
- 1全国计算机OFFICE二级考试大纲,全国计算机等级考试二级MSOffice高级应用考试大纲...
- 2Java开发环境搭建(详细)
- 3我把Java基础编程及思维导图整理的超级详细,谁都能看懂_java思维导图笔记
- 4Keil uVision5 5.38官方下载、安装及注册教程_keil uvision5下载
- 5Python中八种基本排序方法_buchiyexiao
- 66种打包Python代码的方法,让你的程序变成exe应用!_python打包exe
- 7LAN技术 -- MAC地址表、端口安全_获取lan口mac地址
- 8《C语言程序设计》课程总结报告_pintia.cn
- 9python安装后怎么打开?这三种方法你一定要会_python怎么打开_python 打开
- 10Python 开机自启动_python autostart 设置开机自启
人工智能生成文本检测在实践中使用有效性探讨
赞
踩
人工智能辅助撰写文章的技术现在无处不在!ChatGPT已经解锁了许多基于语言的人工智能应用程序,人工智能在任何类型的内容生成中的使用都已经达到了以前前所未有的高度。
在诸如创意写作之类的工作中,人们被要求创造自己的内容。但是由于人工智能在这些任务中的普及和有效性,很人工智能很有可能会被滥用。所以能够获得可靠和值得信赖的工具来检测人工智能生成的内容是一个非常重要的问题。所以本文将提供构建这样一个工具的思路和技术规范。

文本检测的思路
我们的目标是“像GPT这样的大语言模型有多大可能生成全部或部分文本?”
所以我们就要从日常入手,比如:一个典型的日常场景,你母亲对你说下面这句话的可能性有多大?
亲爱的,请在晚上8点前上床睡觉;亲爱的,请在晚上11点后上床睡觉。
我们会猜测前者比后者更有可能发生,因为你已经建立了对周围世界的理解,并对哪些事件更有可能发生有了感觉。
这正是语言模型的工作原理。语言模型学习周围世界的一些东西,他们学会预测给出一个不完整句子的下一个符号或单词。
在上面的例子中,如果你被告知你的妈妈正在说某事,而到目前为止她说的是“亲爱的,请上床睡觉”,那么这个句子最有可能的延续是“8:00 pm之前”,而不是“11:00 pm之后”。因为父母都会让孩子早睡觉,对吧
语言模型的困惑度是什么?
困惑:困惑的状态;混乱;不确定性。
在现实世界中如果你遇到意想不到的情况,例如:当你在路上开车时,看到一个红绿灯,那么你就不太可能感到困惑,而如果你看到一只野生动物穿过城市的街道,那么你肯定就会产生很大的疑问。
对于一个试图预测句子中下一个单词的语言模型,如果它使用一个我们不期望的单词来完成句子,我们说这个模型会让我们感到困惑。
具有低困惑的句子看起来像下面这样
1、It’s a sunny day outside.
2、I’m sorry I missed the flight and was unable to reach the national park in time.
具有高度困惑的句子看起来像下面这样:
1、It’s a bread day outside.
2、I’m convenient missed light outside and could not reach national park.
如何计算语言模型所做预测的困惑度呢?
