
- 1uni APP--uni.request请求数据和渲染页面
- 2rbtree使用
- 3“悟空网盘”操作教程(保姆级),“星子助推”小程序操作方法教程_悟空网盘在哪里打开
- 4html字符及空格占位问题_html 中文和符号一起会压缩吗
- 5HarmonyOS鸿蒙应用开发 (二、应用程序包结构理解及Ability的跳转,与Android的对比)_openharmony startability跳转动画
- 6WinSCP如何使用公网TCP地址访问本地服务器_winscp连接本地
- 7读提交和可重复读的底层原理?事务的隔离级别底层实现?_读已提交的原理
- 8AI绘画生成器怎么选择?
- 9Vue3.0中this的替代方法_vue3 this
- 10《安富莱嵌入式周报》第258期:2022.03.21--2022.03.27_dsp教程 安富莱
干货丨深度学习硬件,GPU、CPU、FPGA到底谁最合适?
赞
踩

人机大战,不仅让谷歌的人工智能“AlphaGo”一炮走红,也让它背后的深度学习(Deep Learning)这个概念为公众所熟知。伴随着摩尔定律带来的芯片计算能力和存储能力大幅提升和大数据时代的来临,一个“深度学习 大数据”的模型组合将人工智的研究能推向了一个新的高潮。诚然,深度学习的核心驱动力是算法:利用算法/函数去模仿和逼近人脑思维方式。而这些算法/模型最终还是要依赖高性能的硬件来实现对于数据的处理。说起关于计算机数据处理的硬件。毫无疑问CPU是第一个被大家联想到的。 但是在深度学习的世界里,CPU并不是一个最佳的选择。好马配好鞍,今天,我们就来聊一聊深度学习中的硬件。
一、深度学习对硬件的需求
一般来说,深度学习包含两个阶段:数据训练和推断。
随着深度神经网络模型层数的增多,与之相对应的权重参数成倍的增长,从而对硬件的计算能力有着越来越高的需求,尤其是在数据训练的阶段。因此,深度学习训练领域的前沿逐渐从算法转移到了对于高性能计算(HPC)的追逐上。目前被业内广泛接受的是“CPU GPU”的异构模式和“MIC (Many Integrated Core)”众核同构来实现高性能计算。

