
- 1华为OD机试 - 开源项目热度榜单(Java & JS & Python & C & C++)_华为od 开源项目热度榜单
- 2关于计算机WIFI网络(无线网卡)消失问题_主板自带无线网卡总是自动丢失
- 3弱口令及字典_弱口令账号密码字典
- 4谁告诉你 Flutter 会凉了的?_flutter框架为什么凉了
- 5Tensorflow1.4.0(GPU)+Win10+Anaconda5.0.1+CUDA8.0+cuDNN6.0+Python3.6深度学习环境安装_tensorflow 1.4 (with cuda 8.0)
- 6Git - push超过100M大文件到远程仓库_sourtree 大文件>100m
- 7【阿里云试用计划】免费试用GPU_gpu云服务器免费试用
- 8java.lang.UnsupportedOperationException 如何解决
- 9Windows服务器端内网穿透工具frps安装及使用教程_wimdows服务器做内网穿透
- 10排序——快速排序
RabbitMQ中 exchange、route、queue的关系_rabbitmq exchange routingkey
赞
踩
从AMQP协议可以看出,MessageQueue、Exchange和Binding构成了AMQP协议的核心,下面我们就围绕这三个主要组件 从应用使用的角度全面的介绍如何利用Rabbit MQ构建消息队列以及使用过程中的注意事项。
-
1. 声明MessageQueue
在Rabbit MQ中,无论是生产者发送消息还是消费者接受消息,都首先需要声明一个MessageQueue。这就存在一个问题,是生产者声明还是消费者声明呢?要解决这个问题,首先需要明确:
a)消费者是无法订阅或者获取不存在的MessageQueue中信息。
b)消息被Exchange接受以后,如果没有匹配的Queue,则会被丢弃。
在明白了上述两点以后,就容易理解如果是消费者去声明Queue,就有可能会出现在声明Queue之前,生产者已发送的消息被丢弃的隐患。如果应用能够通过消息重发的机制允许消息丢失,则使用此方案没有任何问题。但是如果不能接受该方案,这就需要无论是生产者还是消费者,在发送或者接受消息前,都需要去尝试建立消息队列。这里有一点需要明确,如果客户端尝试建立一个已经存在的消息队列,Rabbit MQ不会做任何事情,并返回客户端建立成功的。
如果一个消费者在一个信道中正在监听某一个队列的消息,Rabbit MQ是不允许该消费者在同一个channel去声明其他队列的。Rabbit MQ中,可以通过queue.declare命令声明一个队列,可以设置该队列以下属性:
a) Exclusive:排他队列,如果一个队列被声明为排他队列,该队列仅对首次声明它的连接可见,并在连接断开时自动删除。这里需要注意三点:其一,排他队列是基于连接可见的,同一连接的不同信道是可以同时访问同一个连接创建的排他队列的。其二,“首次”,如果一个连接已经声明了一个排他队列,其他连接是不允许建立同名的排他队列的,这个与普通队列不同。其三,即使该队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除的。这种队列适用于只限于一个客户端发送读取消息的应用场景。
b) Auto-delete:自动删除,如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于临时队列。
c) Durable:持久化,这个会在后面作为专门一个章节讨论。
d) 其他选项,例如如果用户仅仅想查询某一个队列是否已存在,如果不存在,不想建立该队列,仍然可以调用queue.declare,只不过需要将参数passive设为true,传给queue.declare,如果该队列已存在,则会返回true;如果不存在,则会返回Error,但是不会创建新的队列。
-
2. 生产者发送消息
