
- 1我在百科荣创企业实践——简易函数信号发生器(1)
- 2给公众号接入`FastWiki`智能AI知识库,让您的公众号加入智能行列_公众号接入ai
- 3生成式人工智能(AIGC):在软件开发中的助手与变革
- 4培训机构出来的程序员目前的就业前景怎么样?
- 56. 详解 IPSec 的 net2net-RSA 组网实践_xfrm 配置ipsec 中公钥、私钥、服务端证书、客户端证书详解
- 6Python模块multiprocessing & 实现多进程并发_python multiprocess
- 7LeetCode 打卡 Day 60 —— 234. 回文链表
- 8Metasploitable2 靶机漏洞(上)_metasploitable-linux-2.0.0靶机, 弱密码漏洞 1、mysql弱密码登录 2
- 9计算机网络网络层之层次化路由_层次化算力路由
- 10(2-5)基于内容的推荐:文本分类和标签提取_决策树标签怎么抽取
NLP干货: (1) 基于机器学习的文本分类_nlp干货 基于机器学习
赞
踩
目录
3.2 支持向量机(Support Vector Machine)
文本分类是NLP最常用的应用之一,这是基于文档内容将电子邮件、消息、推文或文章形式的文本文档分类为预定义类别的过程。在本章中,你将学习如何使用机器学习技术进行文本分类,并提供了代码进行实战,让我们开始吧。
首先加载所需的依赖库:
- # 依赖库
- import pandas as pd
- import random
- import time
- import joblib
- from sklearn.model_selection import train_test_split, RandomizedSearchCV
- from sklearn.feature_extraction.text import TfidfVectorizer
- from sklearn.metrics import classification_report, confusion_matrix
- from sklearn.linear_model import LogisticRegression
- import re
- import jieba
源数据的形式:
| case number | content | label |
| 0 | 文本内容1。。。 | 标签1 |
| 1 | 文本内容2。。。 | 标签2 |
一、数据预处理
在文本分类中,数据处理是一个关键的步骤,它可以影响模型的性能。以下是一些常用的数据处理技术:
1.1 数据清洗
包括去除文本中的特殊字符、标点符号、数字等,并进行大小写转换、去除HTML标签等操作,以保证文本数据的干净和一致性。
1.2 分词
将完整的句子拆分成词语,实现分词的常用库:jieba, SnowNLP, THULAC, TLNK等。
1.3 去停用词
删除对文本特征没有任何贡献作用的字词,例如语气词、人称助词等频繁表达的词语。
- # 数据预处理:清洗、分词、去停用词 ##
- def preprocess_text(content,words):
- print('开始数据预处理...')
- stopwords = pd.read_csv("C:/Users/xxx/Documents/NLP/data/Stopwords.txt", index_col=False,quoting=3, sep="\t", names=['stopword'], encoding='utf8')
- stopwords = stopwords['stopword'].values
- for line in range(len(content)):
- try:
- content[line] = content[line].lower()
- # 删除提及(例如:@zhangsan);删除URL链接;删除标签(例如:#Amazing);删除记号和下一个字符(例如:he's);删除数字
- content[line] = re.sub("\S+@\S+|https*\S+|#\S+|\'\w+|\d+", " ", content[line])
- # 删除特殊字符
- content[line] = re.sub(r'[’!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’!\[\\\]^_`{|}~]+', ' ',content[line])
- #删除两端空格;删除2个及以上的空格
- content[line] = re.sub('\s{2,}', " ", content[line])
- content[line] = content[line].strip()
- segs = jieba.lcut(content[line])
- segs = filter(lambda x: len(x) > 1, segs)
- segs = filter(lambda x: x not in stopwords, segs)
- segs = list(segs)
- Allsegs = " ".join(segs)
- words.append(Allsegs)
- except Exception as e:
