
- 1printThis.js的使用
- 2数学建模智能优化算法之神经网络案例附Matlab代码_sim 是 matlab neural network toolbox 中的函数,用于执行神经网络的
- 3Idea + SpringBoot + Mybaits + Oracle 环境搭建案例_idea springboot 项目连接oracle数据库的简单实例
- 4杭电2019多校第二场 HDU-6602 Longest Subarray(线段树+lazy标记)_hdu 6602 longest subarray
- 5antd datepicker 添加默认值_datepicker default-value
- 6LeetCode刷题笔记-简单-两整数之和(不许用+/-)_两数之和leetcode 不用
- 7使用pytest单元测试框架执行单元测试
- 8Qt打包生成可执行程序_qt打包成可执行程序
- 9ubuntu20.04设置docker容器开机自启动
- 10视频质量评价python,包括psnr,ssim,LPIPS_lpips视频质量评估
LinkedIn:如何利用大数据算法定位网站性能瓶颈(BOSS)
赞
踩
导读:架构师非常关注性能问题,上篇文章中我们介绍了京东的自动化压测体系 ForceBot,这篇文章来自 LinkedIn 的技术博客,介绍如何通过大数据算法来分析调用数据,自动定位性能瓶颈。本文由高可用架构翻译。

背景
我们是 LinkedIn 的核心性能团队,使命是使 LinkedIn 页面加载更快,我们帮助每个工程团队尝试通过各种优化努力达到页面加载时间目标。
在尝试减少页面加载时间时,我们需要回答的一个常见问题是:性能瓶颈在哪里? 换句话说,工程师应该在哪里集中精力? 通常,为了回答这个问题,性能工程师将研究性能指标,并检查由资源耗时API[1]和调用图[2]捕获的一些样本,并找到调用的热点。 这种方法可能非常有用,但有“尝试和错误”的缺点。
