
Elasticsearch(十二)搜索---搜索匹配功能③--布尔查询及filter查询原理_elasticsearch filter
赞
踩
一、前言
本节主要学习ES匹配查询中的布尔查询以及布尔查询中比较特殊的filter查询及其原理。
复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。
布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些子查询之间的逻辑关系是"与",即所有子查询的结果都为true时布尔查询结果才为真。布尔查询还可以按照各个子查询的具体匹配程度对文档进行打分计算,除了比较特殊的must not查询和filter查询之外,这个后面会详解。
布尔查询支持的子查询主要有4种,各子查询的名称和功能如下表:
| 子查询名称 | 功能 |
|---|---|
| must | 必须匹配该查询条件 |
| should | 可以匹配该查询条件 |
| must not | 必须不匹配该查询条件,且不进行打分计算 |
| filter | 必须匹配过滤条件,且不进行打分计算 |
下面将逐一进行讲解
二、布尔查询
2.1、must查询
当查询中包含must查询时,相当于逻辑查询中的"与"查询。命中的文档必须匹配该子查询的结果,并且ES会将该子查询与文档的匹配程度值加入总得分里。must搜索包含一个数组,可以把其他的搜索匹配查询及布尔查询放入其中。
以下示例使用must查询城市范围为上海和南昌且创建时间范围在2021-02-27 22:00:00到2024-02-27 22:00:00,DSL如下:
POST /hotel/_search
{
"query": {
"bool": {
"must": [
{
"terms": { //第一个terms子查询,城市为上海和南昌
"city": [
"上海",
"南昌"
]
}
},
{
"range": { //第二个range子查询,时间范围为2021-02-27 22:00:00到2024-02-27 22:00:00,包括边界
"create_time": {
"gte": "2021-02-27 22:00:00",
"lte": "2024-02-27 22:00:00"
}
}
}
]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
结果如下图,可以看到结果是同时满足的且我们发现是有打分的
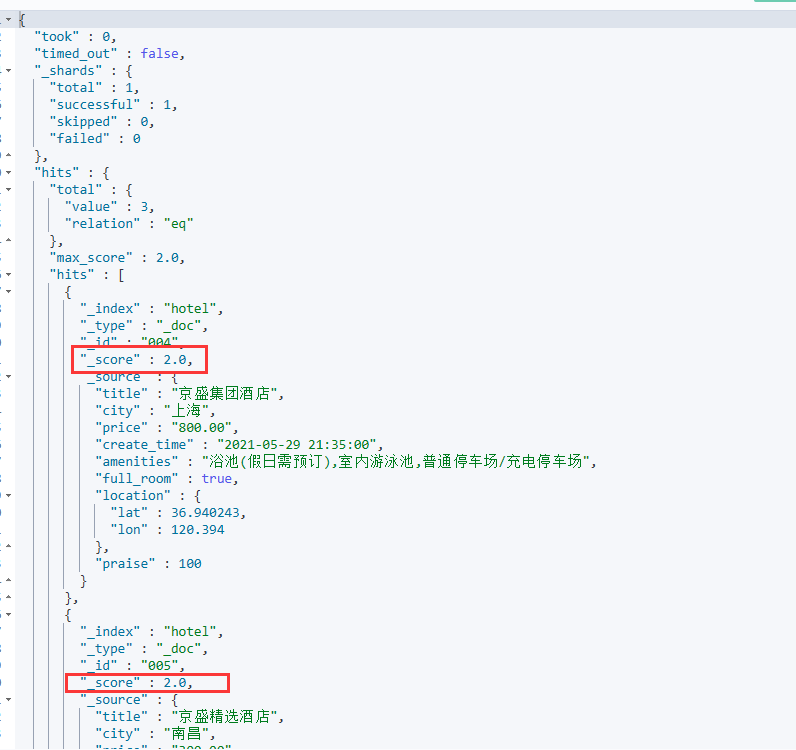
在java客户端上构建must搜索时,可以使用QueryBuilder.boolQuery().must()进行构建,上面的must查询例子改写成Java客户端请求的形式为:
Service层(private方法在后面的查询中通用,不会再展示)
public List<Hotel> mustQuery(HotelDocRequest hotelDocRequest) throws IOException {
//新建搜索请求
String indexName = getNotNullIndexName(hotelDocRequest);
