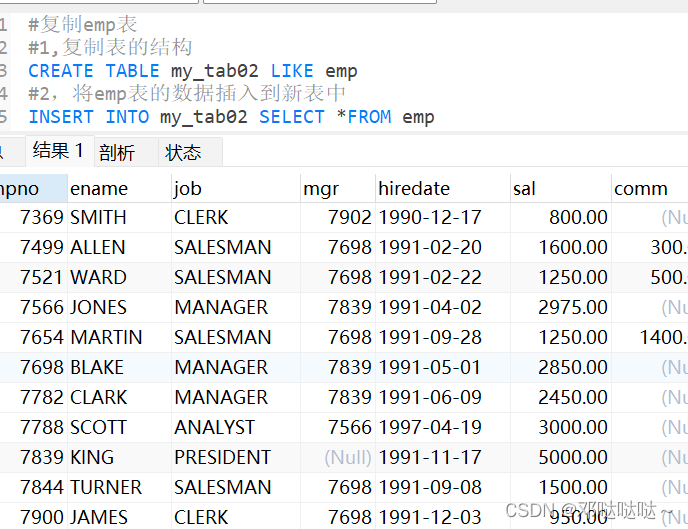
表中的记录复制
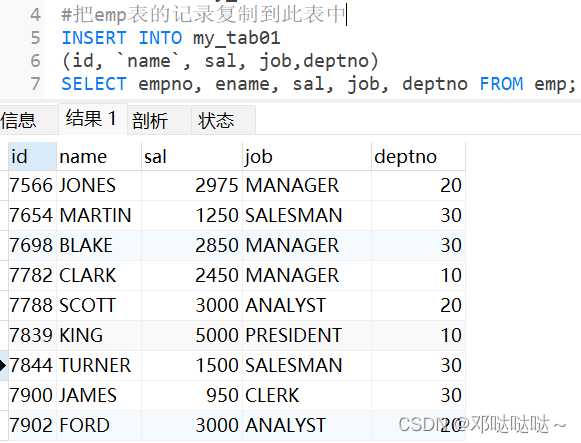
自我复制
复制表(结构,数据)

合并查询
- union all 将两个查询结果合并,不会去重
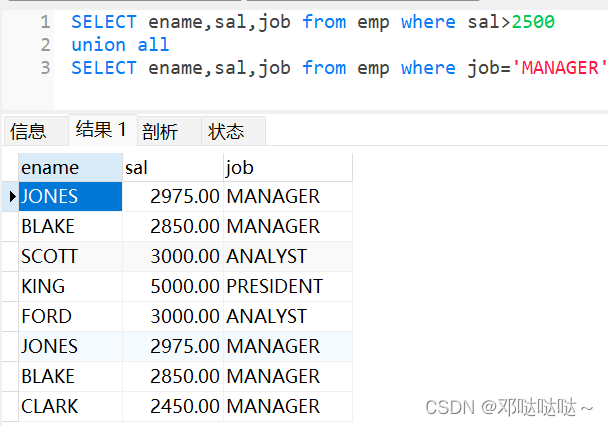
- union 将两个查询结果合并,会去重

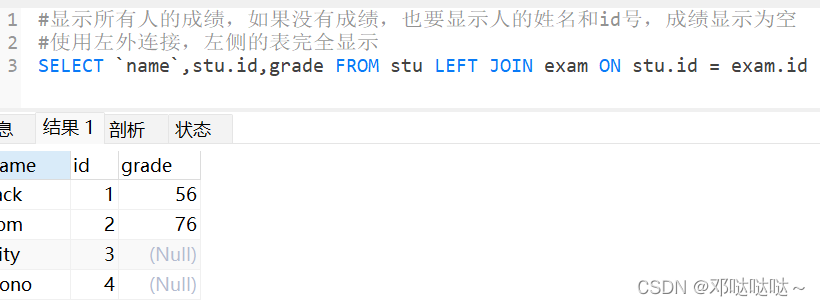
表外连接
- 左外连接:左侧的表完全显示
- 右外连接:右侧的表完全显示
语法:select ...from...表一 left(right) join 表二 on 条件
MySQL约束
约束用于确保数据库的数据满足特定的商业规则。包括:not null,unique key,primary key,check
primary key (主键)
用于唯一的标示表行的数据,当定义主键约束后,该列不能重复
语法:字段名 字段类型 primary key

