
- 1Android Studio gradle下载失败_gradle-8.0-bin.zip 下载失败
- 2ONLYOFFICE 8.1 版本桌面编辑器测评
- 3开源项目:机遇与挑战共存的创新之路
- 4YOLOv10改进 | 主干/Backbone篇 | 轻量级网络ShuffleNetV1(附代码+修改教程)
- 5百度安全X盈科全球数据合规服务中心:推进数据安全及合规智能化创新领域深化合作
- 6Win10下配置CUDA8.0+Tensorflow1.3+Python3.6_cuda 8.0安装tensorflow1.3.0
- 7MongoDB 安装和数据导入导出问题_mongodb compass如何 export data
- 8Google的guava缓存学习使用_谷歌guava缓存
- 9HBase HMaster启动和停止
- 10Flutter和React Native(RN)的比较
Google Gemini API快速上手_google.generativeai
赞
踩

一、前言
12月6日,谷歌发布新一代大模型Gemini的demo, 同时,Bard已将模型更新为Gemini Pro
Gemini 是谷歌目前最新最强的大语言模型,支持多模态(文字,图片,音频,视频等等)处理
美国时间12月13日,Gemini API对公众开放,本文将教学Google Generative AI的简易使用流程。
1、适用范围和声明
如果你只是想体验Gemini,请直接前往 Bard
本文适用场景:批量处理大模型会话;Hackthon;CS课程设计;大模型相关创业demo,等
本文不适用:商业用途
本文使用的一切工具与数据均非内部工具和数据。 NOT Google internal only
本文可随意转载,复制代码
2、开始前的准备
完全不懂什么是大模型?听不懂很多术语?阅读 LLM 概念指南
2. 科学上网
==================================================================
1 生成式AI平台 MakerSuite (Google AI Studio)
MakerSuite是一个基于浏览器的 IDE,用于使用Generative language model(生成式语言模型)进行原型设计。借助 MakerSuite,可以快速试用模型并试验不同的prompt(提示)
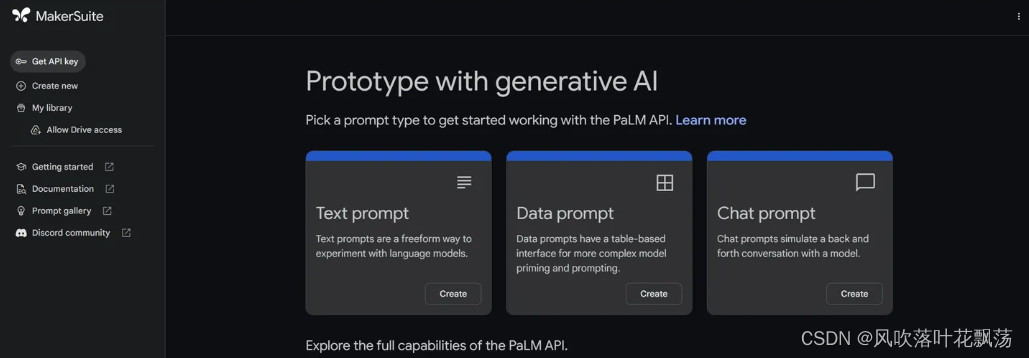
MakerSuite 主界面 12.13更新前
左侧Create new将提供四种不同的方式与模型互动

Freeform prompt
Freeform prompt 文本/图片提示:输入一段提示,LLM将根据提示进行一段创作