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("city", hotelDocRequest.getCities());
Date createTimeStart = hotelDocRequest.getCreateTimeStart();
String createTimeStartToSearch = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(createTimeStart);
Date createTimeEnd = hotelDocRequest.getCreateTimeEnd();
String createTimeEndToSearch = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(createTimeEnd);
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("create_time").gte(createTimeStartToSearch).lte(createTimeEndToSearch);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(rangeQueryBuilder).must(termsQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
return getQueryResult(searchRequest);
}
private String getNotNullIndexName(HotelDocRequest hotelDocRequest) {
String indexName = hotelDocRequest.getIndexName();
if (CharSequenceUtil.isBlank(indexName)) {
throw new SearchException("索引名不能为空");
}
return indexName;
}
private List<Hotel> getQueryResult(SearchRequest searchRequest) throws IOException {
ArrayList<Hotel> resultList = new ArrayList<>();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
RestStatus status = searchResponse.status();
if (status != RestStatus.OK) {
return Collections.emptyList();
}
SearchHits searchHits = searchResponse.getHits();
for (SearchHit searchHit : searchHits) {
Hotel hotelResult = new Hotel();
hotelResult.setId(searchHit.getId()); //文档_id
hotelResult.setIndex(searchHit.getIndex()); //索引名称
hotelResult.setScore(searchHit.getScore()); //文档得分
//转换为Map
Map<String, Object> dataMap = searchHit.getSourceAsMap();
hotelResult.setTitle((String) dataMap.get("title"));
hotelResult.setCity((String) dataMap.get("city"));
Object price = dataMap.get("price");
if(price != null){
hotelResult.setPrice(Double.valueOf((String)price));
}
resultList.add(hotelResult);
}
return resultList;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
controller层:
@PostMapping("/query/must")
public FoundationResponse<List<Hotel>> mustQuery(@RequestBody HotelDocRequest hotelDocRequest) {
try {
List<Hotel> hotelList = esQueryService.mustQuery(hotelDocRequest);
if (CollUtil.isNotEmpty(hotelList)) {
return FoundationResponse.success(hotelList);
} else {
return FoundationResponse.error(100,"no data");
}
} catch (IOException e) {
log.warn("搜索发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
} catch (Exception e) {
log.error("服务发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
postman调用:
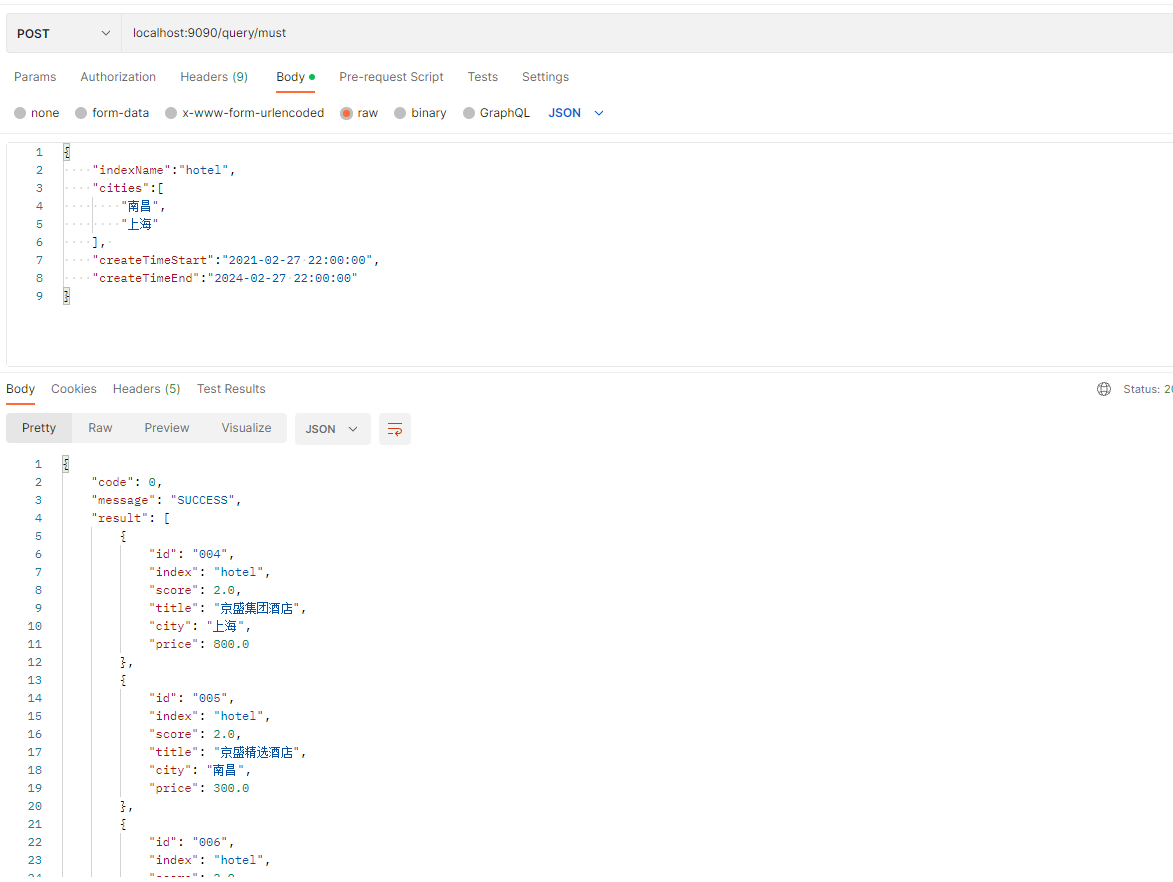
2.2、should查询
当查询中包含should查询时,表示当前查询为"或"查询。命中的文档可以匹配该查询中的一个或多个子查询的结果,并且ES会将该查询与文档的匹配程度加入总得分里。should查询包含一个数组,可以把其他的查询匹配的查询及布尔查询放入其中:
例如,我这边需要查询城市为上海或北京的酒店:
DSL如下:
POST /hotel/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"city": {
"value": "上海"
}
}
},
{
"term": {
"city": {
"value": "北京"
}
}
}
]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
