
- 1Android 开发环境搭建(Android Studio 安装图文详细教程)
- 2【安卓开发快速入门】Android Studio(3.5.2)安装_android studio 3.5.2下载
- 3Nginx 限制单个IP的并发连接数/速度来减缓垃圾蜘蛛爬虫采集_网站单个ip访问最大并发数
- 4MUX实现某些电路的搭建_mux电路
- 5h5实现下拉选择_h5下拉框
- 6Graphpad Prism 9绘制子列图与柱状图_prism 9 format data table
- 7UE4的前世今生_虚幻4什么时候出的
- 8vue3项目实战的请求接口问题(一)跨域问题+解决方法_vue3 请求接口502 proxy
- 9php调用mysql数据库常用操作_mysql.inc.php
- 10应用监控_endpoints.enabled
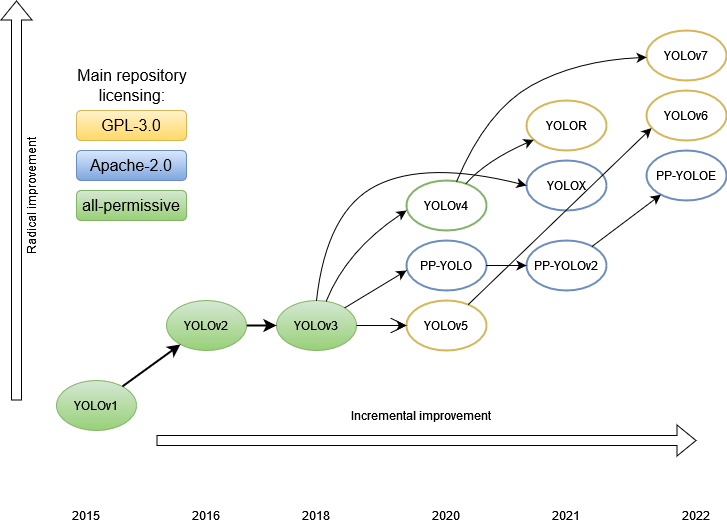
YOLO系列的演进,从v1到v7
赞
踩
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Maxim Ivanov
编译:ronghuaiyang
导读
经典再回顾,本文介绍v1到v3。
如果你需要速度快的目标检测器,那么 YOLO 系列的神经网络模型实际上是当今的标准。
解决检测问题还有很多其他优秀的模型,但我们不会在这篇综述中涉及它们。
目前,已经写了相当多的文章来分析 YOLO 各个版本的功能。本文的目的是对整个家族进行比较分析。我们想看看架构的演变,这样我们就可以更好地了解检测器是如何发展,哪些发展提高了性能,也许还可以想象事情的发展方向。
在YOLO出现之前,检测图像中目标的主要方法是使用各种大小的滑动窗口按顺序穿过原始图像的各个部分,以便分类器给出图像的哪个部分包含哪个目标。这种方法是合乎逻辑的,但非常慢。
一段时间之后,出现了一个特殊的部分,它暴露了感兴趣的区域 —— 一些假设,图像上可能有有趣的东西。但是这些感兴趣区域还是太多,有数千个。最快的算法,Faster R-CNN,平均在0.2秒内处理一张图片,每秒5帧。总的来说,在出现一种全新的方法之前,速度不容乐观。
有什么新奇之处?
在以前的方法中,原始图像的每个像素可以被神经网络处理数百甚至数千次。每次这些像素都通过相同的神经网络传递,经过相同的计算。是否可以做一些事情以免重复相同的计算?
