
- 1Dagger2和它在SystemUI上的应用_systemui dagger
- 2使用Windows插件imagex实现wim镜像多合一_imagex制作系统镜像
- 3Git使用教程(很详细)_git 操作流程
- 4部署kafkamanager
- 53D和人脸的应用场景#ComfyUI Pro节点更新
- 6Elasticsearch_分词器、搜索文档以及原生JAVA操作_elasticsearch分词器使用 java
- 7【一起啃书】《机器学习》第六章 支持向量机_机器学习第六章
- 8语音听写与合成--(讯飞语音识别与合成&&百度语音识别)_百度语音听写
- 9Java中字符串占位替换、字符串拼接、字符串与Collection互转的方式_java string占位符替换
- 10python使用sequoiadb巨杉数据库_pysequoiadb
人工智能基础-Python之Pandas库教程_python人工智能基础.pd
赞
踩
文章目录
前言
Pandas
python三大库numpy,pandas以及matplotlib在人工智能领域有广泛的营运。下面我将介绍一些关于Pandas的一些简单教程
一、Pandas是什么?
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
还有Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。
不是大熊猫哦~
二、使用步骤
1.引入库
import pandas as pd
print(pd.__version__)
# 2.2.1
- 1
- 2
- 3
2.数据读取
2.1 数据类型
| 数据类型 | 读取方法 |
|---|---|
| csv\tsv\txt | pd.read_csv |
| excel | pd.read_excel |
| mysql | pd.read_sql |
2.2 数据读取
本文主要介绍csv的使用方式,采用的数据集是飞浆中的 波士顿房价预测中文版
1.常见操作
head():查看前几行数据,默认为5
tail():查看后几行,默认是5
shape():查看数据的形状
- 1
- 2
- 3
import pandas as pd f_path=r'/Users/zhangqingjie/files/x1/class_work/pandas_prac/housingPrices_train.csv' read=pd.read_csv(f_path) print(read.head()) # Id MSSubClass MSZoning ... SaleType SaleCondition SalePrice # 0 1 60 RL ... WD Normal 208500 # 1 2 20 RL ... WD Normal 181500 # 2 3 60 RL ... WD Normal 223500 # 3 4 70 RL ... WD Abnorml 140000 # 4 5 60 RL ... WD Normal 250000 # # [5 rows x 81 columns] print(read.tail()) # Id MSSubClass MSZoning ... SaleType SaleCondition SalePrice # 1455 1456 60 RL ... WD Normal 175000 # 1456 1457 20 RL ... WD Normal 210000 # 1457 1458 70 RL ... WD Normal 266500 # 1458 1459 20 RL ... WD Normal 142125 # 1459 1460 20 RL ... WD Normal 147500 # [5 rows x 81 columns] print(read.shape) # (1460, 81)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
info():查看数据集的行数、列数、列的数据类型、非空值的数量以及内存使用情况
- 1
print(read.info()) # <class 'pandas.core.frame.DataFrame'> # RangeIndex: 1460 entries, 0 to 1459 # Data columns (total 81 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 Id 1460 non-null int64 # 1 MSSubClass 1460 non-null int64 # 2 MSZoning 1460 non-null object # 3 LotFrontage 1201 non-null float64 # 4 LotArea 1460 non-null int64 # 5 Street 1460 non-null object # 6 Alley 91 non-null object # ... # 77 YrSold 1460 non-null int64 # 78 SaleType 1460 non-null object # 79 SaleCondition 1460 non-null object # 80 SalePrice 1460 non-null int64 # dtypes: float64(3), int64(35), object(43) # memory usage: 924.0+ KB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
describe():返回美列的数据信息,如总数,平均数,方差,均值,分位数等
- 1
print(read.describe())
# Id MSSubClass ... YrSold SalePrice
# count 1460.000000 1460.000000 ... 1460.000000 1460.000000
# mean 730.500000 56.897260 ... 2007.815753 180921.195890
# std 421.610009 42.300571 ... 1.328095 79442.502883
# min 1.000000 20.000000 ... 2006.000000 34900.000000
# 25% 365.750000 20.000000 ... 2007.000000 129975.000000
# 50% 730.500000 50.000000 ... 2008.000000 163000.000000
# 75% 1095.250000 70.000000 ... 2009.000000 214000.000000
# max 1460.000000 190.000000 ... 2010.000000 755000.000000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.txt读取
注意:csv是默认以逗号为分隔符的,但是txt不是,所以要特意指出
需要制定几个参数
sep='分隔符'
header=None表示没有标题
names=[]:表示指定标题
- 1
- 2
- 3
- 4
import pandas as pd f_path=r'/Users/zhangqingjie/files/x1/class_work/pandas_prac/THUOCL_caijing.txt' read=pd.read_csv(f_path,sep='\t',header=None,names=['名称','代码']) print(read) # 名称 代码 # 0 发展 1934814 # 1 部门 1709250 # 2 政府 1617499 # 3 经济 1396619 # 4 服务 1386428 # ... ... ... # 3825 中国民营经济周刊 1 # 3826 瓦房店轴承股份有限公司 1 # 3827 东碳 1 # 3828 华银电力 1 # 3829 资本运作 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.pandas的数据结构
3.1 Series
一维数据,一行或者一列
存带标签的一维数据
1.属性
这是一些常见的属性,感兴趣的小伙伴可以试试~
不一一举例了
values:返回 Series 中的值
index:返回 Series 中的索引
dtype:返回 Series 中元素的数据类型。
name:返回 Series 的名称。
ndim:返回 Series 的维度
shape:返回 Series 中数据的形状
size:返回 Series 中元素的数量
empty:返回一个True(若为空)
axes:返回一个包含 Series 索引和数据轴标签的列表
values_counts():返回一个包含 Series 中唯一值及其出现次数的 Series。
astype(dtype):将 Series 中的数据类型转换为指定的类型。
isnull():返回一个布尔型的 Series,表示 Series 中的缺失值。
notnull():返回一个布尔型的 Series,表示 Series 中的非缺失值。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.创建Series
1.用列表创立索引
可以看到,左侧是自动生成的索引,右侧是数据