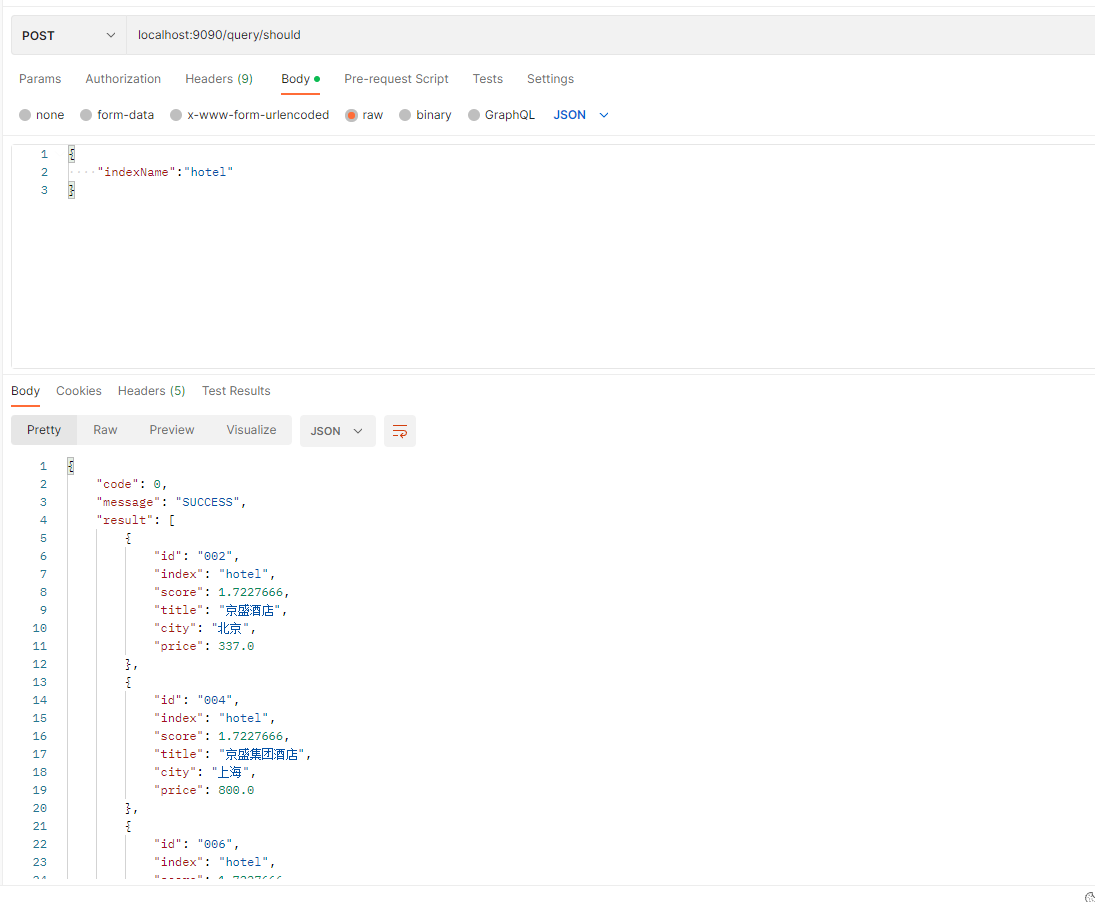
查询结果如图所示:
可以看到城市为上海或者北京的酒店全部被查询出来了。且有根据匹配程度打分

在java客户端上构建should搜索时,可以使用QueryBuilder.boolQuery().should()进行构建,上面的should查询例子改写成Java客户端请求的形式为:
Service层:
public List<Hotel> shouldQuery(HotelDocRequest hotelDocRequest) throws IOException {
//新建搜索请求
String indexName = getNotNullIndexName(hotelDocRequest);
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "北京");
TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("city", "上海");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.should(termQueryBuilder1).should(termQueryBuilder2);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
return getQueryResult(searchRequest);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
controller层:
@PostMapping("/query/should")
public FoundationResponse<List<Hotel>> shouldQuery(@RequestBody HotelDocRequest hotelDocRequest) {
try {
List<Hotel> hotelList = esQueryService.shouldQuery(hotelDocRequest);
if (CollUtil.isNotEmpty(hotelList)) {
return FoundationResponse.success(hotelList);
} else {
return FoundationResponse.error(100,"no data");
}
} catch (IOException e) {
log.warn("搜索发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
} catch (Exception e) {
log.error("服务发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
postman调用演示
2.3、must not查询
当查询中包含must not查询时,表示当前查询为"非"查询。命中的文档不能匹配该查询中的一个或多个子查询的结果。must not查询包含一个数组,可以把其他的查询匹配的查询及布尔查询放入,与上面的2个布尔查询不同,must not查询不会进行打分操作