事实证明,这是可能的。但为此,我们不得不稍微重新表述问题。如果说以前它是一个分类任务,那么现在它变成了一个回归任务。
YOLO aka YOLOv1
让我们考虑第一个 YOLO 模型,也称为 YOLOv1。
作者
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
主要论文
“You Only Look Once: Unified, Real-Time Object Detection”, publication date 2015/06
代码库
除了基于darknet框架的官方实现之外,在其他通用框架上还有大量各种流行的实现。
https://pjreddie.com/darknet/yolov1/
https://github.com/thtrieu/darkflow, 2.1k forks / 6k stars, GPL-3.0 license
https://github.com/gliese581gg/YOLO_tensorflow, 670 forks / 1.7k stars, non-commercial license
https://github.com/hizhangp/yolo_tensorflow, 455 forks / 784 stars
https://github.com/nilboy/tensorflow-yolo, 331 forks / 780 stars
https://github.com/abeardear/pytorch-YOLO-v1, 214 forks / 473 stars, MIT license
https://github.com/dshahrokhian/YOLO_tensorflow, 22 forks / 42 stars
性能比较
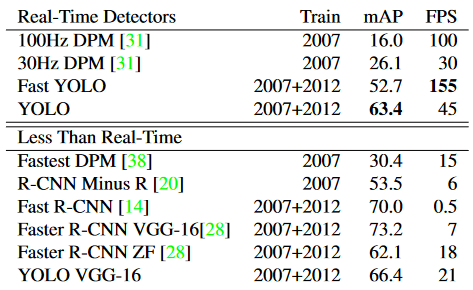
Pascal VOC 2007上的实时系统。YOLO是有记录以来最快的Pascal VOC检测检测器,其准确性仍然是任何其他实时检测器的两倍。
结构
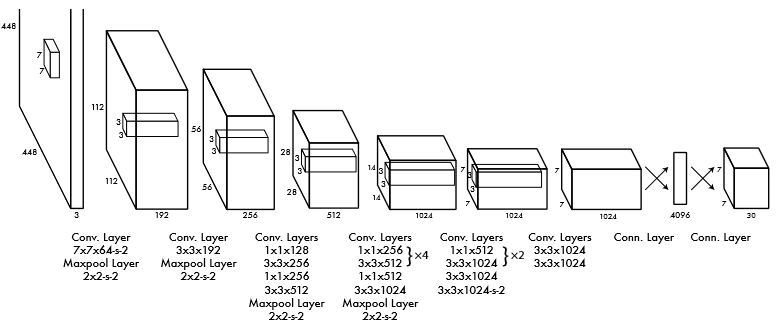
在结构上,YOLO 模型由以下部分组成:
input ― 输入图像被馈送到的输入层
backbone — 输入图像以特征形式编码的部分。
neck — 这是模型的其他部分,用于处理按特征编码的图像
head — 生成模型预测的一个或多个输出层。
该网络的第一个版本基于GoogLeNet的架构。卷积层接MaxPool层级联,最后以两个全连接层的级联作为结束。
此外,作者训练了Fast YOLO架构的更快版本,包含更少的卷积层(9而不是24)。两个模型的输入分辨率均为 448x448,但网络主要部分的预训练通过分辨率为 224x224 的分类器训练。