此外,许多示例瀑布数据需要手动点击和分析以找到瓶颈。 我们需要一种系统的方法,即通过工具来分析现有的大量数据,并快速自动定位瓶颈细节。
在本文中,我们将介绍 BOSS (BOttlenecks for Site Speed),这是我们在 LinkedIn 上建立的系统,它分析了数百万瀑布调用样本,并自动识别瓶颈以提高性能。
为什么瓶颈分析很难?
人工来定位瓶颈存在一系列问题
需要处理多个性能数据源:用户请求由多个系统来提供,因此各自有自己的性能数据。我们使用导航定时[3] , 资源计时API[1] ,来自本地应用程序(iOS,Android)的测量和服务器端跟踪数据(如调用图[2] )进行浏览器端测量。 每个数据源的格式各不相同,这使得难以在一个位置处理所有数据源。
需要处理海量的性能数据:分析100%的流量以找出最重要的瓶颈是非常重要的。 通常,为了找到页面的瓶颈,性能工程师可以查看一些示例,并识别一些热点,但不是全部。 这意味着,很容易错过真正的瓶颈,并可能关注错误的项目。 我们想分析所有的数据,以确保每个LinkedIn成员都对我们的网站速度感到满意。 因此,我们需要确保系统每天可以处理100M +记录。
量化并行调用:找到瓶颈并不是在瀑布中找出最长的请求就解决问题了,因为如果有其他并行调用,只是优化最长的请求链路并不能减少页面加载时间。 我们需要一个考虑所有调用消耗时间以及一个并行化的模型。
解释性能指标:在性能数据中有很多领域特定的术语,例如DNS连接时间,重定向时间,客户端渲染时间等。开发人员不容易理解为什么页面很慢。 我们希望在结果中提供指导改进操作的项目,而不是显示原始指标。 比如需要修复前端服务器的高响应时间,删除网页中的 HTTP 重定向,将第三方请求与其他调用并行等。
在下面的文字中,我们将解释我们如何通过 BOSS 解决这些挑战。
建立调用树模型以统一性能数据源