id列表示主键,id的值不能重复
主键细节
1,primary key 不能重复而且不能为 null。
2,一张表最多只能有一个主键, 但可以是复合主键

如果id 和name都相同,才不能插入成功,其中一个相同都可以插入成功
not null(非空)
如果在列上定义not null,那么当插入数据时,必须为列提供数据
语法:字段名 字段类型 not null
unique(唯一)
当定义了唯一的约束后,该列的值不能重复
语法:字段名 字段类型 unique
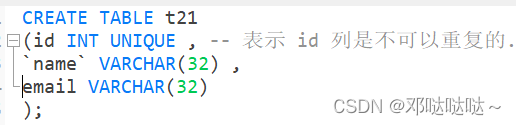
unique细节
1,如果没有指定not null,则unique 字段可以有多个null
2,一张表可以有多个unique字段
foreign key(外键)
用于定义主表和从表之间的关系:外检约束要定义在从表上,主表必须具有主键约束或unique约束,当定义外键约束后,要求外键列数据必须在主表的之间列存在或为null

外键细节
1.外键指向的表的字段,要求是primary key或者是unique
2. 表的类型是innodb,这样的表才支持外键
3. 外键字段的类型要和主键字段的类型一致(长度可以不同)
4. 外键字段的值,必须在主键字段中出现过,或者为null(前提是外键字段允许为null)
5. 一旦建立主外键的关系,数据不能随意删除了
NOT NULL DEFAULT' '---不允许为空
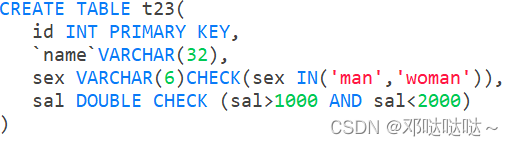
check
用于强制行数据必须满足条件(oracle和sql server均支持check,但MySQL5.7目前还不支持check,只做语法校验,但不会生效)
自增长
语法:字段名 整型 primary key auto_increment
添加自增长的字段方式
1,insert into xxx (字段1,字段2.....)values(null,'值"…);
2,insert into xxx (字段2.....)values('值1',’值2'.…);
3,insert into xxx values(null, '值1'.....)
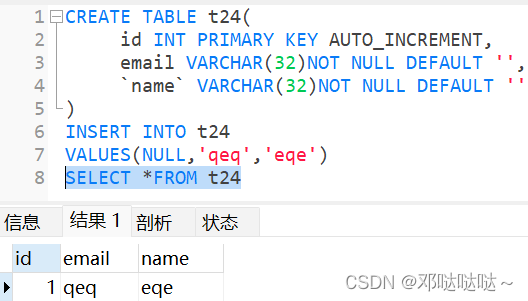
MySQL索引
索引的类型
1.主键索引,主键自动的为主索引(类型Primary key)
2·唯一索引(UNIQUE)
3.普通索引(INDEX)
4,全文索引(FULLTEXT) [适用于MylSAM]一般开发,不使用mysql自带的全文索引,而是使用:全文搜索Solr 和 ElasticSearch (ES)
如果某列的值,是不会重复的,则优先考虑使用 unique 索引, 否则使用普通索引
添加索引

删除索引
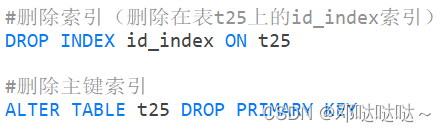
搜索索引

什么字段适合创建索引
1,较频繁的作为查询条件字段应该创建索引
2.唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
3.更新非常频繁的字段不适合创建索引
4.不会出现在WHERE子句中字段不该创建索引
事务
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功,要么全部失败。
当执行事务操作时(dml语句) ,mysql会在表上加锁,防止其它用户改表的数据.这对用户来讲是非常重要的
mysql 数据库控制台事务的几个重要操作:
1.start transaction-开始一个事务
2.savepoint 保存点名 -- 设置保存点
3.rollback to 保存点名-回退事务
4.rollback--回退全部事务
5.commit--提交事务,所有的操作生效,不能回退

