
热门标签
热门文章
- 1Linux环境中的git
- 2Android 9.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析_android 通知栏 左右
- 3double和float的精度和取值范围_double范围
- 4CNN卷积神经网络学习笔记(特征提取)_cnn提取三维数据特征
- 5VGG16网络模型_vgg16模型图
- 6机器学习系列(13)_PCA对图像数据集的降维_02_图片 pca降维
- 7unity3d功能脚本大全_gui.drawtexture(new rect(0, 0, screen.width, scree
- 85个ai工具导航网站,最新最全的ai网址_ai产品行业看哪些网站
- 9Exit 0、exit 1、exit -1 的区别_exit(0)和exit(-1)
- 10Oracle listener lsnrctl_lsnrctl 启动特定实例
当前位置: article > 正文
大白话chatGPT & GPT的发展区别_gpt chatgpt
作者:凡人多烦事01 | 2024-02-25 00:25:25
赞
踩
gpt chatgpt
大白话chatGPT & GPT的发展区别
chatGPT今年年初的时候是非常火爆的,现在也有很多相关的应用和插件。当然现在也有很多新的技术出现,比如autoGPT,它实际上就是嵌套chatGPT。所以这里笔者我希望通过通俗易懂的语言描述一下chatGPT的原理。当然这里笔者是根据自己看的知识进行快速的印象中的总结,如果有不对的地方,非常欢迎指正,也欢迎大家互相学习与交流。
从GPT名字理解chatGPT
chatGPT它是基于GPT3的。GPT也就是Generative Pre-training Transformer模型。从名字上来看,其实也可以知道GPT模型其实有三个核心点:
- 一个是Generative生成式,也就是说GPT它其实是一个生成模型,而且这个生成模型它是基于NLP领域的,所以chatGPT就可以看成一个文字接龙的生成式模型(从外观上看,像前端的流式输出)。
- 第二个是Pre-train预训练,也就是说GPT是一个基于预训练微调的模型,而且GPT是基于大语言模型(LLM)的,因为需要有足够多的数据才能保证更好的语义理解和上文理解。
- 第三个是Trasformer,也就是说GPT模型都使用了Transformer的架构,这就意味着它们都有编码器和解码器来处理输入输出并且都基于多头自注意力机制来实现的,这样子可以使模型关注会话中的不同部分,从而来推断出会话本身的含义和上下文。因为句子中不同词的重要性是不一样的。除此之外,GPT的解码器利用了掩码来进一步构建训练的数据集,这样子其实就像挖词填空,更加有利于模型学习文字跟文字的关系,更有利于文字接龙的准确性。
如果对Transformer不是很理解,可以看我的另外一篇博客《从前端角度快速理解Transformer》。
chatGPT三步曲
因为chatGPT是基于GPT的嘛,所以它的原理其实跟GPT是有些类似的,但它引入评分反馈的训练机制来进行强化学习【人类反馈强化学习RLHF】。主要实现的流程也一样是三部曲:
- 第 1 步:监督微调 (SFT) 模型,利用海量的问答式样本数据集对GPT模型的输出方向进行监督训练,引导GPT采用问答对话的形式进行内容输出。通过微调策略得到GPT-3.5模型。
- 第 2 步:训练一个奖励模型(RM)。训练一个奖励模型对GPT-3.5模型的输出进行一个排序评分,就相当于一个老师,当给出一个问题和四个答案,老师负责按照人类的偏好给这些答案进行打分,将答案进行排序。所以这里的设计跟以往的模型不太一样,因为这里是对输出结果进行排序而不是取值或者取分布。【这里也是有监督数据集的】,基于对比的数据训练建立模型。
- 第 3 步:利用强化学习最大化奖励。基于上面的两步,就可以拥有一个具备对话的GPT和一个能够按照人类偏好进行打分的奖励模型,因此到这里我们就可以利用强化学习来进行一步的自我训练,从而最大化第二步里面的评分。
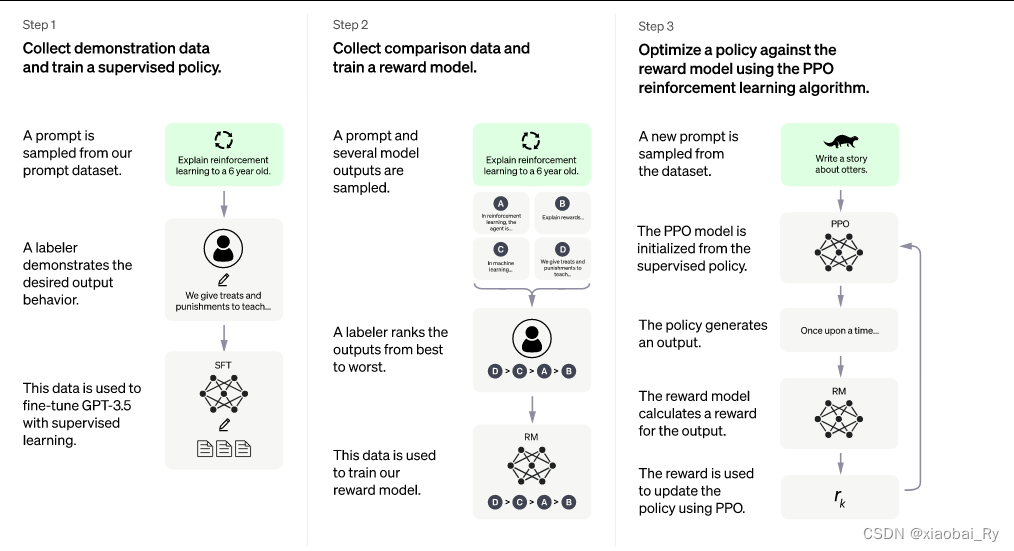
通过上面的训练就可以得到最后的chatGPT模型。
GPT-1到GPT-4
GPT-1~GPT-4的相同点
GPT-1到GPT-4,包括chatGPT的结构其实都是大语言模型,都是基于Transformer的Decoder层,都秉承着不断堆叠Trasnformer的思想,通过不断替身训练的预料规模和质量,提升网络的参数量来完成进一步的迭代更新和性能优化,所以我们也可以看到GPT发展到现在它的参数量从以前GPT-1的1点多个亿的参数量到现在GPT-4的100万亿的参数量,增长速度我认为是堪比指数的
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/137146
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