推断阶段就是利用训练中所获得的特征值去对新的输入数据进行判断或者预测。从应用上来说,推断可以分为两大类:线上数据中心的推断和移动设备中的推断。
相较于训练阶段执着于对高性能计算的需求,线上数据中心的推断不仅要求硬件有着高性能计算,更重要的是对于多指令数据的处理能力。就比如“Bing”搜索引擎同时要对数以万计的图片搜索要求进行识别推断从而给出搜索结果。目前而言,“CPU GPU”的异构模式依旧是第一选择,但是“CPU FPGA”异构计算已经显示出他在这方面的潜力。
而移动设备中的推断更强调在高性能计算和低功耗中寻找一个平衡点。在这个领域的深度学习的执行还是更多的依赖于“CPU FPGA”与“ASIC”。
二、数据的训练:CPU与GPU之争
2.1、现状
在如今的深度学习平台上,CPU面临着一个很尴尬的处境:它很重要又不是太重要。 它很重要,是因为它依旧是主流深度学习平台的重要组成部分:现百度首席科学家吴恩达曾利用16000颗CPU搭建了当时世界上最大的人工神经网络“Google Brain”并利用深度学习算法识别出了“猫”,又比如名震一时的“AlphaGo”就配置了多达1920颗CPU。
但是它又不是太重要:相比于其他硬件加速工具,传统的CPU在架构上就有着先天的弱势。
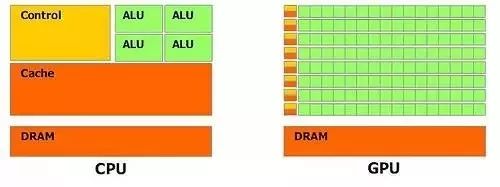
CPU与GPU内部结构上的对比,总体上来说二者都是由控制器(Control),寄存器(Cache、DRAM)和逻辑单元(ALU)构成。但是三者的比例却有很大的不同。在CPU中控制器和寄存器占据了结构中很大一部分,与之相反,在GPU中,逻辑单元的规模则是远远超过其他二者之和。这种不同的构架就决定了CPU在指令的处理/执行,函数的调用上有着很好的发挥,但由于逻辑单元所占比重较小,相对于GPU而言,在数据的处理方面(算术运算或者逻辑运算)的能力就弱了很多。
我们拿NIVIDA公司基于Maxwell构架的GPU来详细说明。这颗代号GM200的显示核心主要由4个图形处理集群(GPC),16个流处理集群(SMM)和4个64bit显存控制器组成。每个流处理集群中包含了4个调度器(Warp),每个调度器又控制着32个逻辑计算核心(Core),这些Core是实现逻辑计算的基本单元。
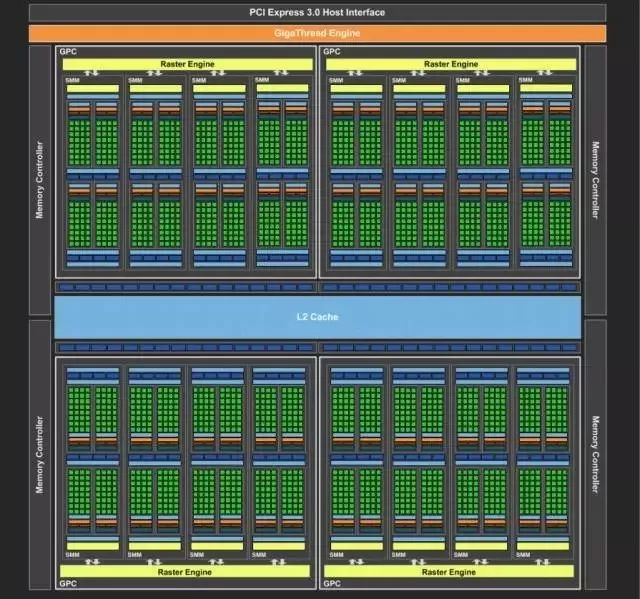
GPU进行数据处理的过程可以描述成:GPU从CPU处得到数据处理的指令,把大规模、无结构化的数据分解成很多独立的部分然后分配给各个流处理器集群。每个流处理器集群再次把数据分解,分配给调度器所控制的多个计算核心同时执行数据的计算和处理。如果一个核心的计算算作一个线程,那么在这颗GPU中就有32×4×16, 2048个线程同时进行数据的处理。尽管每个线程/Core的计算性能、效率与CPU中的Core相比低了不少,但是当所有线程都并行计算,那么累加之后它的计算能力又远远高于CPU。对于基于神经网络的深度学习来说,它硬件计算精度要求远远没有对其并行处理能力的要求来的迫切。而这种并行计算能力转化为对于硬件的要求就是尽可能大的逻辑单元规模。通常我们使用每秒钟进行的浮点运算(Flops/s)来量化的参数。不难看出,对于单精度浮点运算,GPU的执行效率远远高于CPU。

除了计算核心的增加,GPU另一个比较重要的优势就是他的内存结构。首先是共享内存。在NVIDIA披露的性能参数中,每个流处理器集群末端设有共享内存。相比于CPU每次操作数据都要返回内存再进行调用,GPU线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高(速度:共享内存》全局内存)。
再就是高速的全局内存(显存):目前GPU上普遍采用GDDR5的显存颗粒不仅具有更高的工作频率从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。我们认为在数据处理中,速度往往最终取决于处理器从内存中提取数据以及流入和通过处理器要花多少时间。
2.2、未来
但是CPU真的在未来规模深度神经网络的计算中沦为花瓶么?CPU巨擘英特尔显然不甘于出现这样的局面。
在其于去年发布的代号“KNL(Knignts Landing)融核”处理器介绍中,我们发现英特尔针对目前CPU的种种弊端做出了很大的调整:首先在硬件架构上集成了更多的核心(72颗),这意味着有更多的逻辑单元去进行运算。其次是英特尔为这些核心增加了“可变精度”的支持,在低精度模式下(深度学习通常使用单精度)大幅度提高其浮点运算能力(3 TFlops),甚至接近GPU的性能指标。在内存支持方面,它不仅可以支持更多的内存,而且大幅提高了与内存间数据通讯的带宽,这也解决了目前CPU数据传输速度的弊端。

