
热门标签
热门文章
- 1BERT微调—关系分类任务_实体关系分类任务
- 2html网页制作——【制作浪漫气球520告白相册】 HTML5七夕情人节表白网页源码 HTML+CSS+JavaScript_用网页写出520
- 3nacos持久化&集群部署_nacos vue
- 4Kubernetes基础篇-01- Kubernetes的发展史以及架构说明_kubernetes历史版本
- 5青云1000------华为昇腾310_青云1000开发板
- 6Hadoop中HDFS、Hive 和 HBase三者之间的关系_hive hdfs关系
- 7引擎开发_ 碰撞检测_GJK 算法详细介绍_sat gjk
- 8利用 Python 自动抓取微博热搜,并定时发送至邮箱_python爬取微博热搜并发送邮件
- 9Git clone出现问题以及解决办法_用git克隆github项目遇到的问题及解决方案
- 10redisson的锁的类型_Redisson分布式锁实现
当前位置: article > 正文
Milvus Cloud 向量数据库Reranker成本比较和使用场景_mivus 支持的reranker
作者:你好赵伟 | 2024-07-14 05:45:45
赞
踩
mivus 支持的reranker
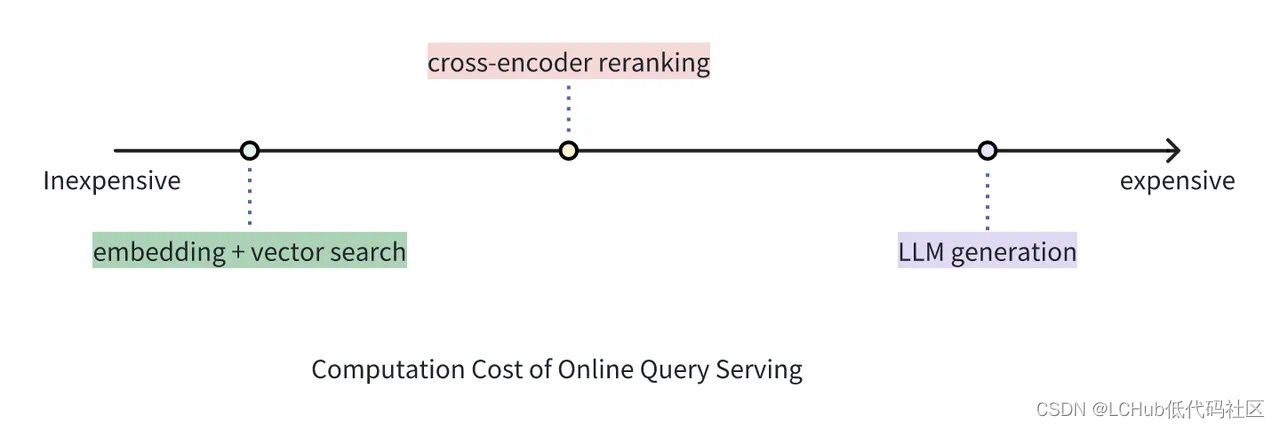