事务细节
1.如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
2.如果开始一个事务,你没有创建保存点.你可以执行rollback,默认就是回退到你事务开始的状态
3.你也可以在这个事务中(还没有提交时),创建多个保存点.
4.你可以在事务没有提交前,选择回退到哪个保存点
5.mysql的事务机制需要innodb的存储引擎才可以使用,myisam不好使
6开始一个事务 start transaction,set autocommit=of
事务的隔离级别
概念:Mysql隔离级别定义了事务与事务之间的隔离程度。
1.多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性。
2.如果不考虑隔离性,可能会引发如下问题:
a,脏读(dirty read):当一个事务读取另一个事务尚未提交的改变(update,insertdelete)时,产生脏读
b,不可重复读(nonrepeatable read):同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复读。
c,幻读(phantom read):同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读。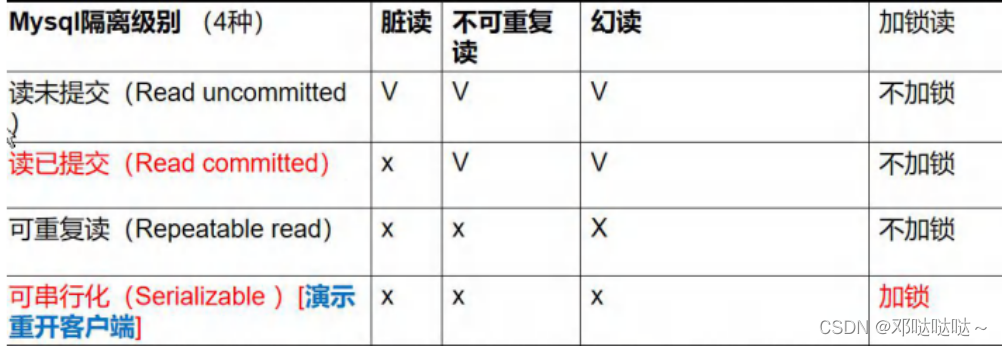
MySQL表类型和存储引擎
MySQL的表类型由存储引擎(StorageEngines)决定,主要包括MyISAM、innoDB、Memory等。
MySQL数据表主要支持六种类型,分别是:CSV、Memory、ARCHIVE、MRG MYISAM、MYISAM、InnoBDB。
这六种又分为两类,一类是“事务安全型”(transaction-safe),比如:InnoDB;其余都属于第二类,称为”非事务安全型”(non-transaction-safe)[mysiam和memory]。
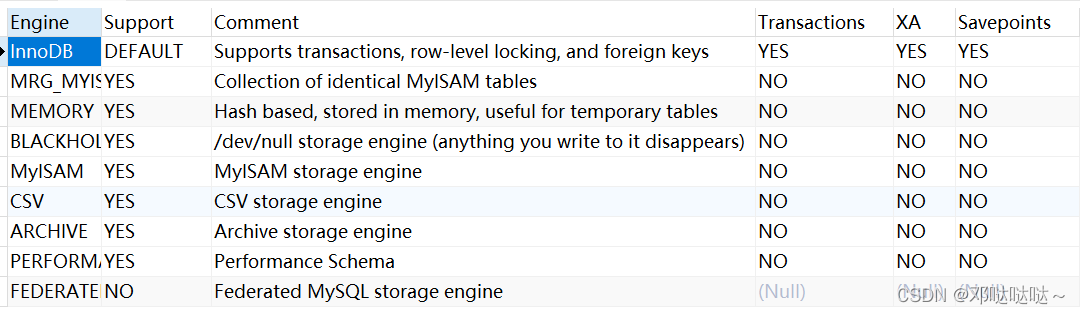
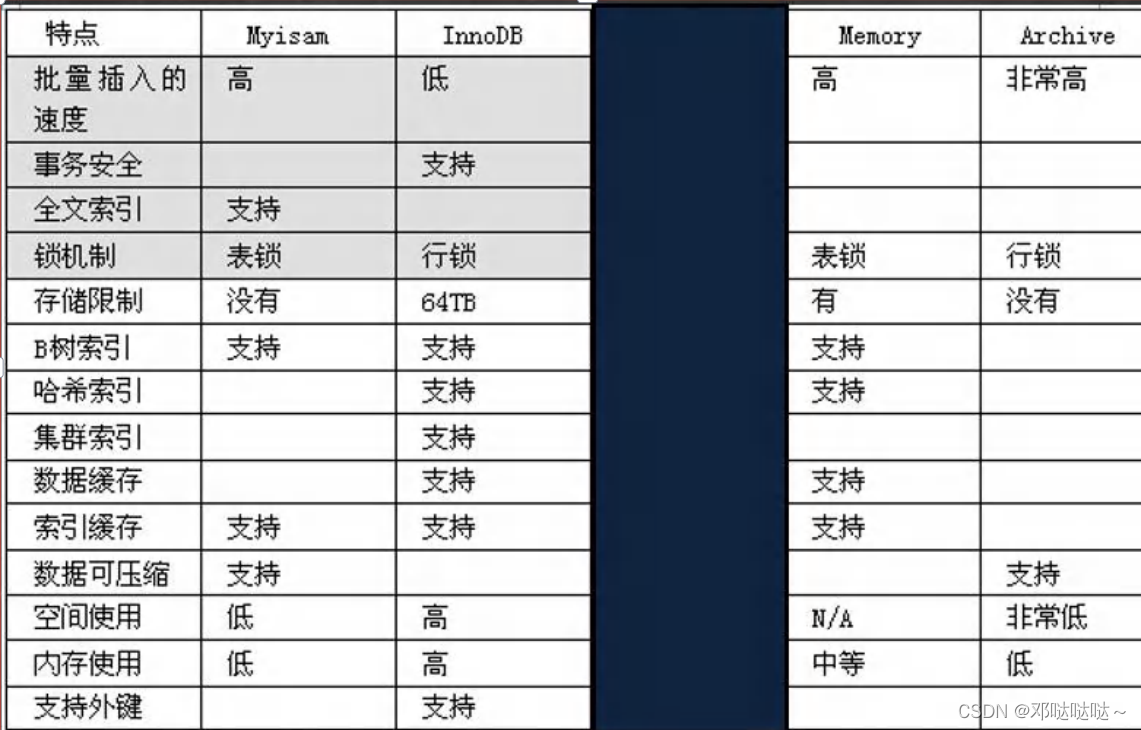
细节MyISAM、InnoDB、MEMORY
1.MyISAM不支持事务、也不支持外键,但其访问速度快,对事务完整性没有要求。
2. InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是比起MylSAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
3. MEMORY存储引擎使用存在内存中的内容来创建表。 每个MEMORY表只实际对应一个磁盘文件。MEMORY类型的表访问非常得快,因为它的数据是放在内存中的并且默认使用HASH索引。但是一旦MySQL服务关闭,表中的数据就会丢失掉,表的结构还在
练习:创建引擎为MYISAM的表