must not查询是用来排除与指定条件匹配的文档的。它的作用是将与条件匹配的文档从结果中排除掉,而不是对这些文档进行打分。因此,must not查询不涉及打分,仅仅关注匹配与不匹配。这一点和后面的filter查询原理上是一样的:
例如,我这边需要查询城市既不为上海也不是北京的酒店:
DSL如下:
POST /hotel/_search
{
"query": {
"bool": {
"must_not": [
{
"term": {
"city": {
"value": "上海"
}
}
},
{
"term": {
"city": {
"value": "北京"
}
}
}
]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
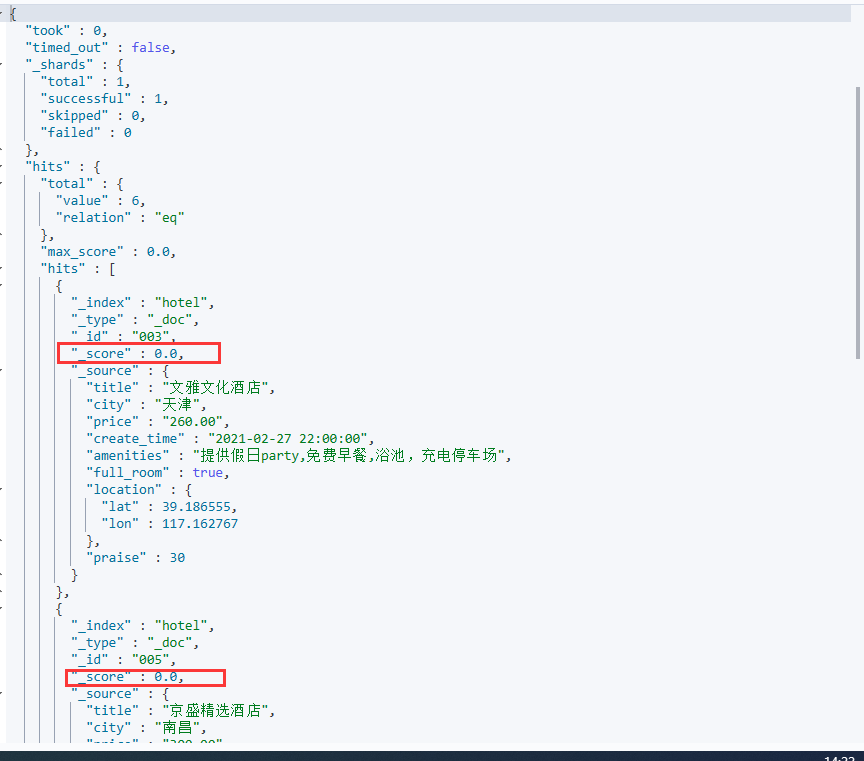
查询结果如图所示:
可以看到查询出来的节点城市均不为北京或者上海。但是并有根据匹配程度打分:
在java客户端上构建must not搜索时,可以使用QueryBuilder.boolQuery().mustNot()进行构建,上面的must not查询例子改写成Java客户端请求的形式为:
Service层:
public List<Hotel> mustNotQuery(HotelDocRequest hotelDocRequest) throws IOException {
//新建搜索请求
String indexName = getNotNullIndexName(hotelDocRequest);
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "北京");
TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("city", "上海");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.mustNot(termQueryBuilder1).mustNot(termQueryBuilder2);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
return getQueryResult(searchRequest);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
controller层:
@PostMapping("/query/must_not")
public FoundationResponse<List<Hotel>> mustNotQuery(@RequestBody HotelDocRequest hotelDocRequest) {
try {
List<Hotel> hotelList = esQueryService.mustNotQuery(hotelDocRequest);
if (CollUtil.isNotEmpty(hotelList)) {
return FoundationResponse.success(hotelList);
} else {
