
- 1es自学笔记--应用_cluster.initial_master_nodes中填什么
- 2mysql强制索引查询_mysql 索引查询优化
- 3修改电脑C:\User\用户名文件夹的名字_c:\users\后面的用户名怎么改
- 4CorelDRAW2020下载使用教程详解_shellext.msi
- 5java地图图表动态亮点,echarts全国地图图表标注效果
- 6Axure元件库的介绍以及个人简介和登录界面案例展示_axure登录页组件
- 7Nginx 配置 HTTPS 完整过程
- 8Finding crash information using the MAP file_wall paper 发生 crash information written
- 9linux sudo 命令无法使用,Linux运维知识之解决Linux下无法使用sudo命令问题
- 10Unity3d--C#封装输入键(移动,鼠标,跳,开火,换弹,蹲下)_unity封装按键系统
基于transformer和图卷积网络的人体运动预测时空网络_transformer行人轨迹预测
赞
踩
效果演示:
python行为识别行为骨骼框架检测动作识别动作检测行为动作分类
近年来,人体运动预测已成为计算机视觉领域的一个活跃研究课题。然而,由于人体运动的复杂性和随机性,它仍然是一个具有挑战性的问题。在以前的工作中,人体运动预测一直被视为典型的序列间问题,并且大多数工作旨在捕获连续帧之间的时间依赖性。然而,尽管这些方法侧重于时间维度的影响,但很少考虑空间中不同关节之间的相关性。因此,考虑人体关节的时空耦合,提出一种基于变压器和图形卷积网络(GCN)(STTG-Net)的新型时空网络。时间变换器用于捕获全局时间依赖性,空间 GCN 模块用于在每个帧的关节之间建立局部空间相关性。为了克服运动预测中误差累积和不连续的问题,还提出了一种基于融合策略的修正方法,将当前预测帧与前一帧进行融合。实验结果表明,与以往的预测方法相比,所提出的预测方法预测误差更小,预测运动更平滑。通过与 Human3.6 M 数据集上的最新方法进行比较,还证明了所提出方法的有效性。其中当前预测帧与前一帧融合。实验结果表明,与以往的预测方法相比,所提出的预测方法预测误差更小,预测运动更平滑。通过与 Human3.6 M 数据集上的最新方法进行比较,还证明了所提出方法的有效性。其中当前预测帧与前一帧融合。实验结果表明,与以往的预测方法相比,所提出的预测方法预测误差更小,预测运动更平滑。通过与 Human3.6 M 数据集上的最新方法进行比较,还证明了所提出方法的有效性。
介绍
人体运动预测是基于提供的观察姿势序列预测未来姿势。它在人机交互、自动驾驶、人体跟踪和医疗保健等领域具有广阔的应用前景。如今,可以利用动作捕捉设备准确获取人体骨骼序列。因此,利用这些序列来预测人体未来的姿势是可行的。人体运动预测问题通常被表述为序列建模问题,解决该问题的常用方法是在时间维度中对上下文信息进行建模,以捕获连续帧之间的时间依赖性。
在之前的研究中,大多数方法都使用了顺序自回归或序列到序列编码器-解码器模型。然而,由于人体运动是一个随机过程,难以捕捉长期的历史信息,因此随着预测范围的增加,更容易生成静态姿势。因此,运动预测不仅要依赖于序列之间的时间关系,还要依赖运动中不同关节的空间耦合关系。例如,在“走”这个动作中,两臂的摆动方向应该相反,这样在“走”的过程中,两臂的关节会相互影响。在动作识别研究中也考虑了时空依赖性 [ 1 , 2],进一步提高了动作的识别率。最近,也有考虑空间依赖性的研究。李等。[ 3 ]通过卷积滤波器捕获空间依赖性,但依赖性受卷积核的影响很大。此外,毛等人。[ 4 ]使用图神经网络来模拟空间相关性。