还可以查索引和值

当然也可以指定索引创建

2.用字典创建Series
直接把字典转换成索引

3.查询
类似于查询字典操作

如果要查询多个值,可以传入一个列表。
但是!!!注意返回值的类型仍然是Series

3.2 DataFrame
二维数据,多行多列,可以将之当做一个表格
既有行索引index,又有列索引columns

1.创建DataFrame
1.多个字典创建
可以看到,字典变成了表格一样的东西,这个就是DataFrame

查一下他的三个属性

注意!!!,大家有没有发现不同,查c0lumn索引的时候的数据类型是object,于是我们查一下他的类型

可以看到,
如果查的的是单行单列,返回的是一个Series
如果查的是多行多列,返回的仍然是DataFrame
4.查询数据
除了要介绍的loc外,还有其他的一些查询方式,暂且不一一举例了,以后慢慢补充的
data.iloc
data.where
data.query
- 1
- 2
- 3
举例数据如下

4.1 data.loc 根据行列标签值进行查询
先介绍一个语法
**set_index()**
参数说明
key:数据表中的某列/列标签列表/数组列表,需要设置为索引的列。
drop:删除用作新索引的列,默认为True,删除。
append:是否将列附加到现有索引,默认为False,否。
inplace:表示当前操作是否对原数据重新,默认为False,否。
verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为False,将提高该方法的性能,默认为False。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
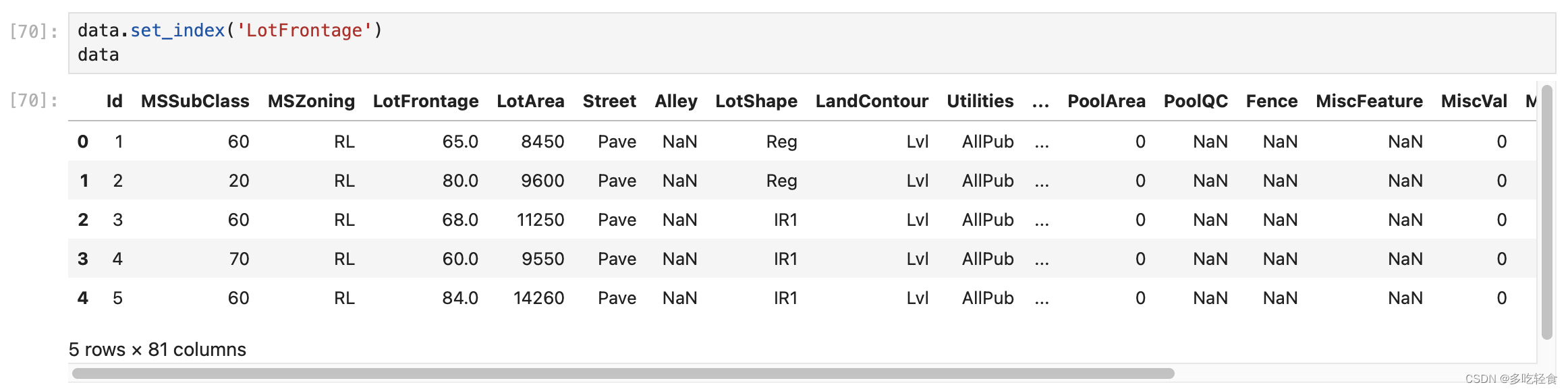
设置索引为街道链接LotFrontage ,若不设置任何参数,将该索引提前