在AMQP模型中,Exchange是接受生产者消息并将消息路由到消息队列的关键组件。ExchangeType和Binding决定了消息的路由规则。所以生产者想要发送消息,首先必须要声明一个Exchange和该Exchange对应的Binding。可以通过 ExchangeDeclare和BindingDeclare完成。在Rabbit MQ中,声明一个Exchange需要三个参数:ExchangeName,ExchangeType和Durable。ExchangeName是该Exchange的名字,该属性在创建Binding和生产者通过publish推送消息时需要指定。ExchangeType,指Exchange的类型,在RabbitMQ中,有三种类型的Exchange:direct ,fanout和topic,不同的Exchange会表现出不同路由行为。Durable是该Exchange的持久化属性,这个会在消息持久化章节讨论。声明一个Binding需要提供一个QueueName,ExchangeName和BindingKey。下面我们就分析一下不同的ExchangeType表现出的不同路由规则。
生产者在发送消息时,都需要指定一个RoutingKey和Exchange,Exchange在接到该RoutingKey以后,会判断该ExchangeType:
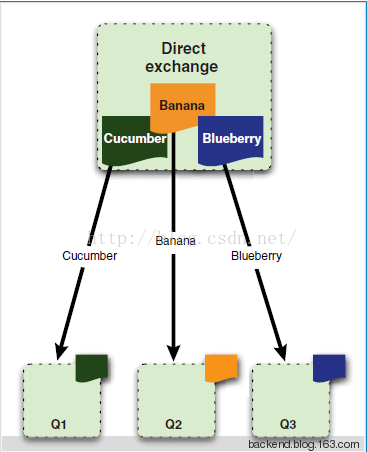
a) 如果是Direct类型,则会将消息中的RoutingKey与该Exchange关联的所有Binding中的BindingKey进行比较,如果相等,则发送到该Binding对应的Queue中。
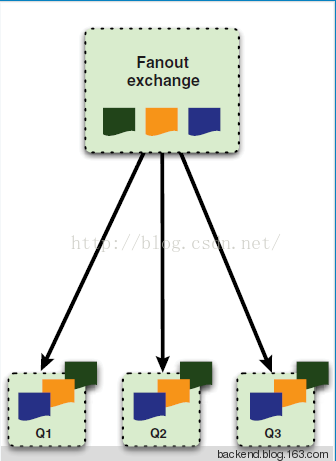
b) 如果是 Fanout 类型,则会将消息发送给所有与该 Exchange 定义过 Binding 的所有 Queues 中去,其实是一种广播行为。
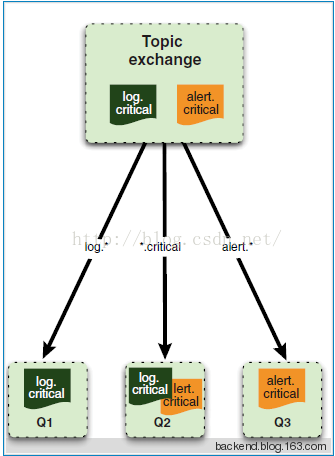
c)如果是Topic类型,则会按照正则表达式,对RoutingKey与BindingKey进行匹配,如果匹配成功,则发送到对应的Queue中。
-
3. 消费者订阅消息
在RabbitMQ中消费者有2种方式获取队列中的消息:
a) 一种是通过basic.consume命令,订阅某一个队列中的消息,channel会自动在处理完上一条消息之后,接收下一条消息。(同一个channel消息处理是串行的)。除非关闭channel或者取消订阅,否则客户端将会一直接收队列的消息。
b) 另外一种方式是通过basic.get命令主动获取队列中的消息,但是绝对不可以通过循环调用basic.get来代替basic.consume,这是因为basic.get RabbitMQ在实际执行的时候,是首先consume某一个队列,然后检索第一条消息,然后再取消订阅。如果是高吞吐率的消费者,最好还是建议使用basic.consume。
如果有多个消费者同时订阅同一个队列的话,RabbitMQ是采用循环的方式分发消息的,每一条消息只能被一个订阅者接收。例如,有队列Queue,其中ClientA和ClientB都Consume了该队列,MessageA到达队列后,被分派到ClientA,ClientA服务器收到响应,服务器删除MessageA;再有一条消息MessageB抵达队列,服务器根据“循环推送”原则,将消息会发给ClientB,然后收到ClientB的确认后,删除MessageB;等到再下一条消息时,服务器会再将消息发送给ClientA。
这里我们可以看出,消费者再接到消息以后,都需要给服务器发送一条确认命令,这个即可以在handleDelivery里显示的调用basic.ack实现,也可以在Consume某个队列的时候,设置autoACK属性为true实现。这个ACK仅仅是通知服务器可以安全的删除该消息,而不是通知生产者,与RPC不同。 如果消费者在接到消息以后还没来得及返回ACK就断开了连接,消息服务器会重传该消息给下一个订阅者,如果没有订阅者就会存储该消息。
既然RabbitMQ提供了ACK某一个消息的命令,当然也提供了Reject某一个消息的命令。当客户端发生错误,调用basic.reject命令拒绝某一个消息时,可以设置一个requeue的属性,如果为true,则消息服务器会重传该消息给下一个订阅者;如果为false,则会直接删除该消息。当然,也可以通过ack,让消息服务器直接删除该消息并且不会重传。
