
- 1分类预测 | Matlab实现CNN-GSSVM卷积神经网络结合网格搜索算法优化支持向量机多特征分类预测_matlab实现卷积神经网络特征融合
- 2PDF文件转换为图片
- 3博客杂谈---开源软件的影响力
- 4centos networkmanager 和 network配置冲突
- 5接入OnlyOffice,支持在线协同编辑Office文档,可私有化部署的企业知识库 zyplayer-doc 2.2.1 发布
- 6详解Xss 及SpringBoot 防范Xss攻击(附全部代码)_springboot xss攻击
- 7【咕咕送书 | 第七期】世界顶级名校计算机专业,都在用哪些书当教材?
- 8抖音知识付费必修课程,学浪入驻及运营全透析教学(2023版)_学浪 知识付费
- 9python解释语言_error: positional-only parameters are only support
- 10【Spring原理高级进阶】有Redis为啥不用?深入剖析 Spring Cache:缓存的工作原理、缓存注解的使用方法与最佳实践
都在卷大模型底座,云计算一哥决定给底座造底座
赞
踩
明敏 丰色 发自 凹非寺
量子位 | 公众号 QbitAI
由AIGC趋势掀起的新一轮AI竞赛,已经到了白热化阶段。
就在人人争相发大模型“秀肌肉”时,也有人不按套路出牌。
在亚马逊云科技的最新发布上,虽然也首发了自研基础大模型Titan,不过仔细琢磨就发现,这是“醉翁之意不在酒”,真正的主角是一个名叫Bedrock的AI平台。
在这里可以直接通过API调用多个热门生成式AI大模型,包括Stable Diffusion、Claude等。
有声音评价说,这一波操作是把生成式AI上云了,并且为自家大模型“打开格局”。