自动化分析的最艰难的部分是将各种数据源放在一起。 我们在客户端和服务器端都有性能跟踪数据。 这些数据集分开放置且格式各不相同。 为了解决这个问题,我们构建了一个通用的调用树模型来将数据粘合在一起。
最终用户的一次点击将导致对多个系统的多个请求。 如下图所示,一个典型的页面视图包含对数据中心的 API 请求,image / JS / CSS 请求到 CDN,以及一些向第三方(如广告)的请求。 这些请求分布到多个系统,我们需要一种方法在一个地方跟踪它们。
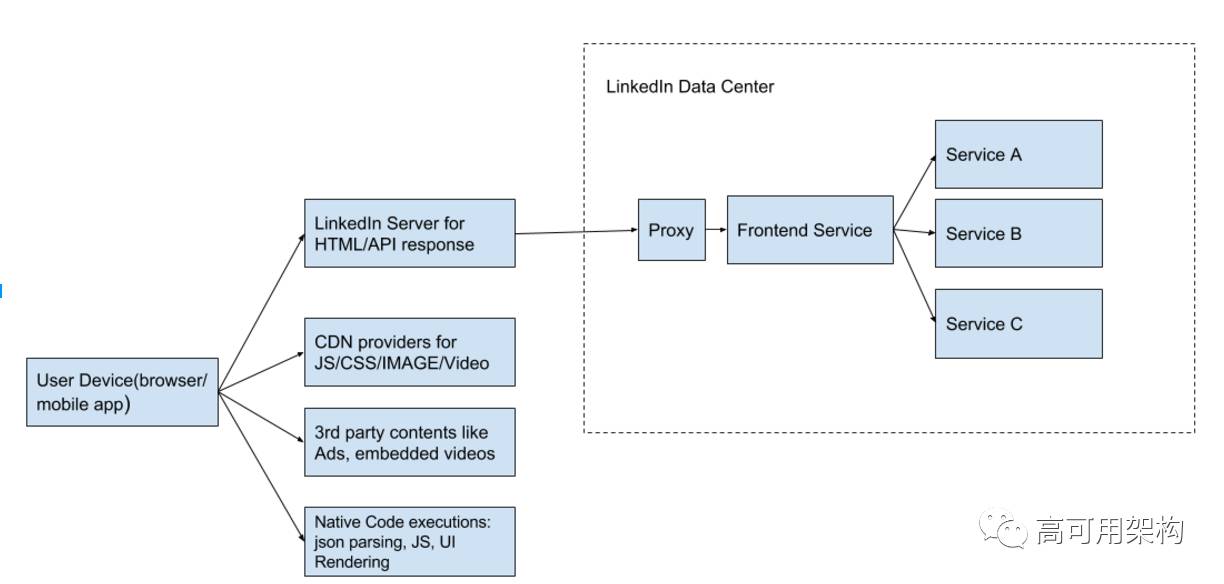
(点击图片可以缩放)
图长得什么样子? 对,一颗树!
在 LinkedIn 上,我们已经在不同的服务之间构建了调用树,这些服务位于数据中心内部。 如果我们将这个概念应用于其他系统,如CDN,第三方广告,浏览器等,我们会得到一个更大的调用树。
简化客户端调用瀑布图
我们使用 Resource Timing 数据来构建客户端调用树模型。 然而,原始瀑布包含许多页面级导航定时指标,例如重定向持续时间,第一字节时间,页面下载时间等,以及与页面 HTTP 调用相关联的所有下载的一百多个资源定时条目具有不同的 URL 和资源类型。这使得很难确定慢度的原因。 瓶颈需要采取行动。 例如,如果个人资料图片通常下载缓慢,则意味着我们的媒体 CDN 需要调查,而不是每个人的个人资料图片。
为了解决这个问题,我们想出了分配给瀑布中每个资源/度量的瓶颈类型,以便获得可操作的瓶颈分析。
| 瓶颈类型 | 资源时序/导航时序数据源 |
| 服务器端 | 到第一个字节的时间和请求到linkedin.com域的内容下载时间 |
| CDN | 请求我们的CDN域 |
| 在客户端上的长本地代码执行时间(JS /解析,渲染) | 使用用户时间数据在瀑布和自定义标记中产生间隙 |
| 第三方内容 | 请求不是由LinkedIn所有的域提供 |