过去的研究表明,相对复杂的网络通常需要同时考虑时间和空间依赖性,此外,近年来,transformer 模型在计算机视觉领域越来越受欢迎,并取得了意想不到的性能。与其他神经网络相比,Transformer完全基于注意力机制,没有复杂的网络结构,参数数量少。即使是最原始的变压器结构也可能产生与复杂神经网络相当的结果。因此,通过之前的研究,transformer 被引入作为以前使用的时间建模的替代品,并将 transformers 与其他神经网络结合起来对时空依赖性进行建模,
受累积误差的影响,预测误差随着预测长度的增加而逐渐增大。而且,当预测误差突然增大时,会出现“跳帧”现象,预测的运动会变得僵硬。鉴于人体运动的连续性,本文提出了一种基于融合策略的预测修正模块。可以将当前预测帧与前一帧进行融合,有效降低预测误差,提高预测动作的连续性。
基于循环神经网络的方法
Fragkiadaki 等。[ 12 ]构建了编码器-递归-解码器和 3 个 LSTM 层,将它们与非线性多层前馈网络相结合来预测视频中人体骨骼的运动趋势,并合成新颖的运动,同时避免长时间漂移。为了对整个身体和单个肢体进行动态建模,Jain 等人。[ 13 ] 提出了 S-RNN 模型,使用由 LSTM 组成的节点和边的结构图进行运动预测,然而,他们忽略了观察和预测姿势之间的不连续性问题。此外,Martinez 等人。[ 14] 通过使用具有剩余结构的简单门控循环单元 (GRU) 解决了不连续性问题,并展示了对特定速度建模的效果。为了合成复杂的运动并生成不受约束的运动序列,Zhou 等人。[ 15 ] 提出了一种自动调节的 RNN 模型,能够生成任意长度的运动序列,并且没有刚度问题。对于预测中的静态接头,Tang 等人。[ 16 ] 提出了一种改进的高速公路单元,通过总结与基于 RNN 的当前预测相关的历史姿势以及框架注意模块来有效消除静态姿势。为了引导模型生成长期运动轨迹,Gopalakrishnan 等人。[ 17] 在具有包含顶层和底层 RNN 的两级处理架构的神经时间模型中使用导数信息作为计算特征。Liu 等人提出的分层运动循环网络。[ 18 ]使用 LSTM 对全局和局部运动上下文进行分层建模,并通过使用李代数来表示骨架框架来捕获关节之间的相关性。电晕等。[ 19 ]提出了一种上下文感知的人体运动预测方法,该方法使用语义图模型来构建场景中物体空间布局的影响,并引入RNN来提高人体运动预测的准确性。为了结合人体轨迹对运动的影响,Adeli 等人。[ 20] 使用 GRU 对轨迹和姿态信息进行编码,以解决端到端结构中预测人体轨迹运动和骨骼姿态的任务。RNN 具有出色的时间建模能力,但大多数使用 RNN 建模的作品都忽略了人体关节之间的空间相关性。
其他方法
李等。[ 3 ] 同时考虑了人体运动的不变和动态信息,并使用多层卷积序列到序列模型来学习空间和时间特征,从而实现更准确的预测。考虑到运动过程中身体各部分的活动程度不同,Guo和Choi [ 21 ]以人体为基础将身体结构分为五个不重叠的部分分别学习局部结构表示,在长期预测。同样,李等人。[ 22 ] 进一步改进了 Guo 和 Choi 的想法 [ 21] 将人体仅分为五部分,构建由多尺度图组成的encoder-decoder结构,提取不同尺度的人体运动特征,进一步提高预测性能。巴苏姆等。[ 23 ] 尝试使用 GAN 来产生预测输出,并将高斯分布向量 z 添加到 GAN 中以增加预测序列的多样性。在 Gui 等人提出的对抗性几何感知编码器-解码器框架中引入了两个全局互补鉴别器。[ 24 ]通过局部和全局鉴别器提高长时间运动预测的准确性。为了改变人体运动预测任务的端到端训练方法,Wang 等人。