若将inplace设置为True,表示对原数据进行更新

如果没有inplace那么原数据不变
1.使用单个label值查询数据
直接loc[行,列]

2.使用值列表批量查询数据
当然也可以传入列表
注意,传入一个列表参数返回series,传入两个返回dataFrame

3.使用数值区间进行范围查询
行和列都可以按照区间进行查询

4.使用条件表达式查询
此外还可以结合‘&’,'|'进行与或操作

5.使用函数查询
1.使用lambda表达式
name=lambda [列表名]: 表达式
上下是等价的~
def add(x, y):
return x+ y
print(add(3,4))
add = lambda x,y:x+y
print(add(3,4))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

2.自己定义函数
loc[]内部调用函数的时候,不强制在函数后面写上 (data)。但是如果加了括号,内部一定是要写相应的dataframe名字

也可以选列名
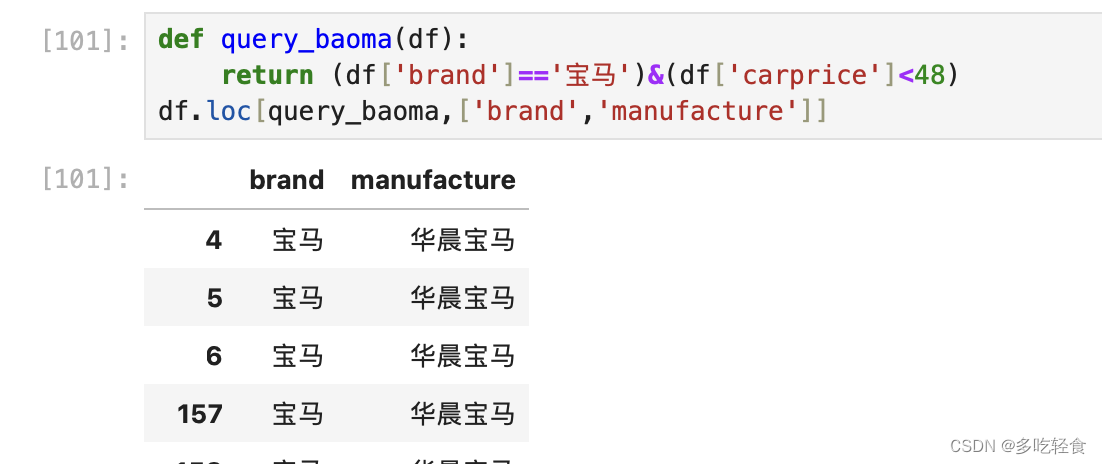
4.2 query
数据
1.基本语法
query(),括号里面内容是类似sql语句的内容,
用and,or,not进行条件判断

