
- 1免费GPU线上跑AI项目实践(Stable Diffusion)_stable diffusion免费算力
- 2转发 3GPP解读5G第一阶段里程碑:系统架构_3gpp stage介绍
- 3数据库:关系运算整理大全(包括关系代数、元组关系演算、域关系演算)_数据库关系运算
- 4一、android hidl完整样例实现_hidl 接口 例子
- 5HarmonyOS Connect FAQ第三期_鸿蒙开发获取deviceid
- 6Android Studio启动AVD报错:The emulator process for AVD Pixel_5_API_30 has terminated.最有效的解决方法
- 7Paper之CVPR&ICCV&ECCV:2009年~2019年CVPR&ICCV&ECCV(国际计算机视觉与模式识别会议&国际计算机视觉大会&欧洲计算机视觉会议)历年最佳论文简介及其解读_2009年cvpr举办时间
- 8javascript UTF-8的编码与解码
- 9百度编辑器Ueditor插入表格没有边框、颜色的解决方法_百度编辑器表格插入表格
- 10机器学习ML笔记_deoldify测试集
微服务分布式中为什么要分库分表呢?
赞
踩
什么是分库分表?
概念:
分库分表是一种数据库水平扩展的方法,通过将数据分散存储在多个数据库实例或多张表中,以提高系统的性能和扩展性。在Java应用中,可以使用一些数据库中间件或框架来实现分库分表。
为什么要分库分表呢?
- 提高性能:随着业务数据量的增长,单一数据库可能会面临存储容量、读写性能等方面的瓶颈。通过分库分表,可以将数据分散存储在多个数据库实例或表中,有效减轻单一数据库的压力,提高系统的读写性能。此外,可以利用多个数据库实例或表的资源并行处理请求,进一步提升系统性能。
- 提高并发能力:通过分库分表,可以将数据分散存储在多个数据库实例中,不同数据库之间的操作互不影响,可以提高系统的并发处理能力。同时,可以利用数据库集群技术实现负载均衡,有效分摊请求压力,提高系统的并发处理能力。
- 扩展数据存储容量:随着业务的扩展,单一数据库的存储容量可能会不足。通过分库分表,可以将数据分散存储在多个数据库实例或表中,有效扩展数据存储容量,满足业务发展的需求。
- 提高系统可用性:通过分库分表,可以实现数据库的水平扩展,即使某个数据库实例或表出现故障,其他数据库实例或表仍然可以继续提供服务,保障系统的可用性。
举一个简单的例子来说明分库分表的概念: 假设有一个电商系统,用户订单数据量非常大,单个数据库已经无法满足存储和查询性能需求。这时候可以考虑使用分库分表来优化。
- 水平分库:将订单数据按照用户ID取模的方式分散存储到多个数据库实例中。例如,用户ID为1的订单存储在数据库A,用户ID为2的订单存储在数据库B,以此类推。这样可以减轻单个数据库的压力,提高并发读写性能。
- 水平分表:在每个数据库实例中,可以再根据某个规则(例如按时间范围)将订单数据分散存储到多张表中。例如,按照订单创建时间,将近期订单存储在表order_recent中,历史订单存储在表order_history中。这样可以减少单表数据量,提高查询性能。
在Java应用中,可以通过配置数据库中间件或框架来实现自动的分库分表路由和管理。开发人员只需按照规则设计数据库表结构和SQL查询,数据库中间件会根据配置自动将数据路由到对应的数据库实例或表中。
总的来说,分库分表是一种有效的数据库水平扩展方案,可以帮助应对大数据量和高并发的业务场景,在Java应用中使用数据库中间件可以简化分库分表的操作,提高系统性能和可扩展性
如何实现分库分表呢?