| 重定向 | 重定向时间和导航定时数据的计数 |
注意,我们看到了瀑布中没有网络活动发生的很多时间差距。 在本地调试之后,我们发现在这些空白期间有很多沉重的本地代码执行(js /解析/渲染)。 为了更准确地衡量这一点,我们开始使用用户计时 API 来测量关键的渲染路径,以便我们获得更多的洞察力。
调用树分析
一旦我们拥有“组合树”,下一个挑战是如何分析这些树以找到每个页面的性能瓶颈。 基本上,有两种调用会损害性能:
慢速调用
顺序/阻塞调用
开发人员对单个请求的延迟非常敏感,但有时忽略调用并行化的重要性。 让我们使用两个假设的网页浏览作为示例。 第一个使用 HTML 请求来并行化 CSS 和 JS 调用,但第二个不会。 所有调用的延迟是相同的,但页面加载时间有 1,100ms 差异! 这里的瓶颈是 HTML 请求阻塞了 CSS 和 JS 请求。

BOSS 认为慢请求和阻塞调用都会造成影响。 在上面的示例中,我们的瓶颈分析将给出并行调用 HTML 38.9% 的影响和非并行页面视图的 72.2%。 即使每次调用的持续时间是相同的,阻塞 HTML 调用在我们的分析中获得更多的惩罚,并被标记为页面的瓶颈。
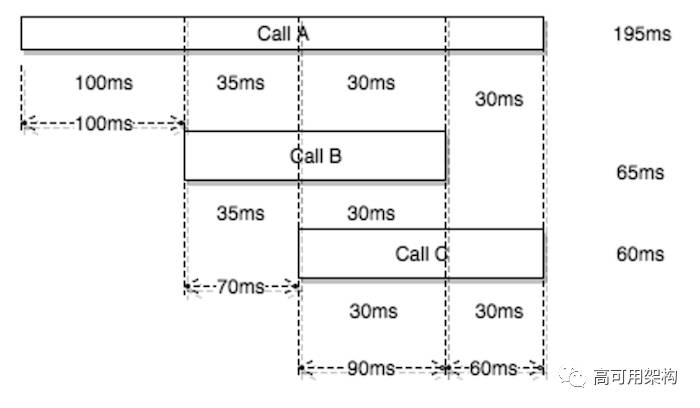
要理解计算瓶颈贡献的算法,让我们使用简化版本的页面视图调用树。基于每个调用的开始和结束持续时间将时间线划分为不同的段。 对于每个时间段,如果有多个并行发生的调用,我们将均匀地为每个调用贡献此段。
在下面的示例中,90ms 段被分成 3 个部分,并且每个服务被分配 30ms 贡献。 对于调用 A 的 100ms 段,没有并行的其他调用,并且它对于整个时间段负责,这将导致对调用 A 有非常高的贡献值。具有高贡献的调用将是最大的瓶颈。 因此,调用 A 获得 195ms,这是总页面加载时间 320ms 的 60.9%,由于第一个 100ms 阻塞段加上其长持续时间。 调用 B 获得 20.3%,调用 C 获得 18.8%,因为它们彼此并行。