以现状而论,GPU的风头远远盖过CPU,但是对于CPU而言,新发布的处理器在构架上的变化让它把曾经的劣势(核心数/带宽)逐渐变为了它潜在的优势。因此,二者数据训练领域之争还依旧会持续下去。
三、数据的推断:FPGA
虽然“CPU GPU”或者“MIC”的计算模型被广泛的应用于各种深度学习中去。
目前在深度学习模型的训练领域基本使用的是SIMD(Single Instruction Multiple Data:单指令多数据流架构)计算,即只需要一条指令就可以平行处理大批量数据。但是,在平台完成训练之后,它还需要进行推理环节的计算。这部分的计算更多的是属于MISD(Multiple Instruction Single Data:多指令流单数据流)。
在这个阶段,他们的作用必远不如训练阶段那么得心应手。而在未来,至少95%的深度学习都用于推断,尤其是在移动端。只有不到5%的是用于模型训练。因此,寻找低功耗,高性能,低延时的加速硬件成了当务之急。在这种情况下,人们把目光投向了“FPGA”与“ASIC”。
3.1、现状
FPGA全称是Field Programmable Gate Array:可编程逻辑门阵列。相对于之前两种芯片,它有一下几个的特点:硬件层面上,其内部集成大量的数字电路基本门电路和存储器,用户可以通过烧入配置文件来定义这些它们之间的连线,从而达到定制电路的目的;逻辑层面上,它不依赖于冯诺依曼结构,一个计算得到的结果可以被直接馈送到下一个无需在主存储器临时保存,因此不仅存储器带宽需求比使用GPU 或者CPU实现时低得多,而且还具有流水处理和响应迅速的特点。
ASIC(Application-Specific Integrated Circuit)是一种为专门目的而设计的集成电路。是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。ASIC的特点是面向特定用户的需求。亮点在于运行速度在同等条件下比FPGA快。根据谷歌披露的数据,完全版的“AlphaGo”拥有1920颗CPU和280颗GPU,除此此外,还有它还安装一定数量的TPU(Tensor Processing Unit)。 尽管谷歌一直对TPU语焉不详,业内普遍认为“AlphaGo”对围棋局势的预判所使用的置信网络(Value network)就是依赖TPU的发挥。

与GPU/CPU相比,FPGA与ASIC拥有良好的运行能效比,在实现相同性能的深度学习算法中,GPU所需的功耗远远大于FGPA与ASIC。
下图是FPGA与ASIC在设计环节的对比。FPGA从设计的角度来说更加的灵活多变。只要用 Verilog或者其他描述语言定义好内部的逻辑结构即可实现硬件加速器功能。而ASIC则更像是一锤子卖卖:针对特定功能深度学习算法量身定做的。而且ASIC的设计和制造要经过很多的验证和物理设计,与FPGA的即插即用相比,需要更多的时间,而且从设计到制造,付出的代价也相应的高了很多。一般来说,基于FPGA的开发周期大约为6个月,而相同规格的ASIC则需要1年左右。
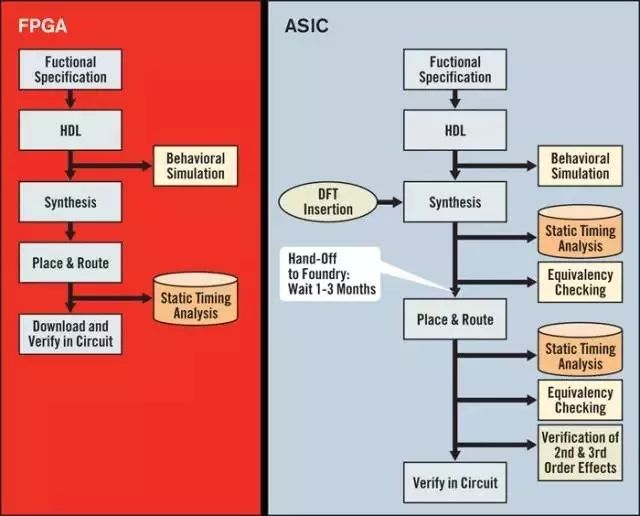
与CPU与GPU之争的一边倒相比,由于功能与市场定位等原因,二者间的竞争还是相当缓和。
由于FPGA具有开发周期短,上市速度快,可配置性等特点,目前被大量的应用在大型企业的线上数据处理中心,和军工单位。
而ASIC由于一次性成本远远高于FPGA,但由于其量产成本低,因此应用上就偏向于消费电子,如移动终端等领域。
3.2、未来
上文所说,在未来的深度学习中,大约有95%的应用是数据的推断。而且FPGA或者ASIC相较于GPU/CPU无论在研发还是产出上的成本都明显降低。因此必然是兵家必争之地。无论从INTEL收购ALTRA/ Movidius,还是XILINX与IBM合作,抑或谷歌和高通默默开发自己的专属ASIC中都可见一斑。而且针对移动端的深度学习,FPGA或者ASIC更多的会以SOC形式出现,以至于更好的优化神经网络结构提升效率。