Structured prompt
Structured prompt 结构化提示:提供表格输入,可以输入至多500组【输入,输出】的案例,根据案例,LLM可学习并基于案例处理新的提示

Chat prompt
Chat prompt 聊天提示:与chatgpt和bard类似的聊天框模式,支持输入历史会话
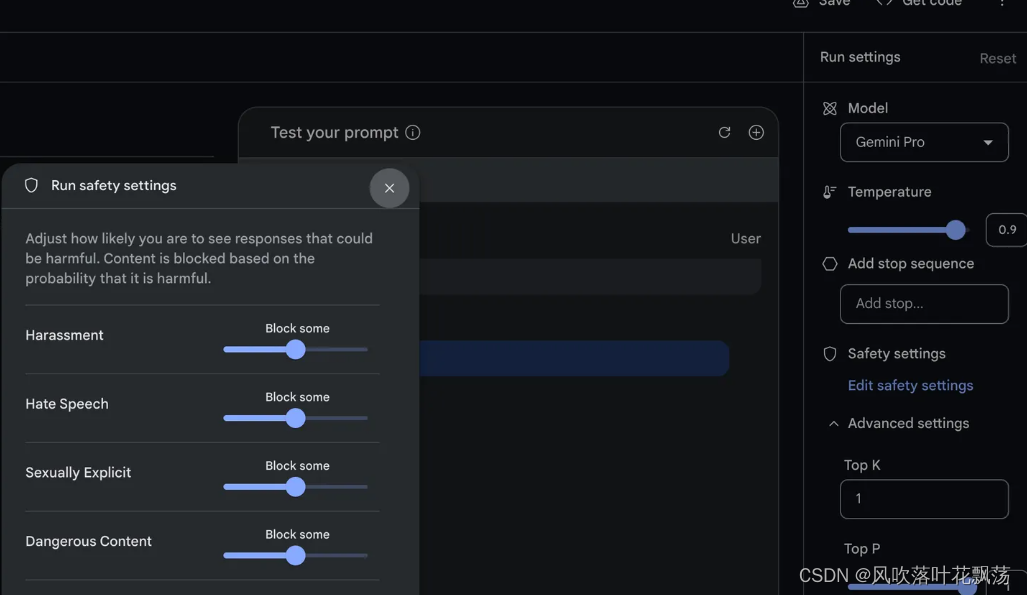
模型参数
模型参数设定 (第一次使用建议全部保持默认):
Model模型选择Gemini Pro(文字),Gemini Pro Vision (图片)
Temperature温度决定模型的创造力,越高越想象力丰富,越低越稳定
Safety settings安全设定中可以调整对骚扰,仇恨,性,恐怖等言论的屏蔽程度
Top K: 选择输出token的方式,top 1 表示永远输出评分最高的回答,top 10 表示在前10评分的回答中取样输出一个回答
Top P: 选择输出token的方式,如果前x个回答的概率之和高于p,则【Top P,其中P=p】等价于【Top K,其中K=x】
2 Fine-tuning model模型调整
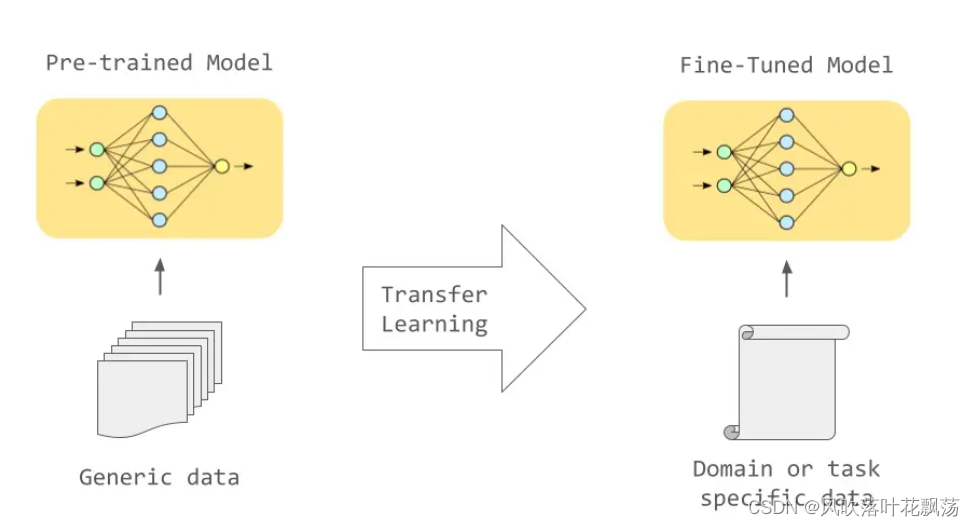
模型预训练与模型调整的关系
大模型的预训练耗费海量数据与计算资源,包括Palm,Gemini在内的所有大模型都可称为预训练模型。
预训练的要求极高,超出个人或中小企业的能力范围。但是针对特定的需求和任务,个人可以用适量(<1000)数据和计算资源调整模型,使得模型特化某种任务解决的能力。
点击左方Create new,点击Tune Model
调整模型
点击import导入csv格式的训练数据,并选择1-多列为input,1-多列为output,做为调整模型的训练集
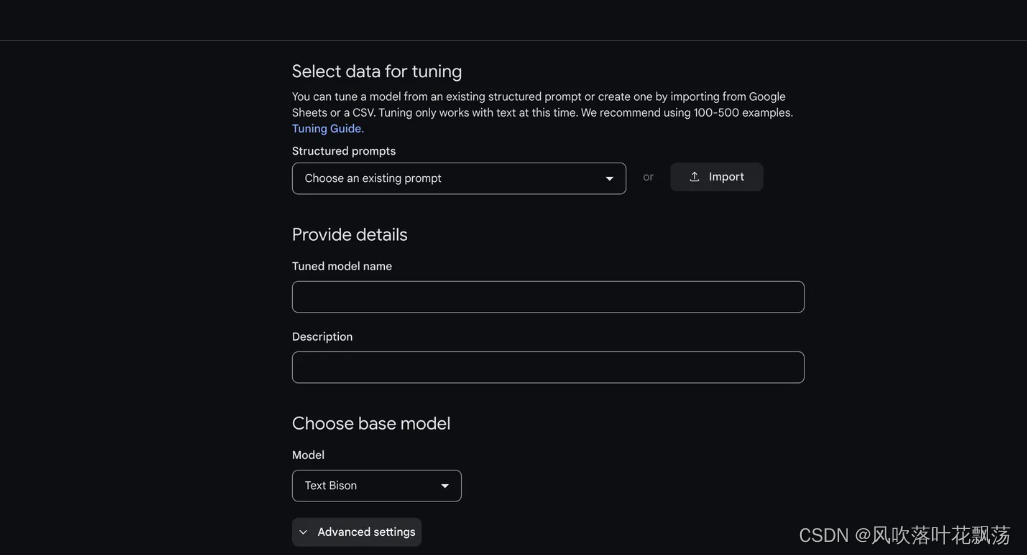
导入训练集
训练参数设定(第一次使用建议默认)
Model模型选择Text Bison,这是老模型PaLM2,新的Gemini截至目前还没可用
Tuning epochs 整个训练集的完整训练遍历次数
Batch size 一次训练迭代中用于验证的样本数量,越大越容易过拟合,越小越容易欠拟合
Learning rate 训练迭代中调整参数的强度,越大越容易过拟合,越小越容易欠拟合
点击Tune开始自动调参。模型调整完毕后,可以在上个环节的各种提示测试中使用自己的新模型
3 使用API,调用预训练模型
点击左侧Get API key
点击Create API key in new project生成API key,复制下来