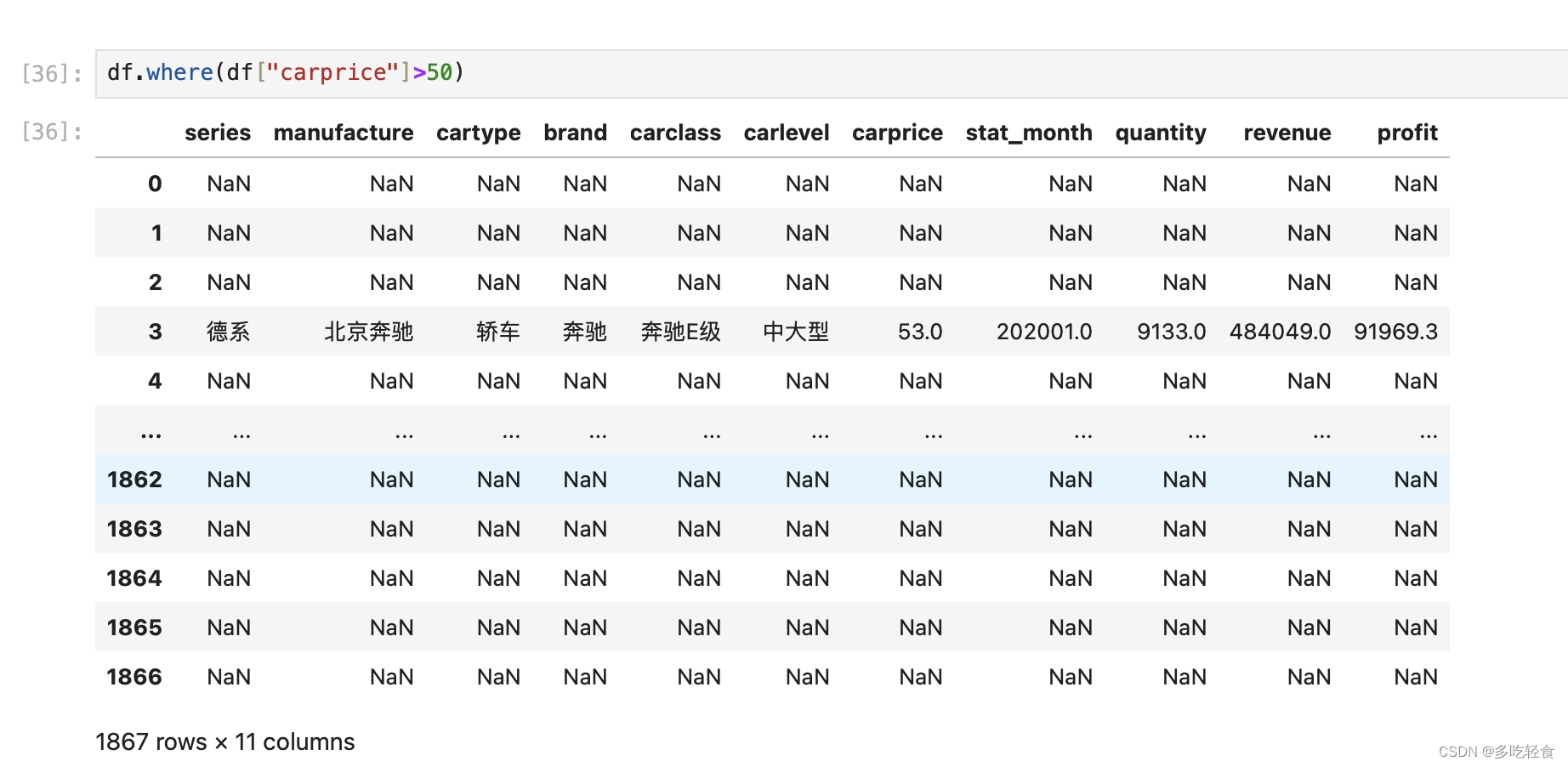
4.3 where
如图所示~
4.4 小结
大家记住,loc是最重要的就好了
5.过滤日期时间
数据例子

第一步:使用pd.to_datetime这个函数,他的作用是将字符串转换为Timestamp格式,转成这个格式之后就可以转换多种格式的时间字符串了
在format的格式字符串中,各种时间元素都有特定的字符表示,例如:
%Y表示四位数的年份,
%m表示两位数的月份,
%d表示两位数的日期,
%H表示小时数(24小时格式),
%M表示分钟数,
%S表示秒数。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
第二步:使用strftime变成自己想要的时间形式,他的作用是将时间元组格式化为字符串

找2015年8月的数据

6.新增数据
数据集展示

6.1 直接赋值
最后一行等于MSS+Lot

6.2 apply
apply()有两个参数
第一个是fun:函数名
第二个是axis:
返回的是一个series对象,它的内容有两种情况:
若为0,则是DataFrame的index索引
若为1,则是DataFrame的columns索引
- 1
- 2
- 3
- 4
- 5
- 6

