
热门标签
热门文章
- 1thingsboard3.2导入测试数据失败_thingsboard db installation failed!
- 2Vue2.0打包后打开出现空白页解决方法_vue 出现空弹窗
- 3springboot+vue.js美食菜谱评分推荐系统java毕业设计源码含文档ppt_美食推荐管理系统ppt毕业设计
- 4合成数据: 利用开源技术节约资金、时间和减少碳排放
- 5Redis解决方案:NOAUTH Authentication required(连接jedis绑定密码或修改redis密码)_redis noauth authentication required.
- 6(十九)数据结构-图的应用-有向无环图表达形式、拓扑排序、关键路径_有向无环图的一个有效的拓扑排序
- 7Android 中的notify 机制_android insert notify
- 8鸿蒙系统学习五-Ability的生命周期_ability的生命周期回调函数
- 9GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案_chatglm3 github
- 10鸿蒙os的速度和ios,鸿蒙OS 2.0对比iOS,苹果流畅度被华为吊打,这个结果可信吗?...
当前位置: article > 正文
【ElasticSearch】中文分词器_es中文分词器
作者:凡人多烦事01 | 2024-03-21 14:08:29
赞
踩
es中文分词器
ES默认的analyzer(分词器),对英文单词比较友好,对中文分词效果不好。不过ES支持安装分词插件,增加新的分词器。
1、如何指定analyzer?
默认的分词器不满足需要,可以在定义索引映射的时候,指定text字段的分词器
例子:
PUT /article
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "smartcn"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
只要在定义text字段的时候,增加一个analyzer配置,指定分词器即可,这里指定的分词器是smartcn,后面会介绍怎么安装smartcn插件。
分词器种类
目前中文分词器比较常用的有:smartcn和ik两种, 下面分别介绍这两种分词器。
smartcn分词器
smartcn是目前ES官方推荐的中文分词插件,不过目前不支持自定义词库。
插件安装方式:
{ES安装目录}/bin/elasticsearch-plugin install analysis-smartcn
- 1
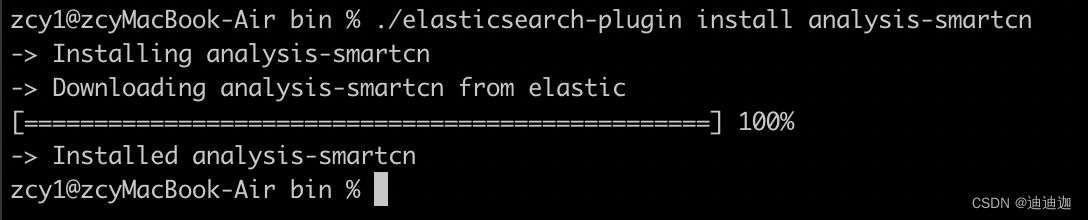
安装完成后,重启ES即可 一定要重启不然找不到分词器!!!。
smartcn的分词器名字就叫做:smartcn
smartcn中文分词效果
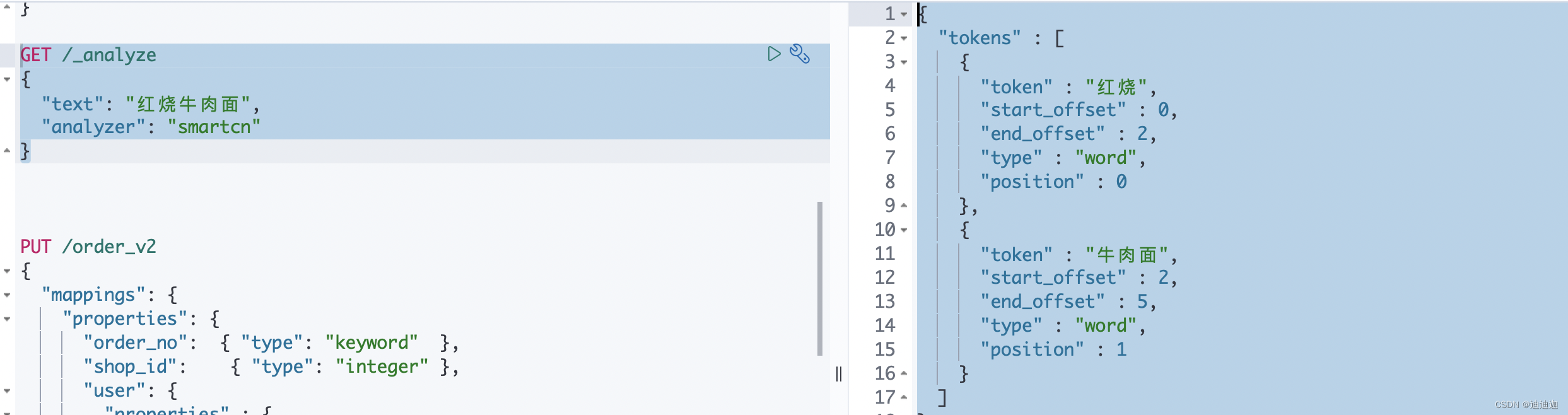
GET /_analyze
{
"text": "红烧牛肉面",
"analyzer": "smartcn"
}
- 1
- 2
- 3
- 4
- 5
{ "tokens" : [ { "token" : "红烧", "start_offset" : 0, "end_offset" : 2, "type" : "word", "position" : 0 }, { "token" : "牛肉面", "start_offset" : 2, "end_offset" : 5, "type" : "word", "position" : 1 } ] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
ik分词器
ik支持自定义扩展词库,有时候分词的结果不满足我们业务需要,需要根据业务设置专门的词库,词库的作用就是自定义一批关键词,分词的时候优先根据词库设置的关键词分割内容,例如:词库中包含 “上海大学” 关键词,如果对“上海大学在哪里?”进行分词,“上海大学” 会做为一个整体被切割出来。(需要重启es)
安装ik插件:
// 到这里找跟自己ES版本一致的插件地址
https://github.com/medcl/elasticsearch-analysis-ik/releases
- 1
- 2
我本地使用的ES版本是7.8.0,所以选择的Ik插件版本地址是:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
- 1
安装命令
{ES安装目录}/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
- 1
ik中文分词效果
ik分词插件支持 ik_smart 和 ik_max_word 两种分词器
ik_smart - 粗粒度的分词
ik_max_word - 会尽可能的枚举可能的关键词,就是分词比较细致一些,会分解出更多的关键词
例1:
GET /_analyze
{
"text": "上海人民广场麻辣烫",
"analyzer": "ik_max_word"
}
- 1
- 2
- 3
- 4
- 5
输出:
{ "tokens" : [ { "token" : "上海人", "start_offset" : 0, "end_offset" : 3, "type" : "CN_WORD", "position" : 0 }, { "token" : "上海", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 1 }, { "token" : "人民", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "广场", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 3 }, { "token" : "麻辣烫", "start_offset" : 6, "end_offset" : 9, "type" : "CN_WORD", "position" : 4 }, { "token" : "麻辣", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 5 }, { "token" : "烫", "start_offset" : 8, "end_offset" : 9, "type" : "CN_CHAR", "position" : 6 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
例2:
GET /_analyze
{
"text": "上海人民广场麻辣烫",
"analyzer": "ik_smart"
}
- 1
- 2
- 3
- 4
- 5
输出:
{ "tokens" : [ { "token" : "上海", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "人民", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "广场", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 2 }, { "token" : "麻辣烫", "start_offset" : 6, "end_offset" : 9, "type" : "CN_WORD", "position" : 3 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/281500
推荐阅读
相关标签

