
- 1四、张量表示_张量显示
- 2FastDFS【FastDFS概述(简介、核心概念 、上传机制 、下载机制)】(一)-全面详解(学习总结---从入门到深化)
- 3使用openvpn连通多个机房内网
- 4linux中clear报错:terminals database is inaccessible的解决方法
- 5OpenWrt下mwan3定时重启_openwrt定时重启
- 6android从strings资源文件获取,并拼接字符串方法_android 从资源文件拼接string
- 7SQLite3移植到ARM Linux教程_sqlite3数据库移植到arm
- 8【Linux】list_for_each_entry用法
- 9Linux | firewall命令 对外开放端口、查看端口、防火墙开启、防火墙关闭_firewall永久开放端口
- 10GitHub上受欢迎的Android UI Library_github 上最受欢迎的android ui
有关摔倒检测数据集(fall detection databases)_摔倒数据集
赞
踩
近期学习摔倒检测,接触摔倒数据集,自学笔记,仅用作个人复习。
- the UR fall detection dataset (URFD)
- the fall detection dataset (FDD)
UR Fall Detection Dataset
(University of Rzeszow - 热舒夫大学)
数据集网站:http://fenix.univ.rzeszow.pl/~mkepski/ds/uf.html
简介:该数据集包含 70 个 (30 个跌倒 + 40 个日常生活活动) 序列。使用 2 台 Microsoft Kinect 相机和相应的加速度计数据记录跌倒事件。ADL 事件仅用一台设备 (camera 0) 和加速度计记录。使用 PS Move (60Hz) 和 x-IMU (256Hz) 设备收集传感器数据。
数据集组织如下。camera 0 and camera 1 每行包含深度和 RGB 图像序列 (平行于地板和吸顶分别安装),同步数据和原始加速度计数据。每个视频流都以 png 图像序列的形式存储在单独的 zip 存档中。
“图像深度是指存储每个像素所用的位数,也用于量度图像的色彩分辨率。图像深度确定彩色图像的每个像素可能有的颜色灰度图像的每个像素可能有的灰度级数.它决定了彩色图像中可出现的最多颜色数,或灰度图像中的最大灰度等级。比如一幅单色图像,若每个像素有8位 例如:一幅画的尺寸是1024*768,深度为16,则它的数据量为1.5M。 计算如下:1024*768*16bit(位)=(1024*768*16)/8Byte(字节)=[(1024*768*16)/8]/1024KB=1536KB={[(1024*768*16)/8]/1024}/1024MB=1.5MB。”
有关深度图像可以参考 https://blog.csdn.net/dujuancao11/article/details/108960398
数据集详情:
Fall sequences
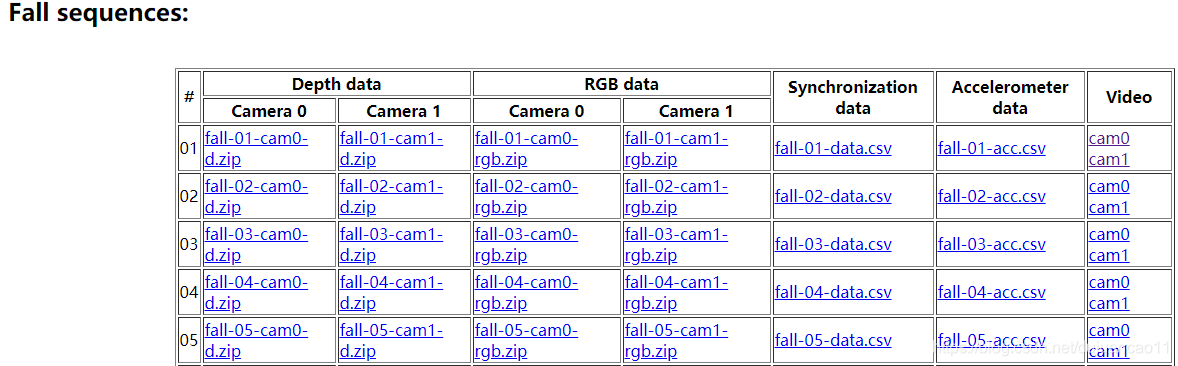
Fall sequences——》Depth data——》Camera 0——》fall-01-cam0-d