在此结构中,原始图片被划分为 S x S 单元格(在原始 7 x 7 中),每个单元格预测 B 个边界框,这些 bbox 中存在目标的置信度,以及 C 类的概率。每条边的单元格数是奇数,因此图像的中心有一个单元格。这比偶数具有优势,因为照片的中心通常有一个主要目标,在这种情况下,主要的预测是在中心单元格中进行的。在区域数量为偶数的情况下,中心可能位于四个中央区域中的某个位置,这降低了网络的置信水平。
置信度值表示模型对给定 bbox 包含某个目标的置信度,以及 bbox 预测其位置的准确度。事实上,这是IoU存在物体概率的乘积。如果单元格中没有目标,则置信度为零。
每个 bbox 由 5 个数字组成:x、y、w、h 和置信度。(x, y)为单元格内 bbox 中心的坐标,w 和 h为 bbox相对于整个图片尺寸的归一化的宽度和高度,即归一化从 0 到 1 的值。置信度是预测的 bbox 和GT框之间的 IoU。每个单元格还预测目标类的 C 个条件概率。每个单元格仅预测一组类别,而不考虑 bbox的数量。
因此,在一次前向中,预测了 S×S×B个包围框。他们中的大多数框的置信度都很低,但是,通过设置一定的阈值,我们可以去除其中的很大一部分。但最重要的是,(与竞争对手相比)检测率提高了几个数量级。这是非常合乎逻辑的,因为所有类别的所有 bbox 现在只需一次预测。对于不同的实现,原始文章给出了从 45 到 155 的FPS。尽管与以前的算法相比,mAP的准确性仍然有所下降,但在某些问题中,实时检测更为重要。
得到检测框
由于与物体中心相邻的单元格也可以产生bbox,从而导致框过多,因此有必要选择其中最好的。为此,使用NMS技术,其工作原理如下。此类的所有 bbox,置信度低于给定阈值的那些将被丢弃。对于其余部分,执行IoU的成对比较过程。如果两个框的 IoU > 0.5,则丢弃置信度较低的框。否则,两个框都会保留在列表中。因此,类似的框被抑制了。
损失函数是组合的,具有以下形式:
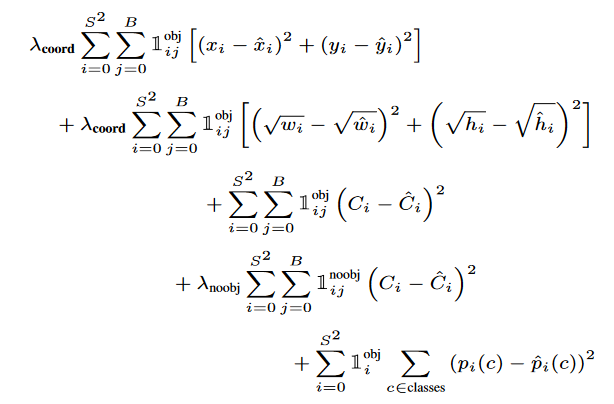
第一项是目标中心坐标的损失,第二项是框尺寸的损失,第三项是目标的类损失,如果目标不存在,则第四项是类的损失,第五项是在框中找到某个目标的概率。
需要 lambda 系数来防止置信度变为零,因为大多数单元格中没有目标。1(obj,i) 表示的中心是否出现在单元格 i 中,1(obj,i,j) 表示单元格 i 中的第 j 个 bbox 负责此预测。
优势
高速
比当时的竞争对手更好的泛化能力,在另一个领域进行测试(训练是在ImageNet上进行的)显示出更好的性能。
图像背景部分的误报更少。
局限性
每个单元格 2 个 bbox 和一个类目标的限制。这意味着一堆小物体的识别度较低。
原始图像的几个连续下采样导致精度不高。