-
4. 持久化:
Rabbit MQ默认是不持久队列、Exchange、Binding以及队列中的消息的,这意味着一旦消息服务器重启,所有已声明的队列,Exchange,Binding以及队列中的消息都会丢失。通过设置Exchange和MessageQueue的durable属性为true,可以使得队列和Exchange持久化,但是这还不能使得队列中的消息持久化,这需要生产者在发送消息的时候,将delivery mode设置为2,只有这3个全部设置完成后,才能保证服务器重启不会对现有的队列造成影响。这里需要注意的是,只有durable为true的Exchange和durable为ture的Queues才能绑定,否则在绑定时,RabbitMQ都会抛错的。持久化会对RabbitMQ的性能造成比较大的影响,可能会下降10倍不止。
-
5. 事务:
对事务的支持是AMQP协议的一个重要特性。假设当生产者将一个持久化消息发送给服务器时,因为consume命令本身没有任何Response返回,所以即使服务器崩溃,没有持久化该消息,生产者也无法获知该消息已经丢失。如果此时使用事务,即通过txSelect()开启一个事务,然后发送消息给服务器,然后通过txCommit()提交该事务,即可以保证,如果txCommit()提交了,则该消息一定会持久化,如果txCommit()还未提交即服务器崩溃,则该消息不会服务器就收。当然Rabbit MQ也提供了txRollback()命令用于回滚某一个事务。
-
6. Confirm机制:
使用事务固然可以保证只有提交的事务,才会被服务器执行。但是这样同时也将客户端与消息服务器同步起来,这背离了消息队列解耦的本质。Rabbit MQ提供了一个更加轻量级的机制来保证生产者可以感知服务器消息是否已被路由到正确的队列中——Confirm。如果设置channel为confirm状态,则通过该channel发送的消息都会被分配一个唯一的ID,然后一旦该消息被正确的路由到匹配的队列中后,服务器会返回给生产者一个Confirm,该Confirm包含该消息的ID,这样生产者就会知道该消息已被正确分发。对于持久化消息,只有该消息被持久化后,才会返回Confirm。Confirm机制的最大优点在于异步,生产者在发送消息以后,即可继续执行其他任务。而服务器返回Confirm后,会触发生产者的回调函数,生产者在回调函数中处理Confirm信息。如果消息服务器发生异常,导致该消息丢失,会返回给生产者一个nack,表示消息已经丢失,这样生产者就可以通过重发消息,保证消息不丢失。Confirm机制在性能上要比事务优越很多。但是Confirm机制,无法进行回滚,就是一旦服务器崩溃,生产者无法得到Confirm信息,生产者其实本身也不知道该消息吃否已经被持久化,只有继续重发来保证消息不丢失,但是如果原先已经持久化的消息,并不会被回滚,这样队列中就会存在两条相同的消息,系统需要支持去重。
-
其他:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程大概如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
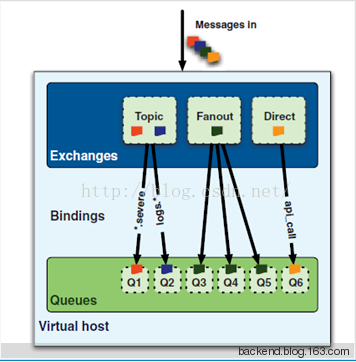
Exchanges, queues, and bindings
exchanges, queues, and bindings是三个基础的概念, 他们的作用是:exchanges are where producers publish their messages, queues are where the messages end up and are received by consumers, and bindings are how the messages get routed from the exchange to particular queues.
