
热门标签
热门文章
- 1vue的深入理解_vue为什么不建议一个目录下很多vue文件
- 2龙格库塔(Runge-Kutta)法求四元数微分方程_四元数微分方程+龙格库塔法
- 3c++多边形求交集算法_opencv 多边形求交
- 4[Unity][UGUI]Tooltip提示框_unity ugui tooltip
- 5OpenCV源码安装教程(兼容CUDA)_opencv with cuda
- 6CSS设置文字不换行,超出部分用 ... 代替_css 不换行 超过用 ... 代替
- 7Python中list的remove方法的坑_python list.remove的坑
- 8什么是 API(应用程序接口)?_插件api的正确说法
- 9Google Gemini 1.5:引领跨模态AIGC信息分析理解与视频内容推理的新篇章,与 Open AI 决一高下!
- 10第七周PCL学习--点云配准(七)_rt矩阵
当前位置: article > 正文
用Python实现简单的验证码处理_python验证码校验
作者:凡人多烦事01 | 2024-02-22 10:05:54
赞
踩
python验证码校验
序言
我们在做采集数据的时候,过快或者访问频繁,或者一访问就给弹出验证码,然后就蚌珠了~

今天就给大家来一个简单处理验证码的方法
环境模块
Python和pycharm如果还有小伙伴没安装的话,可以在文章最下方扫码获取安装包。
这里需要用到一个 ddddocr 模块 ,这是别人开源写好的一个东西,简单又好用,但是精确度差一点点,但是还是非常好用的。
如果你追求精确度的话,可以调用别人写好的一些API 。
咱们直接 win+r 弹出搜索框后输入 cmd ,点击确定弹出命令提示符窗口, 输入pip install ddddocr 即可安装。
不会的话详细参考我置顶文章有详细讲解。
代码展示
代码不多,非常简单。
模块安装好之后咱们先导入一下
import ddddocr
- 1
然后实例化一下,用一个 cor 接收一下这个数据。
ocr = ddddocr.DdddOcr()
- 1
我这里准备了四个验证码




这该死的博客水印,挡住了,但是我是不会关掉滴 ,嘿嘿~

回到正题,分别实现一下验证码。
首先我们用 with open 来读取一下这文件,读取方式使用 rb ,因为是图片的话就读取它的二进制数据
with open('img_3.png', 'rb') as f:
- 1
使用 f.read() 将数据读取出来,再自定义一个变量接收一下。
img_bytes = f.read()
- 1
然后我们通过 classification 将它传进去,把结果打印出来就可以了。
result = ocr.classification(img_bytes)
print(result)
- 1
- 2
实现效果
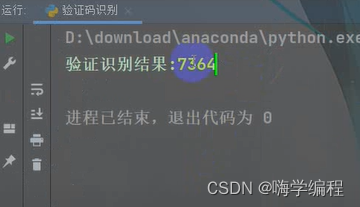
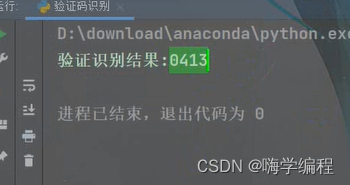
纯数字的
字母+数字的
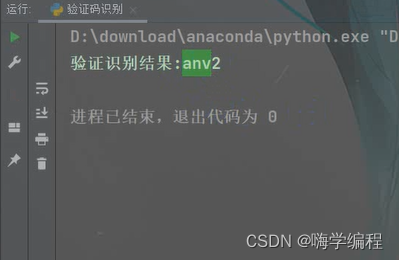

可以看到都完整的识别出来了,即使上面有一些花里胡哨的横线啥的。
完整代码
import ddddocr
ocr = ddddocr.DdddOcr()
with open('img_3.png', 'rb') as f:
img_bytes = f.read()
result = ocr.classification(img_bytes)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
大家可以自己去试试,也可以直接应用在采集数据实践当中~
创作不易,大家帮忙点个收藏吧~

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/129628
推荐阅读
相关标签