损失的设计方式是,它对大框和小框的错误具有同样惩罚。作者试图通过取尺寸大小的根来补偿这种影响,但这并没有完全消除这种影响。
YOLOv2 / YOLO9000
作者
Joseph Redmon, Ali Farhadi
主要论文
“YOLO9000: Better, Faster, Stronger”, publication date 2016/12
代码仓库
https://pjreddie.com/darknet/yolov2/
https://github.com/experiencor/keras-yolo2, 795 forks / 1.7k stars, MIT license
https://github.com/longcw/yolo2-pytorch, 417 forks / 1.5k stars
https://github.com/philipperemy/yolo-9000, 309 forks / 1.1k stars, Apache-2.0 license
性能比较
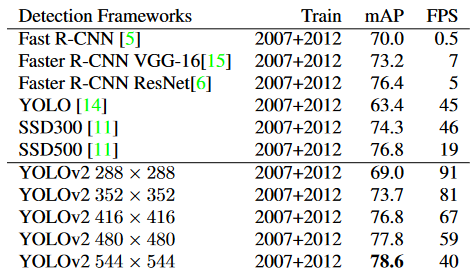
Pascal VOC 2007的检测框架。YOLOv2 比以前的检测方法更快、更准确。它还可以以不同的分辨率运行,以便在速度和准确性之间轻松权衡。每个 YOLOv2 条目实际上是具有相同权重的相同训练模型,只是以不同的大小进行评估。所有计时信息均在 Geforce GTX Titan X 上测试。
结构特点
作者对模型的第一个版本进行了一些改进。
删除了 dropout,并在所有卷积层中添加了BN。
预训练为分辨率为 448x448 的分类器(YOLOv1 分辨率为 224x224),然后将最终网络缩小到 416x416 输入,以产生奇数个 13x13 单元。
删除了全连接层。相反,他们开始使用全卷积和锚框来预测bbox(如Faster RCNN)。这样可以减少空间信息的丢失(就像在 v1 中的全连接层中一样)。
删除了一个最大池化以增加特征的细节(分辨率)。在 v1 中,每张图片只有 98 个 bbox,使用 V2 中的锚点,结果有超过 1000 个 bbox,而 mAP 略有下降,但召回率显著增加,这使得提高整体准确性成为可能。
维度先验。bbox的大小和位置不是像FasterRCNN那样随机手动选择的,而是通过k-means聚类自动选择的。尽管在小bbox上使用具有欧氏距离的标准k均值,但检测误差更高,因此对于k均值,选择了另一个距离度量,1 - IoU(box,质心)。选择5个作为分组数目的折衷方案。测试表明,对于以这种方式选择的 5 个质心,平均 IoU 与 9 个锚点大致相同。