下面我们用一副简单的思维导图把上面的概念组织起来:
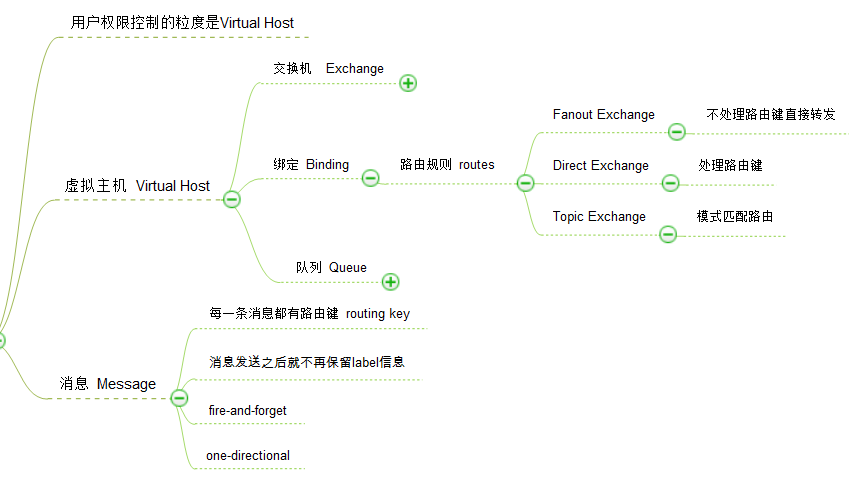
上面还提到了一个vhost的概念,vhost是为了组织exchanges, queues, and bindings提出的概念,我们就从它开始讲起:
VHost
Vhosts也是AMQP的一个基础概念,连接到RabbitMQ默认就有一个名为"/"的vhost可用,本地调试的时候可以直接使用这个默认的vhost.这个"/"的访问可以使用guest用户名(密码guest)访问.可以使用rabbitmqctl工具修改这个账户的权限和密码,这在生产环境是必须要关注的. 出于安全和可移植性的考虑,一个vhost内的exchange不能绑定到其他的vhost.
可以按照业务功能组来规划vhost,在集群环境中只要在某个节点创建vhost就会在整个集群内的节点都创建该vhost.VHost和权限都不能通过AMQP协议创建,在RabbitMQ中都是使用rabbitmqctl进行创建,管理.
如何创建vhost
vhost和permission(权限)信息是并不是通过AMQP创建而是通过rabbitmqctl工具来添加,管理的.
说完vhost我们就来看看重中之重的消息:Message
Message
消息由两部分组成: payload and label. "payload"是实际要传输的数据,至于数据的格式RabbitMQ并不关心,"label"描述payload,包括exchange name 和可选的topic tag.消息一旦到了consumer那里就只有payload部分了,label部分并没有带过来.RabbitMQ并不告诉你消息是谁发出的.这好比你收到一封信但是信封上是空白的.当然想知道是谁发的还是有办法的,在消息内容中包含发送者的信息就可以了.
消息的consumer和producer对应的概念是sending和receiving并不对应client和server.通过channel我们可以创建很多并行的传输 TCP链接不再成为瓶颈,我们可以把RabbitMQ当做应用程序级别的路由器.
Consumer消息的接收方式
Consumer有两种方式接收消息:
通过basic.consume 订阅队列.channel将进入接收模式直到你取消订阅.订阅模式下Consumer只要上一条消息处理完成(ACK或拒绝),就会主动接收新消息.如果消息到达queue就希望得到尽快处理,也应该使用basic.consume命令.