困惑度 perplexity
语言模型的复杂性与能够毫不意外地预测句子的下一个符号(单词)的概率有关。
假设我们用包含6600个记号的词汇表训练一个语言模型,让模型预测句子中的下一个单词。假设选择这个单词的可能性是5/6600(即不太可能)。它的困惑度是概率6600/5 = 1320的倒数,这表示困惑非常高。如果选择这个单词的可能性是6000/6600,那么困惑度将是6600/6000 = 1.1,这说明困不太困惑。
困惑度的计算公式如下:
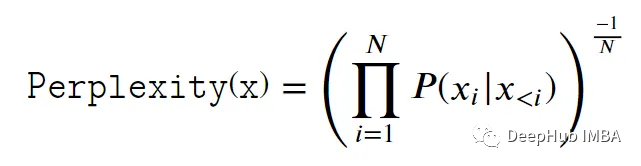
为了保证数值的稳定性,我们可以用对数函数来定义它。
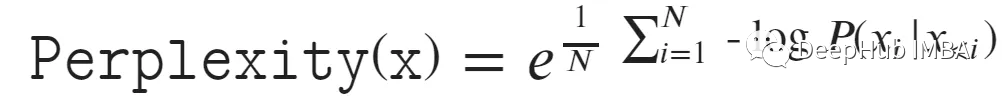
模型的训练和验证困惑度可以直接从batch或epoch损失中计算出来。但是无法计算预测的困惑度,因为它要求每个预测都有一组基本的真值标签。
让我们假设变量probs是一个张量,它包含了语言模型在序列中那个位置预测基真值的概率。
可以使用此代码计算每个困惑度。
token_perplexity = (probs.log() * -1.0).exp()
print(f"Token Perplexity: {token_perplexity}")
- 1
- 2
使用此代码可以计算样本的困惑度。
sentence_perplexity = (probs.log() * -1.0).mean().exp().item()
print(f"Sentence Perplexity: {sentence_perplexity:.2f}")
- 1
- 2
以下代码可以计算给定一个句子的每个单词的概率。
def get_pointwise_loss(self, inputs: List[str], tok): self.model.eval() all_probs = [] with torch.inference_mode(): for input in inputs: ids_list: List[int] = tok.encode(input).ids # ids has shape (1, len(ids_list)) ids: Torch.Tensor = torch.tensor(ids_list, device=self.device).unsqueeze(0) # probs below is the probability that the token at that location # completes the sentence (in ids) so far. y = self.model(ids) criterion = nn.CrossEntropyLoss(reduction='none', ignore_index=0) # Compute the loss starting from the 2nd token in the model's output. loss = criterion(y[:,:,:-1], ids[:,1:]) # To compute the probability of each token, we need to compute the # negative of the log loss and exponentiate it. loss = loss * -1.0 # Set the probabilities that we are not interested in to -inf. # This is done to make the softmax set these values to 0.0 loss[loss == 0.0] = float("-inf") # probs holds the probability of each token's prediction # starting from the 2nd token since we don't want to include # the probability of the model predicting