分析大规模的性能瓶颈
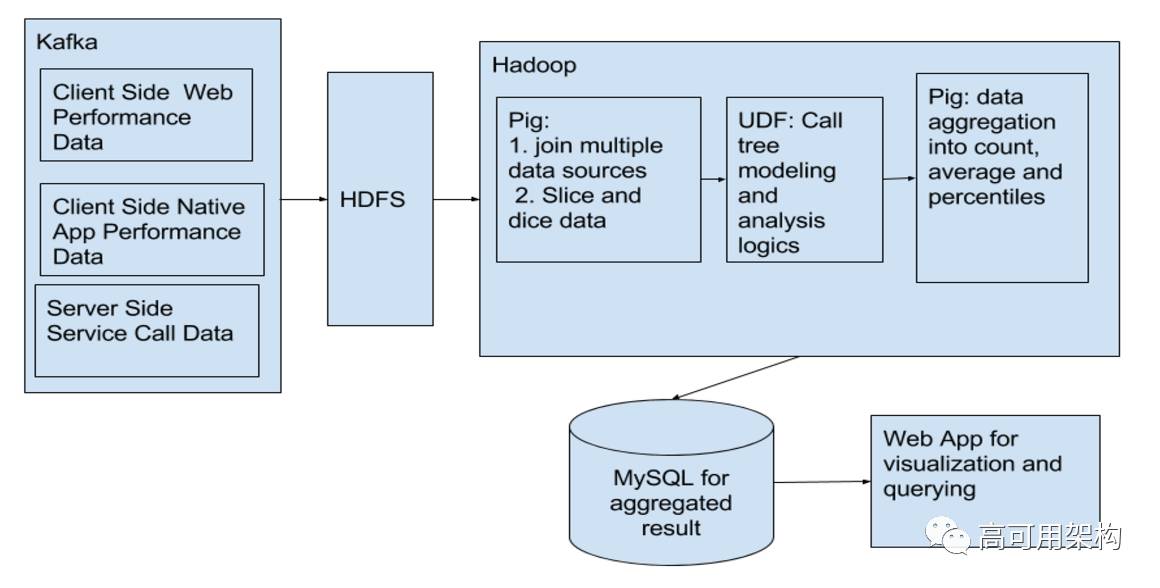
处理调用树数据是非平凡的。 我们获得了数百万的页面访问记录,每个记录创建了一个带有数百个节点的调用树。 这里是我们的数据处理系统的要求和我们选择的解决方案:
可扩展到海量数据:我们选择了 Kafka + Hadoop 解决方案来处理数据,这在 LinkedIn 上证明是非常成功的 。
能够将数据分割和切分为不同维度和聚合指标:最慢的 10% 成员的瓶颈是什么?使用 4G 网络的成员的瓶颈是什么? 每周只访问我们网站的会员的瓶颈是什么? 我们选择 Apache Pig 作为在Hadoop 中执行这些任务的首选语言。
调用树分析算法的快速迭代:处理调用树的逻辑是复杂的,需要在多次迭代中调整。 每次来修改 Pig 处理逻辑并在 Hadoop 上测试是不切实际的。 为了解决这个问题,我们使用以 Java / Python 编写的UDF (用户定义的函数)来处理调用树分析逻辑,并为快速迭代编写单元测试。
使用可扩展的数据分析系统,下一个挑战是构建一个算法来分析调用树。
可视化瓶颈分析:聚合所有信息
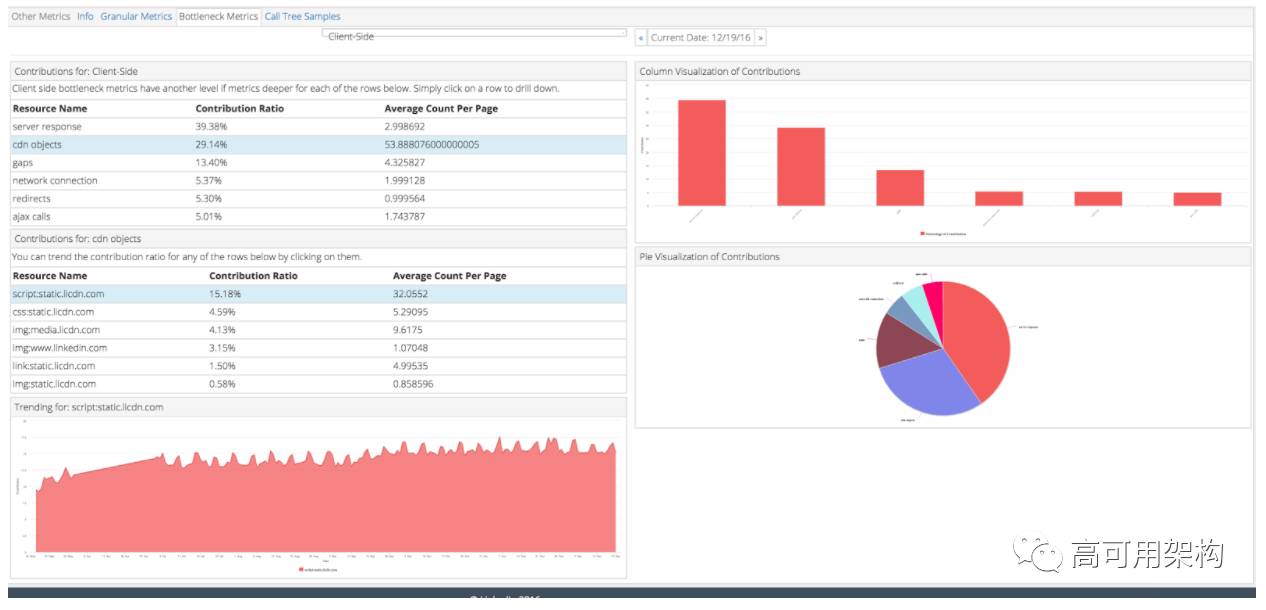
在 UI 方面,我们构建了以下组件来协助分析:
条形图和饼图突出显示顶级瓶颈;
堆叠趋势图显示瓶颈随时间的变化;
便于分类和查找的表。
(点击图片可以缩放)
在同一个UI上,用户还可以在散点图中查看页面查看的延迟分布,并单击每个点以获取页面的完整瀑布。
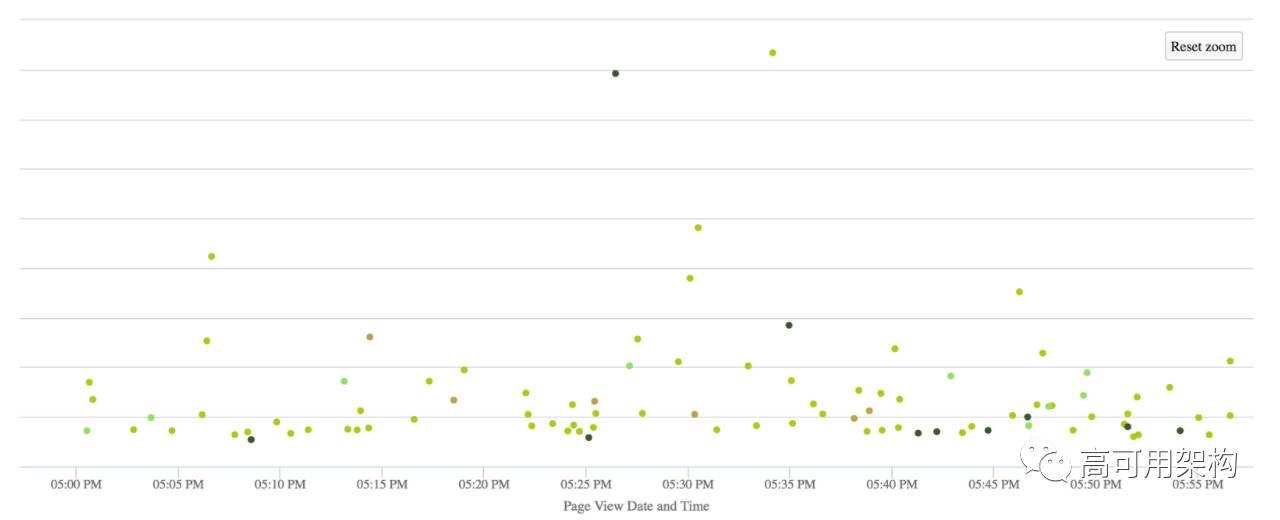
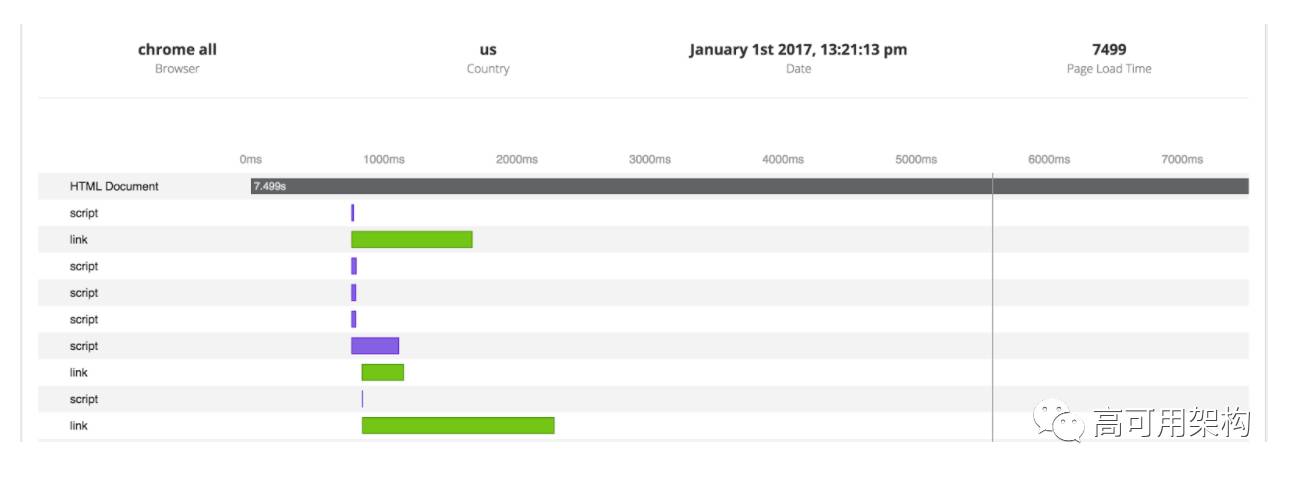
(点击图片可以缩放)
有了这个强大的工具,用户可以轻松点击几下找到瓶颈。
现实世界的例子