- print ("error----"+content[line])
- continue
二、特征提取
在文本分类问题中,特征提取是一个重要的步骤,它将原始的文本数据转换为机器学习算法可以处理的数值特征。以下是一些常用的特征提取技术:
2.1 词袋模型(Bag of Words)
考虑所有词汇在训练文本中出现的频率作为权重。
2.2 TF-IDF模型
除了考量某一词汇在当前训练文本中出现的频率之外,同时关注包含这个词汇的其它训练文本数目的逆频率(即考虑词汇的重要程度)。
TF = 某个词在文档中出现的次数 / 文档的总词数
IDF=log(语料库中的文档数/(包含该词的文档数+1))
TF-IDF = TF * IDF
相比之下,训练文本的数量越多,TF-IDF模型的特征量化方式就更有优势。
- ## 文本向量化
- def Vectorize(sentences):
- ## 将得到的数据集打散,生成更可靠的训练集分布 ##
- random.shuffle(sentences)
- ## 用sk-learn切分数据,分成训练集和测试集 ##
- x, y = zip(*sentences)
- x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=10)
- ## TF-IDF向量化并保存特征集
- vec = TfidfVectorizer(analyzer='word', max_features=30000) ## 字典的最大词量
- vec.fit(x_train)
- print('(训练集,特征量) =', vec.transform(x_train).toarray().shape)
- print('测试集',len(x_test))
- return vec, x_train, y_train, x_test, y_test
输出:
三、模型选择和评估
3.1 朴素贝叶斯(Naive Bayes)
该算法分类思想是:对给定分类项目,在这个项目出现的条件下求出每个类别出现的概率,概率最大的,则这个分类项目被判断属于哪个类别,公式如下:

注解:假设待分类文本Xi属于给定文本类别Y里面的某一类Yj
NativeBayes = MultinomialNB(alpha=0.1).fit(vec.transform(x_train), y_train)3.2 支持向量机(Support Vector Machine)
SVM则是属于广义线性分类器的二分类算法,其特点是经验误差的最小化和几何边缘区域的最大化,因此SVM也称为最大边缘区域分类器,找到一个可以分离全部数据样本的空间是其主要思想,使得采样集中的全部数据到这个超平面的距离最短。点到超平面公式如下:
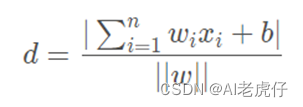
注解:假设P (X1,X2..Xn) 为样本的中的一个点,其中Xi表示为第i个特征变量, ∣∣w∣∣为超平面的2范数,即w向量的模长。
- # kernel:核函数,将线性不可分的特征映射到高维空间
- # C:正则化系数,越大对模型惩罚越高,容易过拟合。越小对模型惩罚越小,容易欠拟合
- SVM = SVC(C=1, kernel='linear').fit(vec.transform(x_train), y_train)
3.3 随机森林(Random Forest)
随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定,参考图例如下: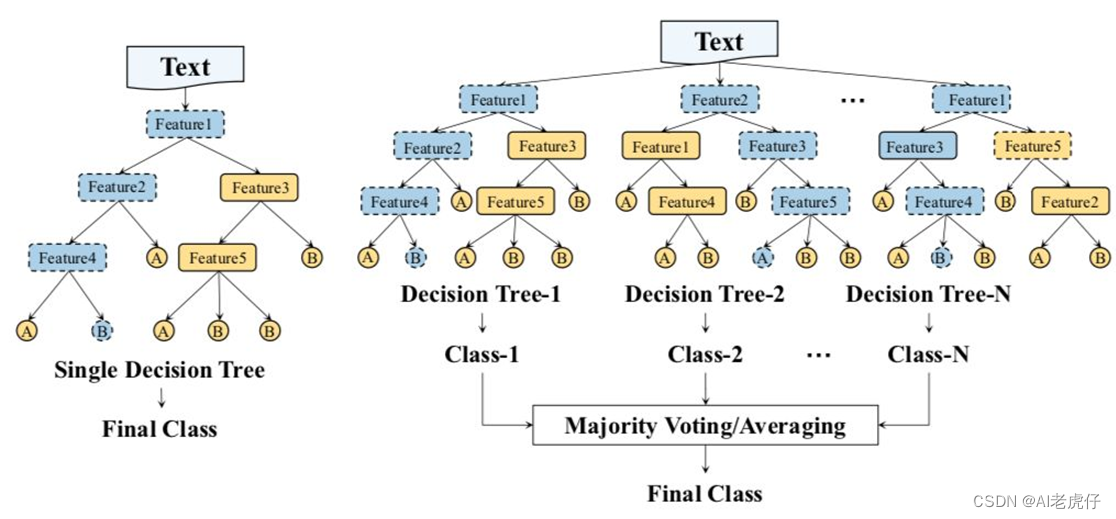
注解:左边是决策树,右边是随机森林,虚线轮廓的节点表示决策路由的节点,此例子代表有5个特征来预测每个文本属于Class-1、Class-2...。
- # oob_score(out of bag):是否采用袋外样本来估计泛化精度,树的生成过程不会使用所有样本,未使用的样本就叫袋外样本
- Forest = RandomForestClassifier(oob_score=True, class_weight="balanced").fit(vec.transform(x_train), y_train)
3.4 逻辑回归(Logistic Regression)
LR算法虽称之回归,但实际上是分类模型,常用作二分类。其算法的本质是:假设数据服从连续型的概率分布,然后使用极大似然估计做参数的估计。
- # penalty:正则化参数, solver:优化算法选择参数, multi_class:分类方式选择参数, C:正则化系数的倒数
- LogisticRegression = LogisticRegression(C=100,penalty='l2',solver='newton-cg').fit(vec.transform(x_train), y_train)
3.5 模型训练与评估
通过混淆矩阵可得出以下4个评估指标:
| 预测值\真实值 | Positive | Negative |
| Positive | TP | FP |
| Negative | FN | TN |
准确率:acc = 精确率:precision =
召回率:recall = F1值:f1 =
- # 构造逻辑回归分类器
- def BuildModel():
- print('分类器开始工作...')
