
- 1离线AI聊天清华大模型(ChatGLM3)本地搭建_chatglm3 6b最低部署要求
- 2AD 20 开发板的PCB完整设计_使用ad设计开发板
- 3POI实现Excel插入多张图片_easypoi一个单元格嵌入多张图片
- 4微信小程序之个人中心静态页面_小程序个人中心页
- 5Java工程报错:java.lang.IllegalArgumentException: Invalid character found in the request target.
- 6微信公众号开发之微信扫一扫
- 7第八周学习报告_devecostudio自定义laucher ability
- 8神经网络参数微调算法:最新进展与未来方向
- 9Jetson_Xavier_NX使用教程1(刷机)_jetson xavier nx 格式化
- 10Android开发学习之路--MAC下Android Studio开发环境搭建_mac 下搭建android studio 环境
CONVMIXER: FEATURE INTERACTIVE CONVOLUTION WITH CURRICULUM LEARNING FOR SMALL FOOTPRINT AND...(2021)
赞
踩
CONVMIXER: FEATURE INTERACTIVE CONVOLUTION WITH CURRICULUM LEARNING FOR SMALL FOOTPRINT AND NOISY FAR-FIELD KEYWORD SPOTTING
CONVMIXER:具有课程学习的特征交互式卷积,适用于小足迹和有噪声的远场关键字识别
摘要
在神经语音处理中建立高效的体系结构对于关键词识别部署的成功至关重要。然而,对于轻量级模型来说,通过简洁的神经操作来实现噪声鲁棒性是非常具有挑战性的。
在现实世界的应用程序中,用户环境通常是嘈杂的,并且可能包含混响。
为了在噪声远场条件下解决这一问题,我们提出了一种新的仅含100K参数的特征交互卷积模型。互动(mixer)单元被提议代替注意力模块,它通过更高效的计算促进信息流。
此外,为了获得更好的噪声鲁棒性,采用了基于课程的多条件训练。
我们的模型在谷歌语音命令V2-12上达到了98.2%的top-1精度,在设计的噪声条件下与大型transformer模型相比具有竞争力。
研究内容
关键词识别(KWS),在当今的技术中,它被广泛用于激活智能设备中的免提应用程序,并带有特定的唤醒词,如“Alexa”或“Hey Siri”。在大多数情况下,这些小工具都受到低内存和计算资源的约束。
最近关于小足迹KWS模型[1,2]的工作在噪音更小、通话距离近的音频设备上取得了巨大成功。然而,该系统变得脆弱,尤其是在低信噪比(SNR)的远场语音场景中。
之前关于提高整体性能和噪声鲁棒性的工作包括使用基于注意的模块来提高音频网络的效率(性能)[2,5,6]。这提供了有选择地关注音频序列中有价值片段的能力。然而,巨大的计算和内存复杂性极大地降低了它在小型设备上的可用性。
我们试图通过构造一种新型卷积网络(CNN)编码器,并使用mixer模块来优化小型KWS系统的性能,该模块提供了一种强大的注意力替代方案。mixer单元计算全局通道的加权特征交互作用,以允许具有不同重要性的信息流。值得注意的是,CNN编码器的内存占用量很小,在较小的型号下非常有效。
此外,我们还提出了一种基于课程的多条件训练学习策略,该策略优于普通的多条件学习,以获得更好的噪声鲁棒性。
提出的方法&模型架构
模型体系结构
我们的ConvMixer网络由三个主要部分组成,即pre-convolutional block, convolution-mixer block and post-convolutional block。
与之前的工作类似,我们基于深度可分离(DWS)卷积构建了模型编码器,因为它使用少量模型参数提供了最高效的计算。
