
- 1element的el-select组件数据过多使用分页_
- 2slot是什么?有什么作用?_slot的作用
- 3k8s获得所有pod命令_k8s查看所有pod
- 4Android字体描边和阴影,CSS基础:通过文字阴影实现文字的立体感,印刷感,描边和虚化效果...
- 5Linux上搭建git服务器_linux 搭建git site:csdn.net
- 6【超详细】Python如何使用Pyecharts+TextRank生成词云图_pyecharts 基本图表之词云图
- 7Linux下的TCP测试工具_linux tcp服务器工具
- 8Web文本去噪——基于DOM树的哈希值去噪法_hash算法用于降噪
- 9ChinaSkills-网络系统管理(2021年全国职业院校技能大赛A-1 模块 A:Linux 环境 真题 )_创建网站 download.chinaskills.cn 站点; 仅允许 ldsgp 用户访问;
- 10【Python Web】Flask框架(十)前端+python+MYSQL案例_python+mysql+django/flask
(二) MdbCluster分布式内存数据库——分布式架构
赞
踩
分布式架构是MdbCluster的核心关键,业界有很多相关的实现,却很少有文章详细的解释每个架构实现背后的细节和这么做的原因。在MdbCluster整个研发和测试的过程中,我们不断的遇到各种各样的问题,分析问题的原因,修改相应的设计和实现,再回归测试。很多在设计的时候一些颇为得意的trick,却造成测试时整个系统运行的灾难。无数次的推到重来警醒我们——在没有详细的测试数据支撑的情况下,不要在设计阶段以增加系统复杂度为代价来进行某些想象的优化。虽然我们一直知道这是一条真理,但总有忍不住、自作聪明的时候。现实总能一次次地将我们拉回原地——Keep it simple,stupid! 本文试图总结这一年来我们交的经验税,来详细阐述那些看似简单架构设计背后的复杂细节。
接我们上一章单节点的架构图,两个节点的架构图如下:
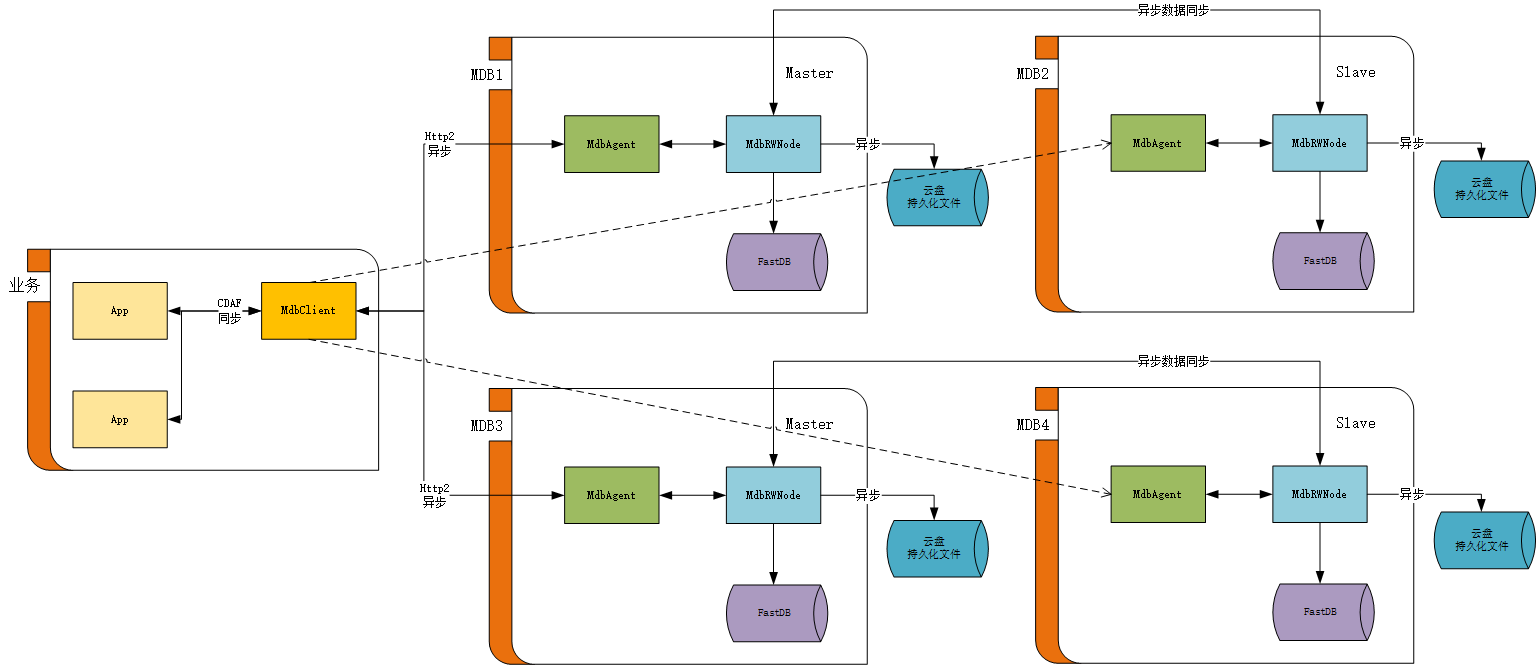
MdbClient与每个节点的MdbAgent建立连接,但只与Master节点进行业务通讯。这个架构本身很简单,几乎可以从1-N无限复制,是一个完全的分布式架构,无单点故障。下面我们通过假设读者的问题,来一步步的介绍整个架构。
1. 数据是根据什么策略来进行分片的?