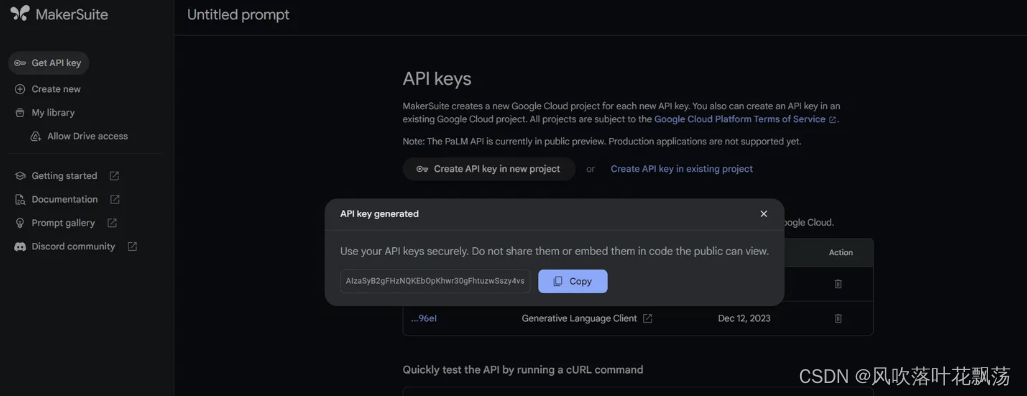
API key 生成
回到刚才的模型页面,点击右上角Get code,其中会包含cURL,js,python,kotlin,swift,五种语言的调用API的代码,用刚才复制的替换代码中的 YOUR_API_KEY
以python为例,先安装插件
pip install google-generativeai
- 1
然后调用API
import google.generativeai as genai
#换成你的api key
genai.configure(api_key="YOUR_API_KEY")
#模型参数
generation_config = {
"temperature": 0.9,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(model_name="gemini-pro", generation_config=generation_config, safety_settings=safety_settings)
#输入提示
prompt_parts = [ "Hello world", ]
#输出回答
response = model.generate_content(prompt_parts)
print(response.text)
使用python文件读写,可以批量得到大量LLM回答
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4 使用API调用自己调整的模型
如果你把上面的python程序中,model参数替换成你自己的模型,会遇上这样的报错
PermissionDenied: 403 Request had insufficient authentication scopes
是因为访问自己的模型需要OAuth身份验证。
获取OAuth身份验证需要前往谷歌云,生成个人密钥并下载到本地
这一步较为繁琐,Google有比较详细的逐步教程 https://developers.generativeai.google/tutorials/oauth_quickstart
完成以上身份验证步骤后,在python中可以用如下代码查看你能访问的所有模型
import google.generativeai as genai
print('Available base models:', [m.name for m in genai.list_models()])
print('My tuned models:', [m.name for m in genai.list_tuned_models()])
- 1
- 2
- 3
- 4