- begin = time.perf_counter()
- Classifier = LogisticRegression(C=10).fit(vec.transform(x_train),y_train)
- y_pred = Classifier.predict(vec.transform(x_test))
- print("\n逻辑回归评估指标:\n", classification_report(y_test,y_pred))
- acc = Classifier.score(vec.transform(x_test), y_test)
- end_time = time.perf_counter()
- run_time = end_time - begin
- print('准确率为:', acc, '建模运行时间', run_time, 's')
- y_pred_proba = [max(max(Classifier.predict_proba(i))) for i in vec.transform(x_test)]
- TestResult = pd.DataFrame(confusion_matrix(y_test, y_pred), columns=['label1', 'label2'],index=['label1', 'label2'])
- print('\n',TestResult)
- return vec,Classifier
-
-
- if __name__ == '__main__':
- ## 导入数据 ##
- df = pd.read_excel("C:/Users/xxx/Desktop/Data.xlsx")
- df = df.dropna() # 清除缺失值
- # # ## 转换为列表 ##
- content = df.content.values.tolist()
- label = df.label.values.tolist()
- words = []
- # ## 调用预处理函数,并保存分词库 ##
- preprocess_text(content, words)
- df['CutWords'] = words
- df.to_excel("C:/Users/xxx/Desktop/Data-clear.xlsx",index=False)
-
- ####### 调用已保存过的cut words, 以免每次测试模型都要重新分词 ##
- Cut_df = pd.read_excel("C:/Users/xxx/Desktop/Data-clear.xlsx")
- Cut_df = Cut_df.dropna()
- CaseNumber = Cut_df['case number'].values.tolist()
- cut_content = Cut_df.content.values.tolist()
- cut_words = Cut_df.CutWords.values.tolist()
- label = Cut_df.label.values.tolist()
- print(pd.value_counts(label))
- sentences = list(zip(cut_words, label))
- Content_Words = list(zip(CaseNumber, cut_content, cut_words))
- ## 语料库向量化
- vec, x_train, y_train, x_test, y_test = Vectorize(sentences)
-
- # ## 调用建模函数
- vec,Classifier = BuildModel()
- ## 保存 model
- joblib.dump(vec,'C:/Users/xxx/desktop/Features.m')
- print('特征集保存成功')
- joblib.dump(Classifier, 'C:/Users/xxx/desktop/Model.m')
- print('模型保存成功!')
输出: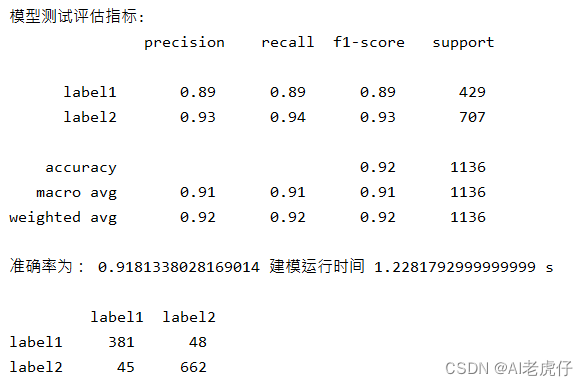
四、小结
至此,相信你已成功训练出分类模型,完整代码:NLP-基于机器学习的文本分类源代码。然而当我们做文本分类的项目时通常需要不断地改进模型以达到目标的准确率,因此下一篇文章 NLP干货: (2) 文本分类模型的调优 会讲述分类模型的几种调优方法。

