
- 1ubuntu下安卓刷机教程和scrcpy无线控制手机_ws-scrcpy 如何确定 安卓ip地址
- 2mysql 错误: unknown database 'xxxxx'_dbserver连接mysql数据库unknown database
- 3张量网络系列(TT分解 MPS)
- 4QT使用QImage做图片切割_qt切割图片
- 5Linux基础工具之vim[基础用法干货:三种模式,块选择,vim文件窗口,文件对比]_vim区块选择
- 6详细教程:AutoDL 如何配置深度学习环境?_autodl配置环境
- 7离线安装python、pip和python的第三方库_离线安装python第三方包的步骤
- 8景联文科技:以高质量数据赋能文生图大模型
- 9蓝桥杯-python大学b组-苏州城市学院-2023_4_4_1打卡_蓝桥杯pythona组2023
- 10计算机网络的八大性能指标,速率、带宽、吞吐量、时延、时延带宽积、往返时间、利用率、丢包率_计算机网络有哪些常用的性能指标?
MySQL索引类型(按数据结构分类)
赞
踩
1、树索引
二叉查找树
BST,binary search tree,二叉查找树是一种支持数据快速查找的数据结构,时间复杂度是O(lgn),支持范围查找。致命缺点:极端情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂退化为O(N),检索性能急剧下降。在数据库中,数据的自增是一个很常见的形式,比如一个表的主键是 id,而主键一般默认都是自增的,如果采取二叉树这种数据结构作为索引,什么提到的致命缺点,即不平衡状态导致的线性查找的问题必然出现。因此,简单的二叉查找树存在不平衡导致的检索性能降低的问题,是不能直接用于实现MySQL底层索引的。

红黑树
二叉查找树存在不平衡问题,因此学者提出通过树节点的自动旋转和调整,让二叉树始终保持基本平衡的状态,就能保持二叉查找树的最佳查找性能。基于这种思路的自调整平衡状态的二叉树有 AVL 树和红黑树。
红黑树,自动左旋右旋节点以及节点变色,调整树的形态,使其保持基本的平衡状态,时间复杂度为O(logn),保证查找效率不会明显减低。
但红黑树并没有完全解决退化为链表的这个问题,虽然右倾趋势远没有二叉查找树退化为线性链表那么夸张,但是数据库中的基本主键自增操作,主键一般都是数百万数千万的,若红黑树存在这种问题,对于查找性能而言也是巨大的消耗,我们数据库不可能忍受这种无意义的等待的。
,不错的查找性能,不存在极端的低效查找的情况。
可以实现范围查找、数据排序。
问题
数据库查询数据的瓶颈在于磁盘 IO,如果使用的是 AVL 树,每一个树节点只存储一个数据,一次磁盘 IO 只能取出来一个节点上的数据加载到内存里。所以我们设计数据库索引时需要首先考虑怎么尽可能减少磁盘 IO 的次数。
磁盘IO的特点,从磁盘读取1B数据和1KB数据所消耗时间是基本一样,根据这个思路,在一个树节点上尽可能多地存储数据,一次磁盘 IO就多加载点数据到内存,即B树,B+树的的设计原理。

B 树
尽可能在一次磁盘 IO 中多读一点数据到内存,反映到树的结构就是,每个节点能存储的 key 可以适当增加。
B树优点:
优秀检索速度,时间复杂度:B 树的查找性能等于O(h*logn),其中h 为树高,n 为每个节点关键词的个数;
尽可能少的磁盘 IO,加快了检索速度;
可以支持范围查找。
如下图就是一颗B-tree,是一颗三路树:

B+树
B 树和 B+树有什么不同呢?
B 树一个节点里存的是数据,而 B+树存储的是索引(地址),所以 B 树里一个节点存不了很多个数据,但是 B+树一个节点能存很多索引,B+树叶子节点存所有的数据。
B+树的叶子节点是数据阶段用一个链表串联起来,便于范围查找。
B+树节点存储的是索引,在单个节点存储容量有限的情况下,单节点也能存储大量索引,使得整个 B+树高度降低,减少磁盘 IO。其次,B+树的叶子节点是真正数据存储的地方,叶子节点用有序链表连接起来,在范围查找时效率更高。因此MySQL的索引用的就是 B+树,B+树在查找效率、范围查找中都有着非常不错的性能。

B tree 和 B+ tree
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。
B+ tree 是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
hash:虽然可以快速定位,但无序,IO复杂度高
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),IO代价高
红黑树:树的高度随着数据量增加而增加,IO代价高
问:为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
绝大多数的存储引擎,比如MyISAM和InnoDB都支持这种索引,但是不同的存储引擎在具体实现时会稍有不同,比如MyISAM会使用前缀压缩的方式对索引进行压缩,InnoDB则不会。
2、Hash索引
哈希索引基于哈希表实现,只有精确索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希存储在索引中,同时在哈希表中保存指向每个数据的指针。
MySQL中,只有Memory存储引擎显示支持hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B-Tree索引。Memory存储引擎支持非唯一hash索引,这在数据库领域是罕见的,如果多个值有相同的hash code,索引把它们的行指针用链表保存到同一个hash表项中。