[ 25] 通过提出强化学习公式和模仿学习算法将生成对抗性模仿学习框架扩展为能够准确预测姿势,从而将其转化为强化学习问题。帕夫洛等人。[ 26 ] 提出了一种基于四元数的姿态表示方法,解决了欧拉角和轴角表示引起的歧义和不连续性,并分别使用 RNN 和 CNN 提出了两个版本。结构训练使得预测位姿更准确,误差更小,但转换到四维空间相对复杂。毛等。[ 4]设计了一个简单的前馈深度神经网络,不同于姿势空间,它通过基于残差结构的离散余弦变换(DCT)在轨迹空间中编码时间信息。每个人体关节的时间变化表示为 DCT 系数的线性组合,使用 GCN 对关节之间的空间依赖性进行建模。在这项工作的基础上,Mao 等人。[ 27 ] 后来提出了一种基于运动注意的模型,通过从历史信息中形成运动估计来学习时空依赖性。估计与最新观察到的运动相结合,然后将组合输入到基于 GCN 的前馈网络中。最近,毛等人。[ 28] 研究了不同层次attention的使用,将attention具体应用于全身、身体部位和单个关节三个不同层次,并引入了融合模块将这种多层次attention机制结合起来,取得了更好的性能。Hermes 等人也通过实验发现了 GCN 的优势。[ 29 ],他设计了一个带有 GCN 的时空卷积来提取时空特征,使用扩展的因果卷积对时间信息进行建模,其中还包含局部联合连接,以获得轻量级的自回归模型。相比之下,Martínez-González 等人。[ 30] 提出了一种非自回归变换器模型来并行推断姿势序列,具有自我注意和编码器 - 解码器注意,并向编码器添加基于骨架的活动分类以通过动作识别改进运动预测。
CNN 通常通过在时间维度上执行卷积运算来抽象序列之间的依赖关系,但它在较长时间段内学习序列关系时效果不佳。GCN 可以通过生成器和鉴别器的监督学习有效地学习运动序列的时间依赖性,但 GAN 相对难以训练且参数调整复杂。尽管 RNN 更适合处理具有时间依赖性的数据,但它们学习长期相关性的能力仍然较弱,而 transformer [ 31]] 可以通过注意力机制对输入和输出的全局依赖进行建模,可以打破RNN限制并行计算和长距离学习的局限性。此外,大多数方法都是对时间关系进行建模,忽略了关节的空间相关性,而 GCN 可以专门处理非欧几里德类型的数据,并且可以通过定义在时间连接运动上的图来捕获人体关节的时间和空间依赖性树。据了解,transformer 尚未广泛用于人体运动预测,但已被广泛用于人体姿势估计任务[ 32、33 ]。为了使用更紧凑的人体骨骼表示,这项研究受到论文的影响 [ 4, 27 ] 并使用 DCT 系数进行运动变换。
方法
本研究提出了一种基于 Transformer 和 GCN 的 STTG-Net,它综合考虑了人体运动中的时间和空间依赖性,以提高运动预测的准确性。整体网络框架如图1所示。
图。1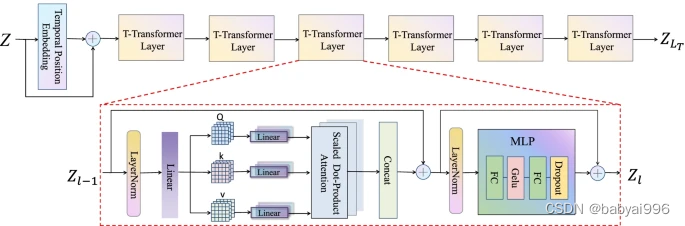
结果与讨论
为了证明本研究提出的STTG-Net的有效性,在Human3.6M数据集上进行了实验。将结果与最先进的方法进行比较和分析。
实验细节
所提出的网络模型是基于 Pytorch 框架实现的,并使用 ADAM 优化器对其进行训练 [ 37 ]。所有实验结果均使用单张 NVIDIA 1080Ti 显卡获得。批量大小设置为 32,训练时期数设置为 3000,学习率为 0.0005。网络的参数大小为 2.33 M。
关节角度用于表示人体姿势。给定输入的关节角度,使用DCT得到相应的系数,然后在训练模型后应用IDCT将预测的DCT系数恢复到相应的角度。为了有效地训练网络,将预测的关节角度与地面实况之间的平均L 1距离用作损失函数。
STTG-Net网络结构概述
