
- 1LNMP动态网站环境部署
- 2一款开源、简洁、支持全平台的高速下载神器
- 3git 新建分支并切换到该分支_Git 命令 - 分支与合并命令
- 4git整合分支的两种方法——合并(Merge)、变基(Rebase)_git变基和合并用哪个
- 5Vue3DraggableResizable知识点_vue-draggable-resizable
- 6【测试资源】测试新手可放心冲的几个学习网站,团队分享学习清单_学习接口测试可用的网站有哪些
- 7【ARM版银河麒麟安装windows应用程序】_银河麒麟安装wine
- 8固定资产管理系统建设方案_固定资产系统方案
- 9深入解析香橙派 AIpro开发板:功能、性能与应用场景全面测评_香橙派可以用来干嘛
- 10java算法:插入排序_快速排序算法
7个强大的文字转语音TTS引擎_文字转语音 开源
赞
踩
大家好,文本到语音(TTS)技术让机器能以人声般自然地“说话”,架起了人机沟通的新桥梁。开源TTS引擎以其开放性和经济性,成为热门工具,为智能应用注入活力。
文本到语音(TTS)引擎,是一种将文字信息转化为口语表达的智能软件。它通过自然语言处理(NLP)技术深入分析文本内容,并借助语音合成器,创造出接近人类自然语音的输出。TTS引擎广泛应用于虚拟助手、导航系统和辅助工具等领域,为用户带来便捷的语音交互体验。
开源文本到语音(TTS)引擎是一项宝贵的技术工具,它将书面文本转化为口语,大大增强了应用程序的可访问性、自动语音响应功能以及虚拟助手的交互能力。这些引擎大多由一群热情的开发者共同打造,并在开放源代码的许可下发布,允许任何人自由使用、修改和分发软件。
本文分享7个好用的开源文本到语音(TTS)引擎,为技术选择提供清晰的视角和实用的参考。以下是一些知名的开源TTS引擎:
1.MaryTTS多模态交互架构
项目链接:https://github.com/marytts/marytts
TTS系统的设计采用了灵活且模块化的架构,内嵌了先进的语音构建工具。此工具能够将录制的音频数据转化为个性化的新语音,拓宽了TTS技术的应用边界。
下面是这个引擎背后的架构概览图:
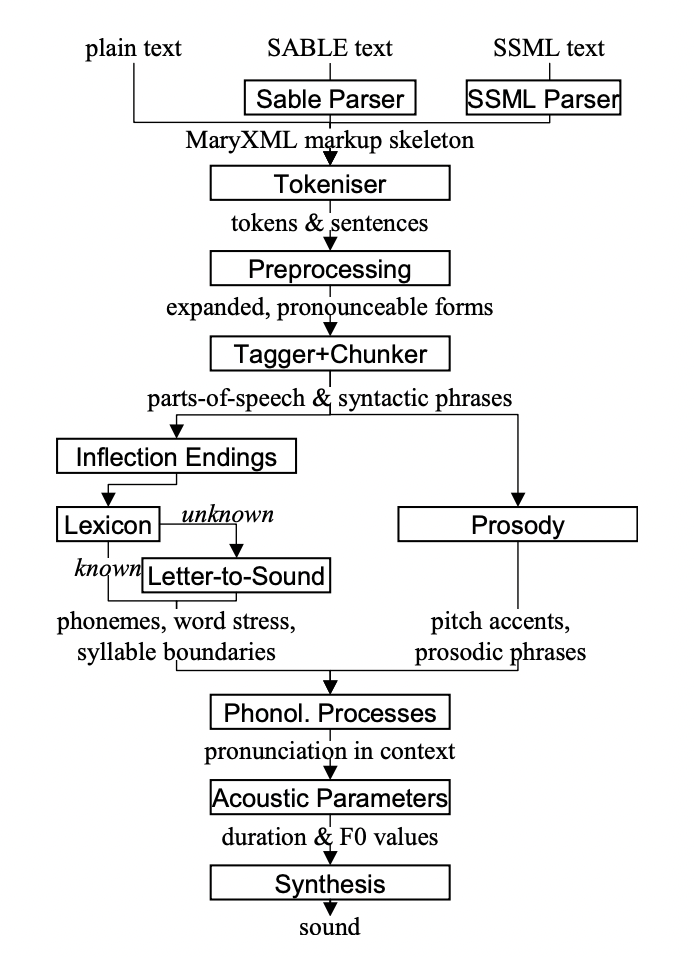
这个架构包括一些基本组件:
-
标记语言解析器:负责读取并解析文本中的标记语言。
-
处理器:接收解析后的文本,执行必要的操作,如转换为语音或生成视觉输出。
-
合成器:生成最终的音频或视觉输出,添加语调、重音等语音特征,以提升语音的自然度。
优点:MaryTTS架构具有高度的可定制性,允许开发者创建自己的解析器、处理器和合成器以满足特定需求。能够实现软件在不同平台和应用中的灵活集成。
缺点:由于其高度可定制的特性,对于不熟悉标记语言和文本到语音技术的开发者来说,可能需要面对一定的学习曲线。