Fall sequences——》Depth data——》Camera 1——》fall-01-cam1-d


Fall sequences——》RGB data——》Camera 0 ——》fall-01-cam0-rgb


RGB data——》Camera 1——》fall-01-cam1-rgb


Synchronization data(同步数据)
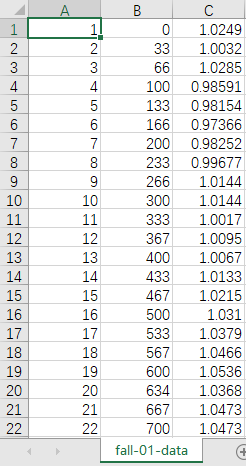
fall-01-data
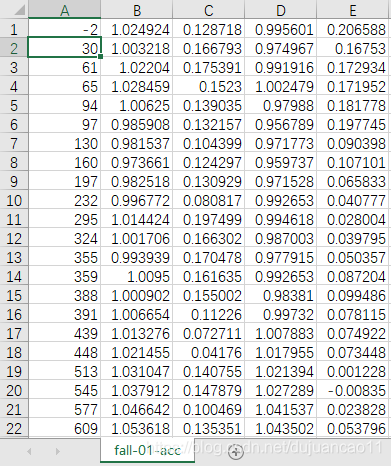
Accelerometer data(加速度数据)
fall-01-acc
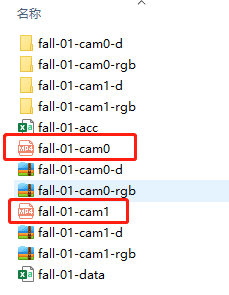
Video:
cam0 cam1
Activities of Daily Living (ADL) sequences:
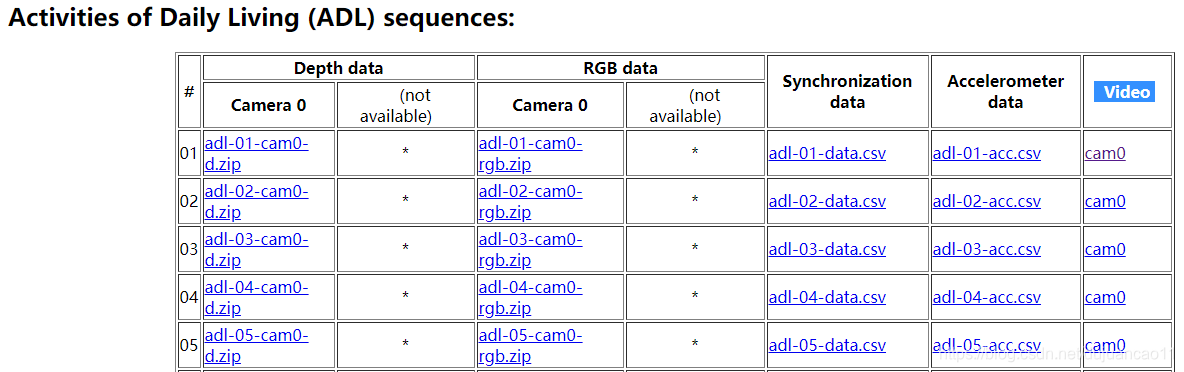
Activities of Daily Living (ADL) sequences——》Depth data——》Camera 0——》adl-01-cam0-d


Activities of Daily Living (ADL) sequences——》RGB data——》Camera 0——》adl-01-cam0-rgb


Synchronization data——》adl-01-data

Accelerometer data
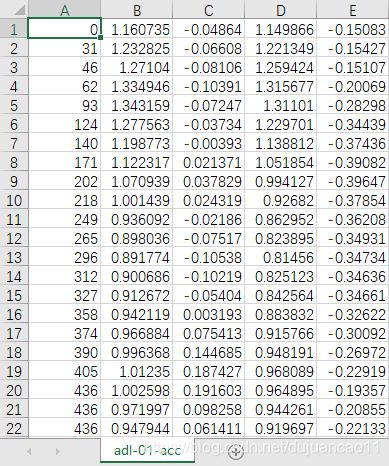
Video——》cam0
Extracted features
从深度图像中提取的特性以CSV格式存储。每一行包含一个数据样本,对应于一个深度图像。各列从左到右排列如下:
- sequence name - camera name is omitted, because all of the samples are from the front camera ('fall-01-cam0-d' is 'fall-01', 'adl-01-cam0-d' is 'adl-01' and so on),
- frame number - corresponding to number in sequence,(帧编号-对应于序列中的编号,)
- label - describes human posture in the depth frame; '-1' means person is not lying, '1' means person is lying on the ground; '0' is temporary pose, when person "is falling", we don't use '0' frames in classification,
(标签-在深度框中描述人体姿态;“-1”表示人没有躺下,“1”表示人躺在地上;“0”是暂时的姿势,当人“正在坠落”时,我们在分类时不使用“0”帧,) - HeightWidthRatio - bounding box height to width ratio,(高宽比-限定框高宽比,)
- MajorMinorRatio - major to minor axis ratio, computed from BLOB of segmented person,
- BoundingBoxOccupancy - ratio of how bounding box is occupied by person's pixels,(包围框中人的像素占据的比率,)
- MaxStdXZ - standard deviation of pixels from the centroid for the abscissa (X axis) and the depth (Z axis), respectively (it is computed on segmented person transformed to the 3D point cloud),
(MaxStdXZ -分别为横坐标(X轴)和深度(Z轴)的像素与质心的标准差(对分割后的人转换为三维点云计算),) - HHmaxRatio - human height in frame to human height while standing ratio,
(站立时,人体身高在包围框中占得比例) - H - actual height (in mm),(H -实际高度(单位mm),)
- D - distance of person center to the floor (in mm),(D -人员中心到地面的距离(单位mm),)
- P40 - ratio of the number of the point clouds belonging to the cuboid of 40 cm height and placed on the floor to the number of the point clouds belonging to the cuboid of height equal to person's height.
(放置在地板上的40cm高的长方体的点云数量与身高等于人的长方体的点云数量之比。)

