
- 1C++迭代器 iterator详解_c++ iterator
- 207代码随想录训练营day07|哈希表part02
- 3基于C++的学生信息管理系统_c++信息管理系统
- 4如何构造linux根文件系统_nsenter.c:(.text.nsenter_main+0x184): undefined re
- 5Pyecharts一文速学-绘制树状图参数详解+Python代码_python绘制树状图
- 6SCons上手教程_scons教程
- 7DOCKER容器中安装JDK1. 8 详细步骤_docker安装jdk1.8
- 8本科学计算机数学吗,计算机科学本科核心课程教材·计算机数学
- 9JavaWeb中Servlet、web应用和web站点的路径细节("/"究竟代表着什么)
- 10统信UOS专业版服务器无人值守安装_uos 无人值守grub参数
OpenAI 发布文生视频Sora大模型,一句话便可生成长达一分钟的视频_sora 生成视频接口
赞
踩
前几期的文章,我们介绍了很多文生视频的大模型,包括字节发布的magic video以及stable video diffusion等模型,都可以输入相关的文本生成对应场景的视频。

文生视频大模型必然会成为各个人工智能大厂竞争的核心领地,这不OpenAI刚刚发布了其自家的文生视频大模型Sora。

从官方生成的视频可以看到,其质量之强大,性能之稳定,且最大的模型可以生成长达一分钟的视频,简直是要颠覆自媒体的节奏。
很多先前的工作使用了各种方法对视频数据进行建模以便生成视频,包括循环神经网络,生成对抗神经网络,自回归transformer模型以及扩散模型。这些模型结构只关注一小部分视觉数据,较短的视频以及固定尺寸大小的视频。而Sora是视觉数据通用模型,可以生成不同尺寸,不同时间长度,不同高宽比和不同分辨率的视频,其最大的模型可以生成一分钟的高清视频,真正的大力出奇迹。
将视觉数据转化为patch
Sora模型借鉴了LLM语言大模型的token方法,在高纬度空间,Sora首先把视频压缩到低维空间,把视频分成每个视频帧图片,再把图片分割成每个单独的patch,而这些patch可以应用在不同类型的视频和图片的模型训练。
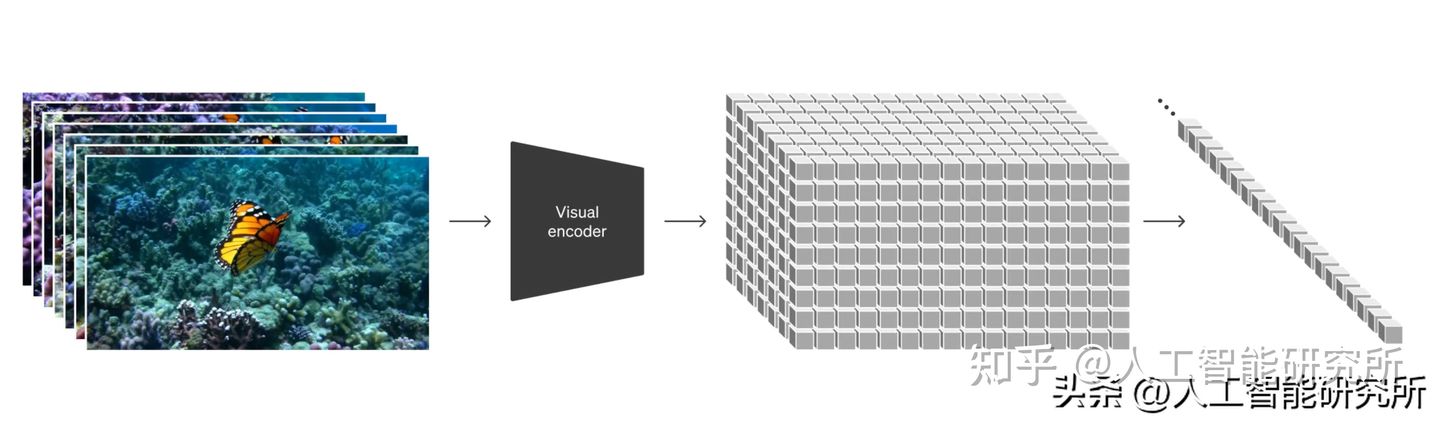
视频压缩网络
OpenAI训练一个降低视觉数据维度网络。该网络将原始视频作为输入,并输出在时间和空间上压缩的潜在数据表示。Sora 在这个压缩的潜在空间中接受训练并随后生成视频。OpenAI还训练了相应的解码器模型,将生成的视频映射回像素空间。
Spacetime latent patches
由于视频是由视频帧图像组成,因此在给定一个压缩的输入视频数据时,Sora模型在输入阶段,提取了一系列时空patch充当输入token。正是基于这些输入token,Sora能够对不同分辨率,不同尺寸大小,持续时间的视频与图片进行训练。在模型推理阶段,可以通过在适当大小的网络中随机排列这些输入token以便生成不同的尺寸视频。
用于视频生成的缩放transformer模型