分库分表的核心理念就是对数据进行切分(Sharding),以及切分后如何对数据的快速定位与查询结果整合。而分库与分表都可以从:垂直(纵向)和 水平(横向)两种纬度进行切分。
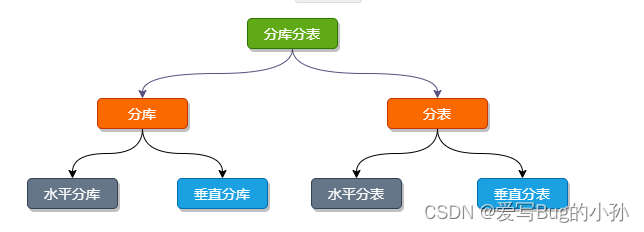
下边我们就以订单相关的业务举例,看看如何做库、表的 垂直 和 水平 切分。
垂直切分
垂直切分有垂直 分库 和 垂直分表。
1、垂直分库
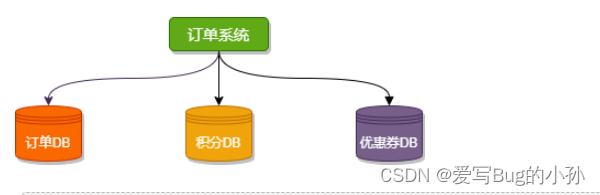
垂直分库相对来说是比较好理解的,核心理念就四个字:专库专用。
按业务类型对表进行分类,像订单、支付、优惠券、积分等相应的表放在对应的数据库中。开发者不可以跨库直连别的业务数据库,想要其他业务数据,对应业务方可以提供 API 接口,这就是微服务的初始形态。
垂直分库很大程度上取决于业务的划分,但有时候业务间的划分并不是那么清晰,比如:订单数据的拆分要考虑到与其他业务间的关联关系,并不是说直接把订单相关的表放在一个库里这么简单。
在一定程度上,垂直分库似乎提升了一些数据库性能,可实际上并没有解决由于单表数据量过大导致的性能问题,所以就需要配合水平切分方式来解决。
2、垂直分表
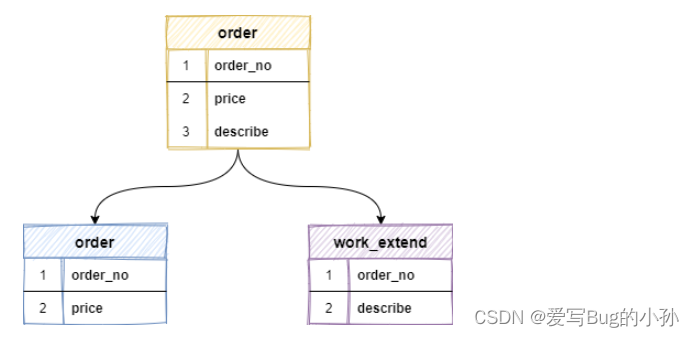
垂直分表是基于数据表的列(字段)为依据切分的,是一种大表拆小表的模式。
例如:一张 order 订单表,将订单金额、订单编号等访问频繁的字段,单独拆成一张表,把 blob 类型这样的大字段或访问不频繁的字段,拆分出来创建一个单独的扩展表 work_extend ,这样每张表只存储原表的一部分字段,再将拆分出来的表分散到不同的库中。
我们知道数据库是以行为单位将数据加载到内存中,这样拆分以后核心表大多是访问频率较高的字段,而且字段长度也都较短,因而可以加载更多数据到内存中,来增加查询的命中率,减少磁盘IO,以此来提升数据库性能。
垂直切分的优点:
- 业务间数据解耦,不同业务的数据进行独立的维护、监控、扩展。
- 在高并发场景下,一定程度上缓解了数据库的压力。
垂直切分的缺点:
- 提升了开发的复杂度,由于业务的隔离性,很多表无法直接访问,必须通过接口方式聚合数据。
- 分布式事务管理难度增加。
- 数据库还是存在单表数据量过大的问题,并未根本上解决,需要配合水平切分。
水平切分
前边说了垂直切分还是会存在单库、表数据量过大的问题,当我们的应用已经无法在细粒度的垂直切分时,
依旧存在单库读写、存储性能瓶颈,这时就要配合水平切分一起了,水平切分能大幅提升数据库性能。
1、水平分库
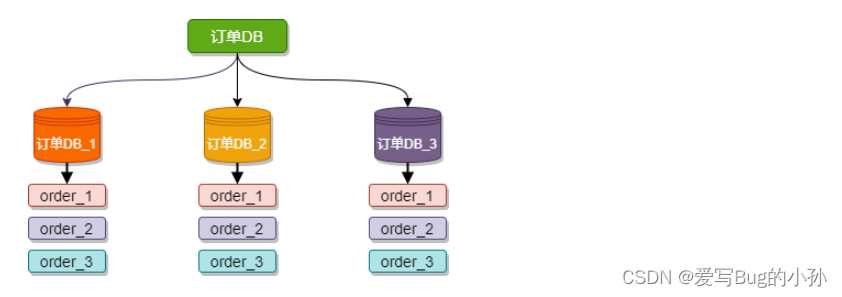
水平分库是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,以此实现水平扩展,是一种常见的提升数据库性能的方式。
这种方案往往能解决单库存储量及性能瓶颈问题,但由于同一个表被分配在不同的数据库中,数据的访问需要额外的路由工作,因此系统的复杂度也被提升了。
例如下图,订单DB_1、订单DB_1、订单DB_3 三个数据库内有完全相同的表 order,我们在访问某一笔订单时可以通过对订单的订单编号取模的方式 订单编号 mod 3 (数据库实例数) ,指定该订单应该在哪个数据库中操作。

2、水平分表
水平分表是在同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。
例如:一张 order 订单表有 900万数据,经过水平拆分出来三个表,order_1、order_2、order_3,每张表存有数据 300万,以此类推。

水平分表尽管拆分了表,但子表都还是在同一个数据库实例中,只是解决了单一表数据量过大的问题,并没有将拆分后的表分散到不同的机器上,还在竞争同一个物理机的CPU、内存、网络IO等。要想进一步提升性能,就需要将拆分后的表分散到不同的数据库中,达到分布式的效果。
水平切分的优点:
- 解决高并发时单库数据量过大的问题,提升系统稳定性和负载能力。
- 业务系统改造的工作量不是很大。
水平切分的缺点:
- 跨分片的事务一致性难以保证。
- 跨库的join关联查询性能较差。
- 扩容的难度和维护量较大,(拆分成几千张子表想想都恐怖)。
一定规则是什么
我们上边提到过很多次 一定规则 ,这个规则其实是一种路由算法,就是决定一条数据具体应该存在哪个数据库的哪张表里。
常见的有 取模算法 和 范围限定算法
1、取模算法
按字段取模(对hash结果取余数 (hash() mod N),N为数据库实例数或子表数量)是最为常见的一种切分方式。
还拿 order 订单表举例,先对数据库从 0 到 N-1进行编号,对 order 订单表中 work_no 订单编号字段进行取模,得到余数 i,i=0存第一个库,i=1存第二个库,i=2存第三个库…以此类推。
这样同一笔订单的数据都会存在同一个库、表里,查询时用相同的规则,用 work_no 订单编号作为查询条件,就能快速的定位到数据。
优点:
数据分片相对比较均匀,不易出现请求都打到一个库上的情况。
缺点:
这种算法存在一些问题,当某一台机器宕机,本应该落在该数据库的请求就无法得到正确的处理,这时宕掉的实例会被踢出集群,此时算法变成hash(userId) mod N-1,用户信息可能就不再在同一个库中了。
2、范围限定算法
按照 时间区间 或 ID区间 来切分,比如:我们切分的是用户表,可以定义每个库的 User 表里只存10000条数据,第一个库只存 userId 从1 ~ 9999的数据,第二个库存 userId 为10000 ~ 20000,第三个库存 userId 为 20001~ 30000…以此类推,按时间范围也是同理。
优点:
- 单表数据量是可控的
- 水平扩展简单只需增加节点即可,无需对其他分片的数据进行迁移
- 能快速定位要查询的数据在哪个库
缺点:
- 由于连续分片可能存在数据热点,比如按时间字段分片,可能某一段时间内订单骤增,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
分库分表的难点
1、分布式事务
由于表分布在不同库中,不可避免会带来跨库事务问题。一般可使用 "三阶段提交 "和 “两阶段提交” 处理,但是这种方式性能较差,代码开发量也比较大。通常做法是做到最终一致性的方案,如果不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,采用事务补偿的方式。
这里我应用阿里的分布式事务框架Seata 来做分布式事务的管理,后边会结合实际案例。
2、分页、排序、跨库联合查询
分页、排序、联合查询是开发中使用频率非常高的功能,但在分库分表后,这些看似普通的操作却是让人非常头疼的问题。将分散在不同库中表的数据查询出来,再将所有结果进行汇总整理后提供给用户。
3、分布式主键
分库分表后数据库的自增主键意义就不大了,因为我们不能依靠单个数据库实例上的自增主键来实现不同数据库之间的全局唯一主键,此时一个能够生成全局唯一ID的系统是非常必要的,那么这个全局唯一ID就叫 分布式ID。
4、读写分离
不难发现大部分主流的关系型数据库都提供了主从架构的高可用方案,而我们需要实现 读写分离 + 分库分表,读库与写库都要做分库分表处理,后边会有具体实战案例。
5、数据脱敏
数据脱敏,是指对某些敏感信息通过脱敏规则进行数据转换,从而实现敏感隐私数据的可靠保护,如身份证号、手机号、卡号、账号密码等个人信息,一般这些都需要进行做脱敏处理。
分库分表工具
我还是那句话,尽量不要自己造轮子,因为自己造的轮子可能不那么圆,业界已经有了很多比较成熟的分库分表中间件,我们根据自身的业务需求挑选,将更多的精力放在业务实现上。
- sharding-jdbc(当当)
- TSharding(蘑菇街)
- Atlas(奇虎360)
- Cobar(阿里巴巴)
- MyCAT(基于Cobar)
- Oceanus(58同城)
- Vitess(谷歌)