这里是我们在 2016 年 3 月为 LinkedIn 桌面主页运行的瓶颈分析。每种类型的瓶颈都有贡献率,这意味着“通过消除这个瓶颈,我们可以提高多少网站速度”。这里列出了顶尖的瓶颈和解决方案。
| 瓶颈类型 | 贡献率(%) | 怎么修 |
| 服务器响应 | 27.32% | 服务器端瓶颈主要来自于较慢的服务 |
| 没有网络活动的间隙 | 22.16% | 这个瓶颈指示一些JS执行或浏览器解析和呈现阻止其他网络请求 |
| CDN对象 | 20.16% | 这个瓶颈指示较慢的CDN供应商或大图像/ JS / CSS大小 |
| AJAX调用 | 9.21% | 这可以通过合并AJAX调用与HTML响应或延迟到页面加载后修复 |
| 广告调用 | 7.57% | 广告调用不应阻止后续调用 |
| 重定向 | 4.50% | 应避免不必要的重定向; 他们总是阻止后续请求 |
| 网络连接 | 3.65% | 这表示缓慢的TCP握手连接,这可能是来自本地ISP提供商或我们的代理服务器的问题 |
找到瓶颈之后,下一步是找到导致瓶颈的特定请求/代码。 我们检查了几个瀑布,发现下载广告后经常发生长时间间隙。 这表示在下载广告后有大量的 JavaScript 执行,下一个请求正在等待 JavaScript 完成执行。

修复很容易:我们只是使广告加载使用非阻塞的方式,使图像和其他东西可以同时加载。 运行 A / B 测试后,我们的主页在页面加载时间上的速度提高了 21%。 与此同时,我们发现用户互动率指标有所提升;在推迟广告之后,用户更多地在网站进行互动。
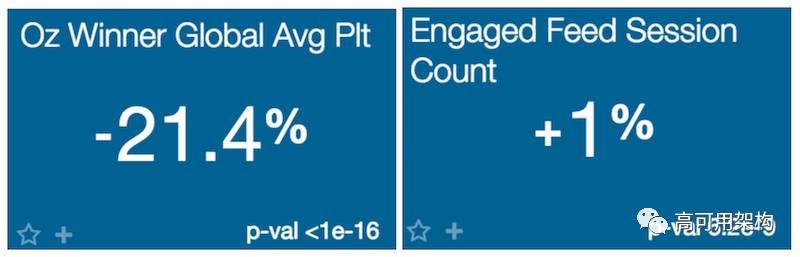
在我们的瓶颈分析数据中,广告调用的停顿时间显著下降。
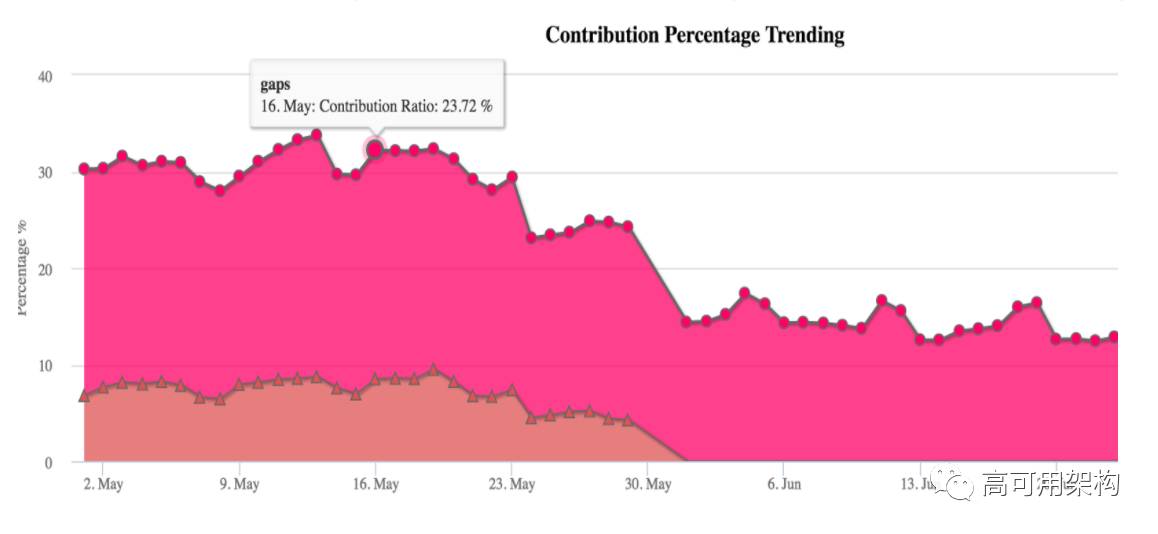
结论