Transformer 在各个领域都表现出了卓越的扩展特性,包括LLM大语言模型、计算机视觉,图像生成以及视频生成等领域。而Sora是一个扩散transformer模型,扩散transformer可以有效的应用到视频生成领域,在固定种子与输入视频样本上,随着模型的不断训练,其生成的视频质量也不断的提升。

Sora模型不仅可以使用1920x1080p 视频,还可以使用手机竖版1080x1920 视频,且可以使用介于2者之间的任意尺寸视频,这让Sora模型可以生成不同尺寸大小的视频,以便可以应用到不同尺寸的移动终端设备上。

以往的经验为了方便模型框架的设计,在输入数据上会进行裁剪以方便模型训练,但是Sora模型使用原始尺寸视频数据进行模型的训练,相对裁剪的输入数据相比,其原始尺寸数据输出的视频更加的完整。有时裁剪输入数据会导致输出视频不完整,个别视频对象会被裁剪。

语言理解是当前大模型需要重点攻克的难题,但是OpenAI有了 ChatGPT的支持,让Sora可以更加理解输入的文本数据。Sora应用了 DALL·E 3 中引入的文本生成技术。首先训练一个高维描述性的字幕生成器模型,然后使用它为训练集中的所有视频生成文本描述。与 DALL·E 3 类似,利用 GPT 将简短的用户提示转换为较长的详细描述,然后发送到视频模型。这使得 Sora 能够生成准确遵循用户提示的高质量视频。