针对上图的理解:
keys:代表创建索引的列值;
buckets: 就是计算出来的hash值和对应的数据的物理位置组成的hash表;
entries:就是代表具体的数据行;
创建hash索引后,会为每个键值通过特定的算法计算出一个哈希码(hash code),需要注意的是不同的键值计算出来的hash值可能是相同的,例上图上的 John Smith 和Sandra Dee算出来的hash值都是152,然后找到hash值为152在hash表中的存储数据的物理位置,这个位置对应着两条数据也(就是John Smith 521-1234 和Sandra Dee 521-9655),然后再次遍历这两条数据,找到需要的数据,这就解释了为啥hash冲突严重了,hash索引效率降低的原因。
hash索引检索数据的过程(摘杂网络)
当我们为某一列或某几列建立hash索引时(目前就只有MEMORY引擎显式地支持这种索引),会在硬盘上生成类似如下的文件:
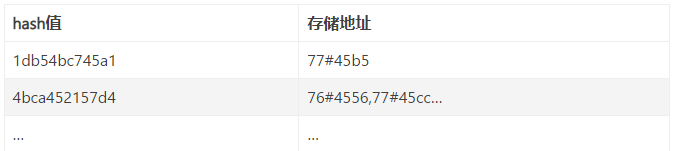
hash值即为通过特定算法由指定列数据计算出来,存储地址即为所在数据行存储在硬盘上的地址(也有可能是其他存储地址,其实MEMORY会将hash表导入内存)。
这样,当我们进行WHERE age = 18 时,会将18通过相同的算法计算出一个hash值==>在hash表中找到对应的储存地址==>根据存储地址取得数据==>最后一步确定这行数据是否是需要查询的数据。
所以,每次查询时都要遍历hash表,直到找到对应的hash值,数据量大了之后,hash表也会变得庞大起来,性能下降,遍历耗时增加;
Hash索引的优缺点
优点:
因为索引自身只需存储对应的哈希值,所以索引的结构十分紧凑,这也让哈希索引查找的速度非常快
缺点:
1、不能避免读取行
哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能的影响并不明显。
2、无法用于排序
哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
3、无法使用部分索引列匹配查找
哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。例如,在数据列(A,B)上建立哈希索引,如果查询只有数据列A,则无法使用该索引。
4、只支持等值查找
哈希索引只支持等值比较查询,包括=、IN()、<=>(注意<>和<=>是不同的操作)。也不支持任何范围查询,例如WHERE price>100。
5、存在Hash冲突
访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。
同时,当哈希冲突很多的时候,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。
综上,Hash索引只适用于某些特定的场景(也就是说实际使用中用得非常少-_-!)
InnoDB引擎有一个特殊的功能叫做“自适应哈希索引”。当InnoDB注意到某些索引值被使用得非常频繁时,它会在内存中基于B-Tree索引上再创建一个哈希索引,这样就像B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找。
查看当前自适应哈希索引的使用状况:ON表示开启自适应哈希索引
SHOW VARIABLES LIKE '%ap%hash_index';
- 1
创建哈希索引:如果存储引擎不支持哈希索引,则可以模拟像InnoDB一样创建哈希索引,这可以享受一些哈希索引的便利,例如只需要很小的索引就可以为超长的键创建索引。
思路很简单:在B-Tree基础上创建一个伪哈希索引。这和真正的哈希索引不是一回事,因为还是使用B-Tree进行查找,但是它使用哈希值而不是键本身进行索引查找。你需要做的就是在查询的where子句中手动指定使用哈希函数。这样实现的缺陷是需要维护哈希值。可以手动维护,也可以使用触发器实现。
如果采用这种方式,记住不要使用SHA1和MD5作为哈希函数。因为这两个函数计算出来的哈希值是非常长的字符串,会浪费大量空间,比较时也会更慢。SHA1和MD5是强加密函数,设计目标是最大限度消除冲突,但这里并不需要这样高的要求。简单哈希函数的冲突在一个可以接受的范围,同时又能够提供更好的性能。
如果数据表非常大,CRC32会出现大量的哈希冲突,CRC32返回的是32位的整数,当索引有93000条记录时出现冲突的概率是1%。
处理哈希冲突:当使用哈希索引进行查询时,必须在where子句中包含常量值。
3、空间(R-Tree)索引
MyISAM支持空间索引,主要用于地理空间数据类型,例如GEOMETRY。和B-TREE索引不同,这类索引无须前缀查询。空间索引会从所有到维度来索引数据。查询时,可以有效地使用任意维度来组合查询。必须使用MySQL的GIS相关函数如MBRCONTAINS()等来维护数据。MySQL的GIS支持并不完善,所以大部分人都不会使用这个特性。开源关系数据库系统中对GIS的解决方案做得比较好的是PostgreSQL的PostGIS。
4、全文(Full-text)索引
全文索引是MyISAM的一个特殊索引类型,innodb的5.6以上版本也支持,它查找的是文本中的关键词主要用于全文检索。
全文索引是一种特殊类型的索引,它查找都是文本中的关键词,而不是直接比较索引中的值。全文搜索和其他几类索引匹配方式完全不一样。它有许多需要注意的细节,如停用词、词干和复数、布尔搜索等。全文索引更类似于搜索引擎做的事情,而不是简单的WHERE条件匹配。
在相同的列上同时创建全文索引和基于值对B-Tree索引不会有冲突,全文索引适用于MATCH AGAINST操作,而不是普通的WHERE条件操作。
总结

B-Tree索引使用最广泛,主流引擎都支持。
哈希索引性能高,适用于特殊场合。
R-Tree不常用。
全文索引适用于海量数据的关键字模糊搜索。
相关链接:
MySQL索引类型(逻辑角度)
MySQL之MVCC实现原理
MySQL 索引底层原理
MySQL之InnoDB中一棵B+树能存多少行数据
MySQL数据库优化的八种方式
MySQL数据库优化-运维角度浅谈