the beginning of # a sentence given no existing sentence context. # # To compute perplexity, we should probably ignore the first # handful of predictions of the model since there's insufficient # context. We don’t do that here, though. probs = loss.exp() all_probs.append(probs) # # return all_probs #

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
上面就是最基本的大语言模型的工作原理,以及我们如何计算每个单词和每个句子的困惑度,下面我们就可以利用这些信息来构建一个可以检测某些文本是否是人工智能生成的工具。
检测ai生成的文本
为了检查文本是否是人工智能生成的,我们需要将句子的困惑度与模型的困惑度进行比较,该困惑度由一个模糊因子alpha缩放。如果句子的困惑程度超过模型缩放的困惑程度,那么它可能是人类编写的文本(即不是人工智能生成的)。否则,它可能是人工智能生成的。如果句子的困惑度小于或等于模型的缩放训练困惑度,那么它很可能是使用该语言模型生成的,但我们不能很确定。这是因为这段文字有可能是人类写的,而它恰好是模型也可以生成的。因为模型是在大量人类书写的文本上进行训练的,所以在某种意义上,该模型就代表了“普通人的写作”。

上式中的Ppx (x)表示输入“x”的困惑度。
让我们看看人类编写的与 ai生成文本的示例。
我们的Python代码可以根据句子中的每个标记相对于模型的困惑度为其上色。如果我们不考虑它的困惑,第一个符号总是认为是手写的(因为模型也需要第一个输入才可以进行后续的输出)。困惑度小于或等于模型缩放困惑度的单词用红色表示,表明它们可能是ai生成的,而困惑度更高的令牌用绿色表示,表明它们肯定不是ai生成的。
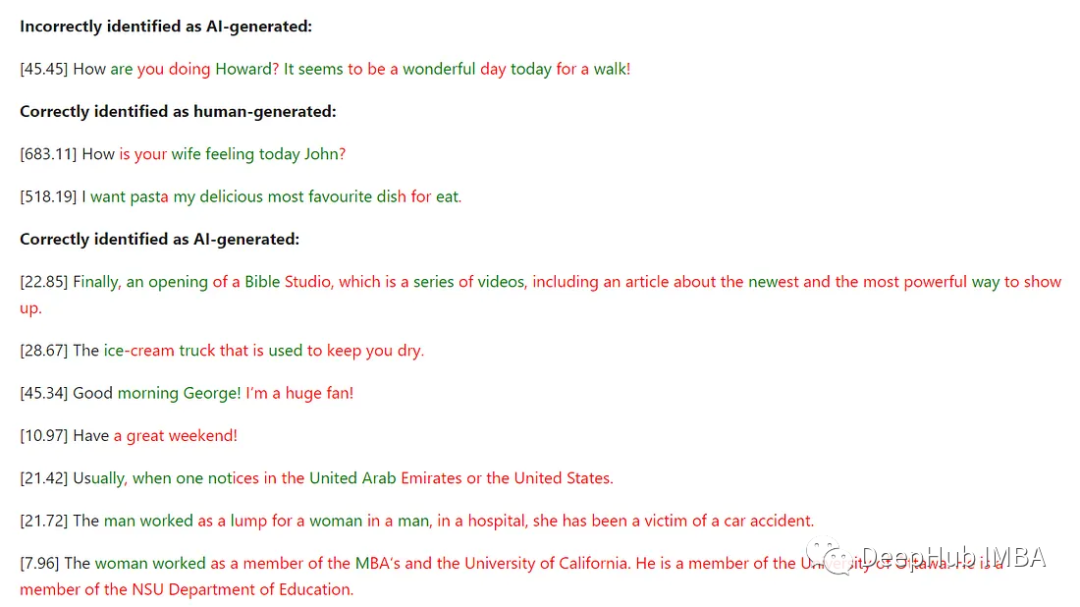
句子前方括号中的数字表示使用语言模型计算出的句子的复杂程度。有些单词是半红半蓝的。这是由于我们使用了子词标记器。
下面是生成上述HTML的代码。
def get_html_for_token_perplexity(tok, sentence, tok_ppx, model_ppx): tokens = tok.encode(sentence).tokens ids = tok.encode(sentence).ids cleaned_tokens = [] for word in tokens: m = list(map(ord, word)) m = list(map(lambda x: x if x != 288 else ord(' '), m)) m = list(map(chr, m)) m = ''.join(m) cleaned_tokens.append(m) # html = [ f"<span>{cleaned_tokens[0]}</span>", ] for ct, ppx in zip(cleaned_tokens[1:], tok_ppx): color = "black" if ppx.item() >= 0: if ppx.item() <= model_ppx * 1.1: color = "red" else: color = "green" # # html.append(f"<span style='color:{color};'>{ct}</span>") # return "".join(html) #
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
正如我们从上面的例子中看到的,如果一个模型检测到一些文本是人工手写的,那么它肯定是人工手写的,但如果它检测到文本是人工智能生成的,那么它就有可能不是人工智能生成的。为什么会这样呢?让我们看看下面!