Sora模型不仅可以对手输入视频进行编辑,也可以连接不同的视频,通过插帧技术,把2个不同风格的视频进行连接

当然,作为视频生成的模型,Sora模型也可以生成图像,该模型可以生成不同尺寸的图像,分辨率高达2048x2048

强大的Sora一经发布,便占据了各大平台的热点,虽然此模型刚刚发布,OpenAI 还没有发布更加详细的技术实现,但是按照OpenAI 的套路,此模型会是一个收费的模型,大概率是提供API接口让开发者使用。
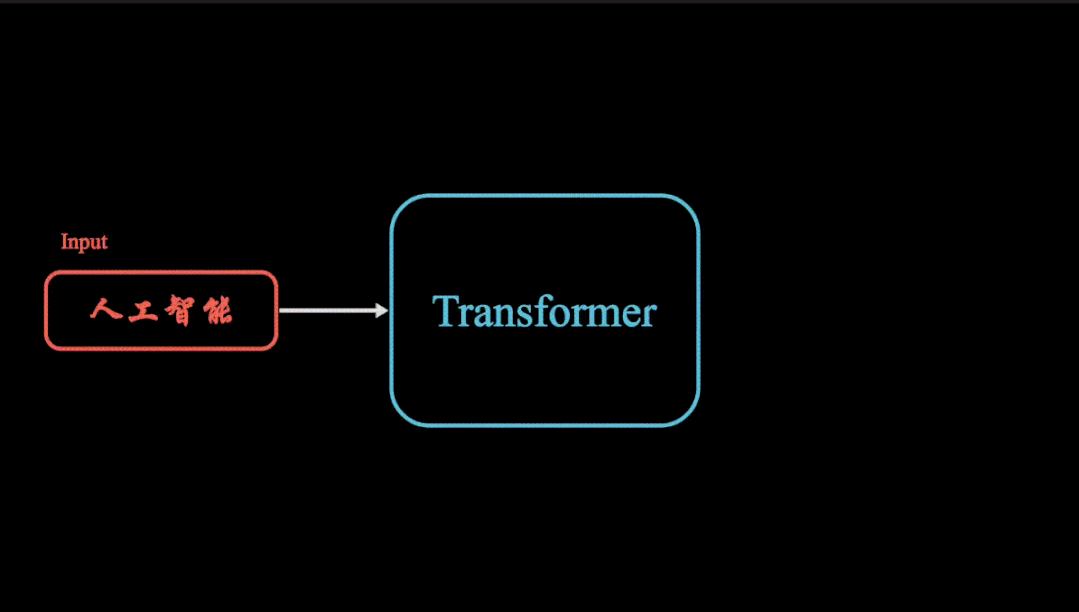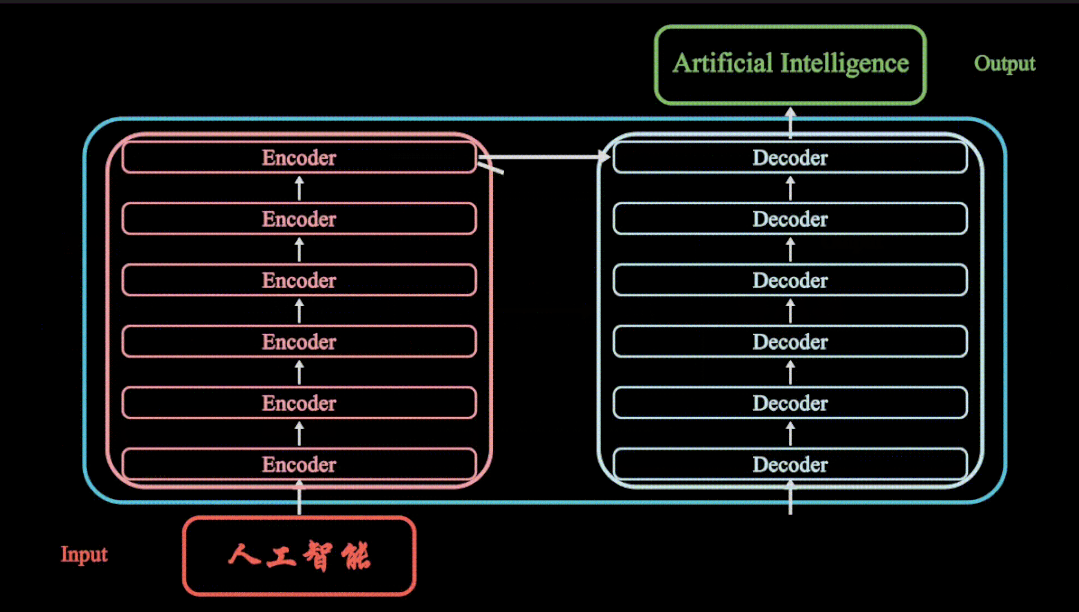