return FoundationResponse.error(100,"no data");
}
} catch (IOException e) {
log.warn("搜索发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
} catch (Exception e) {
log.error("服务发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
postman查询:
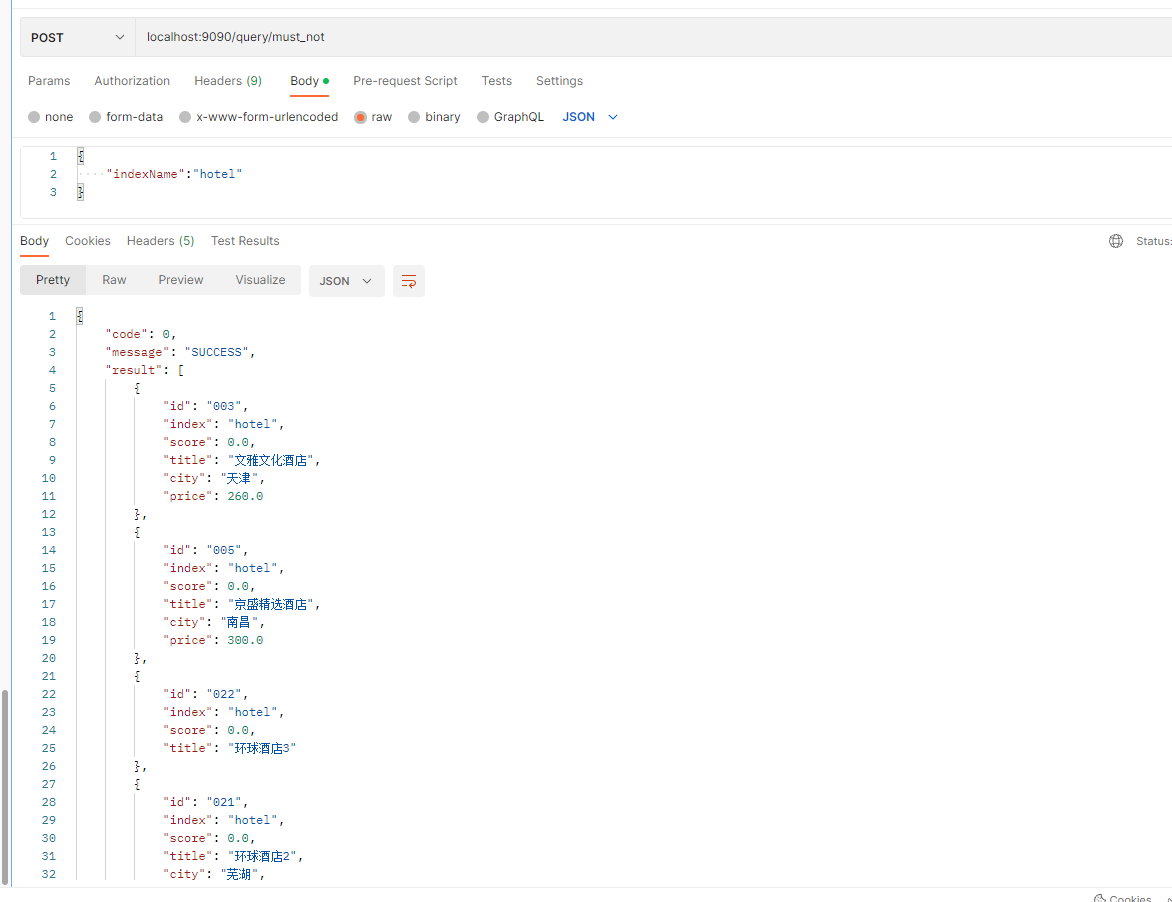
2.4、filter查询
filter查询即过滤查询,该查询是布尔查询里非常独特的一种查询,如果说前面的must not查询用于排除与条件匹配的文档,将这些文档从查询结果中排除掉。filter查询就是用于精确过滤文档,它只关注文档是否符合条件,将匹配的文档包含在结果中。他们都不进行打分、排序或相关性计算,只担心是否匹配。但是filter和must not原理上还是存在一些区别,这个后面讲,先对功能进行讲解:
例如我要查询城市是上海且已经满员的酒店:
POST /hotel/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"city": {
"value": "上海"
}
}
},
{
"term": {
"full_room": {
"value": true
}
}
}
]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
可以看出查询的条件中符合指纹上海且满员,且并没有进行打分
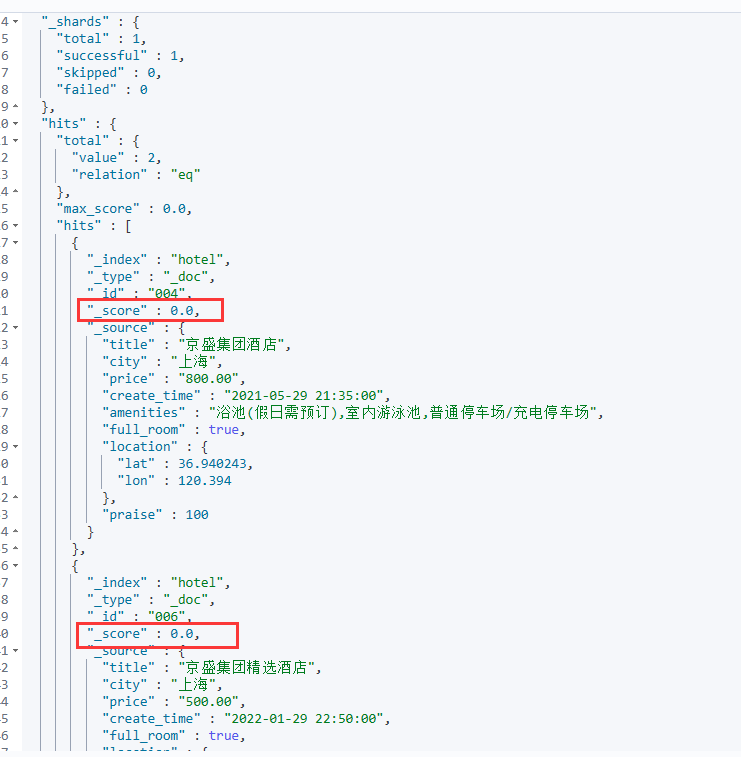
而filter查询会在布尔查询初始阶段进行执行,并将符合条件的文档结果保存下来,接着才会去执行剩余的查询,不管你写的顺序!例如我先写must再写filter,ES执行器也会先执行filter过滤,在过滤后得到的剩余文档中再去执行其他的布尔查询,这样的目的是为了提高查询效率,因为filter查询会将文档集合进行过滤,只保留满足条件的文档,再将这些文档传递给must查询进行进一步的条件匹配和评分。
filter查询主要目的是根据指定的条件来快速地过滤掉不符合条件的文档,以减少后续的计算和评分操作。
请注意,当使用filter查询时,Elasticsearch会对搜索结果进行缓存,以进一步提高性能。缓存可在后续的相同查询中重复使用,除非索引数据发生更改。这使得过滤器查询非常适合用于频繁执行的静态条件过滤
在java客户端上构建filter搜索时,可以使用QueryBuilders.boolQuery.filter()进行构建,例如我要查询城市是上海且已经满员的酒店改写成java客户端请求的形式为:
service层:
public List<Hotel> filterQuery(HotelDocRequest hotelDocRequest) throws IOException {
//新建搜索请求
String indexName = getNotNullIndexName(hotelDocRequest);
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "上海");
TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("full_room", true);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.filter(termQueryBuilder1).filter(termQueryBuilder2);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
return getQueryResult(searchRequest);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
controller层:
@PostMapping("/query/filter")
public FoundationResponse<List<Hotel>> filterQuery(@RequestBody HotelDocRequest hotelDocRequest) {
try {
List<Hotel> hotelList = esQueryService.filterQuery(hotelDocRequest);
if (CollUtil.isNotEmpty(hotelList)) {
return FoundationResponse.success(hotelList);
} else {
return FoundationResponse.error(100,"no data");
}
} catch (IOException e) {
log.warn("搜索发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
} catch (Exception e) {
log.error("服务发生异常,原因为:{}", e.getMessage());
return FoundationResponse.error(100, e.getMessage());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
postman调用:
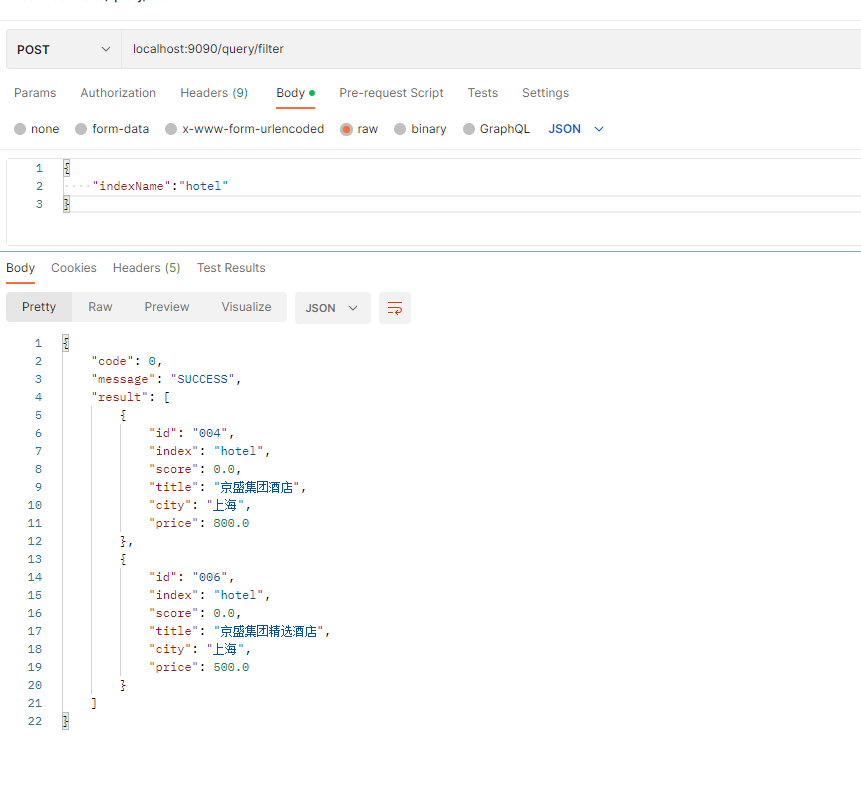
三、filter查询原理
假设当前有5个文档,ES对于city字段的倒排索引结构如图所示:
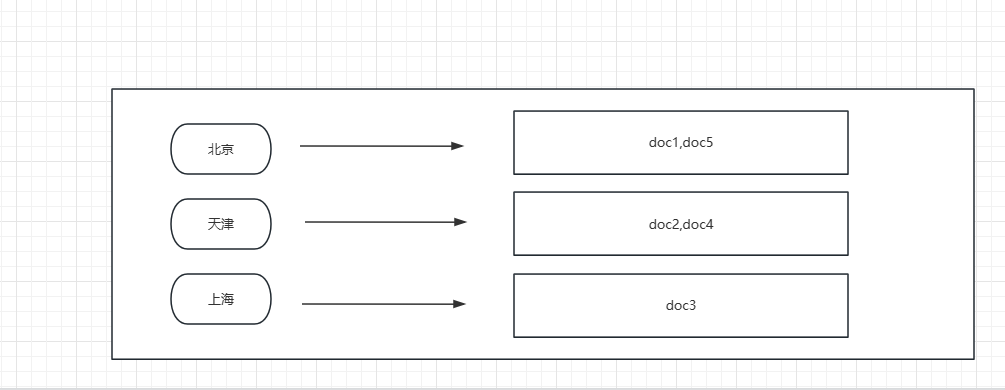
ES对于满房字段倒排的索引结构如图所示:
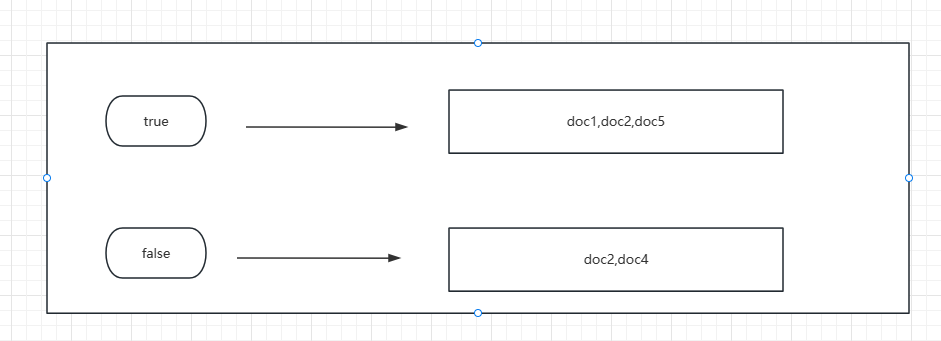
下面以同时查询city为北京,且不满房为例,讲解ES内部执行filter查询的工作步骤。
当ES执行过滤条件时,会查询缓存是否有city字段值为“北京”对应的bitset数组。bitset,中文为位图,它可以用非常紧凑的格式来表示给定范围内的连续数据。如果查询缓存中有对应的Bitset数据,则取出备用;反之,则ES在查询后会对查询条件进行bitset的构建并将其放入缓存中。同时,ES也会考察满房字段为false是否有意对应的bitset数据。如果有,则取出备用;如果没有,ES也会进行bitset的构建。