6.3 assign
分配一个新的列到DataFrame中,返回的是一个对象,并不是直接赋值

直接复制也行,只不过我这里用的是lambda表达式
最棒的是,他可以一次增加多行

6.4 分条件赋值
先设置一个空列,然后中括号里面放条件语句

7.统计函数
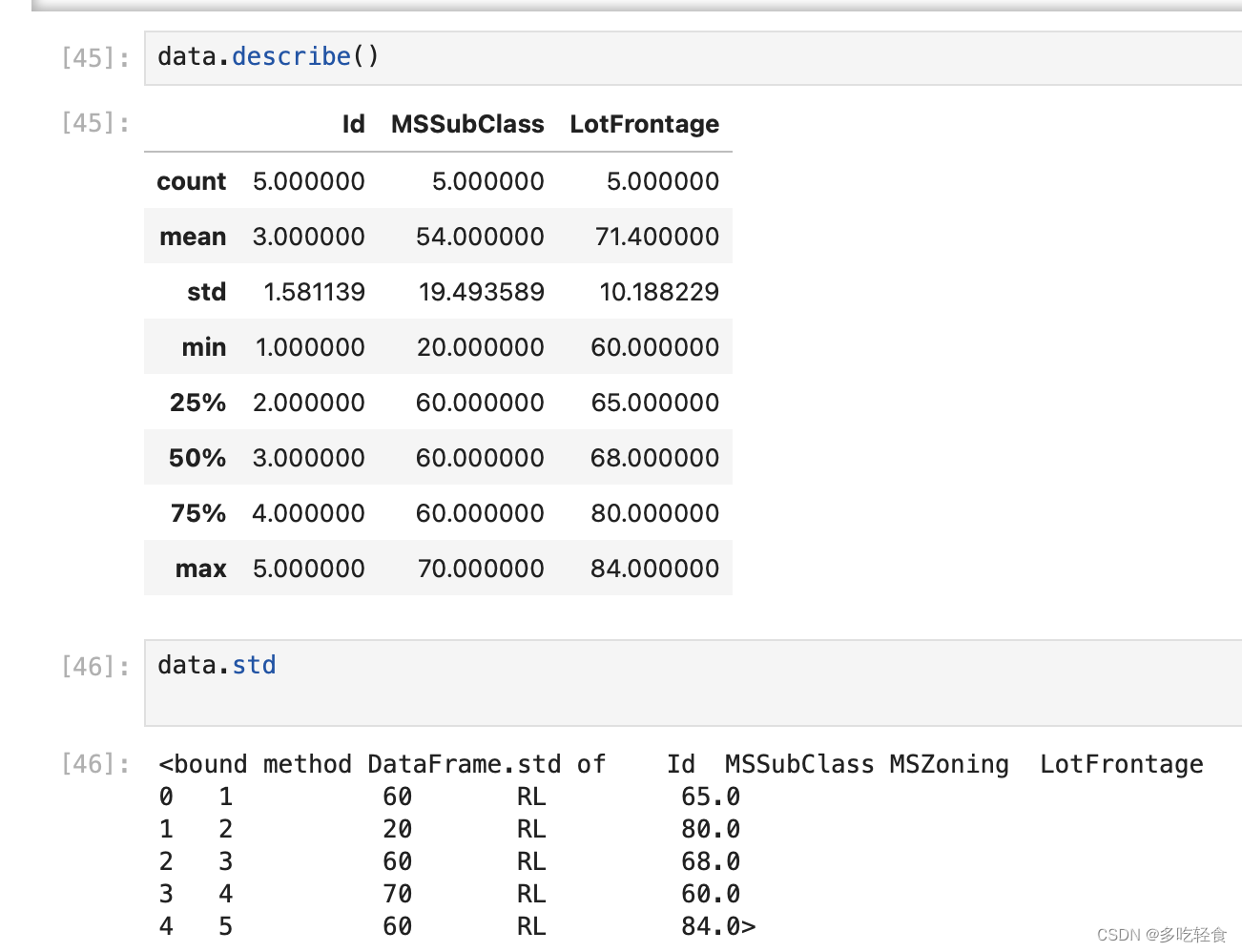
7.1汇总统计
直接describe函数,当然也可以指定其中之一
7.2 唯一性去重和按值计数
1. 唯一去重
一般用于查看包含哪些不同的值