2. 整个业务的交互流程是怎么样的?
3. 当某个节点状态和数量发生变化时,其它节点如何感知?
4. 扩容和缩容时,分片是如何调整的?
5. 业务消息是如何校验、错误消息如何重定向、超时消息如何处理?
一、 数据是根据什么策略来进行分片的?
关于MdbCluster的Sharding策略,我们直接采用了Redis的策略。Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:slot = CRC16(key) & 16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
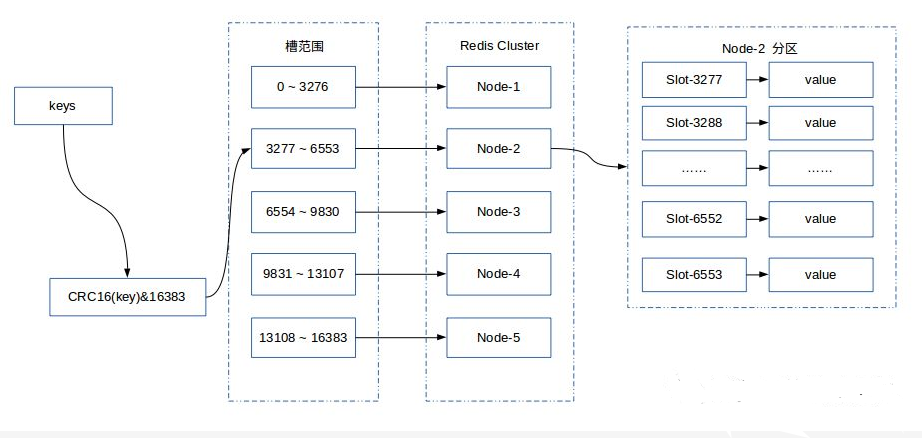
从我们项目实际使用过程,来说说这个分片规则的好处。
1. 通过 keys -> slot -> node的映射关系,解决了从表的partitionid到Mdbcluster分片nodeid的对应关系。
2. 为什么不是keys->node直接映射?在扩容和缩容的过程中,这种解耦将带来迁移的便利。利用上图举个简单例子,如果要将节点从5个扩到10个的时候,上述分片策略,只要将node1的slot(1638-3276)挪到node6。node2的slot(4914-6553)挪到node7。依此类推……只要进行5次节点间的数据迁移。但如果是直接映射,分片策略从keys%5->node 转为 keys%10->node,就会面临node1->(node2, 3, 4, 5, 6, 7, 8, 9,10)都要挪数据的场景,总共需要迁移的次数为9*5=45。反之,缩容也一样。
3. 为什么slot的数量是16384? 2的14次方。网上有很多说法,但我们的经验是:在扩缩容做数据迁移的时候,需要对这个slot的数据进行加锁。如果slot数量太少,锁定的数据量太大,从而造成迁移过程中业务请求失败太多。如果slot数量太多,迁移的批次过多,每次迁移的数据条数太少,造成迁移性能受影响。所以这个数字的大小其实是跟业务每张表的数据量有直接关系的。
二、整个业务的交互流程是怎么样的?
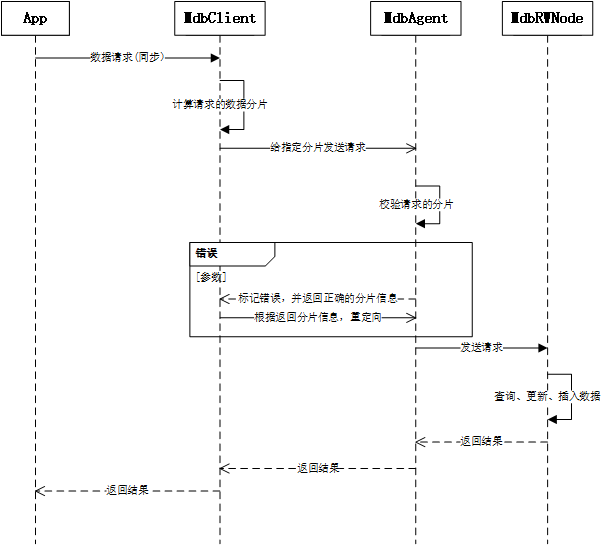
有两点需要特别说明,第一是App的驱动到MdbClient是同步请求,有超时管理。这样做的好处是简化业务逻辑。其它的环节均为异步消息,为了最大化的提高性能。第二是MdbClient到MdbAgent之间具备消息重定向的能力。这样做的好处是,在扩缩容的时候,可以减少App侧返回错误消息的数量。