urfall-cam0-adls
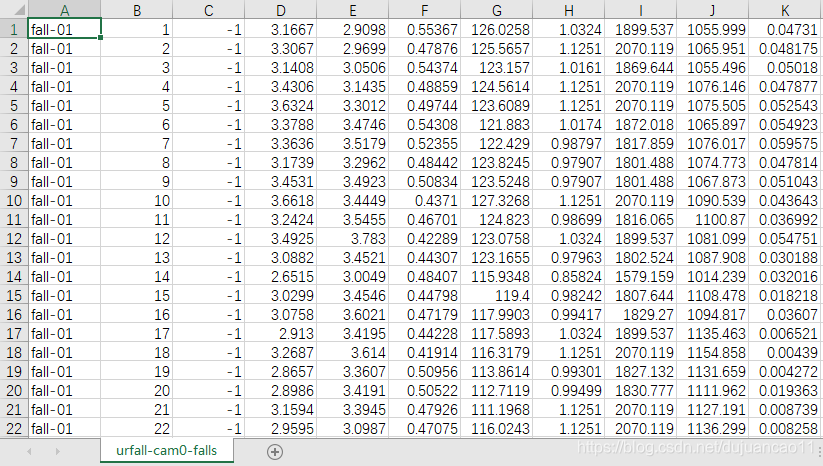
urfall-cam0-adls

Fall detection Dataset
用于模拟目的的数据集是原始RGB和深度图像,大小为320x240,由一个未校准的Kinect传感器在640x480大小调整后记录。
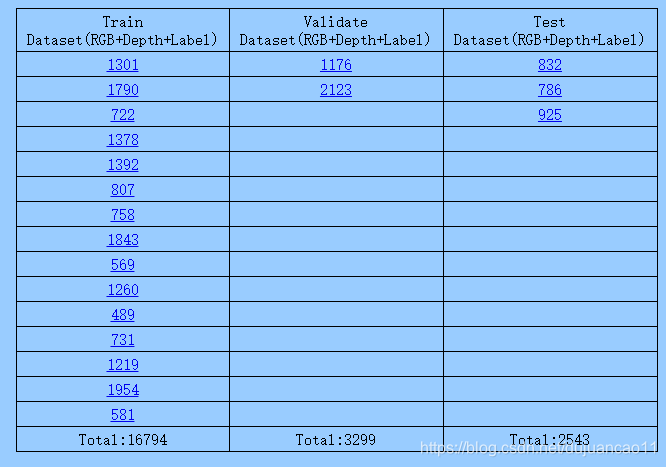
Kinect 传感器固定在屋顶高度约 2.4m 处。数据集总共包含 21499 张图像。在 22636 张图像的全部数据集中,可以使用 16794 张图像进行训练,可以使用 3299 张图像进行验证,可以使用 2543 张图像进行测试。
有 5 位不同的参与者,其中有两名 32 岁和 50 岁的男性参与者和三名 19、28 和 40 岁的女性参与者。参与者的所有活动都代表 5 种不同的姿势,这些姿势包括站立、坐着、躺着、弯曲和爬行。每个图像中只有一个参与者。数据集中的某些图像为空,被归类为 other。
我们使用了 2 位参与者的图像:32 岁的男性和 28 岁的女性,总共 16794 张训练图像,3299 张验证图像,其中训练集包含来自 32 岁的男性参与者,但是位于不同的房间训练和测试集。同样,测试集包含 3 名参与者的图像,其中 2 名女性参与者的年龄分别为 19 岁和 40 岁,男性参与者的年龄为 50 岁。
这些总共 22636 张图像是按顺序排列的,但是没有在序列中的任何位置重复,并且所有集合都依次添加了原始图像和其水平翻转图像,以增加集合中图像的数量。


1. 阿迪卡里、克里佩什、哈米德·布沙基亚和哈马迪·纳伊特-查里夫。基于卷积神经网络的室内坠落检测活动识别 机器视觉应用(MVA),2017年第十五届IAPR国际会议。IEEE,2017年。
(1. Adhikari, Kripesh, Hamid Bouchachia, and Hammadi Nait-Charif. "Activity recognition for indoor fall detection using convolutional neural network." Machine Vision Applications (MVA), 2017 Fifteenth IAPR International Conference on. IEEE, 2017.)