首先,应用 DCT 将每个关节的时间信息编码到轨迹空间中。其次,计算出的 DCT 系数通过时间位置嵌入 (TPE) 传递,然后是时间变换器,以学习整个时间序列的全局依赖性。然后,基于一堆图卷积块的空间 GCN 模块可以有效地学习局部关节之间的相关性。最后,在测试阶段,增加预测修正模块,进一步纠正预测动作的错误。与之前的模型相比,该模型分别在时间和空间维度上捕捉全局和局部依赖关系,并对人体骨骼关节随时间的运动进行建模,因此预测结果更具竞争力。
预测修正模块
人体运动预测中的一个普遍问题是难以从其预测误差中恢复,从而导致误差累积和运动不连续。以前的工作通常通过基于采样的损失 [ 14 ] 和收敛损失 [ 21 ] 来解决这个问题,或者通过 GAN 强制网络的内部状态,这两者都在一定程度上增加了网络的超参数. 与以往的工作不同,本研究在测试阶段增加了一个简单有效的预测修正模块,以减少模型的最终预测误差,如图4 所示. 该模块基于融合策略,将当前预测帧与前一帧的预测信息融合,然后将融合值用作当前帧的预测值。这种考虑的基础是人的动作是连续的,相邻两帧的动作差异不应该太大。因此,如果当前帧产生较大的预测误差,与前一帧的预测融合将“拉回”当前帧的预测,以防止运动突然跳跃。从而减少了预测误差,提高了运动的平滑度。具体的融合方程如下所示:
实验结果
与之前的研究一致,该模型使用 50 帧进行训练,并预测接下来 10 帧的姿势。表1 [ 3 , 14 , 22 , 27 , 29 , 30 , 34 , 39 , 40 ]展示了所有动作的关节角度误差结果与本模型在Human3.6 M上的baselines对比。为了更直观的观察结果,所有实验结果中最好的结果以粗体显示,次优结果以斜体显示。
表1 在Human3.6M上与baselines相比所有动作的关节角度误差和平均角度误差
从比较结果可以看出,与运动预测中的常见基线[ 3、14 ]相比,STTG-Net在除'Phoning'运动之外的所有其他动作上都有很大改进。这主要是因为“打电话”运动具有较少的时空依赖性,因为它的运动主要发生在一只手上,而身体的其余部分几乎是静止的。即便如此,STTG-Net 在此操作上取得了次优结果。与最近提出的也使用变换器进行运动预测的方法[ 34 ]相比,所提出的方法产生的每个动作的误差几乎更小,从而产生更好的平均误差结果。因为 ST 变压器 [ 34]更注重长期预测,它在超过1s的运动中表现更好,表明时空变换器的优势随着时间的增加更加明显。该研究更侧重于短期运动预测,仅使用时间变换器来捕获时间关系,在短期预测中产生了优异的结果,这表明了时间变换器在本研究中的有效性。对于参考文献中提出的其他最近提出的方法。[ 22 , 29 , 30 , 34 , 39 , 40],STTG-Net在一半以上的动作上取得了最优结果,在其他动作上取得了近似最优的结果。在平均误差的对比中,除了80 ms的次优结果外,STTG-Net分别在160、320和400 ms取得了最好的结果。此外,与最先进的方法相比,平均预测误差在 160 毫秒时降低了 3.85%,在 320 毫秒时降低了 2.44%,在 400 毫秒时降低了 5.32%。此外,从实验结果可以看出,随着预测时间的增加,STTG-Net的预测误差增长较慢,表明该方法的误差累积较小。
由于STTG-Net采用transformer结构,模型相对简单,参数较少。总参数量仅为 2.33 M,而 ref 的总参数量。[ 27 ]为3.08 M。为了更直观地展示本研究方法的优势,对部分预测结果进行了可视化对比,对比结果如图5 所示。
图 5
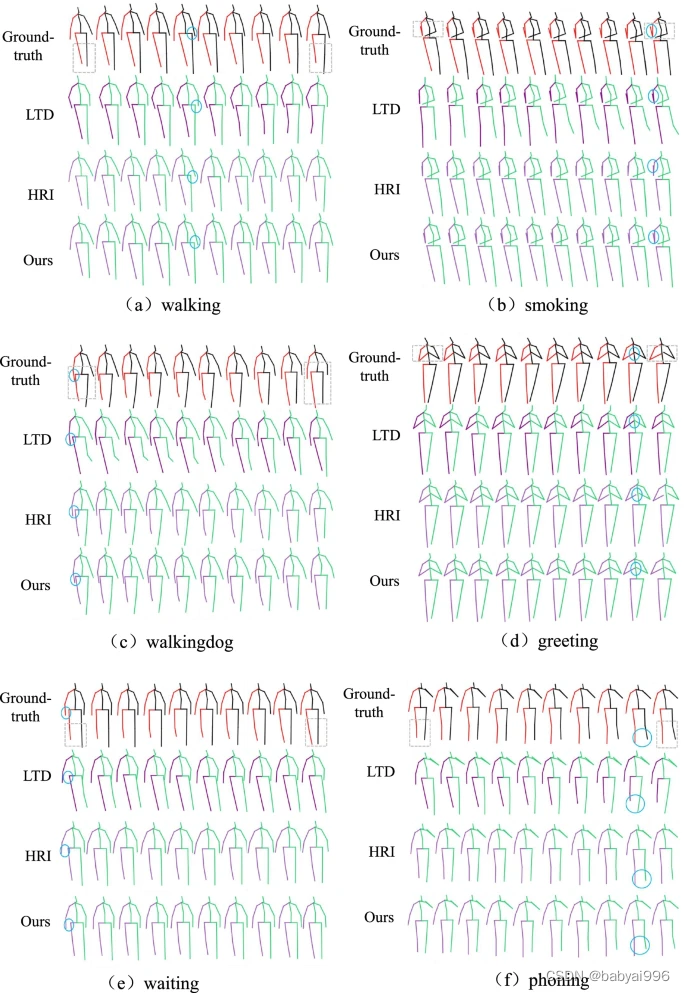