我们用一维DWS的相同神经层设计了pre-convolutional block 和 post-convolutional block,然后进行批量归一化和swish激活[15]。下面所有的块都与图1中所示的不同的内核大小进行卷积,并进行填充,以保留前一时间帧的维度。然而,[16]讨论了一维卷积操作的平移等变特性在频域内没有被保留。这会影响一些空间信息沿着频率通道的学习。因此,我们考虑引入二维DWS,特别是在我们的ConvMixer块中。
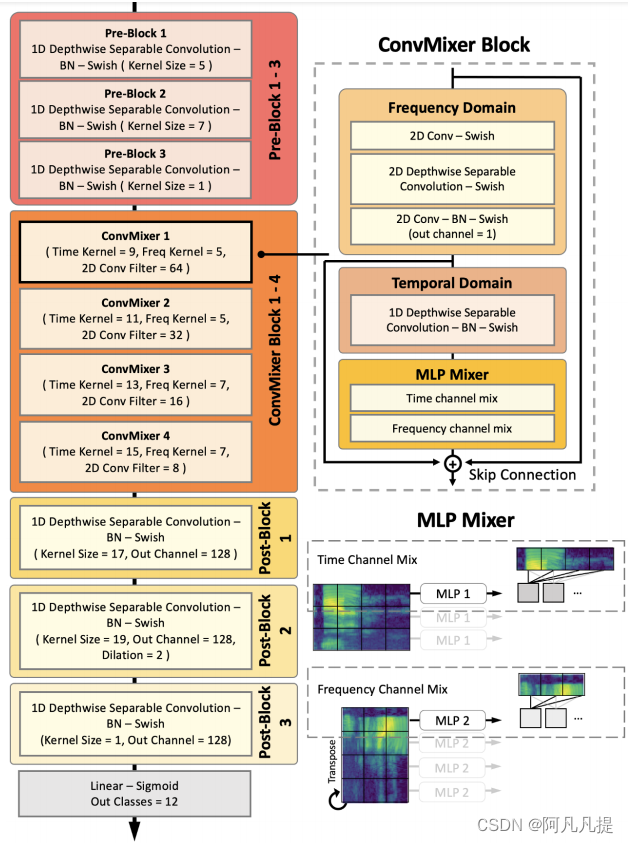
Fig. 1. 我们的Convmixer模型架构的概述
ConvMixer块采用前一个信道×时间特征,并将其通过2D卷积子块进行频域提取。这创造了一个第三维度,表达了来自频域的丰富信息。为了保持之前输入的形状,我们采用了逐点卷积,将其压缩回来以适合形状。
然后,我们用一维DWS块实现了时域特征提取。
这两个操作的结果将导致频率和时间丰富的嵌入。
接下来,我们构建了一个ConvMixer层,允许信息在全局特征通道上流动。最后,我们添加了跳过连接,从上一个输出和二维特征连接到块的输出。我们用以下等式表示我们的ConvMixer块:
z = σ ◦ f1 ( σ ◦ f ( x ) )
y1 = σ ◦ BatchNorm ( f ( z ) ) (1)
y2 = σ ◦ BatchNorm ( f2 ( y1 ) ) (2)
˜ y = x + y1 + f3 ( y2 ) (3)
其中,等式(1)计算频域特征,其中f1为2d-DWS,2D卷积函数f。等式(2)计算时域特征,其中f2为1d-DWS。等式(3)计算块的输出,其中f3为mixer层,σ 为等式(1-3)的swish激活。
mixer层
注意力层因其强大的特征而成为一种潮流,它允许网络关注有用的空间信息。尽管如此,这需要大量的线性计算。
[17,18]没有权衡一个元素与其他每一个token的相关性,而是建议混合token通道,作为特征通信的替代方法。
因此,我们提出利用两种多层感知器(MLP),即时间通道混合和频率通道混合,来诱导特征空间之间的相互作用。每个MLP混合包括两个线性层和一个独立于每个时间和频率通道的GELU激活单元。这被定义为
u∗,i = x∗,i + W2 · δ ( W1 · LayerNorm ( x ) ∗,i )
y j,∗ = u j,∗ + W 4 · δ ( W3 · LayerNorm ( u ) j,∗ ) ( 4 )
其中δ表示GELU单位。 W1和 W2是在所有频率i中共享的时间信道的线性层的可学习权重,对于i∈ {1,I}。W3 和W4是在所有j中共享的频率通道的线性层的可学习权重,对于j∈ {1,J}。
如图1所示,我们只学习将信道特征与在另一个域中共享的加权系数连接起来的权重。为了方便起见,我们将频率信道混合的潜在特征转置,以便算法与时间信道混合保持一致。
之后,将进行另一次转置,以恢复其原始频率×时间的安排。学习到的系数值有助于分配具有不同重要性的信息,类似于注意力,但计算效率要高得多。
基于课程的多条件训练
为了增强我们模型的噪声鲁棒性,上述基于信噪比水平的课程学习被用作训练策略。为了执行,我们将训练过程分为五个逐步加强的步骤。
开始时,我们将模型置于干净且无噪音的样本上。在以下三个步骤中,将以-5dB的增量向固定的N个样本引入噪声,并且N个样本中的所有条件都是均匀分布的,即[clean, 0], [clean, 0, -5], [clean, 0, -5, -10]。最后,我们通过用房间脉冲响应(RIR)数据增加一半的数据集来包含远场音频。
在每个阶段(stage)的每一个epoch,我们都会记录学习进度以及验证的准确性和损失。接下来,级数标准c被定义为归一化验证准确度和归一化验证损失之间的差异。归一化是基于之前epochs的准确性和损失。等式(5)描述了计算归一化准确度和损耗的第m个epoch值的通用算法。请注意,如果m等于零,则归一化结果为零。随后,如果连续10个epochs的c不高于当前最佳标准,则将加载具有最新最佳标准的模型,并进行下一阶段的难度训练。完整的训练策略如算法1所示。
Norm ( am ) = am − min ( A ) max ( A ) − min ( A ) , A = { a1, a2..., am } (5)