2.eSpeak
项目链接:https://github.com/espeak-ng/espeak-ng

eSpeak是一款轻量级的开源语音合成软件,支持英语及其他多种语言,能够生成清晰且易于理解的语音输出。以其简洁的界面和小巧的体积,eSpeak在用户中赢得了良好的口碑。
这款软件的跨平台特性尤为突出,能够在Windows、Linux、macOS以及Android等多种操作系统上流畅运行,为用户提供了广泛的应用场景。
优点:易于使用,支持多种语言和声音。
缺点:功能和定制选项有限,且用C语言编写。
3.Festival语音合成系统
项目链接:https://github.com/festvox/festival
Festival 由爱丁堡大学开发,为构建语音合成系统提供了通用框架,并包含各种模块的示例,被广泛用于研究和教育目的。
优点:高度可定制,适合研究目的。
缺点:对于初学者来说难以使用,需要一些编码知识。
4.Mimic
项目链接:https://github.com/MycroftAI/mimic1
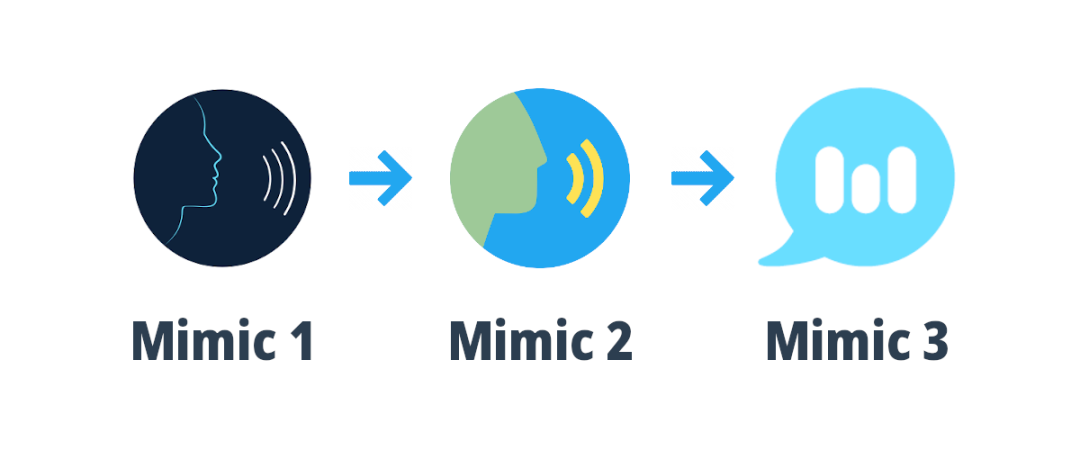
由Mycroft AI开发,Mimic能够产生高度自然的语音,它包括基于Festival语音合成系统的Mimic 1,以及使用深度神经网络进行语音合成的Mimic 2。
优点:提供传统和现代的语音合成方法,并支持多种语言。
缺点:文档有限。
5.Mozilla TTS
项目链接:https://github.com/mozilla/TTS
基于深度学习的TTS引擎致力于创造出更加自然、接近人类语音的合成效果。这一技术通过采用现代神经网络架构,特别是序列到序列的模型,来实现对语音的高度模拟和优化。
优点:使用先进技术进行更自然的语音,可以免费使用。
缺点:语言支持有限。
6.Tacotron 2
项目链接:https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2
Tacotron 2虽不直接定位为一个语音引擎,但其作为神经网络模型架构,在生成自然语音方面发挥着关键作用。该模型的开源版本已经发布,不仅推动了语音合成技术的进步,还激发了行业内的多项创新。
这个系统允许用户使用原始剧本合成语音,不需要任何额外的韵律信息。
优点:由NVIDIA开发,适合用作神经网络模型。
缺点:需要一些技术知识来实现。
7.ESPnet-TTS
项目链接:https://github.com/espnet/espnet
该 TTS 引擎是 ESPnet 项目的一部分,设计用于端到端语音处理,包括语音识别和合成。它使用现代深度学习技术生成语音。
优点:现代且灵活,支持多种语言。
缺点:需要一些技术知识来实现。