这既让人意外,但也不意外。
毕竟是全球云计算行业的“头号玩家”,一定会在AIGC这波趋势中留下名字。
但从实际动向来看,不是盲从趋势,而是基于自身定位和特长,找到适合的身位。
由此不禁好奇,亚马逊云科技究竟如何靠Bedrock杀入AIGC战局?这背后有哪些趋势?AIGC产业如今发展地到底怎样了?
亚马逊云科技的AIGC打开方式
想要理解巨头最新发布背后的动因,还要先了解下发布的核心内容。
简单理解,Bedrock就是一个集成了多种生成式AI模型的平台。
在这里可以通过API访问的方式,快速调用业内领先的大模型。如Stability AI、Anthropic、AI21 Labs和亚马逊云科技自家的大模型。
即Stable Diffusion、Claude等,都是大家耳熟能详的生成式AI了。
除了这些“熟面孔”外,亚马逊云科技首次推出了自研大语言模型Titan:
据介绍,目前Titan包括了两个全新的大语言模型:
Titan text:专注于生成式NLP任务,比如写总结、创作博客、文字分类、对话和信息提取等;
Titan Embeddings:用于搜索和个性化等,可将文本输入翻译成包含语义的嵌入编码能够让搜索结果更相关和符合上下文语境,目前自家产品搜索中已经用上了类似模型。
这些模型都会在Bedrock上托管,可以按需调用或进行定制,无需管理任何基础设施。
举例来说,用户可以将基础模型与Amazon SageMaker机器学习功能集成,使用Experiments测试不同模型和使用Pipelines大规模管理基础模型等。
其中定制化是Bedrock比较重要的一个功能,它支持少样本定制和微调大模型,最少仅需20个示例即可。
而且亚马逊云科技强调,在训练底层模型的过程中不会使用任何用户数据。并对所有数据都进行加密,不会离开用户的虚拟私有网络(VPC)。
平台层向下,就是硬件基础设施。
作为云厂商,自然洞察到了这波最新AI趋势下,对算力的巨大需求。
由此亚马逊云科技也一并宣布了两款自研芯片实例正式可用,一款针对训练,一款针对推理。
首先是基于训练芯片Trainium的Amazon EC2 Trn1n。
与其他同类实例相比,此前的Trn1节省的训练成本已达50%。而通过在超大规模集群(UltraClusters)中进行部署,还可以实现超过6 exaflops的计算能力,数据传输规模达到PB级。
这让内部搜索团队等用户训练大模型的时间从从几个月缩短到了几周甚至几天。
专为网络密集型大模型设计的Trn1n实例,直接可提供高达1600Gbps的网络带宽,总体性能比Trn1还要高出20%。
其次是用于推理的Amazon EC2 Inf2实例。
亚马逊云科技认为,随着基础模型进入大规模部署的阶段,主要成本将转移到模型微调和推理。
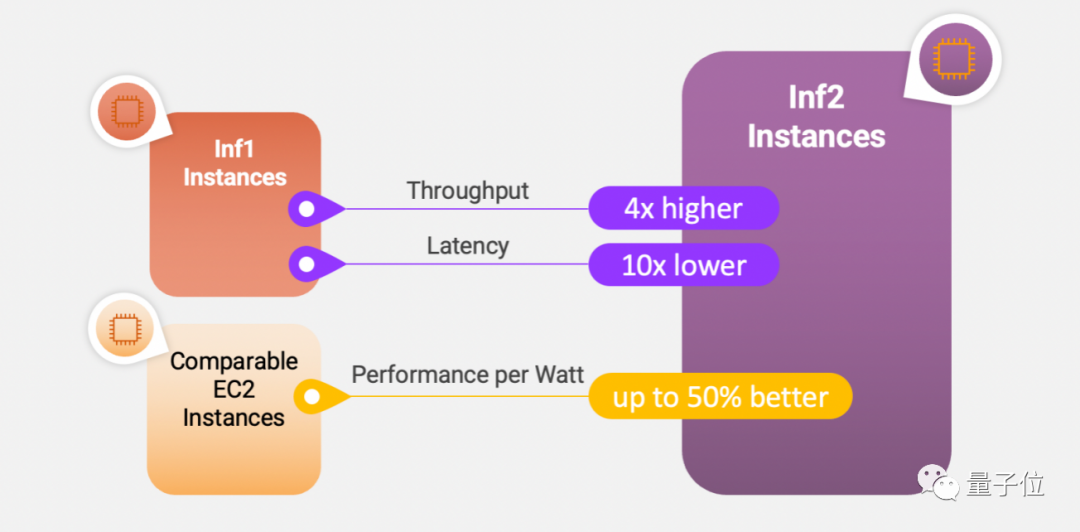
Inf2实例由自研的推理专用芯片Inferentia2提供支持,后者在亚马逊云科技去年的开发者大会上首次亮相(Inferentia一代则问世于2018年)。
它专门针对千亿参数的生成式大模型进行了优化:
与上一代相比,吞吐量提高了4倍,延迟降低了10倍,并可支持大规模分布式推理;与同类实例相比,每瓦性能比提高了50%。
除此之外,亚马逊云科技还为普通开发者推出了完全免费的辅助代码编写工具CodeWhisperer。
无论是面向行业用户、还是C端用户,亚马逊云科技似乎都在想办法让最新的AI趋势离大家更近一点。
实际上,这也是目前很多AI大厂、科技巨头正在推进的事,只不过各家的方法不尽相同。
那么,为什么需要搭建Bedrock这样的AI平台?它们会给行业带来哪些影响?
为什么需要大模型底座?
由表及里,大概有两层原因驱动。
首先是直接原因,行业需求。
生成式AI将会形成一个新市场,如今已是行业公认的趋势。
据Grand View Research估计,到2030年,生成式AI的市场规模可能接近1100亿美元。
这意味着在未来一段时间内,全球将会有大量的行业和企业,寻求将生成式AI接入到自家业务中。并且速度要快,否则一不小心就会被弯道超车。
比如亚马逊云科技就提到过,过去一段时间里他们的客户来问得最多的问题便是:
我怎么能快速上车将它们用到自己的业务中,但又不用耗费太多精力和money?
毕竟对于绝大部分企业来说,炼出一个自家大模型并不划算,背后要投入的人力、物力、时间,都太多了;更何况开发难度也很高。
实际上,很多厂商已经提供了API接口供行业用户直接调用,但这种方法还是要求用户自己管理基础设施;如果想要构建深入场景的定制化模型,也还是需要自己做开发,整个流程不够高效便捷。
由此云服务就被推到了台前。