假设city字段值为“北京”,缓存中没有对应的Bitset数据,则bitset构建的过程如下:
首先,ES在倒排索引中查找字段city值为“北京”字符串的文档,这里为doc1和doc5。然后为所有文档构建bitset数组,数组中每个元素的值用来表示对应位置的文档是否和查询条件匹配,0表示未匹配,1表示匹配。在本例中,doc1和doc5匹配“北京”,对应位置的值为1;doc2、doc3、doc4不匹配,对应的位置为0。最终,本例的bitset数组为[1,0,0,0,1],满房字段同理。之所以用bitset表示文档和query的匹配结果,是因为该结构不仅节省空间而且后续操作时也能节省时间。
接下来ES会遍历查询条件的bitset数组,按照文档命中是否进行文档过滤。当一个请求中有多个filter查询条件时,ES会构建多个bitset数组。为提升效率,ES会从最稀疏的数组(0的元素多于非0元素,反之为稠密数组)开始便遍历,因为遍历稀疏的数组可以过滤掉更多的文档。此时,城市为“北京”对应的bitset比满房为false的Bitset更加稀疏,因此先遍历城市为“北京”的bitset,再遍历满房为false的bitset。遍历的过程中也进行了位运算,每次运算的结果都逐渐接近符合条件的结果。遍历计算完这两个Bitset后,得到匹配所有过滤条件的文档,即doc1和doc5。
正如上面的介绍,如果查询内包含filter,那么ES首先就从缓存中搜索这个filter条件是否有执行记录,是否有对应的bitset缓存可查询。如果有,则从缓存中查询;如果没有,则为filter中的每个查询项新建bitset并且缓存。以供后续其他带有filter的查询可以先在缓存中查询。也就是说,ES对于bitset是可重用的,这种重用的机制叫作filter cache(过滤器缓存)。
filter cache会跟踪每一个filter查询,ES筛选一部分filter查询的bitset进行缓存。首先,这些过滤条件要在最近256个查询中出现过;其次,这些过滤条件的次数必须超过某个阈值。
另外,filter cache是有自动更新机制的,即如果有新增文档或者文档或者文档被修改过,那么filter cache对应的过滤条件中的bitset将被更新。例如城市为“北京”过滤条件对应的bitset为[1,0,0,0,1],如果文档4的城市被修改为“北京”,则“北京”过滤条件对应的bitset会被自动更新为[1,0,0,1,1].
filter查询带来的效益远不止这些,使用filter查询的子句是不计算分数的,这可以减少不小的时间开销。而之前提到的must not查询同样也不进行打分,但是must not是没有和filter cache这样的缓存机制的。filter查询和must_not查询都是用于筛选文档的查询类型,它们不会对文档进行评分。Filter查询适用于需要快速过滤大量文档的场景,而must_not查询适用于排除不需要的文档。在实际使用中,可以根据具体需求选择合适的查询类型。
为提升查询效率,对于简单的term级别匹配查询,应该根据自己的实际业务场景选择合适的查询语句,需要确定这些查询项是否都需要进行打分操作,如果某些匹配条件不需要打分操作的话,那么需要把这些查询全部改为filter形式,让查询更加高效。

