
热门标签
热门文章
- 1全网最全stable diffusion模型讲解!快来!!小白必收藏!!_stable diffusion 模型只能出动画吗
- 2电脑没有ps怎么改照片dpi_零基础PS的自学教程,新手收藏
- 3哈哈笔记 | HarmonyOS Arkts学习笔记(未完)
- 4小程序学习4 mock
- 5APP服务器:你想知道的都在这里_app挂在别人的服务器上有没问题
- 6Android安装KALI_./atilo_cn install kali
- 7Linux文件管理命令_在/opt目录下创建文件a,b.文件内内容分别为a,b。为文件/opt/a创建一个硬链接/tmp/
- 8Unity3D中的C#协程(概念、使用方法、底层原理)
- 9Mac安装kali双系统
- 10【哈士奇赠书活动 - 18期】-〖Flask Web全栈开发实战〗_flask web全栈开发实战 pdf 网盘 清华
当前位置: article > 正文
fasttext原理复习与代码实现
作者:凡人多烦事01 | 2024-03-15 16:19:17
赞
踩
fasttext原理
一:fasttext原理
https://blog.csdn.net/sinat_33741547/article/details/78784234
fastText简而言之,就是把文档中所有词通过lookup table变成向量,取平均后直接用线性分类器得到分类结果。fastText和ACL-15上的deep averaging network [1] (DAN,如下图)非常相似,区别就是去掉了中间的隐层。两篇文章的结论也比较类似,也是指出对一些简单的分类任务,没有必要使用太复杂的网络结构就可以取得差不多的结果。


有两个tricks,文章使用了Hierarchical softmax(分层softmax)和n-gram features
1:Hierarchical softmax


就是类别较多时,通过构建一个Huffman编码树来加速softmax layer的计算,和之前word2vec中的trick是相同的
并且时间复杂度为O(hlog2(k));
2: N-gram features

只用unigram的话会丢掉word order信息,所以通过加入N-gram features进行补充,用hashing来减少N-gram的存储。

二:fasttext代码实现例子
1:词向量模型学习
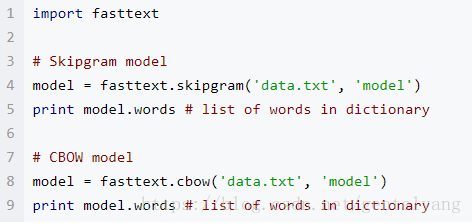
文本分类
classifier=fasttext.supervised('data.train.txt','model')
data.train.txt是一个含有训练句子,每行加上标签的文本文件,默认情况下,假设标签的话,前缀
字符串_label_.
输出model.bin 和model.vec

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/242820
推荐阅读
相关标签

