
- 1ChatGLM本地部署(支持中英文,超级好用)!_chatgpt本地部署
- 2HarmonyOS鸿蒙基于Java开发: 基于Java UI实现的Java卡片开发指导_鸿蒙ets 实现java放射
- 3【JavaBigDecimal练习】利用BigDecimal精确计算欧拉数_用java求小数点后1000位
- 4Windows本地部署ChatGLM3-6B模型_chatglm3-6b 下载
- 5网络安全 kali 渗透学习 web 渗透入门 kali 系统的安装和使用_kaliweb渗透
- 6elementui中的el-input回显成功后input框不能进行编辑的问题_回显后的值el-input 无法输入
- 7深度学习交通标志识别项目
- 8初学vue,模仿个静态网站
- 9如何利用PS中的钢笔抠图
- 10【问题记录】关于vue-cli项目build后,index.html无法在浏览器打开_vue3本地build打开html接口调不通
机器学习算法_[优化算法系列]机器学习\深度学习中常用的优化算法
赞
踩
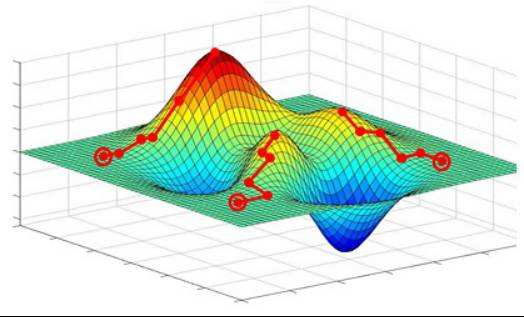
通俗易懂的讲解机器学习深度学习中一些常用的优化算法,梯度下降法、动量法momentum、Adagrad、RMSProp、Adadelta、Adam,介绍不同算法之间的关联和优缺点,后续会继续分享其他的算法,感兴趣的可以关注一下。
大多数机器学习问题最终都会涉及一个最优化问题,只是有的是基于最大化后验概率,例如贝叶斯算法,有的是最小化类内距离,例如k-means,而有的是根据预测值和真实值构建一个损失函数,用优化算法来最优化这个损失函数达到学习模型参数的目的。
优化算法有很多种,如果按梯度的类型进行分类,可以分为有梯度优化算法和无梯度优化算法,有梯度优化算法主要有梯度下降法、动量法momentum、Adagrad、RMSProp、Adadelta、Adam等,无梯度优化算法也有很多,像粒子群优化算法、蚁群算法群体智能优化算法,也有贝叶斯优化、ES、SMAC这一类的黑盒优化算法,这篇文章主要介绍一下有梯度优化算法。
优化算法之间的关系
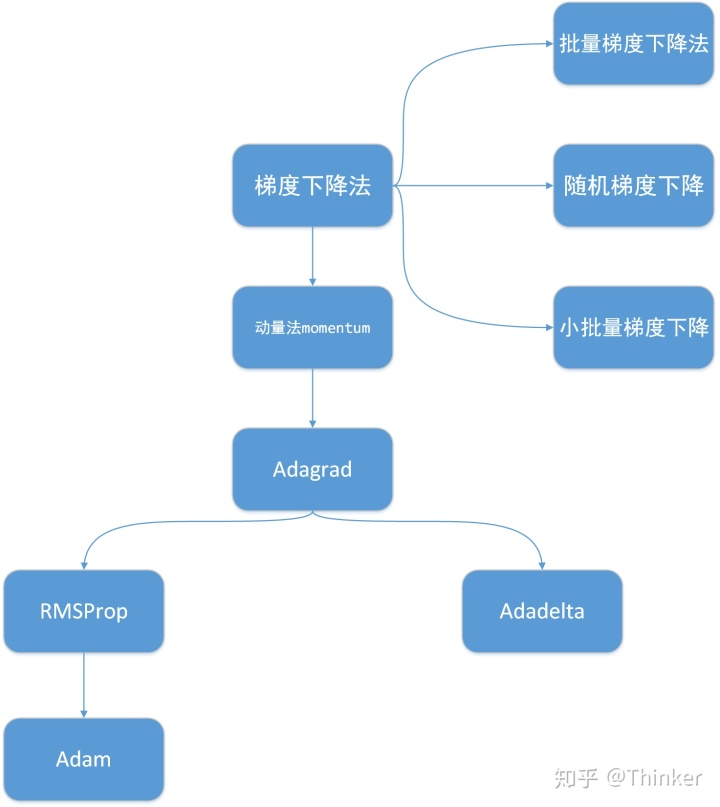
首先看一下下面的流程图,机器学习中常用的一个有梯度优化算法之间的关系:
梯度下降法
梯度下降法主要分为三种,
- 梯度下降法
梯度下降使用整个训练数据集来计算梯度,因此它有时也被称为批量梯度下降
下面就以均方误差讲解一下,假设损失函数如下:
大多数机器学习问题最终都会涉及一个最优化问题,只是有的是基于最大化后验概率,例如贝叶斯算法,有的是最小化类内距离,例如k-means,而有的是根据预测值和真实值构建一个损失函数,用优化算法来最优化这个损失函数达到学习模型参数的目的。
优化算法有很多种,如果按梯度的类型进行分类,可以分为有梯度优化算法和无梯度优化算法,有梯度优化算法主要有梯度下降法、动量法momentum、Adagrad、RMSProp、Adadelta、Adam等,无梯度优化算法也有很多,像粒子群优化算法、蚁群算法群体智能优化算法,也有贝叶斯优化、ES、SMAC这一类的黑盒优化算法,这篇文章主要介绍一下有梯度优化算法。
优化算法之间的关系
首先看一下下面的流程图,机器学习中常用的一个有梯度优化算法之间的关系:
梯度下降法
梯度下降法主要分为三种,
- 梯度下降法
梯度下降使用整个训练数据集来计算梯度,因此它有时也被称为批量梯度下降
下面就以均方误差讲解一下,假设损失函数如下:
其中
其中
- 随机梯度下降法
在机器学习深度学习中,目标函数的损失函数通常取各个样本损失函数的平均,那么假设目标函数为:
其中
如果使用梯度下降法(批量梯度下降法),那么每次迭代过程中都要对
- 小批量梯度下降法
随机梯度下降虽然提高了计算效率,降低了计算开销,但是由于每次迭代只随机选择一个样本,因此随机性比较大,所以下降过程中非常曲折(图片来自《动手学深度学习》),
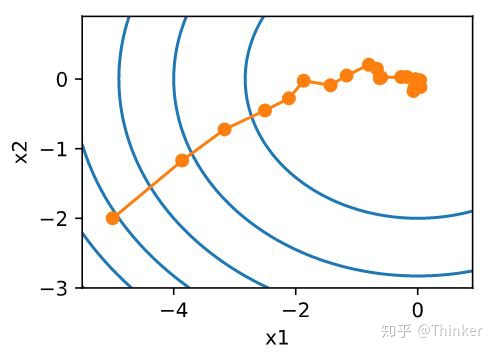
所以,样本的随机性会带来很多噪声,我们可以选取一定数目的样本组成一个小批量样本,然后用这个小批量更新梯度,这样不仅可以减少计算成本,还可以提高算法稳定性。小批量梯度下降的开销为
该怎么选择?
当数据量不大的时候可以选择批量梯度下降法,当数据量很大时可以选择小批量梯度下降法。
动量法momentum
梯度下降法的缺点是每次更新沿着当前位置的梯度方向进行,更新仅仅取决于所在的位置举个例子,假设一个二维的问题,
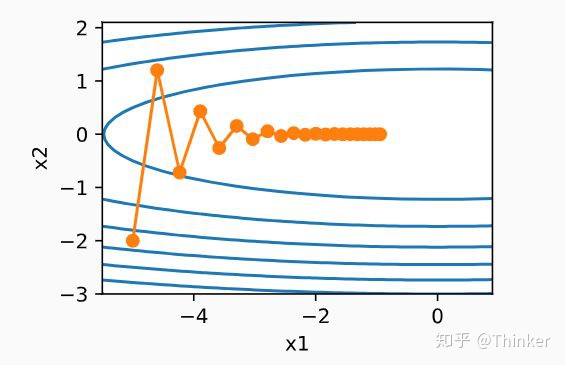
以
动量法在梯度下降法的基础上结合指数加权平均的思想加入一个动量变量
也就是把小批量梯度下降法中的
Adagrad
前面所介绍的方法都是针对梯度进行改进,而保持一个固定的学习率,例如动量法是通过指数加权平均使得各个方向的梯度尽可能的保持一致,减少梯度在各个方向的发散,而Adagrad算法是根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。
Adagrad在原来的基础上加入了一个梯度的累加变量
其中
其中
可以看出Adagrad与小批量梯度下降法的不同之处在于把原来的固定学习率
RMSProp
Adagrad算法在原来的基础上加上了累加变量
RMSProp使用了和动量法类似的思想,对梯度和累加变量利用指数加权平均,
和 Adagrad 一样,RMSProp 将目标函数自变量中每个元素的学习率通过按元素运算重新调整,然后更新自变量,
Adadelta
Adadelta和RMSProp一样,是针对Adagrad后期有可能较难找到有用解的问题进行改进,和RMSProp不同的是,Adadelta没有学习率这个参数。
和RMSProp相同点是,Adadelta也维护了一个累加变量
和RMSProp不同的是,Adadelta还维护了一个变量
梯度更新公式就变成了:
现在回过头看一下,可以发现,Adadelta和RMSProp的不同之处就是把学习率
Adam
这个算法在深度学习中用的比较多,Adam是在RMSProp的基础上进行改进的,该算法与RMSProp不同的是,Adam不仅对累加状态变量
Adam加入了动量变量
状态变量的指数加权平均为,
需要注意的是,当迭代次数
更新公式为:
结语:本人是一个学习者,本文主要参考李沐的《动手学深度学习》,概括性的总结了一下,文末附上了课程链接,如果想详细了解的可以看一下。后期我会定期分享一些机器学习、优化算法、计算机视觉、强化学习等方面的知识,也会分享一些开发中的总结和经验,如果感兴趣的可以关注一下,学习。http://zh.gluon.ai/chapter_introduction/index.htmlzh.gluon.ai
更多我的作品
Jackpop:机器学习入门指导
Jackpop:推荐15款免费网盘,总有一款适合你
Jackpop:有哪些堪称「神器」,却鲜为人知的APP?
Jackpop:Windows 下有什么用过之后就离不开的冷门软件?
Jackpop:初学 Python 需要安装哪些软件?
Jackpop:你读过哪些令你有跪感的书?
Jackpop:你的研究生导师是什么样的?
Jackpop:你有哪些特别搞笑的图片或视频值得分享?