成本比较:向量检索 v.s. Cross-encoder Reranker v.s. 大模型生成
虽然 Reranker 的使用成本远高于单纯使用向量检索的成本,但它仍然比使用 LLM 为同等数量文档生成答案的成本要低。在 RAG 架构中,Reranker 可以筛选向量搜索的初步结果,丢弃掉与查询相关性低的文档,从而有效防止 LLM 处理无关信息,相比于将向量搜索返回的结果全部送进 LLM 可大大减少生成部分的耗时和成本。
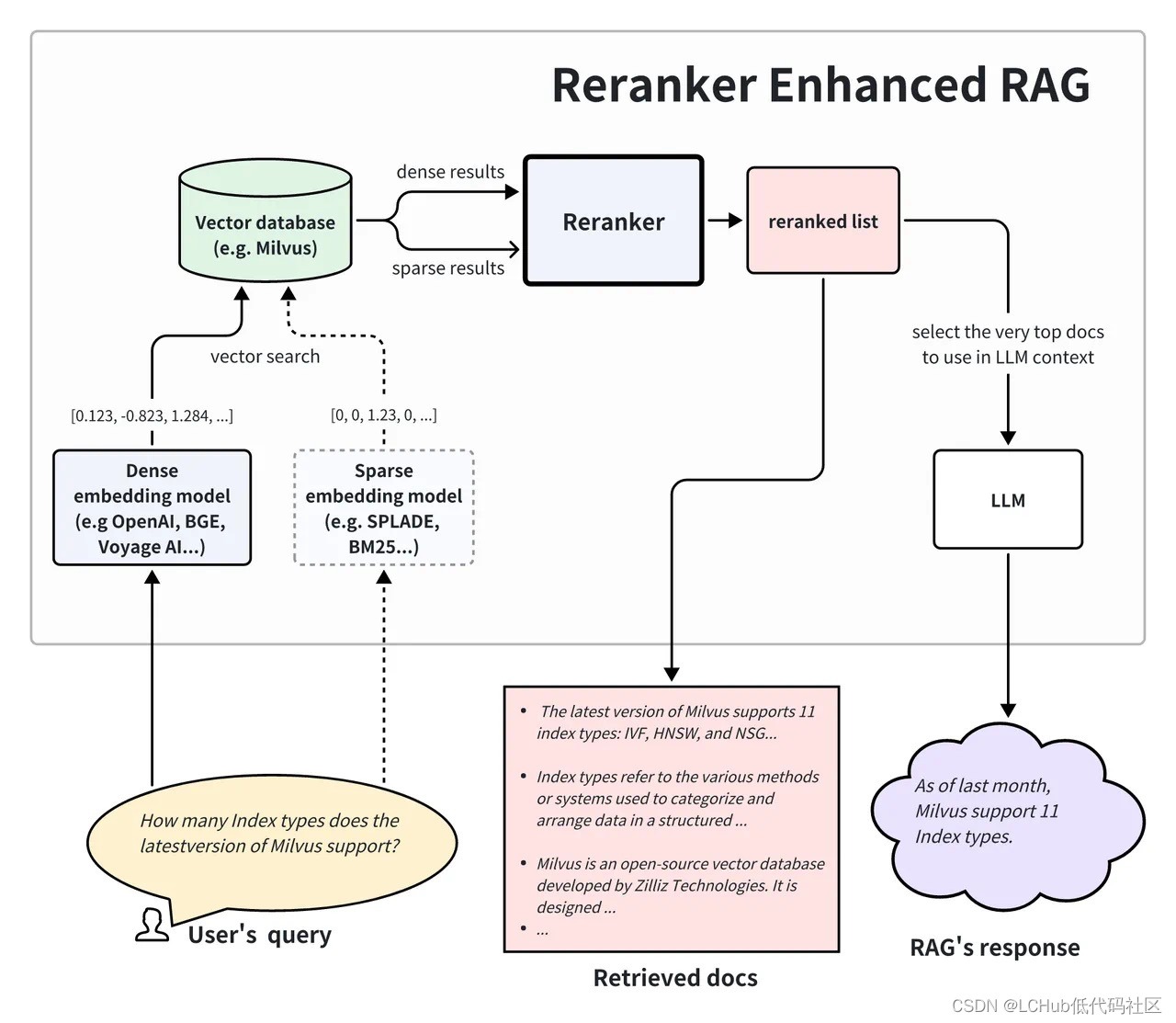
举一个贴近实际的例子:第一阶段检索中,向量搜索引擎可以在数百万个向量中快速筛选出语义近似度最高的 20 个文档,但这些文档的相对顺序还可以使用 Reranker 进一步优化。虽然会产生一定的成本,但 Reranker 可以在 top-20 个结果进一步挑出最好的 top-5 个结果。那么,相对更加昂贵的 LLM 只需要分析这 top-5 个结果即可,免去了处理 20 个文档带来的更高成本和注意力“涣散”的问题。这样一来,我们就可以通过这种复合方案平衡延迟、回答质量和使用成本。
哪种情况适合在 RAG 应用中使用 Reranker?
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/823393
推荐阅读
相关标签