直接位置预测。最初,对于锚,与确定中心(x,y)坐标相关的网络训练存在不稳定性:由于网络权重是随机初始化的,并且坐标预测是线性的,大小是没有限制的。因此,我们没有预测相对于锚中心的偏移量,其中系数的正确范围是 [-1,1],而是决定预测 bbox 相对于单元格中心的偏移,范围 [0,1],并使用 sigmoid 来限制它。网络为每个单元格预测 5 个 bbox,每个 bbox 5 个数字:tx、ty、tw、th、to。bbox 的预测参数计算如下:
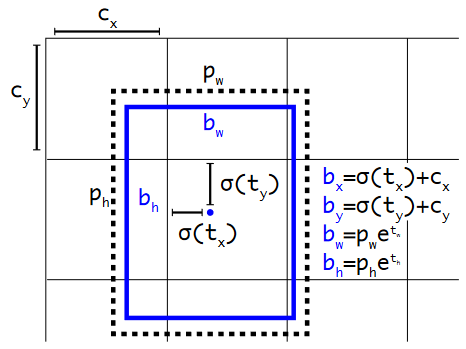
具有维度先验和位置预测的边界框。我们将框的宽度和高度预测为聚类质心的偏移量。我们使用 sigmoid 函数预测框相对于中心坐标的偏移。

细粒度特征。特征映射现在为 13x13。
多尺度训练。由于网络是全卷积的,因此只需更改输入图像的分辨率即可动态更改其分辨率。为了提高网络的鲁棒性,其输入分辨率每 10 批次更改一次。由于网络缩小了 32 倍,因此输入分辨率是从集合 {320, 352, ..., 608} 中选择的。网络的大小从 320x320 调整为 608x608。
加速。VGG-16作为v1的骨干,太重了,所以在第二个版本中使用了darknet-19:
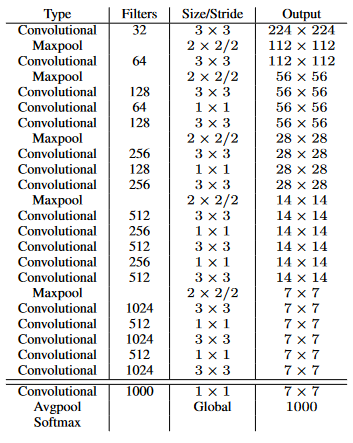
训练分类器后,从网络中删除最后一个卷积层,添加三个具有 1024 个滤波器的 3x3 卷积层和一个具有检测所需输出数量的最终 1x1的卷积层。在 VOC 的情况下,它是 5 个 bbox,每个 bbox 有 5 个坐标,每个 bbox 有 20 个类,总共有 125 个滤波器。
分层分类。在 v1 中,这些类属于同一类目标并且是互斥的,而在 v2 中引入了 WordNet 树结构,这是一个有向图。每个类别中的类都是互斥的,并且有自己的softmax。因此,例如,如果图片显示已知品种网络的狗,则网络将返回狗和特定品种的类。如果是网络未知品种的狗,那么它只会返回狗的类别。因此,训练了 YOLO9000,它是具有 3 个先验的 v2,而不是 5 个和 9418 个目标类。
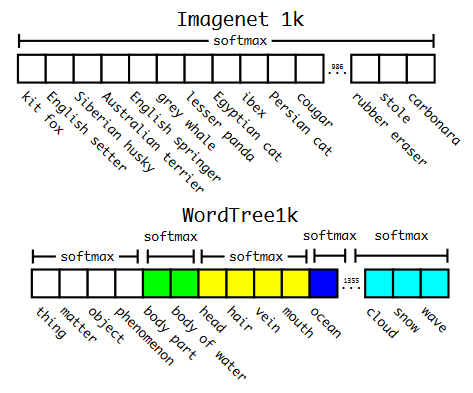
ImageNet vs WordTree上的预测。大多数 ImageNet 模型使用一个大的 softmax 来预测概率分布。使用WordTree,我们对共同下义词执行多个softmax操作。
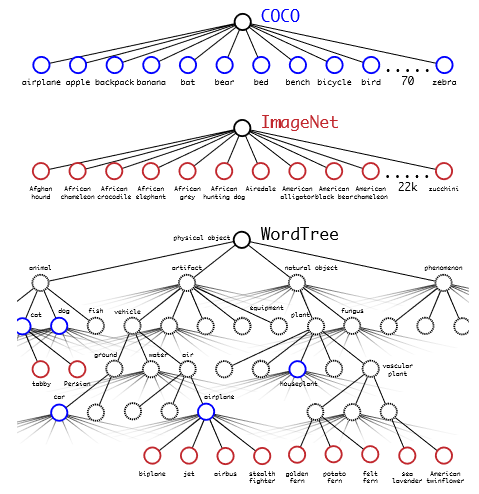
使用 WordTree 层次结构合并数据集。使用WordNet概念图,我们构建了一个视觉概念的分层树。然后,我们可以通过将数据集中的类映射到树中的合成集来将数据集合并在一起。这是 WordTree 的简化视图,用于说明目的。
优势
现在它不仅是速度方面的 SOTA,而且在 mAP 方面也是。
现在可以更好地检测小物体。
YOLOv3
作者
Joseph Redmon, Ali Farhadi
主要论文