还有一种情况,我们不需要一直保持订阅,只要使用basic.get命令主动获取消息即可.当前消息处理完成之后,继续获取消息需要主动执行basic.get 不要"在循环中使用basic.ge"t当做另外一种形式的basic.consume,因为这种做法相比basic.consume有额外的成本:basic.get本质上就是先订阅queue取回一条消息之后取消订阅.Consumer吞吐量大的情况下通常都会使用basic.consume.
要是没有Consumer怎么办?
如果消息没有Consumer就会老老实实呆在队列里面.
多个Consumer订阅同一个队列
只要Consumer订阅了queue,消息就会发送到该Consumer.我们的问题是这种情况下queue中的消息是如何分发的?
如果一个rabbit queue有多个consumer,具体到队列中的某条消息只会发送到其中的一个Consumer.
消息确认
所有接收到的消息都要求发送响应消息(ACK).这里有两种方式一种是Consumer使用basic.ack明确发送ACK,一种是订阅queue的时候指定auto_ack为true,这样消息一到Consumer那里RabbitMQ就会认为消息已经得到ACK.
要注意的是这里的响应和消息的发送者没有丝毫关系,ACK只是Consumer向RabbitMQ确认消息已经正确的接收到消息,RabbitMQ可以安全移除该消息,仅此而已.
没有正确响应怎么办
如果Consumer接收了一个消息就还没有发送ACK就与RabbitMQ断开了,RabbitMQ会认为这条消息没有投递成功会重新投递到别的Consumer.如果你的应用程序崩掉了,你可以设置备用程序来继续完成消息的处理.
如果Consumer本身逻辑有问题没有发送ACK的处理,RabbitMQ不会再向该Consumer发送消息.RabbitMQ会认为这个Consumer还没有处理完上一条消息,没有能力继续接收新消息.我们可以善加利用这一机制,如果需要处理过程是相当复杂的,应用程序可以延迟发送ACK直到处理完成为止.这可以有效控制应用程序这边的负载,不致于被大量消息冲击.
拒绝消息
由于要拒绝消息,所以ACK响应消息还没有发出,所以这里拒绝消息可以有两种选择:
1.Consumer直接断开RabbitMQ 这样RabbitMQ将把这条消息重新排队,交由其它Consumer处理.这个方法在RabbitMQ各版本都支持.这样做的坏处就是连接断开增加了RabbitMQ的额外负担,特别是consumer出现异常每条消息都无法正常处理的时候.
2. RabbitMQ 2.0.0可以使用 basic.reject 命令,收到该命令RabbitMQ会重新投递到其它的Consumer.如果设置requeue为false,RabbitMQ会直接将消息从queue中移除.
其实还有一种选择就是直接忽略这条消息并发送ACK,当你明确直到这条消息是异常的不会有Consumer能处理,可以这样做抛弃异常数据.为什么要发送basic.reject消息而不是ACK?RabbitMQ后面的版本可能会引入"dead letter"队列,如果想利用dead letter做点文章就使用basic.reject并设置requeue为false.
消息持久化
消息的持久化需要在消息投递的时候设置delivery mode值为2.由于消息实际存储于queue之中,"皮之不存毛将焉附"逻辑上,消息持久化同时要求exchange和queue也是持久化的.这是消息持久化必须满足的三个条件.
持久化的代价就是性能损失,磁盘IO远远慢于RAM(使用SSD会显著提高消息持久化的性能) , 持久化会大大降低RabbitMQ每秒可处理的消息.两者的性能差距可能在10倍以上.
消息恢复
consumer从durable queue中取回一条消息之后并发回了ACK消息,RabbitMQ就会将其标记,方便后续垃圾回收.如果一条持久化的消息没有被consumer取走,RabbitMQ重启之后会自动重建exchange和queue(以及bingding关系),消息通过持久化日志重建再次进入对应的queues,exchanges.
皮之不存,毛将焉附?紧接着我们看看消息实际存放的地方:Queue
Queue
Queues是Massage的落脚点和等待接收的地方,消息除非被扔进黑洞否则就会被安置在一个Queue里面.Queue很适合做负载均衡,RabbitMQ可以在若干consumer中间实现轮流调度(Round-Robin).
