
热门标签
热门文章
- 1Docker快速部署RabbitMq教程,这一篇就够了!_docker部署rabbitmq
- 2Go:安全漏洞扫描工具Gosec详解
- 3《云原生安全攻防》-- 云原生安全概述
- 4基于内容和主题的个性化新闻推荐系统设计需求分析[转载]_个性化推荐需求稿
- 52024年【危险化学品经营单位安全管理人员】报名考试及危险化学品经营单位安全管理人员找解析_危化经营安全员考试
- 6指纹识别工具-Heimdallr(六)_heimdallr 插件
- 7vue项目中使用better-scroll实现侧边导航与列表的联动_van-sidebar配合显示右侧内容
- 8一文读懂tsconfig.json配置文件_项目多个目录下都有tsconfig.json
- 9Servlet组件
- 10APISIX简介与应用
当前位置: article > 正文
大模型应用:LLM基本原理及应用场景_llm开源和闭源模型以及使用场景
作者:你好赵伟 | 2024-08-13 13:43:05
赞
踩
llm开源和闭源模型以及使用场景

1.背景
23年以来,随着OpenAI公司的ChatGPT横空出世,大模型一词开始火爆全球。国内外以OpenAI、Google、百度、阿里、字节等大厂为代表,相继推出一系列大模型及其应用,涉及社交、问答、代码助手等多个方面。
目前主流的大模型及产品:
- OpenAI:GPT3.5、GTP4系列,以及Lora等文生图模型,代表产品:ChatGPT
- Google:Gemini
- 百度:文心一言3.0、4.0系列,代表产品:文心一言、文心一格
- 阿里:通义大模型,代表产品:通义千问
- 百川:百川大模型
- 腾讯:混元大模型
- 字节:豆包大模型
大模型究竟是什么,和基础的垂类模型/多模态模型有何差异?为什么可以基于大模型来构建一系列垂类应用,以及可以使用大模型构建什么应用?
2.LLM基本原理
大模型又被称为大语言模型(Large Language Model)或大规模预训练语言模型(Large Pretrained Language Model)。
对于小模型(垂类模型):每个小模型对打标数据集识别进行训练,比如专注识别猫狗图片的图片模型、并在对应的数据集上评估,给出模型产物。小模型的特点是“专注”,每一个小模型训练出来就是为了识别某类特定目标。
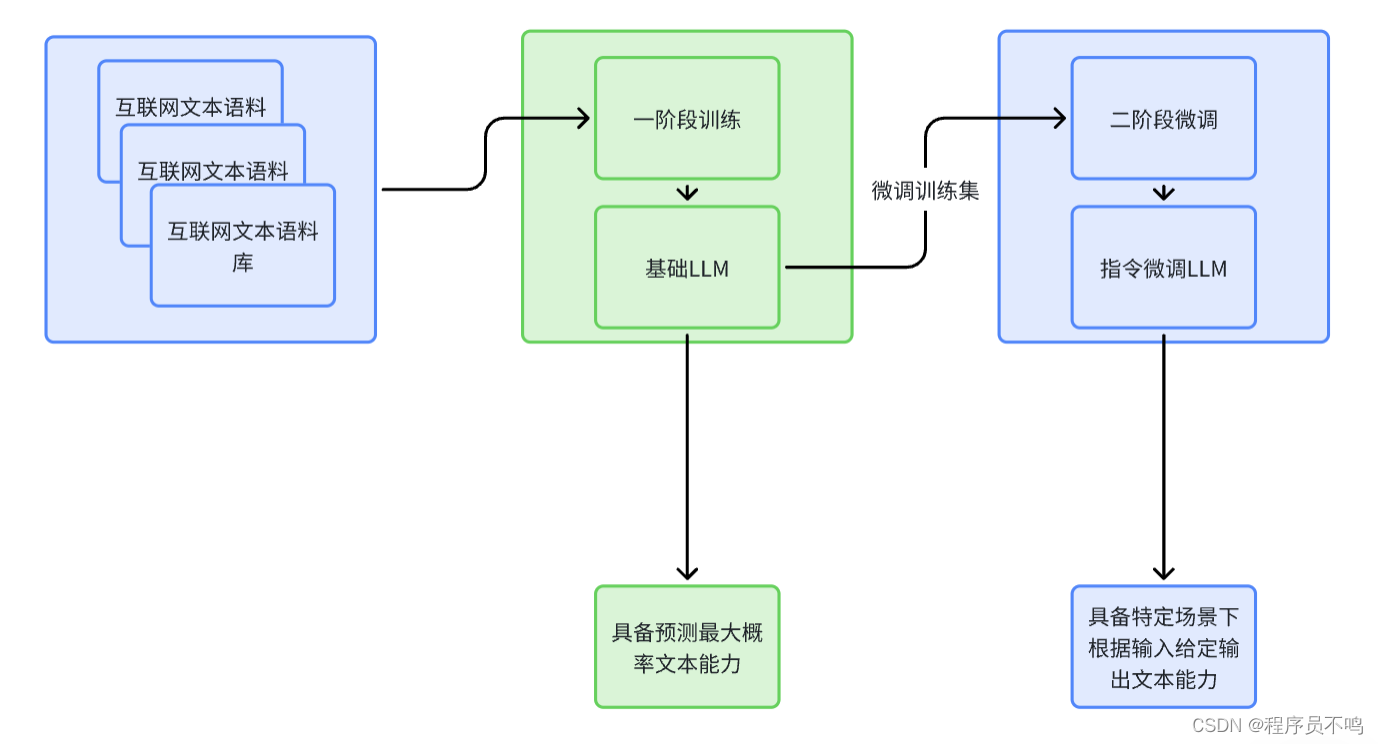
对于大模型来说,其需要具备大量的语料参数以及很好的理解能力,其训练分为两个阶段:
- 一阶段预训练:在大量的文本语料数据集(待标数据)中进行训练,提取特征。经过预训练后的大模型具有大量参数和强大的语料理解能力,它能识别输入的文本,并且预测出下一个最大概率的文本,一阶段训练后产出的大模型为基础LLM。
- 二阶段指令微调:由于一阶段产出的基础LLM只能做到从输入的文本预测下一个最有可能的文本,比如输入“中国的首都”,那么预测输出为“中国”,但如果我们想让大模型“思考”,如输入“你知道中国的首都是北京吗?”,那么大模型的预测输出可能不符合预期。所以对于使用场景,需要对一阶段基础LLM进行微调,通过指令微调给定输入,并且明确告诉LLM需要基于该输入,得到什么样的结果,让LLM学习这个过程,已得到二阶段的指令微调LLM。比如ChatGPT使用大模型的就是由GPT基础LLM经过微调后得到的。
对于算法架构,LLM主要是采用了Transformer架构来增强大模型对语料的上下文理解能力,可以做到长序列理解及推理。
3.LLM应用场景
基础LLM具有千亿级别参数及语料,具有很好的文本理解能力,通过二阶段指令微调可以让基础LLM在特定场景下做到更准确的输出判断,目前LLM应用场景十分广泛,包括:
- 社交领域
- 智能对话
- 虚拟人
- 编程领域
- 代码理解
- 潜在BUG扫描
- 代码生成
- 风控领域
- 智能审核
- 风险判别
- 工业/医学领域
- 系统检修判断
- 医学辅助诊断
- 生成式创造
- 文生图
- 文生视频
- 图片/视频扩展
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/975198
推荐阅读
相关标签