“YOLOv3: An Incremental Improvement”, publication date 2018/04
代码仓库
https://pjreddie.com/darknet/yolo/, all-permissive license
https://github.com/ultralytics/yolov3, 3.3k forks / 8.9k stars, GPL-3.0 license
https://github.com/eriklindernoren/PyTorch-YOLOv3, 2.6k forks / 6.8k stars, GPL-3.0 license
性能比较
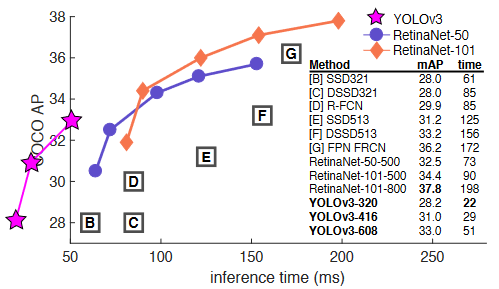
YOLOv3 的运行速度明显快于具有相当性能的其他检测方法。从M40或Titan X开始,它们基本上是相同的GPU。
结构
这是模型的增量更新,即没有根本上更改,只有一组改进技巧。
每个 bbox 的置信度得分,即给定 bbox 中存在目标的概率,现在也使用 sigmoid 计算。
作者从多类分类切换到多标签,所以我们摆脱了softmax,转而支持二进制交叉熵。
在三个尺度上对 bbox 进行预测,输出张量大小:N * N * (3 * (4 + 1 + num_classes))
作者使用k均值重新计算先验框,并在三个尺度上得到了9个bbox。
新的、更深、更准确的骨干/特征提取器Darknet-53。
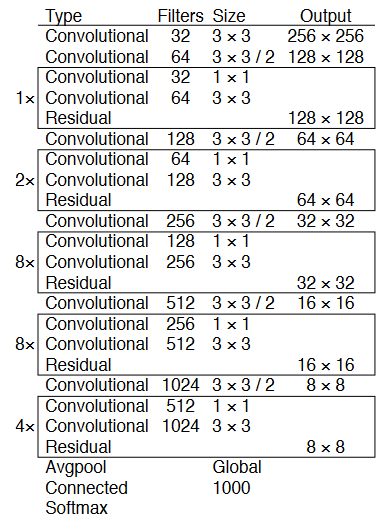
在准确性方面,它与 ResNet-152 相当,但由于更有效地使用 GPU,它所需的操作减少了近 1.5 倍,产生的 FPS 提高了 2 倍。
总体结构
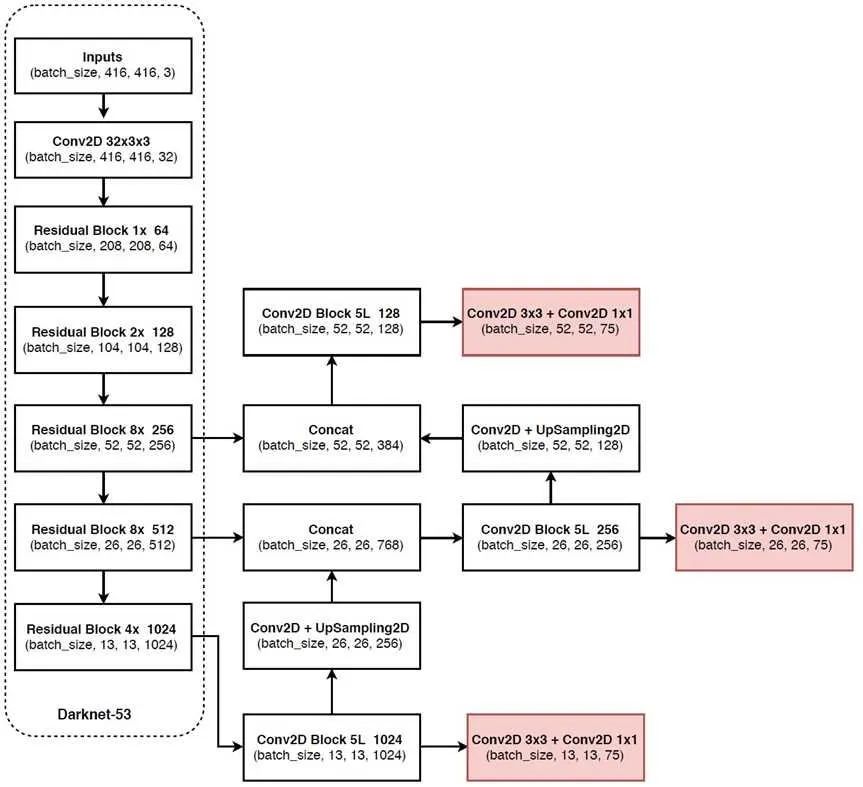
不起作用的方法
BBOX 通过线性激活函数而不是logistic激活函数来协调位移预测。
focal loss — mAP 下降了 2 点。
用于确定GT的双 IoU — 在 Faster R-CNN 中,IOU 有两个阈值,通过该阈值确定正样本或负样本(>0.7 正值,0.3-0.7 忽略,<0.3 负样本)
优势
发布时的检测精度高于竞争对手
发布时的检测率高于竞争对手
在下一部分中,我们将考虑v4,v5,PP-YOLOS和YOLOX。敬请期待!

—END—
英文原文:https://medium.com/deelvin-machine-learning/the-evolution-of-the-yolo-neural-networks-family-from-v1-to-v7-48dd98702a3d

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!