这种基于互联网给企业提供基础架构、平台或软件的服务,本身在灵活性、易用性和能力上都得到了行业验证,尤其大模型本身对云计算就有着天然的依赖性。
在生成式AI席卷而来时,不少声音认为这也会为整个云计算行业带来根本性的改变,云计算的主流商业模式会从传统的IaaS变成MaaS。
而近期,越来越多AIGC玩家也在顺势推出自己云服务,兜售大模型能力。
那么亚马逊云科技的动作,则是给出了一种新范式,将多种大模型囊括在一起,放在一个大平台底座上,让用户的可选择性提升,同时发挥他们云厂商本身的优势,让用户的调用和定制化过程门槛更低、效率更高,并在安全性做出保障。
更深层次的原因在于,给大模型加底座,能够更进一步降本增效,这本身就符合市场和行业的发展要求。
参考数字化转型浪潮的演进过程,从最初的无纸化,到云计算的使用,本质上都是降本增效的过程,让企业可以在生产制造、推进业务的过程中更高效利用资源,降低生产运营成本。
最新一轮的生成式AI浪潮,亦会如此。
只是这一轮的主角不再是计算机、云计算,而是AI大模型。
未来一段时间内,Bedrock这类AI平台或许还会出现新玩家,并进一步形成一个赛道、成为AIGC产业中的一层结构。

亚马逊云科技的做法,正是给大家示范了一下,科技巨头在面对最新趋势时,如何结合自身优势找到合适身位。
而除了大模型底座,在近期或许还会衍生出一大批“新兴物种”。比如当下软件应用在争先恐后接入Chatbot,就有企业推出相应服务帮软件应用接入大模型能力。
可见在当下这个时刻,怎么把握机遇非常关键。
该怎么做?
AIGC玩家种类丰富,不一定都要“卷”大模型本身
前面提到,到2030年,全球生成式AI市场规模可能接近1100亿美元这一巨大数字。
此等规模下,自然会涌现种类空前丰富的玩家。
根据量子位智库3月发布的《AIGC产业全景报告》,无论玩家属于初创公司还是互联网巨头、专门的AI厂商/科研机构还是生态链场景公司,我们都可按基础设施层、模型层和应用层将它们分为三大类。
具体而言,基础设施层主要包含为行业提供数据、算力、计算平台、模型开发训练平台以及其他配套设施的企业。

其中,比如光数据这一环就分为数据提供商和数据服务商,光数据提供商就包括提供通用数据、垂直数据、特定业务下的标注数据、符合法规的审核数据等等。
对于算力平台来说,智算中心这类算力集群、云服务商和硬件领域的芯片商也都是不可或缺的角色。
模型层则主要分为专供底层通用大模型和中间层模型这两类。
前者由于建设和提升迫切性最强,目前最受关注,吸引了一大批“火力”。
不过,它也相对最容易形成壁垒,因为人才、时间、数据和资金等多个方面都会形成制约。
值得注意的是,如Hugging Face、魔搭ModelScope这样的模型站玩家,也可以归于这一类。
至于中间层模型,则主打垂直化、行业化和细分化,可分为:
(1)中间集成商,主要组合多个接口,形成新的大模型;
(2)行业大模型商,由底层模型持有者进行端到端提供;
(3)以及二次开发商,主要增加行业特色数据和行业认知。
这类玩家比较适合具有特定行业积累以及技术积累的企业快速进入。
最后,应用层。如果按照底层逻辑来看,可以分为生产可直接消费内容、结合底层系统生产含有附加价值内容、提供内容生产辅助工具、用于提供打包内容或解决方案这四类。
如果基于模态分,则包括文本生成、图像生成、音频/视频/跨模态、策略生成等等,其中文本生成又包括应用型、创作型、交互型和辅助生成。

这是创业最为友好的一层,当然,关键卡口还是模型层玩家。
具体分类暂且不表。
重点是,从以上这些内容我们可以看到,整个AIGC市场的玩家方向确实多如牛毛,而由于行业整体还处于培育摸索期,不管哪个位置都还远谈不上饱和,可谓机会多多。
那么,如何找到合适的位置就成了关键。
如亚马逊云科技,作为一家云厂商,偏就盯准应用层,提供打包内容或解决方案,做上了各类大模型的接入和改造平台。
这也传递了一个声音,行业巨头不一定非要都往大模型方向“卷”,根据市场需求和自身实力出发,即使入局较慢几步,也能get恰到好处的落脚点。
据可靠消息:5月25日将举办亚马逊云科技大模型及生成式AI发布深度解读大会,敬请期待。
戳下方链接或点击文末“阅读原文”,可进行大会报名~
https://www.awsevents.cn/innovate/ai2023/registerSignUp.aspx?s=8440&smid=17578