我们构建了一个瓶颈分析工具 BOSS,可以大规模处理数据并生成可指导操作的优化建议。我们已经有几个成功案例,也计划进行其他改进,包括:
更侧重于服务器端分析。 到目前为止,BOSS 在客户端的分析工作完成得很好,我们想在服务器端做同样的事情。 例如,针对不同 API 端的瓶颈分析,跨不同数据中心的服务调用等。
自动建议性能优化。 目前,该工具以被动模式使用:仅当用户访问我们的工具并想要进行一些优化时才进行分析。 相反,我们希望为每个网页自动运行分析,并向网页所有者直接发送优化建议。 这样,我们可以轻松地提高性能问题,并尽早改进。
致谢
感谢David He和Ritesh Maheshwari的宝贵意见和反馈。 感谢Toon Sripatanaskul他的真棒服务贡献算法。 感谢Swapnil Ghike和Joseph Zemek为这个项目做出的开拓性努力。 并感谢Oliver Tse为我们的热心用户和他的宝贵反馈。 最后,感谢Steven Pham和Dylan Harris在开发BOSS UI方面的帮助。
参考资源
https://www.w3.org/TR/resource-timing/
https://engineering.linkedin.com/distributed-service-call-graph/real-time-distributed-tracing-website-performance-and-efficiency
https://www.w3.org/TR/navigation-timing/
本文英文原文:https://engineering.linkedin.com/blog/2017/01/boss--automatically-identifying-performance-bottlenecks-through-
推荐阅读
本文由高可用架构翻译,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号