-- innodb 存储引擎-- 1. 支持事务 2. 支持外键 3. 支持行级锁-- myisam 存储引擎-- 1. 添加速度快 2. 不支持外键和事务 3. 支持表级锁-- memory 存储引擎-- 1. 数据存储在内存中 [ 关闭了 Mysql 服务,数据丢失 , 但是表结构还在 ]-- 2. 执行速度很快 ( 没有 IO 读写 ) 3. 默认支持索引 (hash 表 )如何选择表的存储引擎
1.如果你的应用不需要事务,处理的只是基本的CRUD操作,那么MyISAM是不二选择,速度快
2.如果需要支持事务,选择InnoDB。
3. Memory存储引擎就是将数据存储在内存中,由于没有磁盘I./0的等待,速度极快。但由于是内存存储引擎,所做的任何修改在服务器重启后都将消失。(经典用法 用户的在线状态().
修改存储引擎
ALTER TABLE 表名 ENGINE = 存储引擎
视图
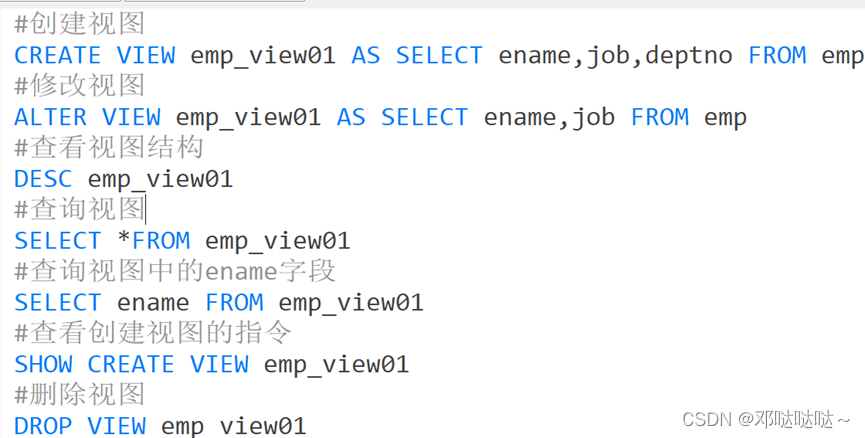
视图的细节
-- 1. 创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式: 视图名.frm)
-- 2. 视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete ]
-- 3. 视图中可以再使用视图

视图最佳实践
1.安全。一些数据表有着重要的信息。有些字段是保密的,不能让用户直接看到。这 n时就可以创建一个视图,在这张视图中只保留一部分字段。这样,用户就可以查询自己需要的字段,不能查看保密的字段。
2.性能。关系数据库的数据常常会分表存储,使用外键建立这些表的之间关系。这时,O 数据库查询通常会用到连接(JOIN)。这样做不但麻烦,效率相对也比较低。如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用JOIN查询数据。
3.灵活。如果系统中有一张旧的表,这张表由于设计的问题,即将被废弃。然而,很多应用都是基于这张表,不易修改。这时就可以建立一张视图,视图中的数据直接映射到新建的表。这样,就可以少做很多改动,也达到了升级数据表的目的。