2.按值计算
记录数据出现的次数,降序排列

3.相关系数和协方差(常用哦~)
协方差矩阵和相关系数矩阵,机器学习中计算距离度量的时候会用到的

当然也可以单独两个进行

8.对缺失值的处理
表格数据

介绍一些方法
8.1 isnull和notnull:
是否为空值,可以用于dataframe和series
第一种情况是df的情况,第二种是series的情况

8.2dropna:丢弃、删除空值
axis:删除行还是列(0:index,1:columns),默认为0
how:(any:任何值为空都删除,all:所有值为空才删除)
inplace:(如果为TRUE则修改当前的dataframe,否则是返回一个新的dataframe)
- 1
- 2
- 3

8.3fillna:填充空值
value:用于填充的值(还可以是字典)
method:(ffill:用起那一个不为空的值填充,bfill:后一个不为空的值填充)
axis:(按行还是按列)
inplace:(如果为TRUE则修改当前的dataframe,否则是返回一个新的dataframe)
- 1
- 2
- 3
- 4
两种填充方式:

当然也可以直接全部填充

最后保存

打开文件一看,保存成功啦!

9.排序
原数据

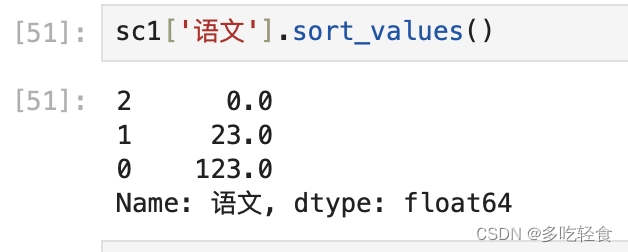
9.1 Series排序
series.sort_values()
参数说明:
ascending:True为生序排序
inplace:是否修改
- 1
- 2
- 3
- 4
9.2 DataFrame排序
DataFrame.sort_values()
参数说明:
by:可以传列名或者列表,实现多列和单列排序
ascending:bool或List,(生序还是降序),如果是list对应by的多列
inplace:同上
- 1
- 2
- 3
- 4
- 5
by的用法是优先列表中第一个元素的排序,在第一个元素相等的基础上,在按照第二个排序

另一个例子:
按照第一个元素生序排序,第二个元素降序排序

10.字符串处理
10.1 全部属性
以下是我从官方文档中复制的所有的方法,大家可以尝试一些,我会调一些重要的举例子




10.2.注意事项
- 先获取Series的字符串属性,在属性上调用函数
- 只能在字符串的列上使用,不能再数字的列上使用
- DataFrame没有字符串的属性和处理方法
10.3 栗子~
初始数据

-
一些基础的属性

-
使用startwith,contains等得到的bool的Series可以做条件查询

11.merge合并操作
merge(left,right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
* left,right:要合并的的dataframe或者有name的Series。
* how:join类型,‘left’, ‘right’, ‘outer’, ‘inner’。等价于sql里的左、右连接,外连接和内连接
* on:join的key,left和right都需要有这个key。
* left_on:left的df或者series的key。
* right_on:right的df或者seires的key。
* left_index,right_index:使用index而不是普通的column做join。
* suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是(‘_x’, ‘_y’)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里就要讲一下sql里的左右连接,内外连接了。
left:左连接
right:右连接
inner:内连接
outer:外连接
这里是例子数据:

11.1外连接(交集)

11.2内连接(并集)

11.4左连接
以左边df的‘配偶’元素为基准,进行合并
若右边的df中没有匹配的元素,空值处理

11.4右连接
以右边df的‘配偶’元素为基准,进行合并。
若左边的df中没有匹配的元素,空值处理

12.concat合并
pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False)
参数解释
objs:待合并的所有数据集,一般为列表list,list中的元素为series或dataframe
axis:合并时参考的轴,axis=0为基于行合并;axis=1为列合并,默认为0
join:连接方式为内连接(inner)or外连接(outer)
- 1
- 2
- 3
- 4
原数据
行合并

列合并

13.merge和concat的区别
merge与concat的区别
1、merge默认内连接,concat默认外连接
2、merge的参数有四个【内、外连接,左右连接】,concat是利用axis进行合并
3、merge合并范围广,可以通过索引和列进行合并,concat只能进索引合并
13.分组groupby的用法
13.1创建groupby对象

13.2聚合操作agg
英语是aggregation(聚合)
有如下方法

常用使用方法如下:

13.3 transfrom
pandas的一个转换函数,对DataFrame执行传入的函数后返回一个相同形状的DataFrame。
transform(func, axis=0, *args, **kwargs):
func: 用于转换数据的函数,函数必须满足传入一个DataFrame能正常使用,或传递到DataFrame.apply()中能正常使用。
func可以接收函数的名字、函数名的字符串、函数组成的列表、行/列标签和函数名组成的字典。
axis: 设置按列还是按行转换。设置为0或index,表示对每列应用转换函数,设置为1或columns,表示对每行应用转换函数。
args: 传递给函数func的位置参数。
kwargs: 传递给函数func的关键字参数。
- 1
- 2
- 3
- 4
- 5
用法如下:
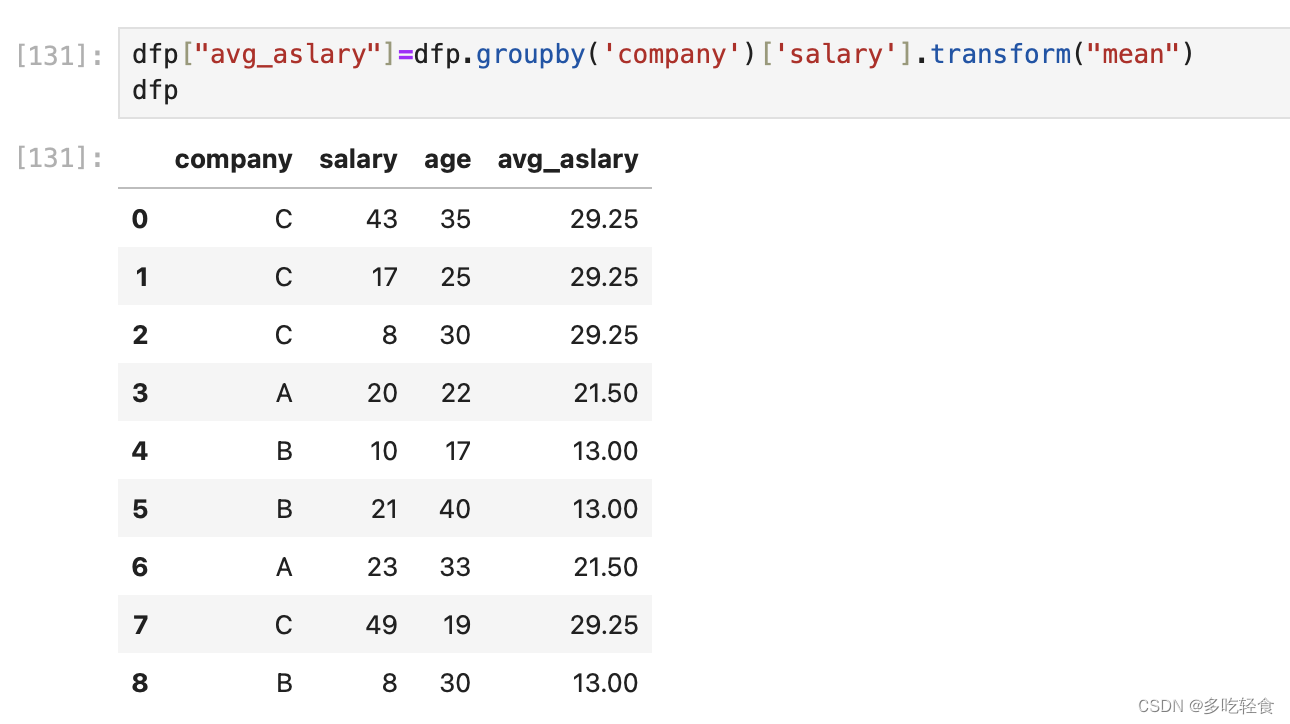
这个group是13.1中设置的