假阳性
语言模型是在人类写的大量文本上训练的。一般来说,很难发现某件东西是否是由特定的人写的。该模型用于训练的输入包括许多不同的写作风格,是由不同的人完成的。这使得模型学习许多不同的写作风格和内容。很有可能你的写作风格与模型训练的某些文本的写作风格非常接近。这就会产生误报,也是为什么模型不能确定某些文本是人工智能生成的。但是该模型可以确定一些文本是人为生成的。
”OpenAI最近宣布将停止其用于检测ai生成文本的工具,理由是准确率低“(https://tech.hindustantimes.com/tech/news/openai-kills-off-its-own-ai-text-detection-tool-shocking-reason-behind-it-71690364760759.html)。这条新闻就说明了上面的问题。
原始版本的人工智能分类器工具从一开始就存在一定的局限性和不准确性。用户需要手动输入至少1000个字符的文本,然后OpenAI对其进行分析,将其分类为人工智能或人类编写的文本。该工具的表现并不理想,因为它只正确识别了26%的人工智能生成的内容,并且在大约9%的情况下错误地将人类编写的文本标记为人工智能。
以下是OpenAI的博客文章(https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text)。与本文中提到的方法相比,他们似乎使用了不同的方法。
我们的分类器是一个语言模型,对同一主题的人类编写文本和人工智能编写文本的数据集进行微调。从各种各样的来源收集了这个数据集,我们认为这些数据是由人类编写的,比如预训练数据和人类对提交给InstructGPT的提示。将每篇文章分为提示和回复。根据这些提示,从我们和其他组织训练的各种不同的语言模型中生成响应。对于我们的web应用程序,我们调整置信阈值以保持低误报率;换句话说,如果分类器非常自信,我们只会将文本标记为可能是人工智能编写的。
GPTZero是一个流行的人工智能生成文本检测工具。似乎GPTZero使用perplexity 和Burstiness 来检测人工智能生成的文本。“Burstiness ”指的是某些单词或短语在文本中突发性出现的现象。如果一个词在文本中出现过一次,它很可能会在很近的地方再次出现。”
GPTZero声称有非常高的成功率。根据GPTZero常见问题解答,“在0.88的阈值下,85%的人工智能文档被归类为人工智能,99%的人类文档被归类为人类。”
方法的通用性
本文中提到的方法不能很好地一般化。如果您有3个语言模型,例如GPT3、GPT3.5和GPT4,那么必须在所有3个模型中运行输入文本,并检查它们的困惑度,以查看文本是否由其中任何一个生成。这是因为每个模型生成的文本略有不同,并且它们都需要独立地评估文本,以查看是否有任何模型生成了文本。
截至2023年8月,随着世界上大型语言模型的激增,人们似乎不太可能检查任何一段文本是否来自世界上任何一个语言模型。
下面的例子显示了要求我们的模型预测ChatGPT生成的句子是否是人工智能生成的结果。正如您所看到的,结果喜忧参半。

这种情况发生的原因有很多。
1、我们的模型是在非常少的文本上训练的,而ChatGPT是在tb的文本上训练的。
2、与ChatGPT相比,我们的模型是在不同的数据分布上训练的。
3、我们的模型只是一个GPT模型,而ChatGPT针对类似于聊天的响应进行了微调,使其以略微不同的语气生成文本。如果你有一个生成法律文本或医疗建议的模型,那么我们的模型在这些模型生成的文本上也会表现不佳。
4、我们的模型非常小(与chatgpt类模型的> 200B个参数相比,我们的模型小于100M个参数)。
很明显,如果希望提供一个相当高质量的结果来检查任何文本是否是人工智能生成的,我们需要一个更好的方法。
接下来,让我们来看看网上流传的一些关于这个话题的错误信息。
有些文章错误地解释了困惑。例如,如果你在google.com上搜索“人类写的内容是高困惑还是低困惑?”,将在第一个位置获得以下结果。
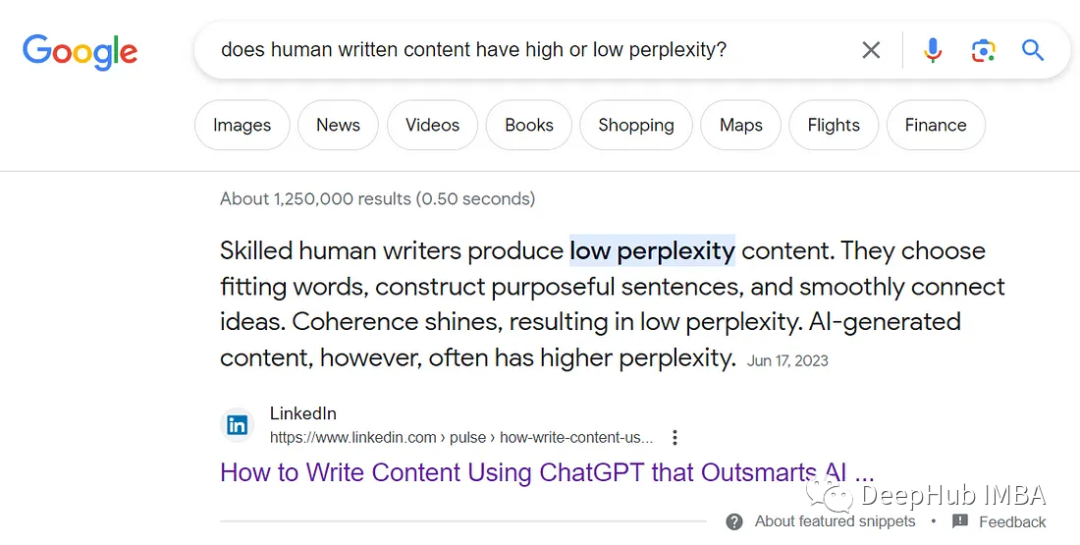
这是不正确的,因为与人工智能生成的内容相比,人类编写的内容通常具有更高的困惑度。
最近kaggle也发布了一个 LLM - Detect AI Generated Text 的比赛,目前的baseline只用的tfidf和lgb,有兴趣的也可以关注一下。
以下是我总结的一些代码:
import nltk from collections import Counter from sklearn.feature_extraction.text import CountVectorizer from textblob import TextBlob import numpy as np text = "This is some sample text to detect. This is a text written by a human? or is it?!" # 1. N-gram Analysis def ngram_analysis(text, n=2): n_grams = nltk.ngrams(text.split(), n) freq_dist = nltk.FreqDist(n_grams) print(freq_dist) ngram_analysis(text) # 2. Perplexity # Perplexity calculation typically requires a language model # This is just an example of how perplexity might be calculated given a probability distribution def perplexity(text, model=None): # This is a placeholder. In practice, we would use the model to get the probability of each word prob_dist = nltk.FreqDist(text.split()) entropy = -1 * sum([p * np.log(p) for p in prob_dist.values()]) return np.exp(entropy) print(perplexity(text)) # 3. Burstiness def burstiness(text): word_counts = Counter(text.split()) burstiness = len(word_counts) / np.std(list(word_counts.values())) return burstiness print(burstiness(text)) # 4. Stylometry def stylometry(text): blob = TextBlob(text) avg_sentence_length = sum(len(sentence.words) for sentence in blob.sentences) / len(blob.sentences) passive_voice = text.lower().count('was') + text.lower().count('were') vocabulary_richness = len(set(text.split())) / len(text.split()) return avg_sentence_length, passive_voice, vocabulary_richness print(stylometry(text)) # 5. Consistency and Coherence Analysis # Again, this is a simple way to explain the idea of calculating the consistency of a text. In reality, more complex algorithms are used. def consistency(text): sentences = text.split(".") topics = [sentence.split()[0] for sentence in sentences if sentence] topic_changes = len(set(topics)) return topic_changes print(consistency(text))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
总结
本文介绍了关于如何检测ai生成文本的思路。可以使用的主要指标是生成文本的困惑度。还介绍了这种方法的一些缺点,包括误报的可能性。希望这有助于理解检测人工智能生成文本背后的细节。
但是当我们讨论检测人工智能生成文本的技术时,这里的假设都是整个文本要么是人类编写的,要么是人工智能生成的。但是实际上文本往往部分由人类编写,部分由ai生成,这使事情变得相当复杂。本文总结的代码也是对所有文本内容的检测,对于部分由人类编写,部分由ai生成则会复杂的多。
对于人工智能生成文本的检测是一个不断发展的领域,还需要我们努力找出一种方法,以更高的准确率检测人工智能生成的文本。
https://avoid.overfit.cn/post/17629222ee754169a7e40c6516815170
作者:Dhruv Matani