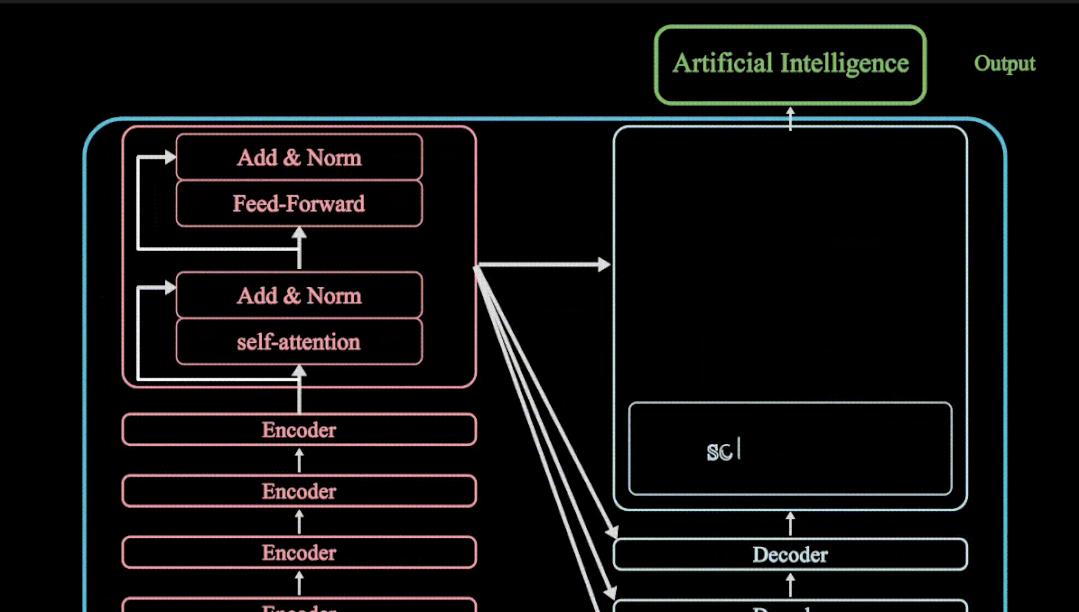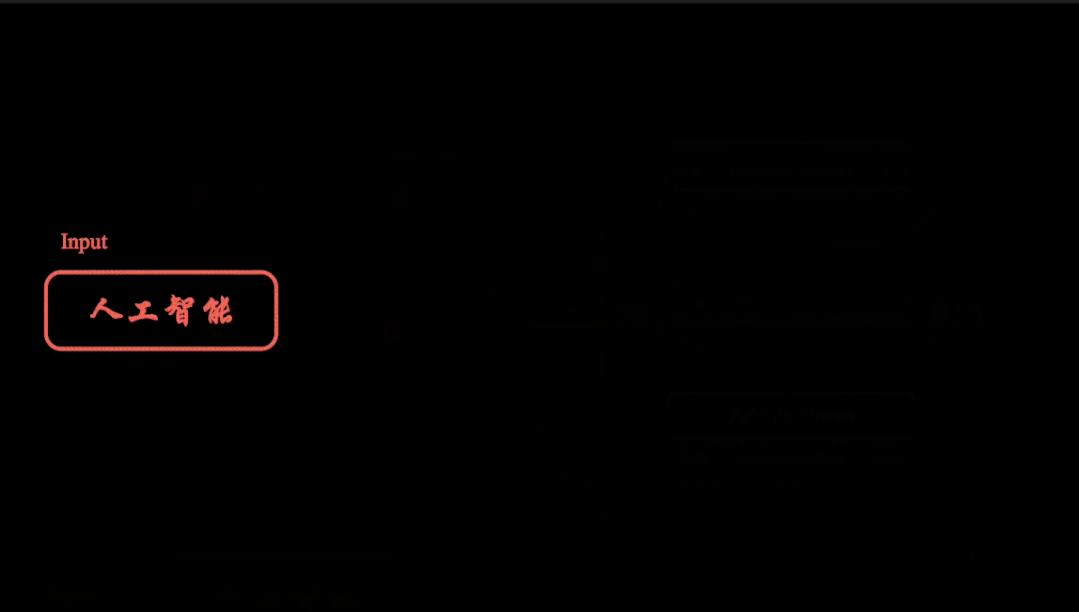
- https://openai.com/research/video-generation-models-as-world-simulators
- 更多transformer,VIT,swin tranformer
- 参考头条号:人工智能研究所
- v号:启示AI科技
- 微信中复制如下链接,打开,免费使用chatgpt
-
- https://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24