Human3.6 M. The ground-truth, LTD [ 4 ], HRI的(a) walking (b) smoking (c) walkingdog (d) greeting (e) eating (f) phoning phoneing 四种动作的预测可视化结果[ 27 ],并从上到下显示了所提出的方法。从预测的第一帧到最后一帧的动作变化可以在灰色虚线框中清楚地看到,而蓝色圆框显示了通过所提出的方法和其他方法预测的动作与地面实况之间的比较。从可视化结果可以看出,与 HRI 和 LTD 相比,所提出的方法产生的预测更接近于真实情况。
结论
本工作提出的时空网络(STTG-Net)利用其内部的T-transformer和S-GCN两个模块对人体骨骼关节的时空依赖进行建模,预测修正模块可以通过融合减少累积误差将当前预测帧与上一帧的预测信息相结合,以更好地完成人体运动预测的任务。在 Human3.6 M 数据集上的实验表明,与常用的基线和最近发布的运动预测模型相比,所提出的方法在大多数动作上都取得了最先进的结果。尽管 STTG-Net 使用相对较少的参数在短期运动预测中取得了出色的结果,但在减少参数量和改善长期运动预测结果方面仍有空间。为了以后的工作,我们将继续尝试构建轻量级网络以进一步减少网络参数,并研究算法以学习校正模块的融合变化。此外,我们将继续探索长期运动预测模型。
参考
-
Wang H, Wang L (2017) 使用双流递归神经网络对动作的时间动态和空间配置进行建模。论文发表于 2017 年 IEEE 计算机视觉和模式识别会议,IEEE,火奴鲁鲁,2017 年 7 月 21 日至 27 日。https: //doi.org/10.1109/CVPR.2017.387
-
Liu J, Shahroudy A, Xu D. Kot AC, Wang G (2018) 使用带信任门的时空 LSTM 网络进行基于骨架的动作识别。IEEE Trans Pattern Anal Mach Intelli,40(12):3007-3021。Skeleton-Based Action Recognition Using Spatio-Temporal LSTM Network with Trust Gates | IEEE Journals & Magazine | IEEE Xplore
-
Li C, Zhang Z, Lee WS, Lee GH (2018) 人类动力学的卷积序列到序列模型。在 2018 年 IEEE/CVF 计算机视觉和模式识别会议上发表的论文,IEEE,盐湖城,2018 年 6 月 18 日至 23 日。https: //doi.org/10.1109/CVPR.2018.00548
-
Mao W, Liu MM, Salzmann M, Li HD (2019) Learning trajectory dependencies for human motion prediction。论文于 2019 年 10 月 27 日至 28 日在首尔 IEEE 举行的 2019 年 IEEE/CVF 计算机视觉国际会议上发表。https: //doi.org/10.1109/ICCV.2019.00958
-
Tanco LM, Hilton A (2000) 从动作捕捉示例数据库中真实合成新的人体动作。12 月 7 日至 8 日在奥斯汀 IEEE 人体运动研讨会上发表的论文。Realistic synthesis of novel human movements from a database of motion capture examples | IEEE Conference Publication | IEEE Xplore