文章贡献
在这项工作中,我们介绍了一种新的小足迹模型ConvMixer,它具有特征交互结构MLP mixer。
采用基于课程的多条件训练方法提高噪声鲁棒性。
我们的ConvMixer在干净和嘈杂的远场条件下,在命令V2-12上的性能超过了现有的SOTA KWS。
此外,它还与基于transformer的KWS的性能相匹配,KWS使用的内存消耗和计算资源是前者的50倍。
结果突出了ConvMixer在端点部署和实际场景中的应用中的潜力。
前提知识
多条件训练
多条件训练因其在小足迹模型中的简单噪声鲁棒性策略而成为首选方法。然而,当模型从更大范围的噪声中学习时,即从非常低的信噪比中学习,例如从-10 dB到清洁[13],它变得不适用。
最近,[13,14]提出了一种更有效的课程学习方法。简而言之,他们从干净或高信噪比的音频开始训练模型,然后逐渐增加噪声水平以降低信噪比。在获得噪声鲁棒性方面,这种渐进式训练比传统方法更有效。
数据集
用于远域关键字识别的数据集
我们在Google Speech Commands V2[20]上评估了我们提出的系统。它包含105000个由35个独特单词组成的话语,每个单词的长度为1秒,采样频率为16kHz。我们使用为12个标签分类任务提供的正式训练、验证和测试拆分。这包括“向上”、“向下”、“向左”、“向右”、“是”、“否”、“开”、“关”、“走”和“停”以及“沉默”和“未知”类。后一类是从数据集中剩余的单词中处理的。
为了模拟嘈杂的远场环境,我们使用了两个额外的数据集。我们应用了MUSAN[21]的噪声样本,其中包含930个以16kHz采样的各种噪声文件,总持续时间约为6小时。它们携带各种技术和非技术噪音,如DTMF铃声、雷声和汽车喇叭,我们将它们添加到命令中,以模拟不同噪音条件下的音频。远场语音是利用BUT的混响产生的Speech@FIT混响数据库[22]。数据集保存了九个不同大小房间(大、中、小)的RIR数据。
结果
我们将ConvMixer的性能与之前提出的SOTA模型进行了比较。模型是从我们设计的数据环境提供的官方源代码中重新训练出来的。结果如表1所示。从表中,我们观察到,在官方V2-12上测试时,我们提出的模型在小型模型中达到了SOTA精确度。此外,模型参数和MAC的数量显著减少,这意味着内存和计算资源减少。最重要的是,在嘈杂的远场条件下进行评估时,我们与MatchboxNet相比获得了3%的绝对改善,而MatchboxNet具有相同多条件训练的相似内存占用。对于我们基于课程的训练,这一比例提高到了7.4%。最后,我们证明了在具有挑战性的噪声远场条件下,该模型与更大的基于transformer的模型(KWT-3,AST-Tiny)具有竞争力。
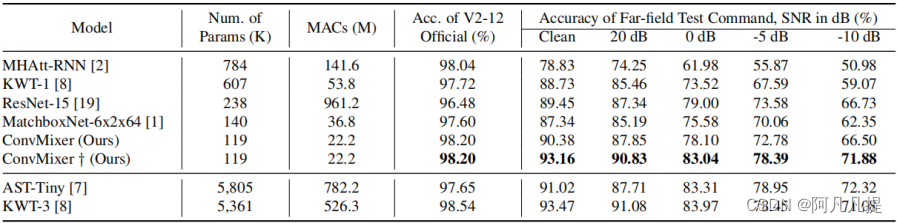
表1.与SOTA模型的比较(†:提出的课程学习模型)。用1计算的MACs
消融实验
我们进一步研究了特征交互结构:MLPmixer在噪声远场条件下的重要性。使用相同的基于课程的多条件训练方法,我们移除了模型ConvMixer块中的MLPmixer,并获得了如表2所示的结果。mixer层的添加大大提高了约7%的精确度,这表明该特征交互结构在使模型更鲁棒性方面的有用性。
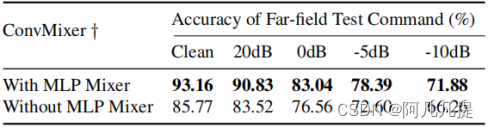
表2.有/没有MLP混合层的比较
我们还探索了基于课程的多条件训练在基于transformer的AST-Tiny上的性能增益,结果如图2所示。AST-Tiny †上的课程学习领先于图表,与多条件训练相比,准确率提高了约3%。
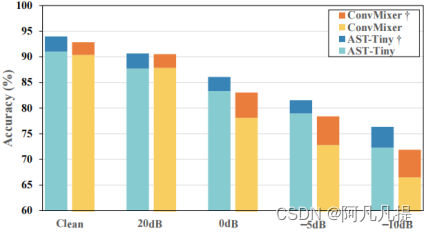
图2.课程学习带来的绩效收益
这与课程学习能力提高模型的表现是一致的。尽管如此,我们提出的模型只落后于AST-Tiny †不到2%。此外,图表显示,课程学习在模型参数较小的 ConvMixer † 上更有效,尤其是在SNRs较低的情况下,准确率提高了约5.5%。