13.4 apply()
定义一个函数,进行回调。
例子为找到每个公司中年纪最大的信息
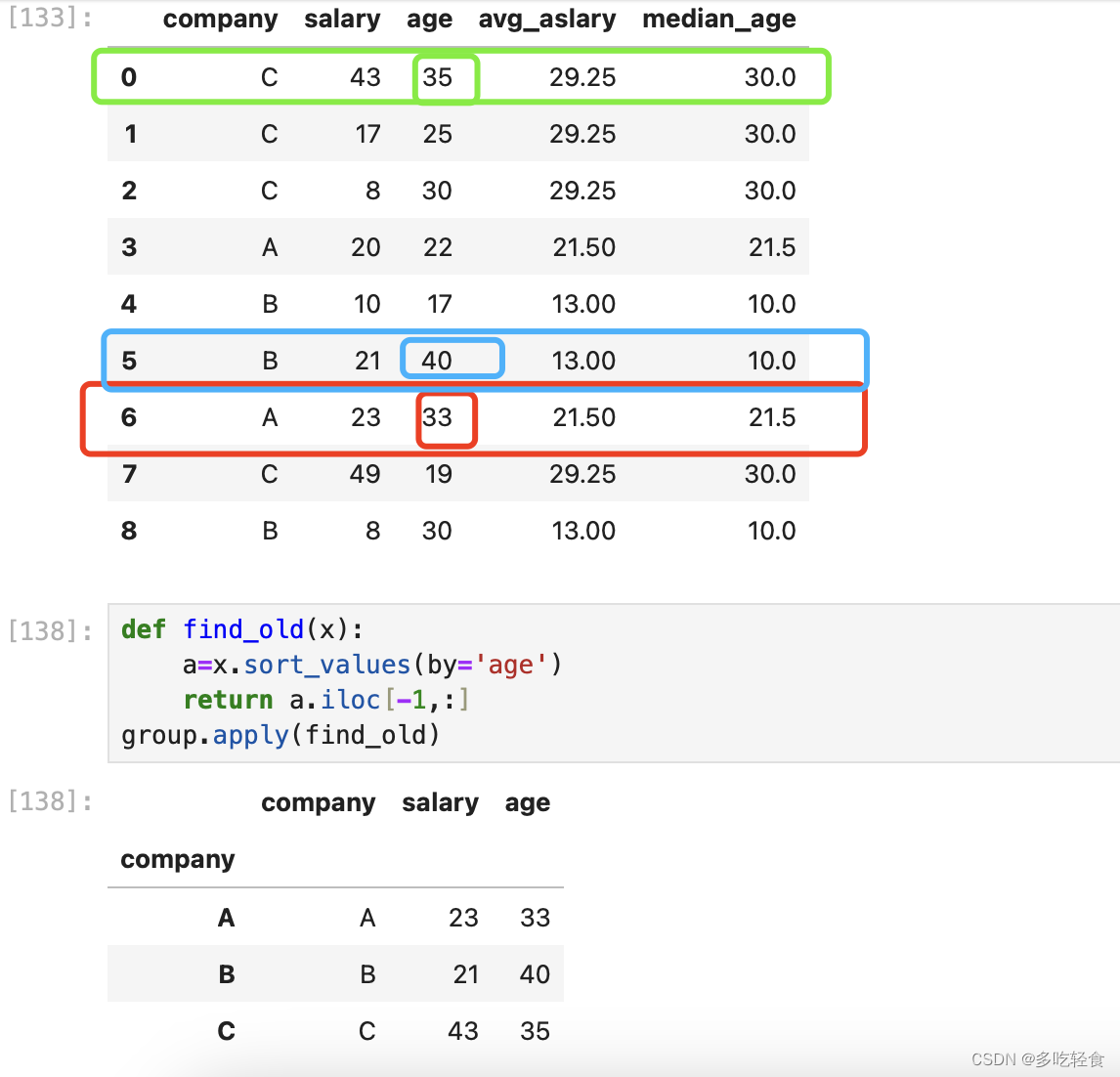
14. 删除重复值
先构造一个df

14.1duplicated()
查看是否重复的bool数组

14.2.drop_duplicates()
删除重复元素,默认是保留第一个

还可以保留最后一个,加上一个keep='last’的参数

14.3.针对某一列删除重复元素
这样列上也没有重复了,而且是按照最后一个保留

15 轴
轴按照官方的解释是
axis=0表示从行的方向从左到右,从上倒下

axis=1表示从列的方向从上到下,从左到右

这个轴的概念怎么说的都有,众说芸芸,我的见解是这样的。
axis=0代表行
axis=1代表列

以axis=0为例子
当执行计算平均数、求和等方法的时候,他的结果是把一个二维表格变成一个一维数据(例子中,吧三行四列的数组变成了一行四列),也就是说将数据向行方向降维(多行变一行)。

列方向的例子


总结
这就是pandas 的全部教程啦,本文篇幅较长,包括了最基础的pandas的应用,道友们可以作为参考!
要是想进一步了解pandas的用法建议还是多动手,实战中才能真正的进步。
也许会很累,但是也不要忘记周围的美景,春末夏初,路边的柳树早已长出来枝芽。
把酒祝东风,且共从容,道友,加油!!!