如何创建队列
consumer和producer都可以创建Queue,如果consumer来创建,避免consumer订阅一个不存在的Queue的情况,但是这里要承担一种风险:消息已经投递但是consumer尚未创建队列,那么消息就会被扔到黑洞,换句话说消息丢了;避免这种情况的好办法就是producer和consumer都尝试创建一下queue. 如果consumer在已经订阅了另外一个Queue的情况下无法完成新Queue的创建,必须取消之前的订阅将Channel置为传输模式("transmit")才能创建新的Channel.
创建Queue的时候通常要指定名字,名字方便consumer订阅.即使你不指定Rabbit会给它分配一个随机的名字,这在使用临时匿名队列完成RPC-over-AMQP调用时会非常有用.
创建Queue的时候还有两个非常有用的选项:
exclusive—When set to true, your queue becomes private and can only be consumed by your app. This is useful when you need to limit a queue to only one consumer.
auto-delete—The queue is automatically deleted when the last consumer unsubscribes.
如果要创建只有一个consumer使用的临时queue可以组合使用auto-delete和 exclusive.consumer一旦断开连接该队列自动删除.
重复创建Queue会怎样?如果Queue创建的选项完全一致的话,RabbitMQ直接返回成功,如果名称相同但是创建选项不一致就会返回创建失败.如果是想检查Queue是否存在,可以设置queue.declare命令的passive 选项为true:如果队列存在就会返回成功,如果队列不存在会报错且不会执行创建逻辑.
消息是如何从动态路由到不同的队列的?这就看下面的内容了
bindings and exchanges
消息如何发送到队列
消息是如何发送到队列的?这就要说到AMQP bindings and exchanges. 投递消息到queue都是经由exchange完成的,和生活中的邮件投递一样也需要遵循一定的规则,在RabbitMQ中规则是通过routing key把queue绑定到exchange上,这种绑定关系即binding.消息发送到RabbitMQ都会携带一个routing key(哪怕是空的key),RabbitMQ会根据bindings匹配routing key,如果匹配成功消息会转发到指定Queue,如果没有匹配到queue消息就会被扔到黑洞.
如何发送到多个队列
消息是分发到多个队列的?AMQP协议里面定义了几种不同类型的exchange:direct, fanout, topic, and headers. 每一种都实现了一种 routing 算法. header的路由消息并不依赖routing key而是去匹配AMQP消息的header部分,这和下面提到的direct exchange如出一辙,但是性能要差很多,在实际场景中几乎不会被用到.
direct exchange routing key完全匹配才转发
fanout exchange 不理会routing key,消息直接广播到所有绑定的queue
topic exchange 对routing key模式匹配
exchange持久化
创建queue和exchange默认情况下都是没有持久化的,节点重启之后queue和exchange就会消失,这里需要特别指定queue和exchange的durable属性.
Consumer是直接创建TCP链接到RabbitMQ吗?下面就是答案:
Channel
无论是要发布消息还是要获取消息 ,应用程序都需要通过TCP连接到RabbitMQ.应用程序连接并通过权限认证之后就要创建Channel来执行AMQP命令.Channel是建立在实际TCP连接之上通信管道,这里之所以引入channel的概念而不是直接通过TCP链接直接发送AMQP命令,是出于两方面的考虑:建立上成百上千的TCP链接,一方面浪费了TCP链接,一方面很快会触及系统瓶颈.引入了Channel之后多个进程与RabbitMQ的通信可以在一条TCP链接上完成.我们可以把TCP类比做光缆,那么Channel就像光缆中的一根根光纤.
参考资料
[1] Rabbits and warrens http://blogs.digitar.com/jjww/2009/01/rabbits-and-warrens/
[2] 兔子和兔子窝 ftofficer|å¼ èªçš„blog » [翻译] [RabbitMQ+Python入门ç»å…¸] å…”å和兔åçª


